0. Abstract
- conversational search에서 현재 conversational turn에서의 실제 검색 의도는 이전 대화 history에 의존한다.
- whole conversation context에서 good search query를 결정하기란 어렵다.
- 쿼리 인코더 train에는 비용이 많이 들기 때문에 rewriting model을 학습하려고 한다. 이 모델은 manual query rewriting을 흉내냄으로써 현재 query를 de-contextualize를 한다.
- 하지만 manually rewirtten query는 항상 좋은 seqrch query를 얻지 못함. 따라서 sub_optimal query 찾을 수 있는 rewriting model 학습해야함.
- search query를 향상시키는 또다른 정보는 question에 대한 potential answer이다. 이 논문에서는 Pretrained language Models (PLMs)를 활용하여 conversational query를 reformulate하는 ConvGQR 를 제안한다. 이는 query를 rewriting 용으로 쓰이거나 generating potential answers 용으로 쓰임.
- ConvGQR은 두 가지 모두를 결합하여 더나은 search query를 생성한다. 추가로 query reformulation을 retrieval task에 연관시키기 위해서 knowlege infusoin mechanism 을 제안한다. 이는 query reformulation과 retrieval 모두 최적화 한다.
1. Introduction
- Conversational search는 multi-turn conversation을 통해 complex information needs를 얻는 것을 목표로 하는 분야임. 이 분야는 interaction context를 기반으로 user의 real search intents를 결정하는 것과 good search queries를 formulate 하는 것이 주요 과제임.
- 크게 두가지 부류가 있음
- directly uses the whole context as a query, 긴 conext와 passages 사이의 연관도를 결정하는 model을 train 함. 따라서 이접근법에서 retriever 는 훈련이 필요하고 현실에서 사용하기 어려움. 현실에서 사용하기 위해선 독립적인 query 하나를 받는 retriever가 필요.
- query reformulation을 통해 de-contextualized query 를 생성하는 것을 목표로 함. 이러한 쿼리는 현실의 retrievers에 적용될 수 있음. 저자들은 이 방법에 focus on 함
- query reformulation 에는 또 두가지 type의 연구가 있었음.
- query rewriting : train the generative model to rewrite the current query to mimic the human-rewritten one.
- query expansion : context 로부터 선택된 중요한 부분을 바탕으로 현재 query를 확장한다.
위 두 분야는 두 가지의 제한 사항이 존재한다.
- Query rewriting and query expansion can produce different effects.
- Query rewriting은 모호한 query를 처리하고 missing token을 추가하는 경향이 있는 반면 query expansion은 query에 보충 정보를 추가하는 경향이 있다. 즉 다른 효과가 존재한다는 것.
- query reformulation 할 때는 위 두 효과가 모두 중요하므로 모두 사용되는 것이 좋음
-
query rewriting models는 passage ranking task과 독립적으로 human-rewritten query를 생성하도록 에 최적화되었다.
passage ranking : 수백만 개의 구절 중 주어진 질문과 관련도가 가장 높은 구절을 순위화하는 task.
- human-rewritten query에 맞게 최적화하는 것은 기존 query보단 성능이 좋지만 optimal solution이 아님. 따라서 쿼리를 reformulation 할때 직접적으로 연관 있는 ranking performance와 연관있는 추가적인 criteria를 사용하는 것이 유용하다.

- 위 그림의 왼쪽을 보면 human-rewriteen query는 crucial missing information인 “goat”를 recover 하지만, 여전히 더욱 개선이 가능하다. 즉 optimal이 아니다.
- 이 논문에서는 위 문제점을 지적하며 새로운 Generative Query Reformulation frame- work for Conversational search 인 ConvGQR 를 제안한다. → query rewriting, query expansion을 결합.
- 위 그림의 오른쪽을 보면 현존하는 방법과의 차이를 보여준다.
- ConvGQR에서는 human-rewritten queries 에 기반한 query rewriting 외에도 potential answer를 생성하는 것을 배우며 이를 query expansion에 활용함. 이 전략은 생성된 potential answer 을 담고 있는 passage는 더 관련된 passage 이라는 것에서 motivated 된다. 왜냐하면 generated answer이 정답이거나, 혹은 generated answer이 같은 passage에 존재하고 있을 수 있기 때문이다. 완벽히 이해 X
- query reformulation 모델의 train은 query rewriting and query expansion에 대한 loss의 결합으로 구성된다. 이 두 component의 학습은 knowledge infusion mechanism 을 통한 relevant passage information 에 의해 guide 되고 이는 query generation의 더 나은 search performance를 장려함.
- 저자들은 dense and sparse retriever에 대해서 실험 하여 성능이 좋음을 보여줌.
Contribution
- propose ConvGQR to integrate query rewriting and query expansion for conversational search. → 특히 PLM을 통해 생성된 potential answer를 추가함으로써 qeury expanstion이 수행된다.
- guidance of passage retrieval 를 통해 query reformulation을 최적화 할 수 있는 knowledge infusion mechanism 을 제안함.
- 2개의 off-the-shelf (기성품) retriever에 대헛 ConvGQR의 성능을 검증함.
2. Related Work
Conversational Query Reformulation
- 직관적인 아이디어는 대화형 context에서 잘 구성된 검색 쿼리를 수정하기 않고 off-the-shelf retriever에 넣어 검색할 수 있다는 것임. Query Reformulation은 Query rewriting과 Query expansion으로 나뉜다.
