Dfifusion
1.Denoising mcmc for accelerating diffusion-based generative models 논문 리뷰
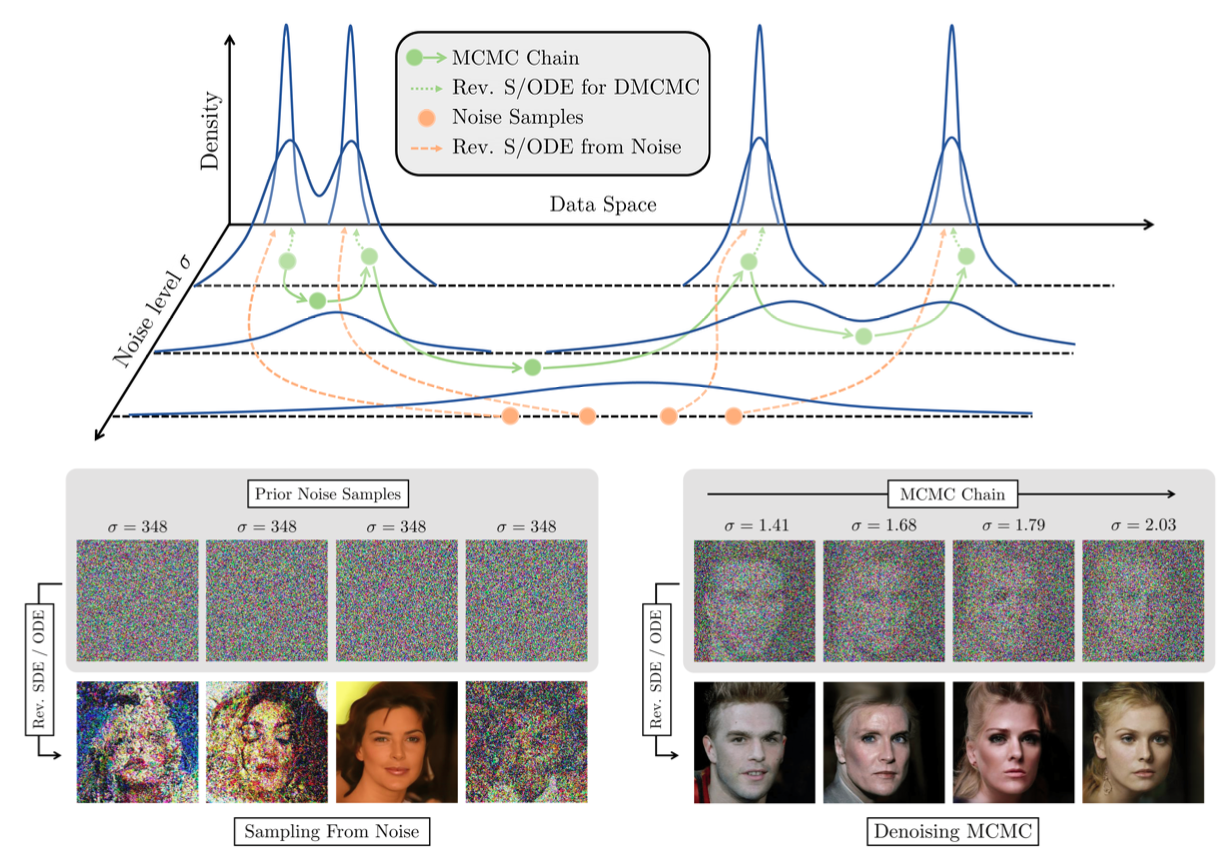
이 논문은 위 그림만 이해하면 어느정도 다 이해했다고 봐도 된다고 생각한다.초록색 실선이 이 논문에서 제안하는 DLG의 Step1인 MCMC ON THE PRODUCT SPACE X × S 부분, 초록색 점선이 Step2인 INCORPORATING DENOISING S
2.DDIM 논문리뷰

DDPM은 GAN없이 이미지 생성을 잘해냈지만, Markovian Process 라서 이미지 생성까지 많은 Step을 거쳐야 하기 때문에 시간이 너무 오래 걸린다. Sampling을 가속화하기 위해 non-Markovian diffusion process를 도입한 DD
