RAG-Sequence Model
y= target sequence, z = retrieve text documents, x = input sequence
- RAG는 유사한 retrieved document를 사용해서 전체 sequence를 생성하는 모델이다. Top-k에 대해서 probability p(y|x) 를 얻기 위하여 retrieved document를 single latent variable로 다룬다.
- 아래와 같이 각 document 별로 아래와 같이 output sequence probability를 생성한다.
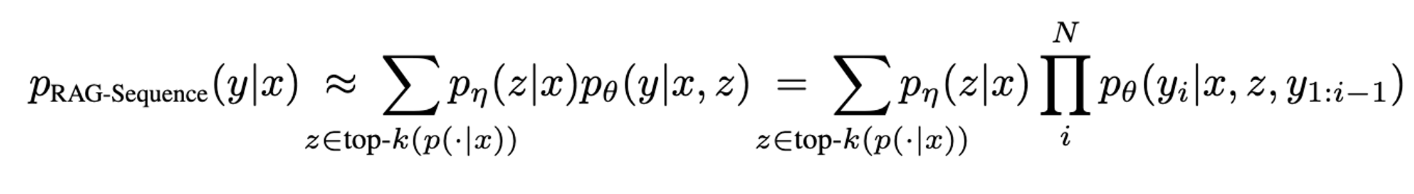
RAG-Token Model
- 각 each Token을 생성할때 각 latent document 를 사용하여 적절히 marginalize 할 수 있음. 아래와 같이 이걸 반복적으로 한다
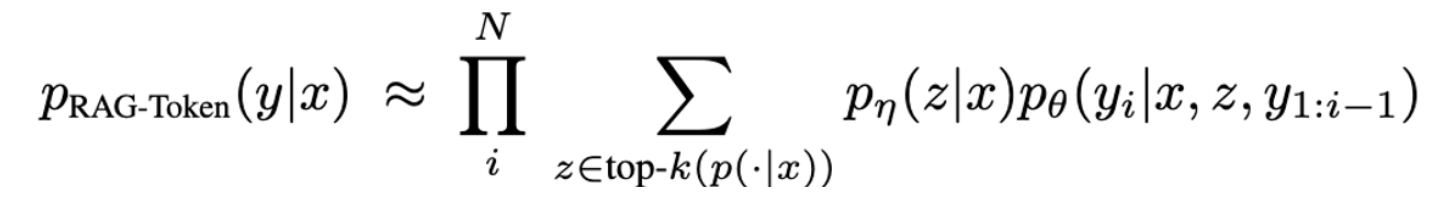
Retriever : DPR
- DPR을 기반으로 관련 문서를 찾는다. 아래와 같이 query x와 document z에 대해서 embedding d(z), q(x)를 추출하고, 내적을 통해 유사도를 구한다.
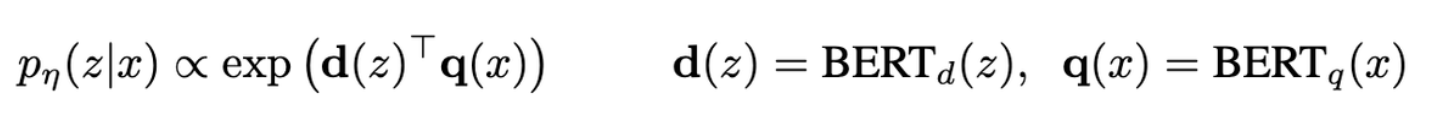
- Pre trained DPR을 사용함.
Generator : BART
-
아래 generator는 어느 encoder-decoder 모델도 사용될 수 있음. 여기선 BART 사용
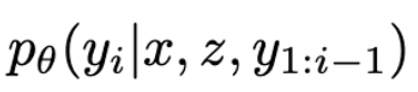
-
간단히 x와 z를 concat해서 generator BART에 넣어준다.
Training
-
어떤 문서를 retrieved 해야하는지에 대한 직접적인 supervision 없이 Retriever와 Generator를 공동으로 train한다. input x와 y가 주어지면 아래의 objective를 최소화 하도록 학습한다.
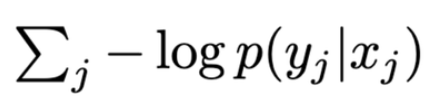
-
를 학습하는 것은 document가 너무 많기 때문에 비용이 많이든다..
-
따라서 는 freeze 하고, 와 만 학습한다.
-
이때 주어진 input X에 대해 검색된 상위 K개의 문서 (z_1, z_2, ..., z_K)만을 고려하여 이 document 들을 바탕으로 답변을 생성하고, 이때의 예측된 답변과 실제 답변(Y) 사이의 Cross Entropy를 계산하여 모델을 학습한다.

이전 tistory 블로그 주소: https://dohwai-ai.tistory.com/ tistory는 정리하기가 너무 불편해서 velog로 블로그를 이전했습니다.