- 23/09 Notion에 정리했던 글을 복습하는 차원에서 다시 블로그에 포스팅한다.
Abstract
- ControlNet 제안. 이 모델은 기존의 Text-to-Image model을 freeze하고, 수십억개의 이미지 데이터로 pretrained 된 인코더 부분만 가져와서 다양한 conditional 조건에서 다시 fine tuning 함.
- parameter를 0으로 초기화시켜 점진적으로 증가시키고, 유해한 Noise가 파인튜닝에 영향을 미치지 않도록 하는 zero convolution 을 사용. edges, depth 등의 조건에서 다양한 conditioning control을 테스트 함. 작은 데이터, 큰 데이터 셋에서 모두 잘 동작.
1. Introduction
-
기존의 text-to-image는 성능이 좋지만, 에서 text 하나로만은 복잡한 표현들을 control 할 수 없다. text-to-image를 원하는 condition 조건에서 end-to-end로 학습시키는 것은, 기존의 데이터보다 학습 시키려는 데이터가 매우작아 어려운 일. 적은 데이터로 기존의 모델을 finetuning하면, 오비피팅이나 치명적인 망각이 일어날 수 있다.
-
이 논문에서 제안하는 ControlNet에서는 pretrained 된 t2i diffusion model의 parameter를 freeze하여 quality와 capabilities를 보존하고 encoding layer를 copy한다. 학습가능한 copy와, original model은 train과정에서 점진적으로 학습되기 위해서 가중치가 0으로 초기화된 zero convolution layer로 연결된다. 이는 training을 시작할 때 거대한 diffusion model에 deep feature에 noise가 끼는 것을 방지.
-
Canny edges, Hough lines, user scribbles, human key points, segmentation maps, shape normals, depths에서 잘 작동
2. Related Work
- 데이터로 직접 pretrained 모델을 fine-tuning하면 과적합, 모드 붕괴, 치명적인 망각이 발생할 수 있다. 이 문제를 해결하기 위해 많은 연구가 있었음. 여기에선 zero conv 이용
2.1. Finetuning Neural Networks
HyperNetwork
- NLP에서 시작, 더 큰 신경망에 영향을 미치도록 작은 recurrent neural network를 학습시키는 것.
Adapter
- 새로운 module layers를 임베딩하여 pretrained transformer model을 customizing 하는 것. CV에서는 domain adapation에서 사용되고 주로 CLIP과 함께 같이 사용된다.
Additive Learning
- 원래의 가중치를 freeze하고 소수의 새로운 매개변수 추가하여 망각을 방지함.
Low-Rank Adaptation (LoRA)
- low-rank 행렬로 파라미터의 offset만을 학습하여 망각을 방지함.
Zero-Initialized Layers
- ControlNet에서 네트워크를 연결하는 데 사용된다. 0으로 초기화된 layer를 사용함.
2.2. Image Diffusion
- 생략
2.3. Image-to-Image Translation
- 생략
3. Method
3.1. ControlNet 중요!!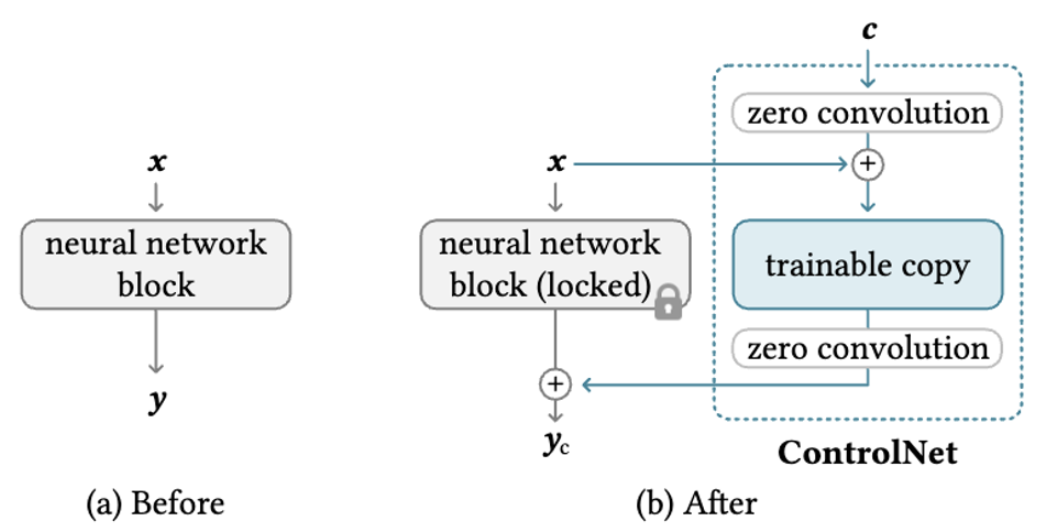
-
원래의 파라미터 Θ를 lock하고 Θ를 복사한 를 학습시킴. 이 복사본은 외부의 control c를 인풋으로 받음. 이때 원본 SD는 모델의 원래 정보를 보존하는 반면, 학습가능한 copy는 기존 모델을 재사용하여 다양한 input condition을 다루기 위한 깊고 강건하고 강력한 백본을 구축한다.