3.Common Diffusion Noise Schedules and Sample Steps are Flawed 논문 리뷰
저자들은 일반적인 Diffusion noise schedule은 last timestep에서 SNR이 0이 되도록 강제하지 않고, inference 시에 last timestep 에서 시작하지 않는다는 것을 발견했다. 이러한 결함있는 디자인은 inference와 tra
4.Diffusion with Offset Noise

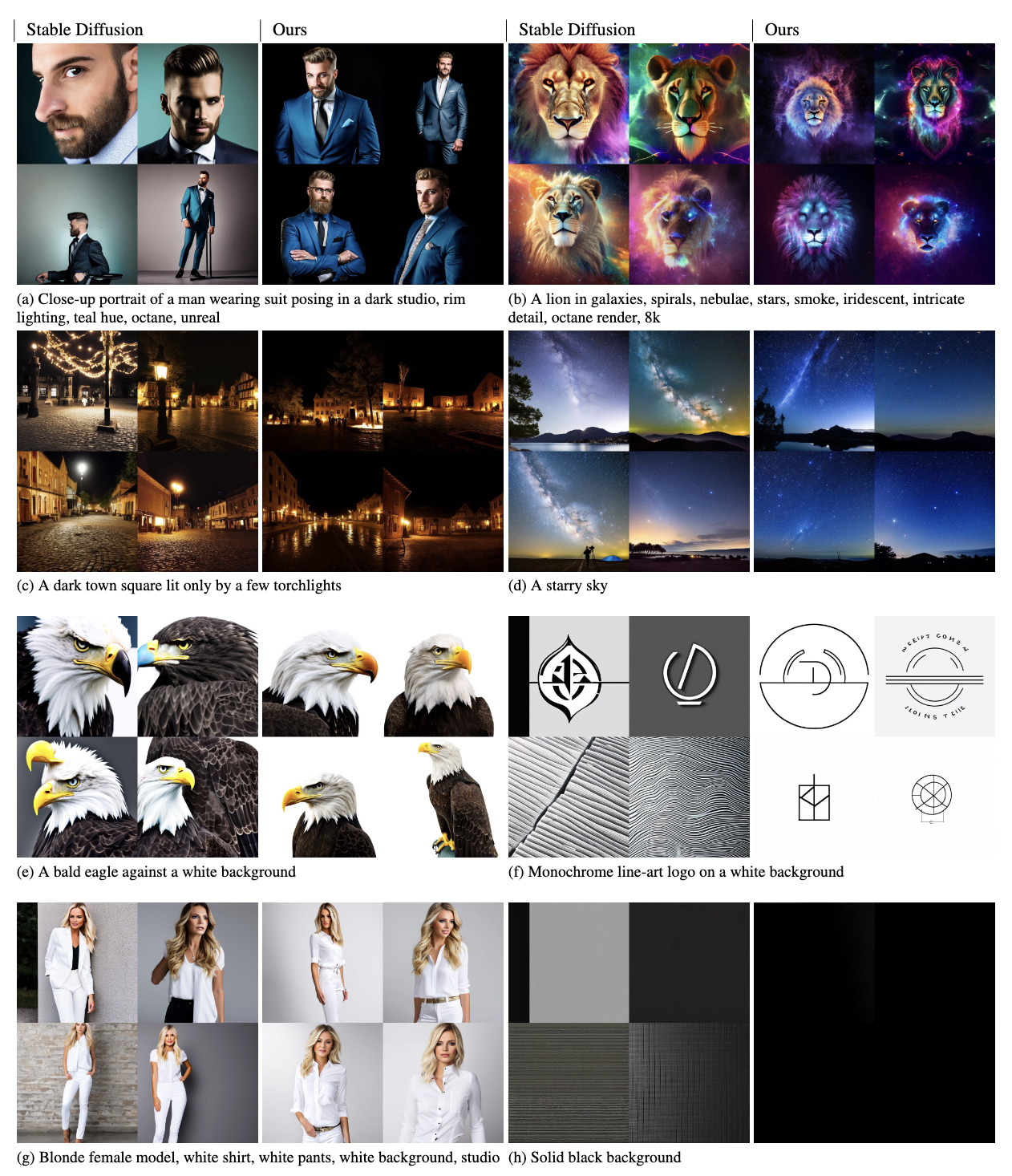
1. Stable diffusion의 문제 Stable diffusion은 매우 좋은 성능을 띄지만, 문제점이 존재한다. 매우 어둡거나 매우 밝은 이미지를 생성하도록 시도해도 항상 평균값이 0.5에 가까운 이미지를 생성한다. (완전 검정색 이미지는 0, 완전 흰색
5.Adding Conditional Control to Text-to-Image Diffusion Models (ControlNet) 논문리뷰
