[논문 리뷰] Data Distributional Properties Drive Emergent In-Context Learning in Transformers
LLM
Abstract
- Large transformer-based models 들은 explicit한 train 없이 in-context few-shot learning을 할 수 있다. 훈련 체제의 어떠한 측면이 이러한 현상을 일으킬까?
- this behavior is driven by the distributions of the training data itself.
- in-context learning은 훈련 데이터가 uniform이 아니라 cluster에 나타나는것과 같이 거의 발생하지 않는 class가 많을때 나타난다. 또한 item meanings or interpretations이 dynamic할때 더 강하게 나타난다.
- 이 속성는 natural language에서 예시되지만 이뿐만 아니라, 다른 도메인의 naturalistic data 에서도 내제 되어 있다.
- 이는 또한 supervise learning에서 학습할때의 분포인 uniform, iid 에서 크게 벗어난다.
- 첫번째 실험에서 in-context learning이 weight-based learning과 trade off가 있으며, 모델은 두 가지를 동시에 최적화 할 수 없음을 발견함.
- 다른 실험에서는 language를 포함한 naturalistic data에서 skewed Zipfian distribution를 따를때, 한 모델에서 두 가지를 함께 학습할 수 있음을 밝힘.
- 추가 실험에서 naturalistic data distributions는 recurrent model이 아닌transformer 에서만 in-context learning을 할 수 있음을 보여줌
- 요약하자면, 트랜스포머 아키텍처가 학습 데이터의 특정 속성과 함께 작동하여 large language models의 흥미로운 emergent in-context learning 을 유도하는 방법과 언어 이외의 도메인에서 in-context 와 in-weights learning을 모두 장려할 수 있는 방법을 보여줌.
1. Introduction
-
transformers는 in-context learning을 잘 수행한다.
-
이는 gradient update 없이 모델이 새로운 concept의 몇가지 examples를 빠르게 일반화하는 능력이다. in-context learning은 output이 몇가지 예시에 따라 conditioned 되고, gradient update 없는 few-shot learning의 특수한 경우이다.
-
in-weight learning은 이와 반대 개념임. → 지도학습, 느리고, gradient update를 함.
-
‘meta-learning’ 연구 분야에서 뉴럴넷이 weight update 없이 few shot learning이 가능함을 보여주었음
-
이를 위해 meta-learning 이라고 불리는 프로세스인 in-context learning에 맞는 훈련 체계를 명시적으로 설계했다.
-
transformers 모델은 in-context learning의 방식을 생각하고 디자인 되지 않았음에도 in-context learning 능력이 부각된다.
-
어떻게 이 능력을 가질까? → recurrent models 이 transformers model로 대체됨에 따라서 이 능력이 생김. in-context learning 은 훈련 데이터 분포의 qualities에 따라서 그 능력이 결정된다는 가설을 탐구함.
- 많은 natural language 데이터는 일반적인 supervision dataset과 다름. 자연어는 일시적으로 ‘bursty’된다. 즉 주어진 entity(단어, 사람, 객체) 는 시간에 걸쳐 uniform이 아닐 수 있으며, cluster로 나타나는 경향이 있다. → 예를 들어, "선거"라는 단어는 선거 시즌 동안에는 뉴스 기사, 토론 등에서 자주 등장하지만 선거가 끝나면 이 단어의 출현 빈도가 줄어들 수 있다.
- 또한 natural data는 드문 item의 긴 꼬리가 있는 Zipfian distribution 를 따라 entities 간 marginal distribution 가 highly skewed (한쪽으로 치우쳐짐) 되는 특성이 있다.
- 마지막으로, entities의 의미는 fix되어 있지않고 dynamic 하다. 즉 하나의 entity는 여러가지 의미를 가질 수 있고, 여러 entities 가 같은 해석에 mapping 될 수도 있다. 이는 문맥에 따라서 달라진다.
- 위 속성을 조합하면 일반적인 supervised learning에 사용되는 data와 few shot meta training에 사용되는 data 사이의 중간 지점을 차지하는 traning data를 생성할 수 있다.
- supervised learning에서는 학습 전반에 걸쳐서 fix 된 (규칙성으로 반복되는 item class 와 item-label mapping)으로 구성된다. → gradient descent 사용해서 점진적으로 학습가능.