- Query rewriting : 사람이 작성한 쿼리를 모방하도록 rewriting 모델을 학습한다. 모호한 쿼리를 개선하고 missing element를 recover할 수 있지만, 사람이 작성한 쿼리가 항상 optimal이 아닐 수 있음. 강화학습으로 rewriting 모델을 학습할 수도 있지만 강화학습은 너무 오래 걸린다.
- Query expansion : 더 효율적이기 위해 normalization score를 통한 Query expansion 방법을 제안했지만 이는 여전히 retriever를 학습해야 한다. 초기의 Query expansion 방법들은 대화 context에서 유용한 용어를 선택하는 것에 집중한다.
- 위 두 방법 모두 retrieval results를 향상시키지만, 모두 별도로 사용되었다 ConvGQR에서는 두 방법을 통합하여 conversational query를 reformulate 함. 추가로 query reformulation과 retrieval을 연결해주는 knowledge infusion mechanism을 제안함.
Query Expansion via Potential Answers
QA 의 선행 연구에서 쿼리를 expand 하는 효과적인 방법은 answer pattern을 추출하거나, 답변이 될 수 있을만한 용어를 expansion 용어로 선택하는 것이었다. 최근 generation-augmented retrieval methods는 PLMs에서 capture한 지식을 활용하여 잠재적인 답변(expansion terms)을 생성하는 데 집중한다.
저자들은 위 idea를 conversational search에 적용함.
3. Methodology
3.1 Task Formulation
p from C for
- relevant passage : p
- large passage collection : C
- current user query : , qi given the conversational historical context
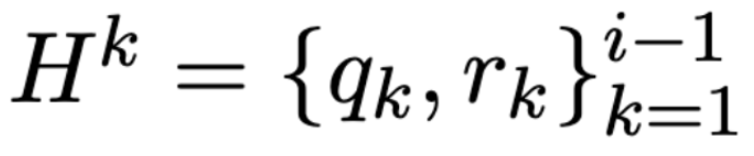
-
query and system answer of previous turn :
-
이 논문에서는 query reformulation model을 design하는 것이 목표인데, 이는 기존의 query 를 conversational historical context 와 함께 conversational search를 위한 de-contexutalized rewritten query로 변형한다.
3.2 Our Approach: ConvGQR
- query reformulation이 첫번째로 원하는 동작은 human exert와 유사한 query를 작성하는 것이다. 이는 현재 쿼리의 모호함을 일부 해결하며, query rewritten은 접근법에 필수적인 부분임.
- query rewritten은 현재 query와 과거 정보를 바탕으로 rewritten query를 생성하는 text generation으로 간주될 수 있다. 따라서 본 논문에서는 PLMs을 사용하여 인간의 query rewriting process를 모방한다.
- 하지만 human-rewritten quert는 optimal이 아니고, 표준 query rewirting models은 retirever와 독립적이라서 query writing model 만으로는 best search query를 생성할 수 없다.
- 그러므로 저자들은 관련된 passage에 포함될 가능성이 있는 additional terms를 추가하여 query를 expand하는 방안을 통합한다. 여러가지 방법 중 current query와 이 이에 해당하는 context 를 사용하여 query에 대한 potential answer을 생성한다. 이 생성된 답변은 expansion terms로 사용된다. PLM을 활용함.
- 이 생성된 potential answer는 두 가지 상황에서 passage retrieval 에 유용하다.
- 생성된 답이 정답이고, 답이 포함된 passage를 선호하는 경우.
- 생성된 답이 정답은 아니지만, 특정 passage에서 정답과 함께 존재하고 있는 경우.
- 이는 correct passage를 결정하는 데 도움을 줄 수 있으며 IR(Information Retrieval(정보 검색))에서 사용되는 query expansion approaches에서의 배경이 되는 가정이다. 이에 착안하여 다른 PLM을 사용하여 query를 확장하기 위한 potential answer를 생성한다.
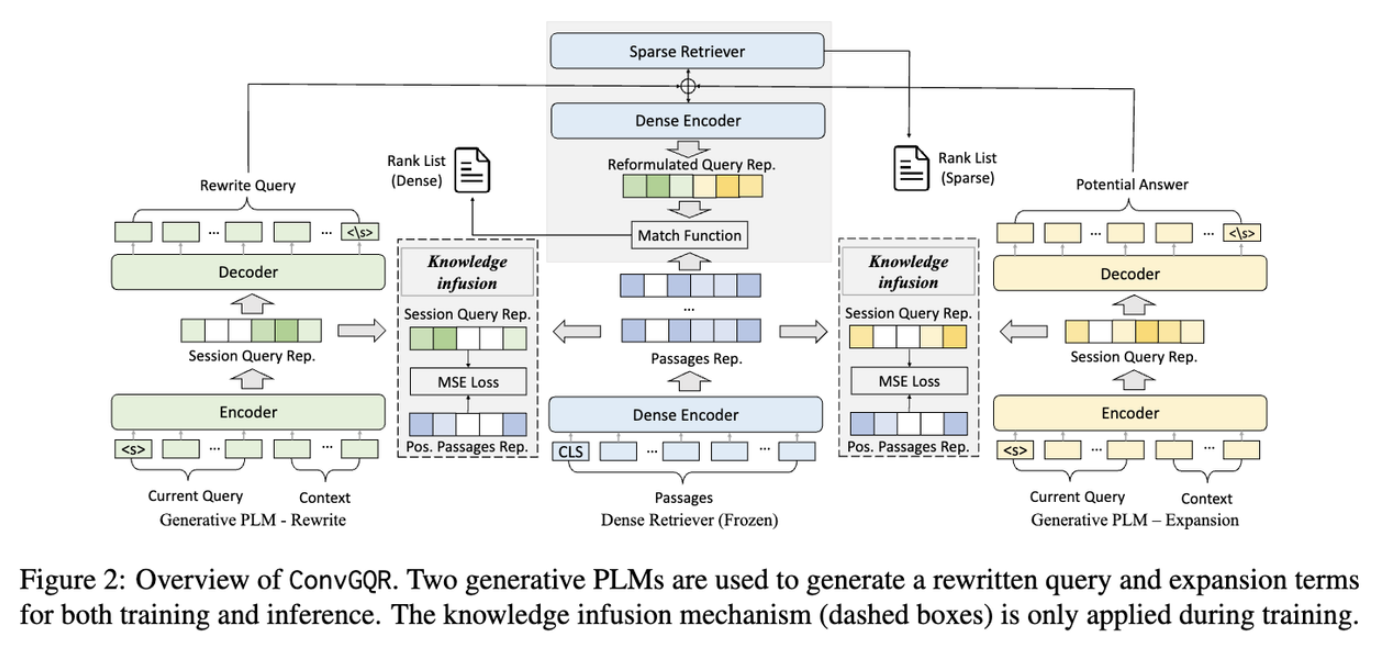
- Fig 2 를 보면 query rewriting, query expansion, and knowledge infusion mechanism의 세가지 main components로 이루어져 있다. knowledge infusion mechanism은 query reformulation retrieval을 연결한다.