-
이때 copy는 zero convolution Z(·; ·)에 연결된다. Z(·; ·)는 가중치와 bias가 모두 0으로 초기화된 1x1 conv layer이다. ControlNet에서 , 를 가지는 두개의 zero conv 를 사용한다. 처음 condition에 zero conv 태우고, 복사한 encoder 태우고, 다시 zero conv 태워서 SD에 연결한다. 아래 식에서 F는 파라미터 Θ를 가지는, x를 태우면 y가 나오는 함수(nerual network)
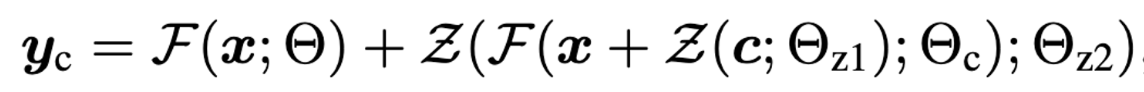
-
위 식에서 알 수 있듯이, 첫번째 training step에서는 Z의 매개변수는 모두 0이므로 Z의 연산값은 모두 0임. 따라서 = y 임.
-
이렇게 되면 해로운 noise가 training이 시작될때 학습가능한 copy의 neural network의 hidden state에 영향을 줄 수 없다. =0이고, 학습가능한 copy또한 x를 input으로 받아 원래 large의 capabilities를 모두 유지하고 있기 때문에, pretrained 모델은 추가 학습을 위한 강력한 백본 역할을 할 수 있다.
-
zero conv는 훈련 초기에 gradient가 흐르는 과정에서, random noise를 제거함으로써 백본을 보호한다.
3.2. ControlNet for Text-to-Image Diffusion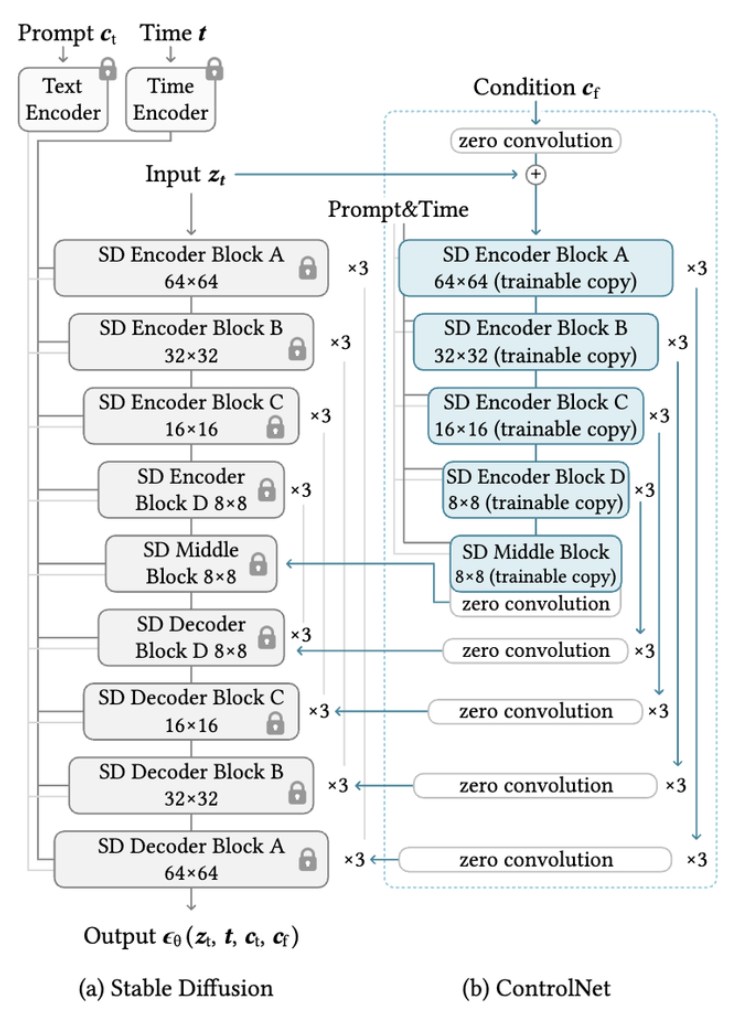
-
SD는 인코더 12, 디코더 12, middle block 1개로 총 25개 블럭으로 구성된다. 이때 8개 블럭은 downsampling or upsampling conv layer임. 나머지 17개 블럭은 4개의 resnet layer와 2개의 VIT를 포함함. 각 VIT에는 cross-attention, self-attention mechanism이 포함 된다. 예를 들어 그림 3-a에서 A 블럭은 4개의 resnet과 2개의 VIT가 포함되어 있고, 이 블럭이 3번 반복되는 것을 의미한다. text는 CLIP으로 embedding화 되고 timstep은 positional encoding을 사용한 time encoder로 encoded 된다.