- 반면에 few-shot or in-context meta-training 은 일반적으로 item class가 반복 되거나 item-label mapping이 에피소드 내에서만 고정되는 특별한 데이터 시퀀스에 대해 모델을 직접 훈련하는 것이다. 에피스드 간에는 반복되거나 고정되지 않음. Naturalistic data, such as language or first-person experience는 이 두가지 유형의 특성을 모두 가지고 있음.
- 또한 natural data의 skewed 되고 꼬리가 긴 분포는 item 별로 빈도수 차이가 크다는 것을 의미함. 드문 item들은 종종 'meta-training' 데이터의 시퀀스처럼 주어진 context window 내에서 여러 번 발생할 가능성이 불균형적으로 높다는 것이 중요함.
- entitiy간의 dymaic 관계(다의어, 동음이의어) 는 매 에피소드마다 mapping이 무작위로 변경되는 few shot meta learning에서 사용되는 completely dynamic item-label mapping의 약한 버전으로 볼 수 있음.
-
이 논문에서는 훈련 데이터의 분포 특성을 실험적으로 조작하고, in-context few shot learning에 미치는 영향을 측정했다.
-
transformer 모델이 data that includes both burstiness and a large enough set of rarely occurring classes 로 학습했을때만 in-context learning이 나타났다. 또한 natural data에서 관찰되는 dynamic item 해석의 두 가지 instance, 즉 item 당 label 이 많은 경우와, class 내 variation이 있는 경우를 테스트했고 그 결과, 학습 데이터에 대한 두 가지 개입 모두 모델이 in-context learning 에 더 강하게 편향될 수 있음을 발겸함.
-
우리가 테스트한 모델은 일반적으로 빠른 in-context learning과 느린 gradient 기반 update를 통해 저장된 정보('in-weight learning')에 의존하는 것 사이에서 상충되는 모습을 보임. 그러나 클래스에 대한 skewed marginal distribution(자연 데이터의 집피안 분포와 유사)으로 학습할 경우 모델이 in-context learning과 in-weight learning을 동시에 나타낼 수 있다는 사실을 발견함.
-
동시에 아키텍처도 중요하다. 트랜스포머와 달리, (매개변수 수에 따라 매칭되는) LSTM 및 RNN과 같은 recurrent 모델은 동일한 데이터 분포로 학습할 때 in-context learning이 안된다. 그러나 잘못된 데이터 분포로 훈련된 트랜스포머 모델또한 in-context learning을 보여주지 못했다는 점에 유의해야 함. 따라서 아키텍처와 데이터는 모두 in-context learning을 구현하는 데 있어 핵심.
2. Experimental Design
2.1 The training data
-
in-context few-shot learning 이 가능하게 하는 원인을 찾기 위해 Omniglot dataset를 사용하여 standard image-label dataset 을 만들었다. → various international alphabets의 1623 different character class 로 구성되어 있고 각 class에는 20개의 필기 예시가 포함되어 있음.
-
The few-shot challenge는 훈련에서 본 적이 없는 character class의 예를 해당 클래스의 몇 가지 예와 몇 가지 대체 클래스만을 기반으로 분류하는 것이다.
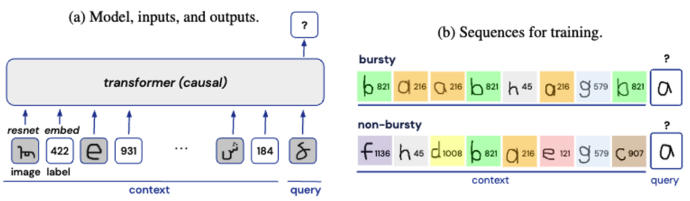
- 훈련 데이터는 이미지와 레이블의 시퀀스로 구성된다.
- 각 시퀀스의 처음 16개의 element는 ‘context’를 구성하고, 8개의 image-label 쌍으로 구성되었음.마지막 element는 '쿼리' 이미지로, 모델의 목표는 쿼리에 대한 올바른 레이블을 예측하는 것.
- 이미지가 학습 전반에 걸쳐 반복되도록 허용되었으며, 각 이미지 클래스에 대한 정수 레이블은 일반적인 supervision dataset 에서와 같이 학습 전반에 걸쳐 unique하고 fix 되었음. 이는 각 에피소드마다 item-label mapping이 완전히 새로워지거나, 각 에피소드마다 item 자체가 새로워지는 기존의 few-shot traning에서 크게 벗어난 방식이라는 점을 강조한다.