3.2.1 Query Reformulation by Combining Rewriting and Expansion
- query rewriting, query expansion 모두 historical context 를 query와 concatenated 하여 input으로 사용한다. SEP을 separation token 으로 사용하여 각 turn 사이에 추가하여 아래 그림과 같이 역순으로 concatenate 한다.

Query Rewriting → human-written query를 supervision으로
- query rewriting model 의 objective 는 generative PLM을 기반으로 M(, ) = 이다. 는 supervision signal로 사용되는 sequence 임. (human-rewritten query)
- 그렇게 되면 는 없지만 에는 포함되어 있는 정보가 추가되어 에 접근 가능하다. 최족 목표는 아래 mle 를 통해 parameter 를 최적화하는 것.
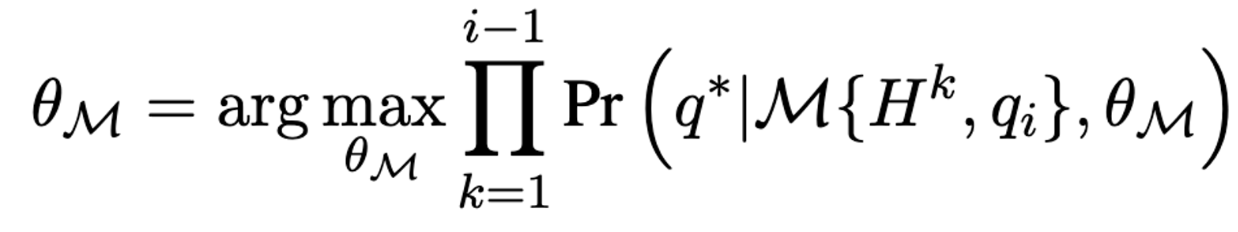
Query Expansion → 정답을 supervision으로
- 최근 연구에 따르면 PLM은 close-book question answering 시스템으로써 질문에 직접 응답할 수 있는 기능을 갖추고 있으며, 이는 생성된 답변의 정확성이 보장되지는 않지만, potential answer로써의 유용한 expansion term의 역할을 하며, potential answer 또는 simliar answer가 존재하는 passage로의 검색으로 guide할 수 있다.
- generation process를 학습하기 위해 각 query turn에서의 training objection으로 gold answer 을 활용한다. 는 데이터 세트에 따라서 short entity, consecutive text-segments, non-consecutive text-segments, 일 수 있다.
- 새로운 query를 Inference 할때에는 query expansion model에 의해 potential answer가 생성되고, 이는 이전에 rewritten 되었던 쿼리를 확장하는데에 사용된다.
- reformulated query의 최종 형태는 rewritten query와 generated potential answer를 concatenation 한 형태이다. rewriting and expansion 에 사용되는 두개의 PLMs는 target과 input sequence을 일치시키기 위해 negative log-likelihood에 의해 fine-tuned 된다. (각 모델에서 훈련 데이터는 다르다)
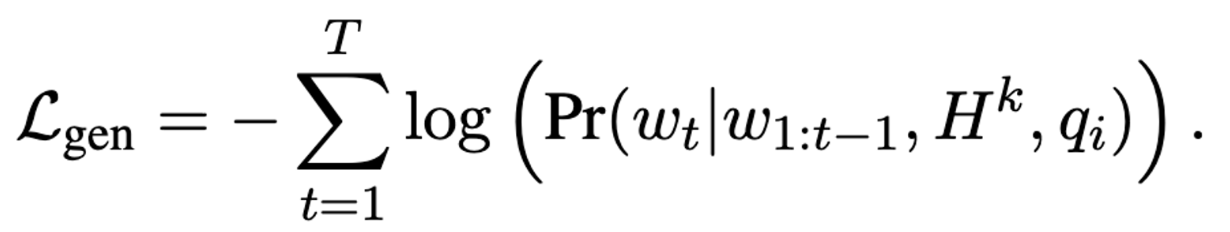
3.2.2 Knowledge Infusion Mechanism
- 기존의 generative conversational query reformulation method의 중요한 한계점은 generation과 retrieval의 의존성을 무시하여 독립적으로 학습 된다는 것이다. 본 논문에서는 knowledge infusion mechanism 를 제안하여 query reformulation과 search(retrieval) task를 함께 optimize 한다.
