Mutual infomation score(MI)
Using MI for feature selection
copy_feature = feature.copy()
mi_result = []
# object feature 임시 encoding -> MI 계산을 위해
for col in feature.select_dtypes('object'):
# object feature column만 factorize()
copy_feature[col], _ = copy_feature[col].factorize()
mi_score = mutual_info_regression(copy_feature,target, random_state=0)
series_mi_score = pd.Series(
mi_score,name='Mutual Information Score'
index=feature.columns
)
# Series -> sort_values (MI 높은 순으로)
series_mi_score = series_mi_score.sort_values(ascending=False)
print(series_mi_score)-
select_dtype('data type')
ex)
- data type -> object.
- object feature들을 반환한다.
-
factorize()
- object feature를 enumerated type이나 categorical variable으로 encoding.
-
mutual_info_regression
- 연속형 data에 대한 MI score를 계산.
- 자매품 mutual_info_classif도 있다.
-
code and result
R2 -> 0.77
cross_valid_score을 이용한 model accuracy mean -> 65.5%
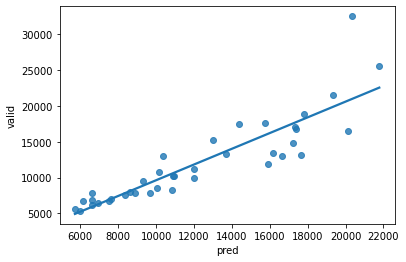
-
All Result IN My kaggle

#ChrisBumsteadFan