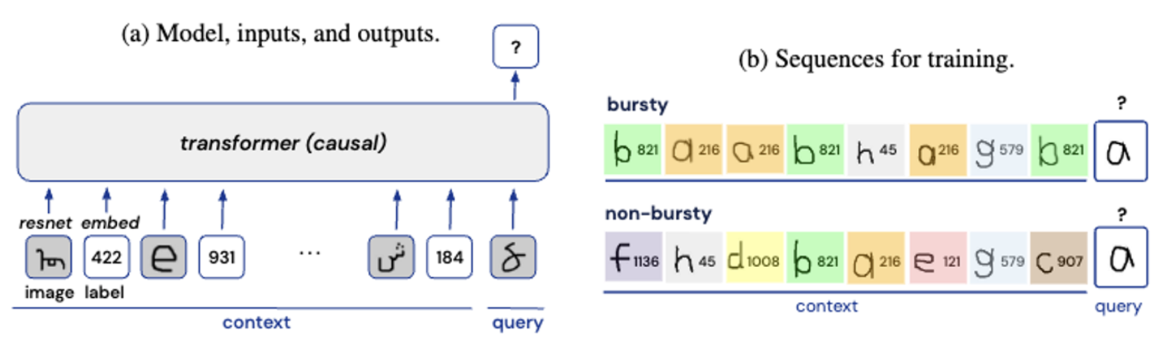
- 표준 실험에서는 'bursty' 시퀀스와 'non-bursty' 시퀀스를 혼합하여 모델을 훈련함. bursty 시퀀스에서는 쿼리 클래스가 context에서 3번 등장함. burstiness를 정량화하거나 인스턴스화하는 방법은 여러 가지가 있지만(예: Altmann 외, 2009; Alvarez-Lacalle 외, 2006; Lambiotte 외, 2013; Neuts, 2007; Sarkar 외, 2005; Serrano 외, 2009), 실험의 'burstiness' 시퀀스는 언어에서 관찰되는 맥락 내 burstiness을 반영하도록 설계함. 모델이 단순히 시퀀스에서 가장 일반적인 레이블을 출력하는 것을 방지하기 위해 두 번째 image-label pair(b)도 문맥에서 3번 등장함. 버스트가 없는 시퀀스의 경우, image-label pair은 전체 Omniglot 세트에서 무작위로 균일하게 추출. 'bursty' 시퀀스와 'non-bursty' 시퀀스의 비율을 변경하여 데이터 세트의 전반적인 burstiness를 지속적으로 변화시킬 수 있음.
2.2 The model
- 시퀀스의 각 element는 embedder(standard embedding layer for the integer labels, and a ResNet for the images)를 통해서 토큰화되고 이 토큰들은 transformer에 전달된다. 12개의 레이어와, 64의 임베딩 크기를 가지는 transformer 사용
2.3 The evaluation data
-
(1) in-context learning 과 (2) in-weights learning 를 평가하기 위해 두 가지 유형의 시퀀스에 대해서 평가함. evaluation seq 도 train seq와 같이 각 시퀀스의 처음 16개의 element는 ‘context’를 구성하고, 8개의 image-label 쌍으로 구성되었음.마지막 element는 '쿼리' 이미지로 사용
-
in-context few-shot learning의 능력을 평가하기 위해 standard few-shot setup 사용. context는 각각 4개의 예시가 포함된 2개의 서로다른 이미지 클래스를 랜덤하게 구성하였고, 쿼리는 랜덤하게 두개의 이미지 중 하나를 선택했음.

- 모든 시퀀스에 걸쳐 레이블이 고정된 훈련과는 다르게, 이 두 이미지 클래스의 레이블은 각 시퀀스에 무작위로 다시 할당. 한 이미지 클래스는 0에 할당되고 다른 이미지 클래스는 1에 할당되었음(그림 1c). → 각 시퀀스에 대해 라벨이 무작위로 다시 할당되었기 때문에, 모델은 쿼리 이미지에 대한 라벨 예측을 수행하기 위해 현재 시퀀스의 context를 사용해야 합니다. 달리 명시하지 않는 한 in-context learning은 항상 훈련에서 볼 수 없는 holdout 이미지 클래스에서 평가된다.