-
ControlNet은 인코더 12개와 middle block 1개를 copy하여 tranable하게 만든다. 12개의 블럭은 64,32,16,8의 4개의 resolution으로 구성되며 각각 3번 반복된다. output은 skip-connection과 1개의 middle block에 추가된다.
-
ControlNet을 연결하는 방식은 계산이 효율적이다. SD만 학습한는것 보다 GPU가 23%만 더 필요. 시간은 34%만 더 소요된다.
-
SD는 VQ-GAN과 유사한 방식으로 512이미지를 64의 latent로 변환시켜 그 space 상에서 diffusion process, reverse process를 거침. SD에 ControlNet를 추가하기 위해 condition image를 512에서 64로 encoding함. 특히 4x4 kernel과 2x2 stride를 가지는 4개의 conv layer를 가지는 작은 인코더 를 사용하여 condition image를 특정 feature space로 보낸다. (인코더는 controlNet과 함께 훈련되며 각 16 32 64 128의 채널을 가짐)
3.3. Training
- 아래 Loss로 학습된다. 는 noisy image, t는 timestep, 는 text prompt, 는 task-specific condition임. 아웃풋은 .

- 학습 과정에서 50%로 text를 빈 string으로 줌. 이 방법은 prompt 대신 condition을 인식하는 데에 도움을 줌. 훈련과정에서 zero convolutions운 network에 noise를 주지 않음. → 좋은 퀄리티의 이미지 생성 가능.
- 저자들은 점차적으로 condition을 학습하지 않고, 갑자기 condition을 따르는것을 확인함. 이 현상은 10K 미만의 step에서 일어나는데, 이 현상을 sudden convergence phenomenon라고 부름.