- generative model이 relevant passage와 관련된 query를 생성하도록 하는 것이 intuition 하다. 만약 generative model의 hidden state에 relevant passage에 대한 정보가 포함되어 있다면, 이러한 표현을 통해 생성된 query는 semantic similarity의 증가로 search results를 개선할 수 있을 것이다.
- 따라서 PLMs를 파인튜닝 할때 relevant passage 표현의 정보를 query representation에 주입하는 것이다. 구체적으로 관련 구절에 대한 representation 를 생성하는 인코더 역할을 하는 off-the-shelf retriver를 개발한다.
- 일관성을 유지하기 위해 retriever는 검색할때와 같은 것을 사용하며, 따라서 passage의 representation은 query reformulation과 retrieval 단계에서 동일하게 유지된다.
- 먼저 query representation 가 gernerative model에 의해 인코딩 되면, 의 정보를 증류하며, 아래 수식과 같이 MSE를 최소화하며 에 주입한다. , 모두 seqnece의 첫번째 토큰인 CLS 토큰을 의미한다.
- 최종적으로 은 아래와 같이 generation loss 과 retrieval loss 으로 구성된다. 는 하이퍼 파라미터.
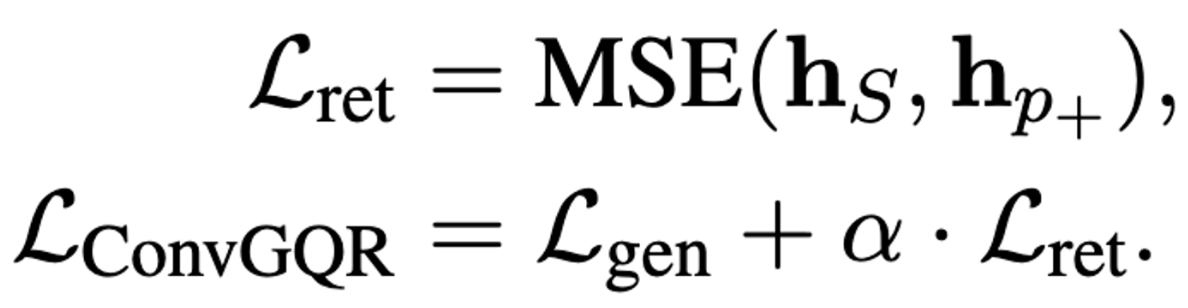
3.3 Training and Inference
- query rewriting과 query expansion을 위한 두개의 LLM이 별개로 학습된다.
- ConvGQR의 최종 출력은 rewritten query와 generated potential answer를 concatenation 한 것이다. knowledge infusion mechanism은 generation과 retrival에 동시에 최적화 될 수 있도록 훈련시에만 사용된다.
- dense retriever는 train과정에서 passage를 encode하기 위해 frozen된다.
3.4 Retrieval Models
- sparse, dense retriever 모두 사용함. dense는 ANCE, sparse는 BM25 사용.
4. Experiments
Datasets
학습 시 TopiOCQA, QReCC 사용. TREC CAsT 를 평가시에 사용.
Evaluation Metrics
- retrieval results를 평가하기 위해 MRR, NDCG@3, Recall@10, Recall@100을 사용.
Baselines
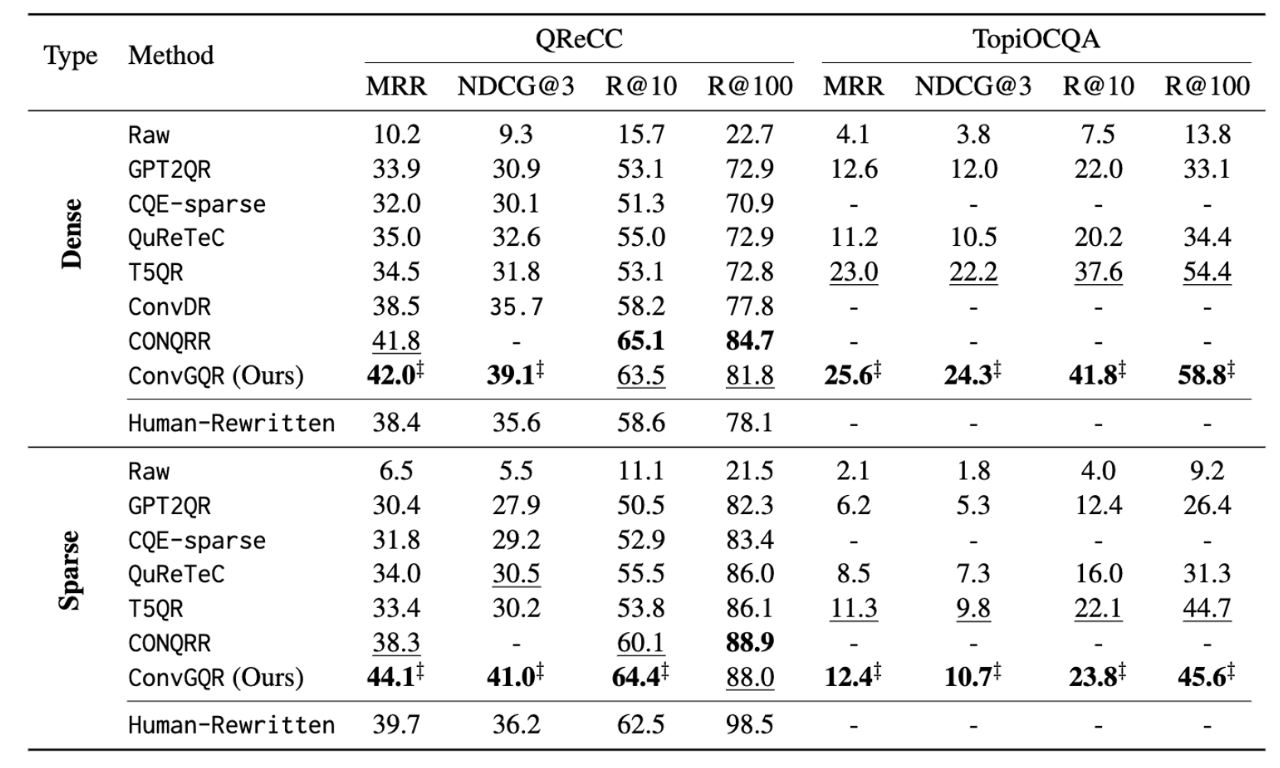
- both dense and sparse 에 대해서 ConvGQR과 query reformulation (QR) baselines retrieval 모델들을 비교.