-
모델은 항상 가능한 모든 출력 레이블에 대해 full multi-class classification 를 수행해야 하지만(학습에서와 같이) few-shot 정확도는 few-shot 시퀀스에 표시된 두 개의 레이블에 대해서만 모델 출력을 고려하여 계산된다. (0, 1) 확률은 1/2. 이는 예를 들어 컨텍스트에서 레이블 중 하나를 무작위로 선택하여 우연 이상의 성능이 발생하지 않도록 보장한다. 또한 모델은 새로운 이미지 클래스에 대한 in-context learning 을 위해 평가되었지만 새로운 레이블은 평가되지 않았음. (appendix 참조)
-
모델에서 훈련된 클래스의 in-weight 학습을 평가하기 위해 평가 시퀀스는 훈련에 사용된 것과 동일한 레이블을 사용하여, 교체 없이 uniformly하게 선택된 이미지 클래스로 구성.(그림 1d) 이미지 클래스는 각 시퀀스 내에서 unique 했기 때문에 쿼리는 컨텍스트에서 support 되지 않았음. 따라서 모델이 라벨을 정확하게 예측하는 유일한 방법은 모델 가중치에 저장된 정보에 의존하는 것임. 이 문제의 경우 올바른 쿼리 라벨은 훈련에서 표시된 라벨 중 하나일 수 있으며 확률은 일반적으로 1/1600입니다.
3. Results
3.1 What kinds of training data promote in-context learning?
Burstiness.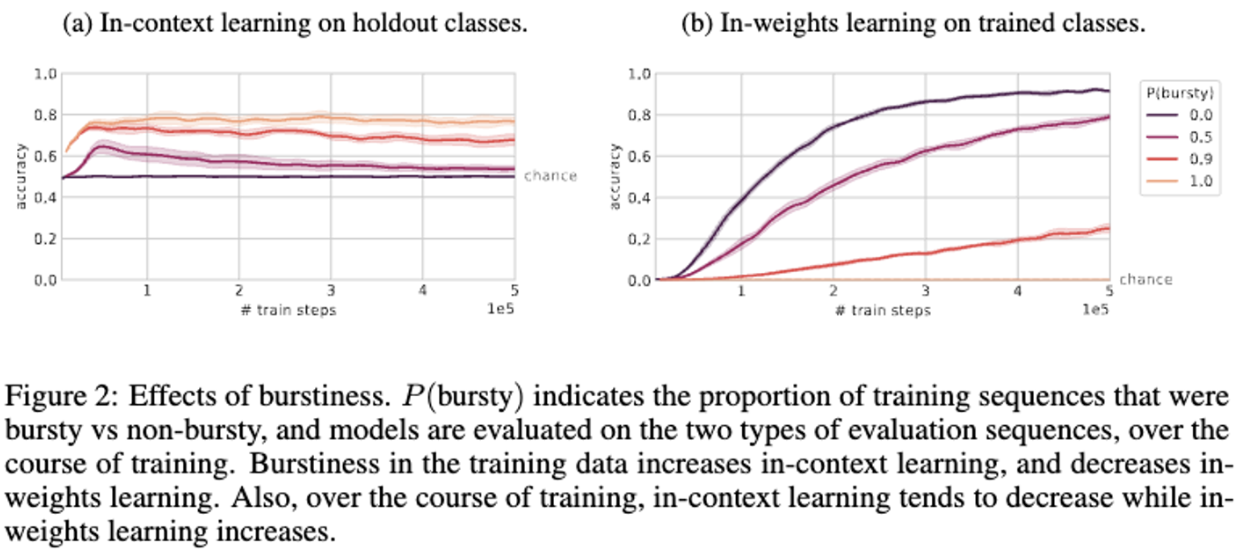
- 다양한 burstiness level을 사용하여 실험함. burstiness가 클 수록 in-context learning을 잘 수행함.
- burstiness가 작을수록 in-weight learning을 잘 수행하지 못함.
- 흥미로운 점은 모델은 경우에 따라 in-context learning 에 대한 초기 bias을 잃어 버려, 훈련 과정에서 in-weights learning으로 이동할 수 있다는 점이다.