3.4. Inference
Classifier-free guidance resolution weighting
SD는 아래 식의 Classifier-Free Guidance를 사용함.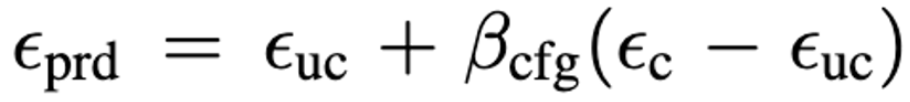
- uc : unconditional, c : conditional, B : guidance scale
- conditioning image는 에 모두 추가 될 수도 있고, 에만 추가될 수도 있다. prompt를 주지 고 두 경우 모두 추가하면 CFG guidance가 완전히 제거된다. 에만 주면 guidance가 너무 세게 들어감.
- 해결책은 conditioning image를 첫번째로 에만 추가하고, resolution 각 (8,,,64)에 따라서 = (64/)를 곱한다. (해상도가 클수록 condition 적게) 이 strength를 줄이면 좋은 성능을 보여주고, 이를 CFG resoltuion weighting이라고 한다.
Composing multiple ControlNets.
- ControlNet의 output을 SD에 직접적으로 add한다. (추가적인 weighting나 선형 보간 없이)
4. Experiments
4.1. Qualitative Results
4.2. Ablative Study
- 4가지 prompt setting에서 zero conv를 일반 conv로 변경한 실험, 각 학습가능한 copy를 conv로 변경한 실험을 했음.
- zero conv의 효과가 생각보다 대단함. → 이를 사용하지 않으면 훈련가능한 copy의 정보가 훈련 과정중에 파괴되는 것을 볼 수 있음.
4.3. Quantitative Evaluation
User study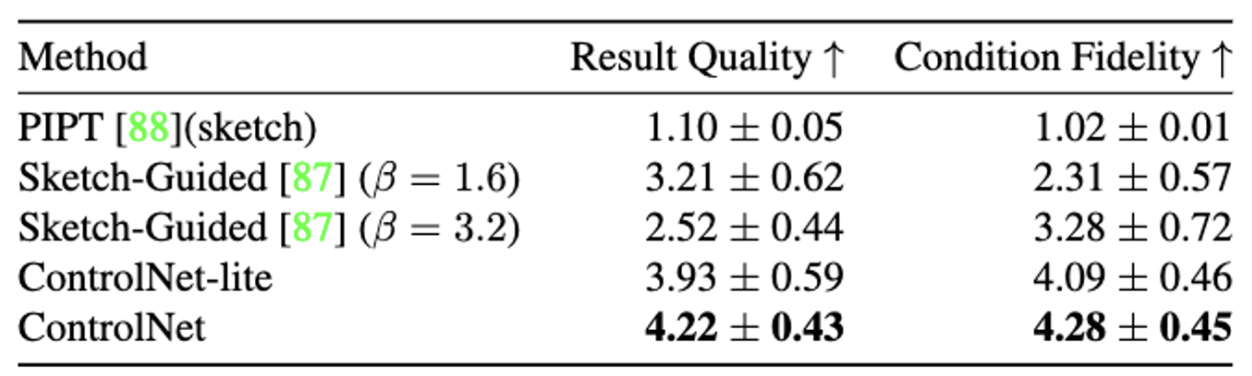
- 1~5점의 Average Human Ranking 사용
Comparison to industrial models
- 매우 많은양의 GPU와 Data, 1000시간의 양의 시간을 들인 Stable Diffusion V2와 그에비해 매우 적은 양의 리소스를 들인 ContronNet 비교. 사람들에게 평가 하라고 했을때 거의 구별 못했음.
