LLM
1.[논문 리뷰] Data Distributional Properties Drive Emergent In-Context Learning in Transformers
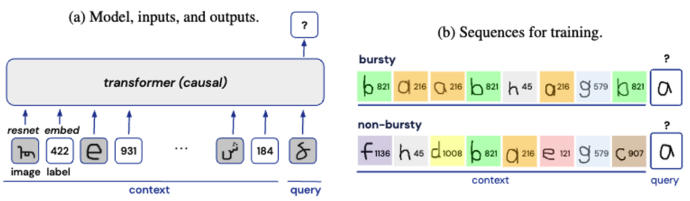
Abstract Large transformer-based models 들은 explicit한 train 없이 in-context few-shot learning을 할 수 있다. 훈련 체제의 어떠한 측면이 이러한 현상을 일으킬까? this behavior is dri
2024년 4월 7일
2.[논문 리뷰] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
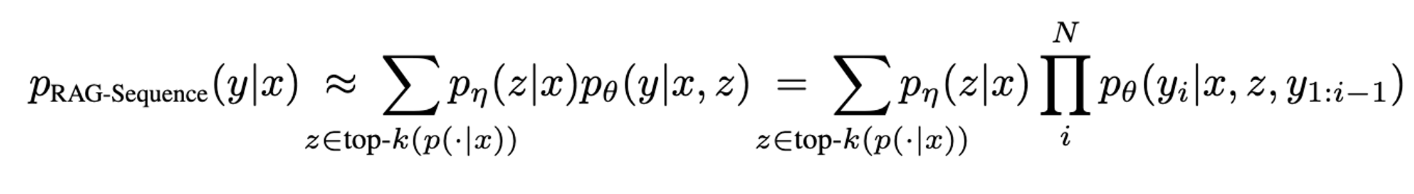
y= target sequence, z = retrieve text documents, x = input sequenceRAG는 유사한 retrieved document를 사용해서 전체 sequence를 생성하는 모델이다. Top-k에 대해서 probability
2024년 5월 13일
3.[논문 리뷰] ConvGQR: Generative Query Reformulation for Conversational Search

ConvGQR
2024년 5월 13일