A large number of rarely occurring classes.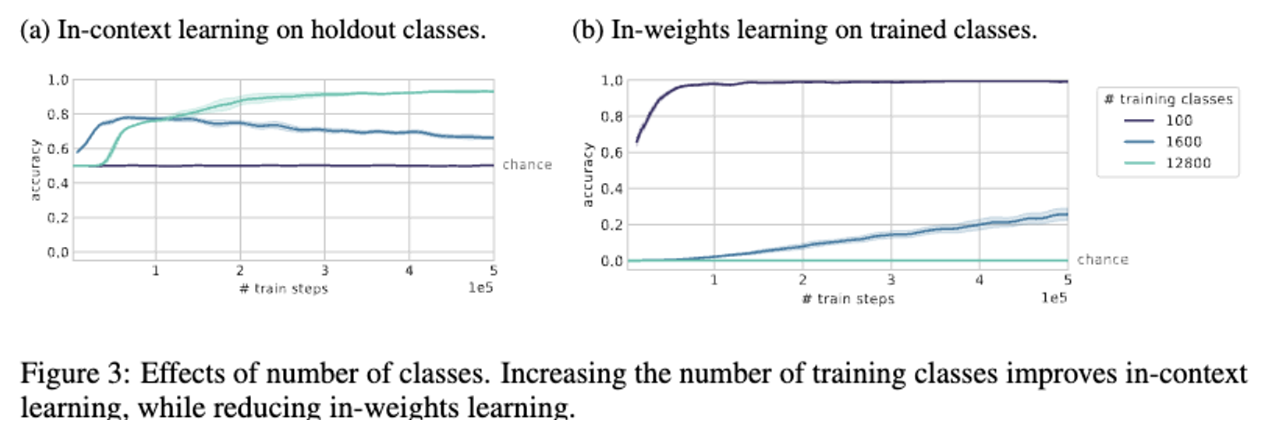
- 훈련 class에 따라서 in-context learning의 성능이 달라진다. 클래스 수를 100개에서 1600개로 늘리고, 즉 각 class의 수를 줄이면, in-context learning 의 성능이 향상되며, in-weight learning의 성능은 떨어짐. 이는 분포에서 긴 꼬리를 가지는 경우(대부분의 데이터가 드물게 발생)와, 큰 vocab size를 가지는 것이 좋을 것이라는 가정과 일치함.
- in-context learning에서 큰 burstiness 와 많은 클래스의 수가 필요하다는 것이 중요함.
- Omniglot 데이터셋에서 flip과 rotate를 적용해 8배의 더 많은 클래스를 만듬. → 이 데이터 셋은 in-context learning의 성능을 더 향상시킴. flip이나 rotate에 대해서 대칭인 것들이 있는데 이에 대한것은 아래에서 보자. → 0의 경우 flip이나 rotate 하든 말든 하나의 이미지, 같은 0이지만 다른 label로 되어있음.!!!
Multiplicity of labels.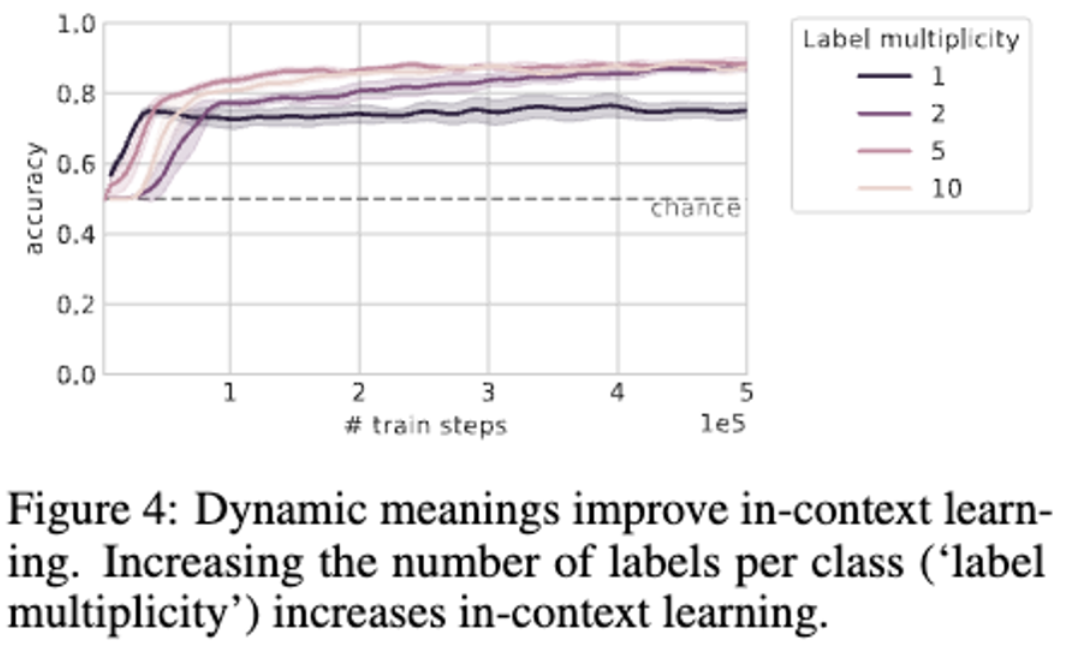
- 이미지에 완전히 fix된, 레이블이 없는 훈련 분포를 사용하여 dynamic meanings의 효과를 탐색함.