- Raw : query 재구성 없음
- GPT2QR : strong GPT2 based QR model
- CQE-sparse : context에서만 중요한 토큰 선택하는 weakly-supervised method.
- QuReTeC : historical context 에 포함된 각 term이 현재 query에 추가되어야 하는지를 결정하는 sequence tagger를 학습하는 weakly-supervised method.
- T5QR : strong T5 based QR model
- ConvDR : rewritten query representation과 historical context representation 사이의 knowledge distillation 을 활용한 하여 search retriever fine-tuned한 strong ad-hoc search retriever
Implementation Details
- T5-base 모델을 기반으로 ConvGQR을 위한 PLMs를 구현한다. dense retriever 를 frozen 하여 passage encoder의 역할만 한다.
- zero-shot scenario 에서는 QReCC에 대해서 학습한 generative Models를 사용하고, dense retrieval 과 sparse retrieval 은 각각 Faiss와 Pyserini 를 사용함
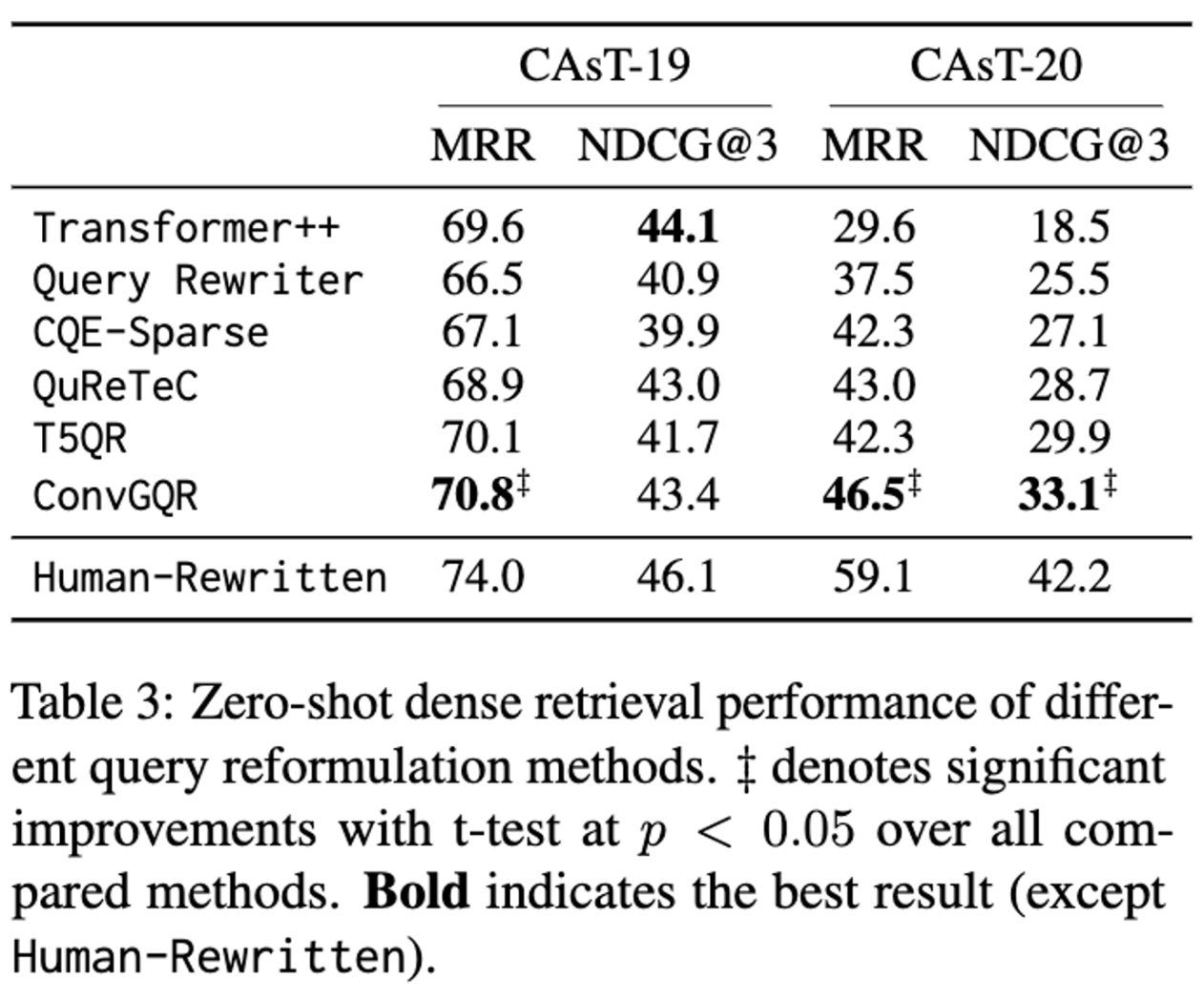
4.1 Main Results
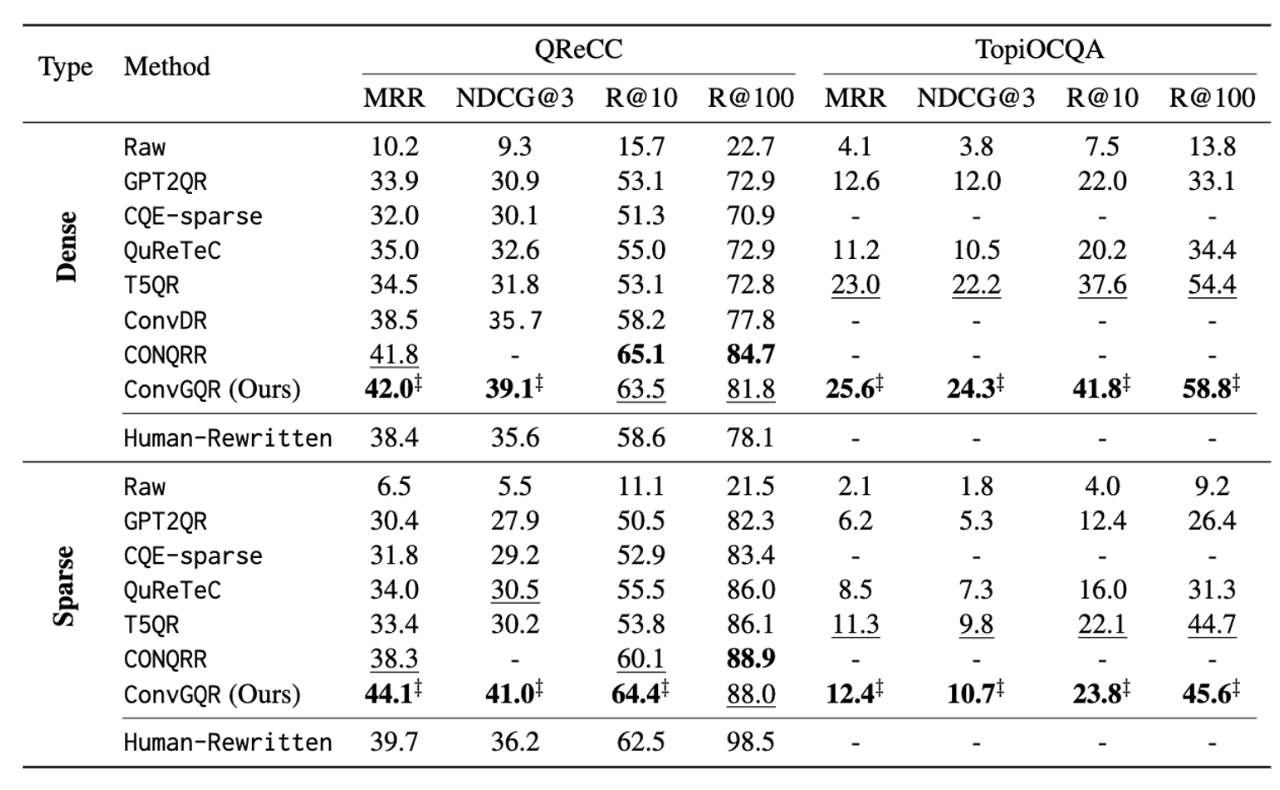
- human-rewritten 보다 성능이 높다는 것을 볼 수 있음.
- ‡ denotes significant improvements with t-test at p < 0.05 over all compared methods (except CONQRR)
4.2 Ablation Study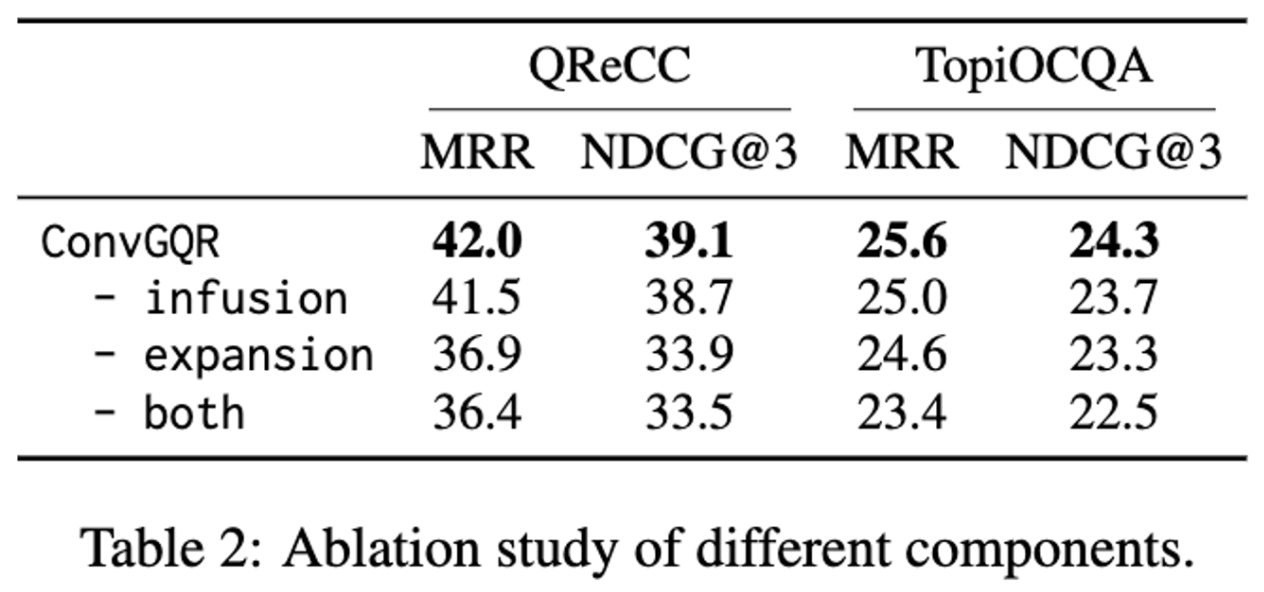
- infuse : Knowledge Infusion Mechanism