Condition reconstruction and FID score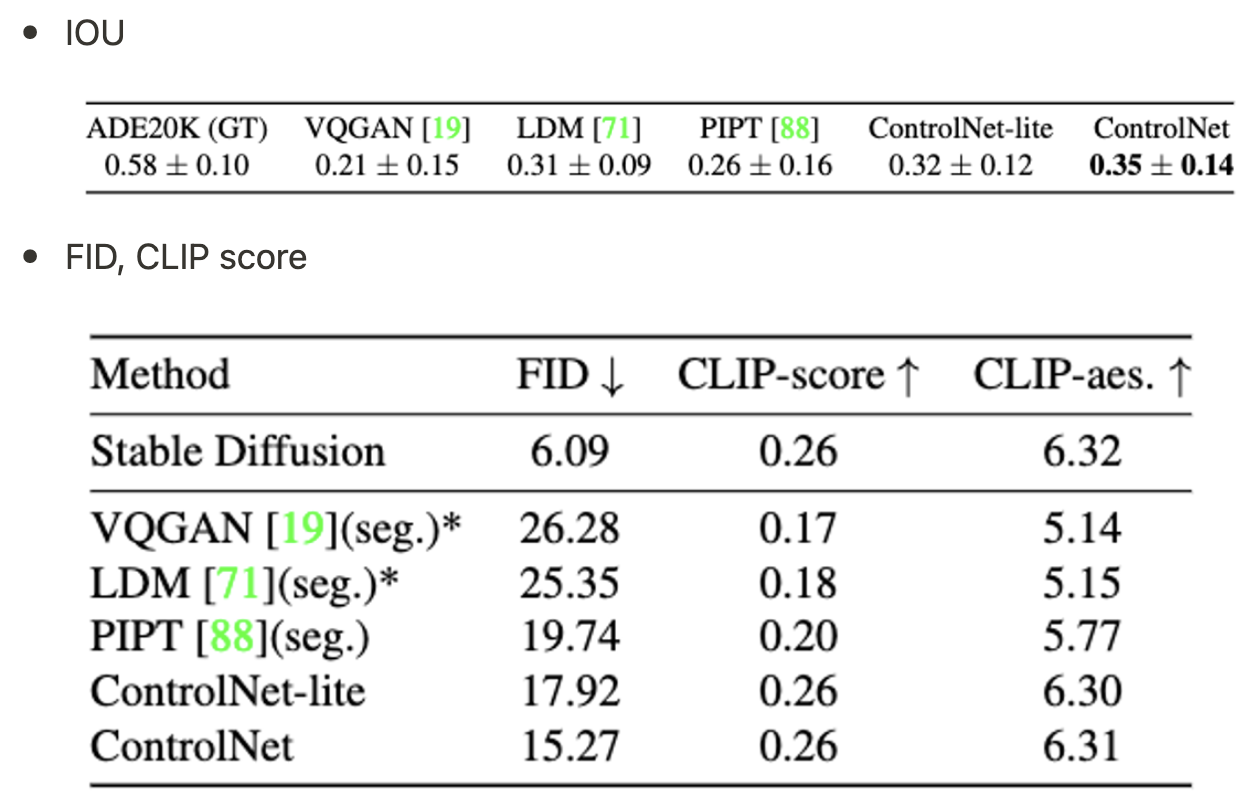
- iou는 sota model인 oneformer와 비교 (0.58)
4.4. Comparison to Previous Methods
4.5. Discussion
- data가 많으면 성능좋음 - Fig 10
- condition image의 semantic 정보를 잘 잡음 -Fig 11
- SD의 구조를 변경하지 않기때문에 다른 diffusion model에 직접 적용 가능 -Fig 12
5. 결론
- 기존의 SD를 복사하여 훈련가능하게 만들고, 간단한 인코더 도입.
- zero conv를 사용하여 noise가 끼는것을 방지 → 꽤나 중요한 역할을 하더라.
- 매우 다양한 condition image를 사용한 이미지 생성이 가능함.
- SD의 구조를 복습할 수 있어서 좋았음.
코드
- https://huggingface.co/docs/diffusers/training/controlnet 이 링크 참고하여 사용.
- 저는 https://huggingface.co/datasets/JFoz/dog-poses-controlnet-dataset 이 데이터 셋으로 학습을 시켜봤는데, 결과가 딱히 좋진 않았음. 6k개의 data로 학습을 했지만, 기존의 sd가 dog의 pose를 잘 잡지 못한다고 생각. SD 1.5버전의 model을 huggingface의 예시 코드를 돌려보았을 때에는 사람의 pose는 잘 잡는것 같았음. 아래 결과보면 4개의 validation중 4번째 사진만 어느정도 pose를 잘 이해한것 같음.