- 각 이미지 클래스는 여러 개의 가능한 레이블(0의 경우 flip이나 rotate 하든 말든 하나의 이미지, 같은 0이지만 다른 label로 되어있음.!!!)에 할당되었으며, 데이터 시퀀스에서 각 이미지 뒤에 표시되는 레이블은 가능한 레이블 중에서 무작위로 선택되었음. 클래스가 동일한 시퀀스에 두 번 이상 나타나면 해당 레이블은 해당 시퀀스 내의 모든 presentations에 대해 동일하게 사용.(이는 언어와 같은 자연 데이터에서도 흔히 발생함; Gale et al., 1992).
Within-class variation.
-
another source of dynamic variation of meaning인 image class의 variation에 대한 탐구.
-
in the lowest- variation condition에선 각 이미지 클래스는 단일 이미지로만 구성. → 특정 클래스의 이미지는 항상 동일.
-
in the medium-variation conditions에선 이미지에 가우스 픽셀 노이즈 추가.
-
In the high- varation condition에선 전체 Omniglot class사용. 각 class에서 20명의 사람들이 그린 20개의 서로다른 이미지로 구성
-
결과를 보면
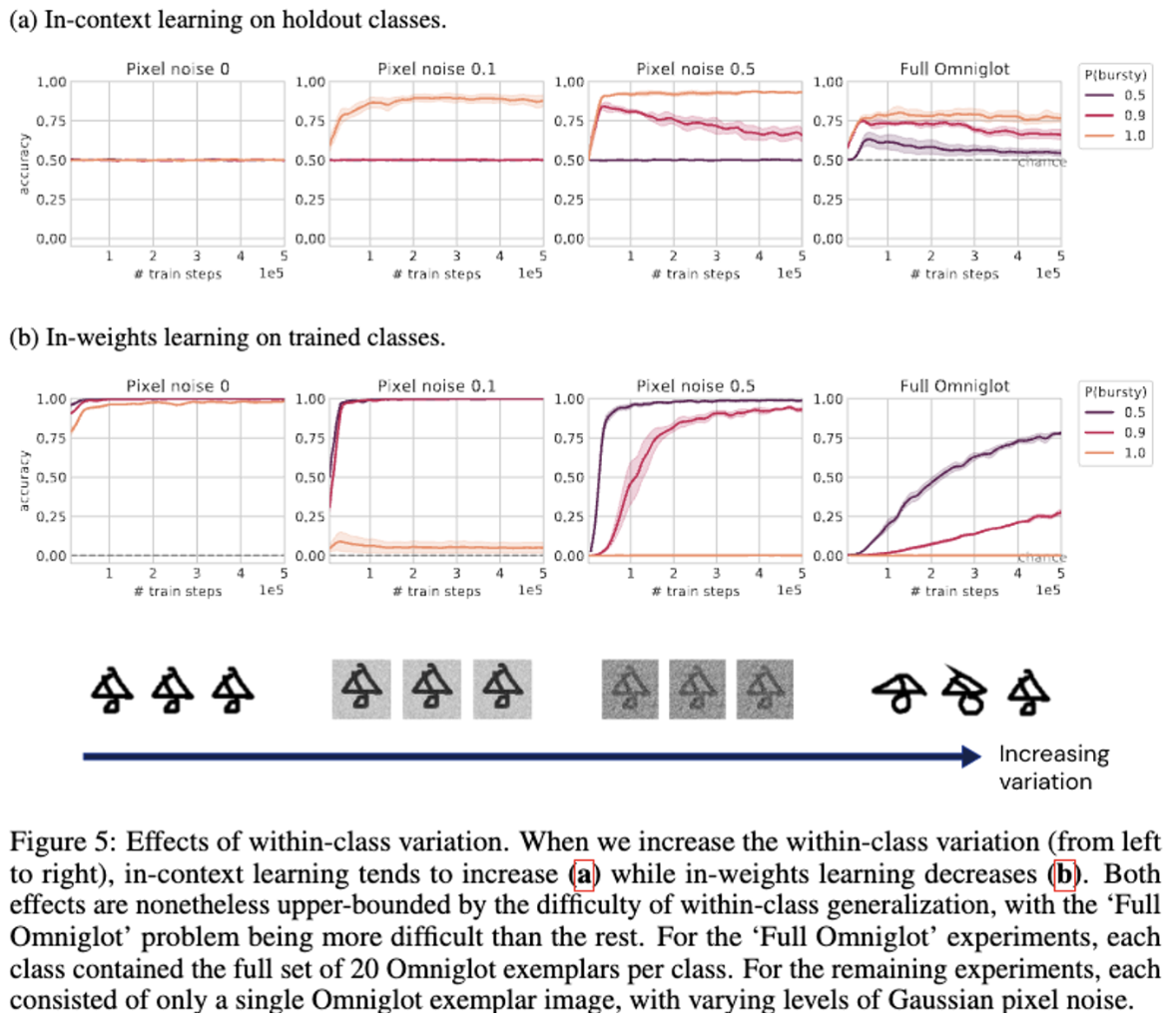
- class variation이 커질수록 in-context learning이 더 잘된다는것을 발견. → 일반화 문제를 더 어렵게 만드는 것이 in-context learning을 더 잘하게 만듬.
- 이는 in-weights learning을 더 방해함.
-