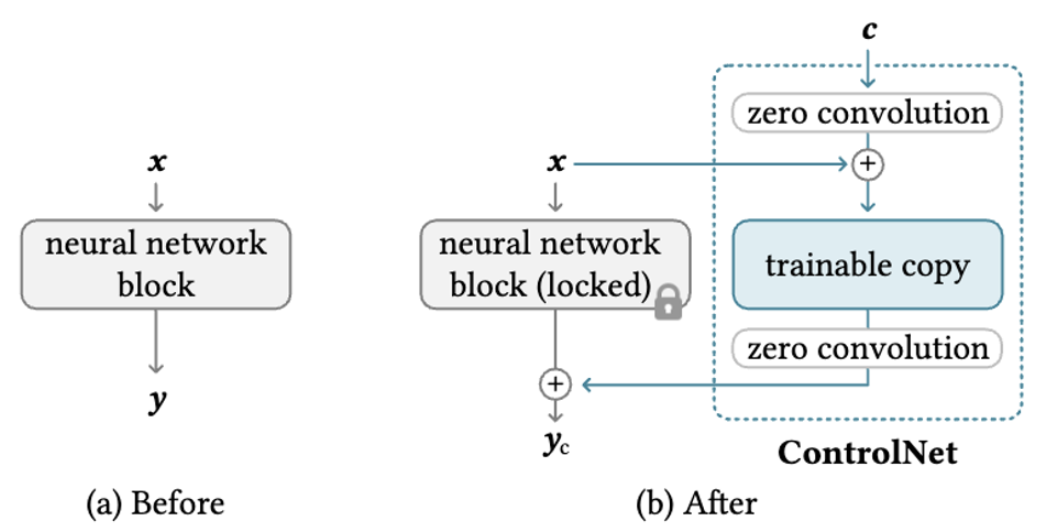
23/09 Notion에 정리했던 글을 복습하는 차원에서 다시 블로그에 포스팅한다.ControlNet 제안. 이 모델은 기존의 Text-to-Image model을 freeze하고, 수십억개의 이미지 데이터로 pretrained 된 인코더 부분만 가져와서 다양한 con
6.Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators 논문 리뷰
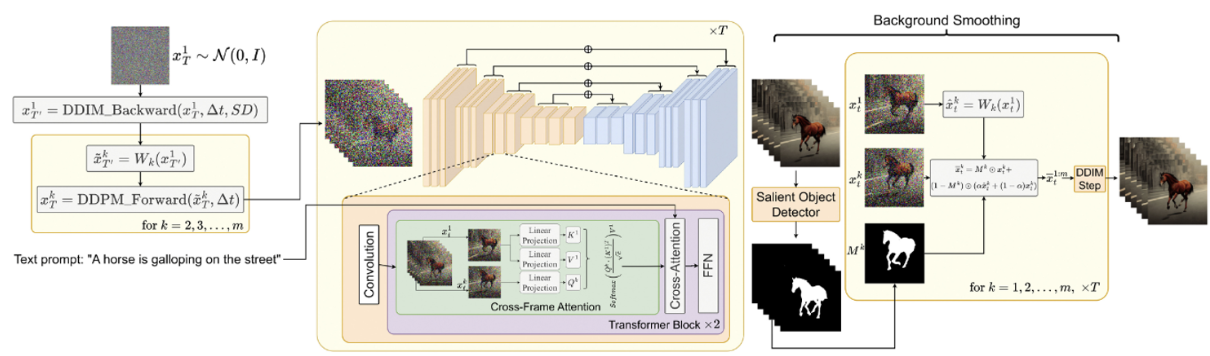
text-image model들만 보다가 video에 대해서 공부해보고 싶어서 봤던 논문. 23/10 Notion에 정리했던 글을 복습하는 차원에서 다시 블로그에 포스팅한다.이 논문은 기존의 text-to-image의 힘을 활용하여 Zero-shot text-to-vi