- expansion : query expansion + rewriting
4.3 Zero-Shot Analysis
4.4 Impact of Generated Answer for Retrieval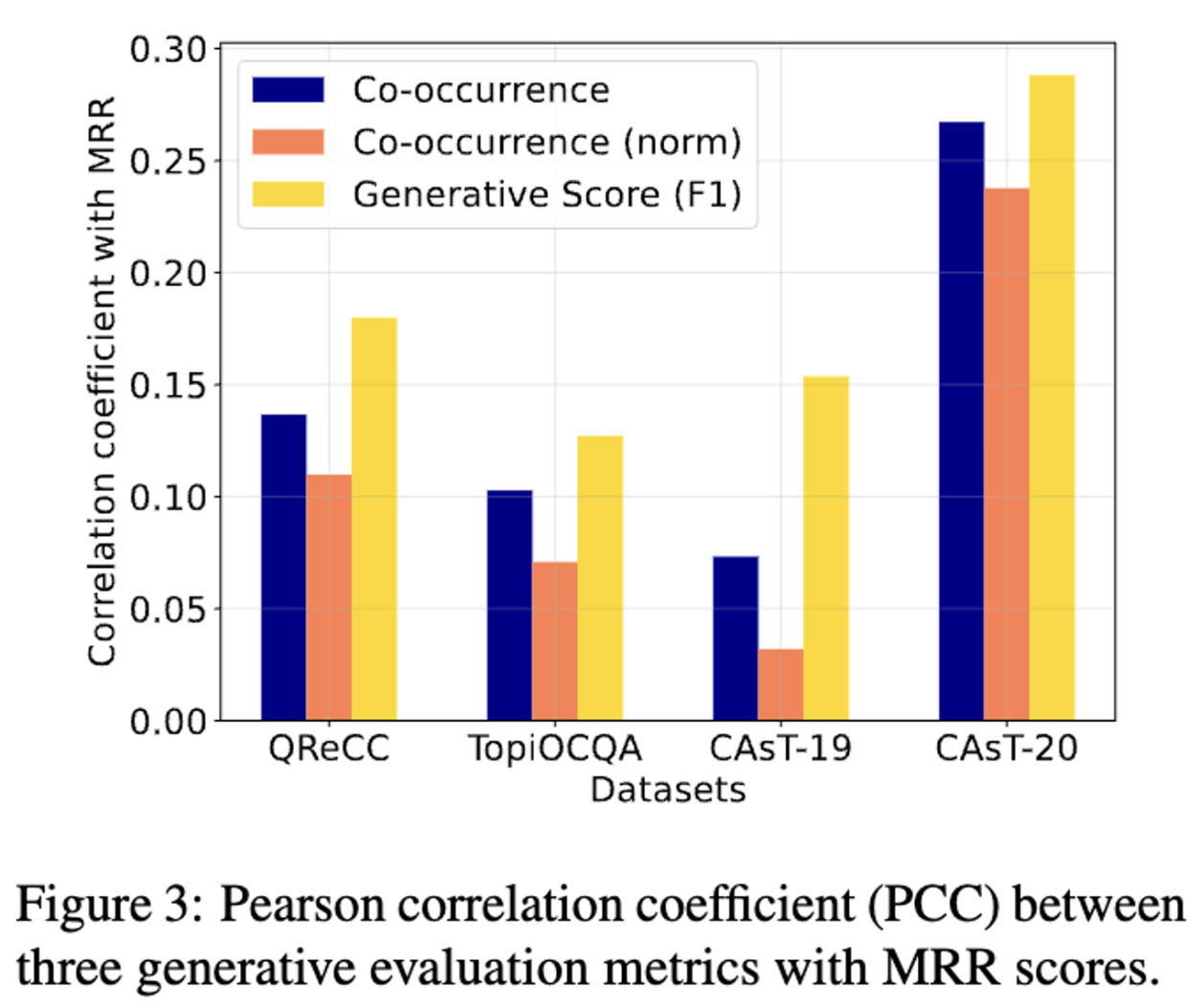
- potential answers가 실제 answer 과 관련된 passage와 유용한 expansion terms을 포함하고 있다는 가설을 했는데 이를 검증하기 위한 실험. token overlaps 를 계산, 생성된 답변의 길이가 다르기 때문에 길이로 normalization을 해줌. 생성된 답변과 gold 답변에 대해서 F1 계산.
- 피어슨 상관계수가 QReCC와 CAsT20에서 TopiOCQA, CAsT-19 보다 더 좋은데 이는 이전에 보여줬던 실험에서의 결과와 동일하며, generated answer와 relevant passage 간의 co-occurrence는 중요하다고 볼 수 있다.