위의 실험들에서 우리는 훈련 클래스(홀드아웃 클래스가 아닌)에 대한 in-context learning 도 평가했으며, 다시 클래스를 레이블 0과 1에 무작위로 할당했음(훈련에서 본 클래스를 사용하는 대신). 평가는 모든 경우에 유사하게 보였으며 성능은 약간 더 높았음
3.2 What kinds of training data enable in-context learning and in-weights learning to co-exist in the same model?
-
지금까지는 in-context learning과 in-weigth learning의 tradeoff 를 봤는데, evaluation에 나타날 데이터와 holdout에서만 나타나는 새로운 클래스에 대해 둘다 잘 할 수 없을까?
-
데이터가 위 실험에서 marginal 분포는 전체 클래스에서 uniform이었음. 즉, 각 클래스가 데이터 세트 전체에 걸쳐 하게 나타날 가능성이 높았음. → bursty, unbursty 였지만 그럼에서 전체로 생각하면 uniform 이었음.
-
marginally-skewed distributions 에 대해 훈련하여 두가지 유형의 학습을 달성 할 수 있다고 생각했음. 이 case에서는 대부분의 단어가 드물게 나타남. → Zipfian 분포, α : zipf exponent에 따라 degree of skew 가 달라짐.
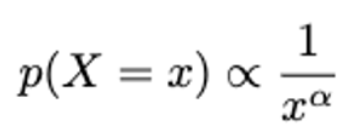
-
아래 그림 a와 b를 보자.
-
이 분포로 학습하게 되면 common class에 대해서 in-weight traning을 할 수 있는 동시에, rare class에 대해 꼬리가 긴 분포 이므로, in-context learning 을 잘 할 수 있게 된다.