Effects of Different Generated Forms
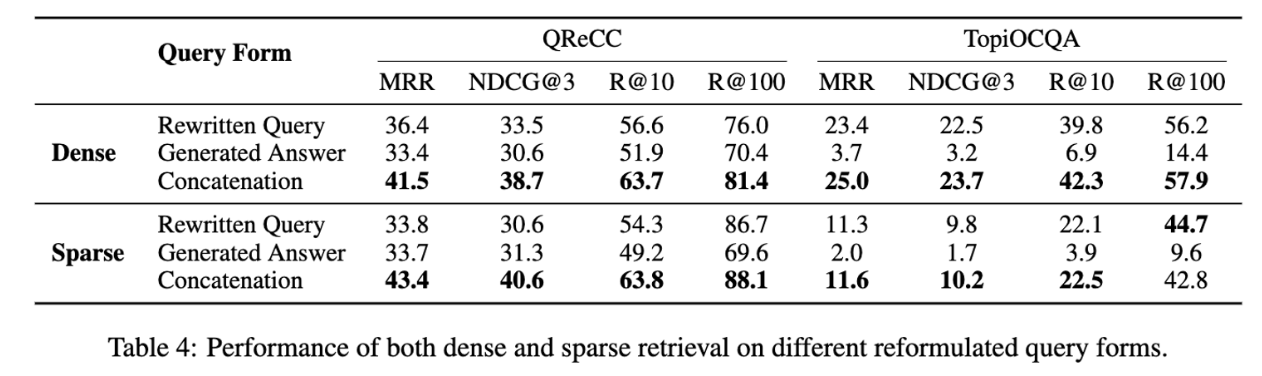
- Rewritten Query, Generated Answer 보다 concat 하는 것의 성능이 좋다.
- QReCC 보다 TopiOCQA에서 특히 Rewritten Query 방법이 Generated Answer 방법보다 좋은데, 이는 TopiOCQA에 비해 QReCC에 더 사실적인 질문이 포함되어 있는데, 사실적인 질문이 아닌 경우 PLM이 potential 답변을 생성하기 어렵기 때문이다.
4.5 Impact of Knowledge Infusion Loss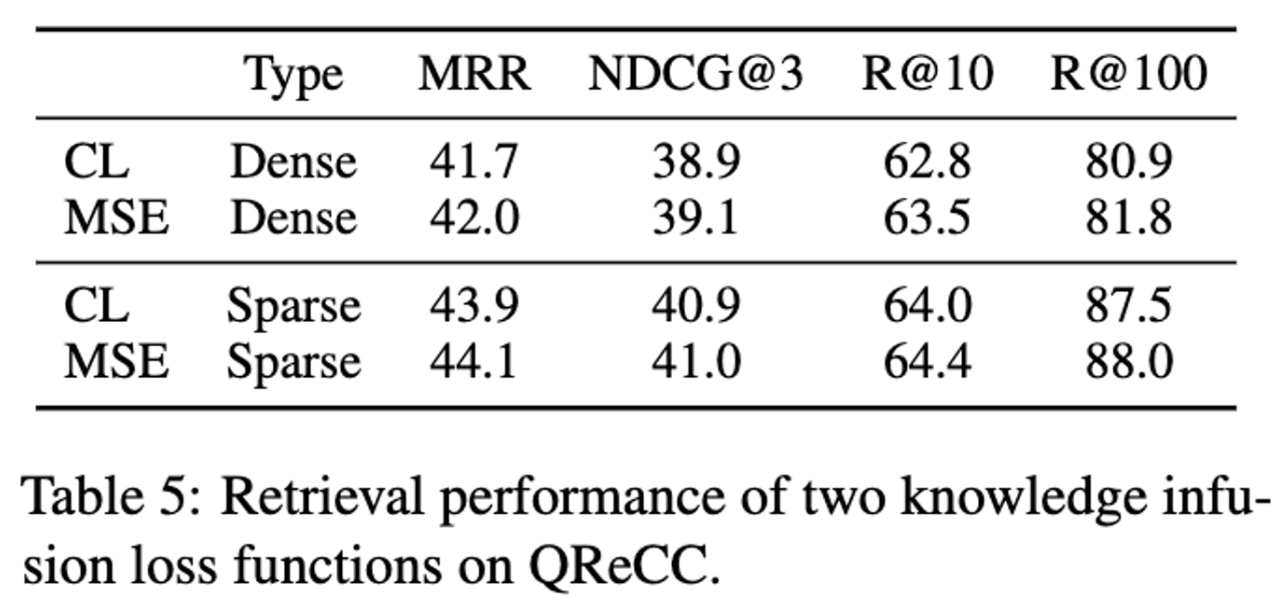
- contrastive learning (CL) 보다 MSE가 더 좋다.
5. Conclusion
Limitations
- query rewriting괴 query expansion 를 위한 서로 다른 데이터 학습된 두개의 PLMs가 필요하므로 추가적인 cost가 필요함. 저자들은 이를 통합하는 모델을 만드는 것이 개선점이라고 생각함.
- expansion term은 generative PLMs에만 의존하는 것이 아닌, (pseudo-relevant feedback and knowledge graph : 문서들간의 어떤 관계에 대해서 말하는 것이라고 이해.. ) 과 같은 다른 리소스 들에서 생성될 수 있다는 것.
- knowledge infusion 에 대한 더 다양한 방법을 시도 할 수 있을 듯.

이전 tistory 블로그 주소: https://dohwai-ai.tistory.com/ tistory는 정리하기가 너무 불편해서 velog로 블로그를 이전했습니다.