-
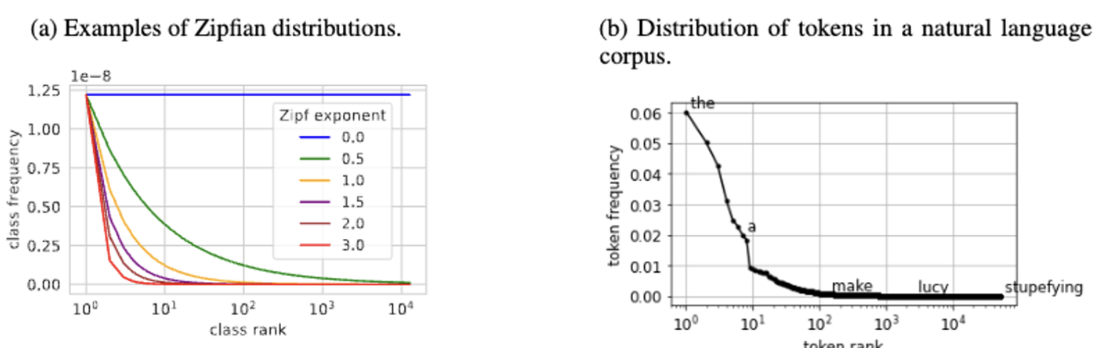
training with 12800 classes and p(bursty) = 0.9.
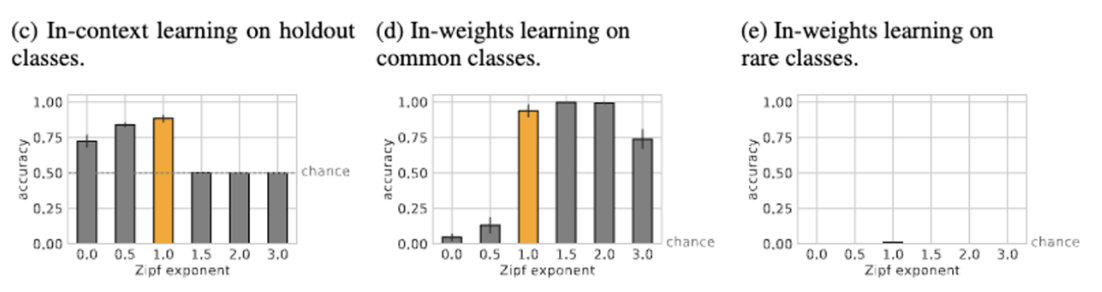
- 가장 자주 나타나는 클래스 10개를 common class로, 나머지를 rare class로.
- skew가 없을 면 in-context learning은 잘하지만, in-weights learning은 못함.
- skew가 증가하면 in-context learning이 손실되고 공통 클래스의 in-weights learning이 증가.3 두 극단 사이에는, 모델이 in-context learning과 공통 클래스의 in-weights learning 모두에서 높은 수준을 유지하는 zipf exponent = 1에서 spot이 관찰된다. 흥미롭게도 자연어는 zipf exponent가 약 1인 Zipfian distribution으로 가장 잘 설명된다.(Piantadosi, 2014). 단, 트랜스포머에서 in-weight learning과 in-context learning을 동시에 유지할 수 있는 최적점은 훈련 체제에 따라 다를 수 있다는 점에 유의.
-
3.3 But architecture does matter too.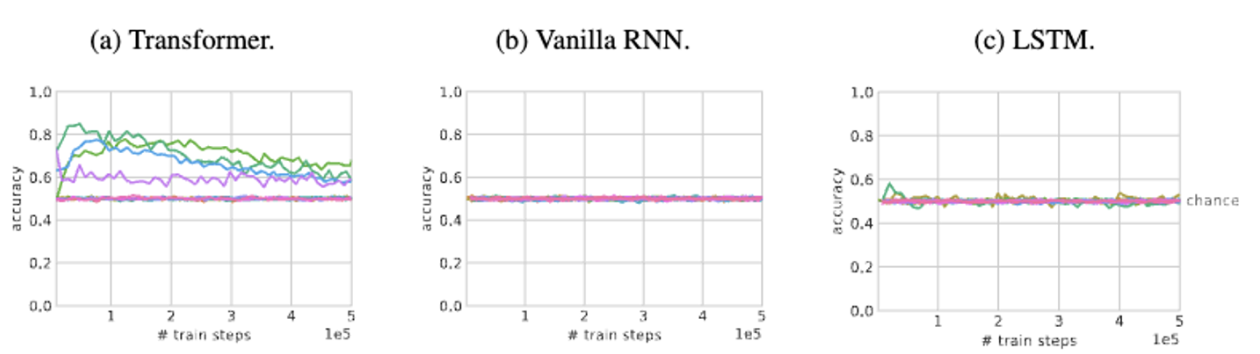
- rnn은 in-weight learning 구조에 맞춰져 있음. → 성능 안좋음.
