현재 Transformer 모델은 Bert, GPT의 기본적인 Architecture로 활용되고 있으며, 대용량 데이터를 한번에 처리할 수 있는 강점을 가졌습니다. 시계열 분야에 국한되지 않고, Computer Vision분야에서도 SOTA를 차지하고 있는 모델의 대부분이 Transformer 계열의 모델이기 때문에 해당 모델들의 기초가 되는 Transformer모델의 review를 진행하겠습니다.
(개인적인 공부를 진행하면서 정리한 내용이기 때문에 부족한 부분이나 틀린 부분이 있다면, 피드백 부탁드립니다.)
서론
Transformer 이전
-
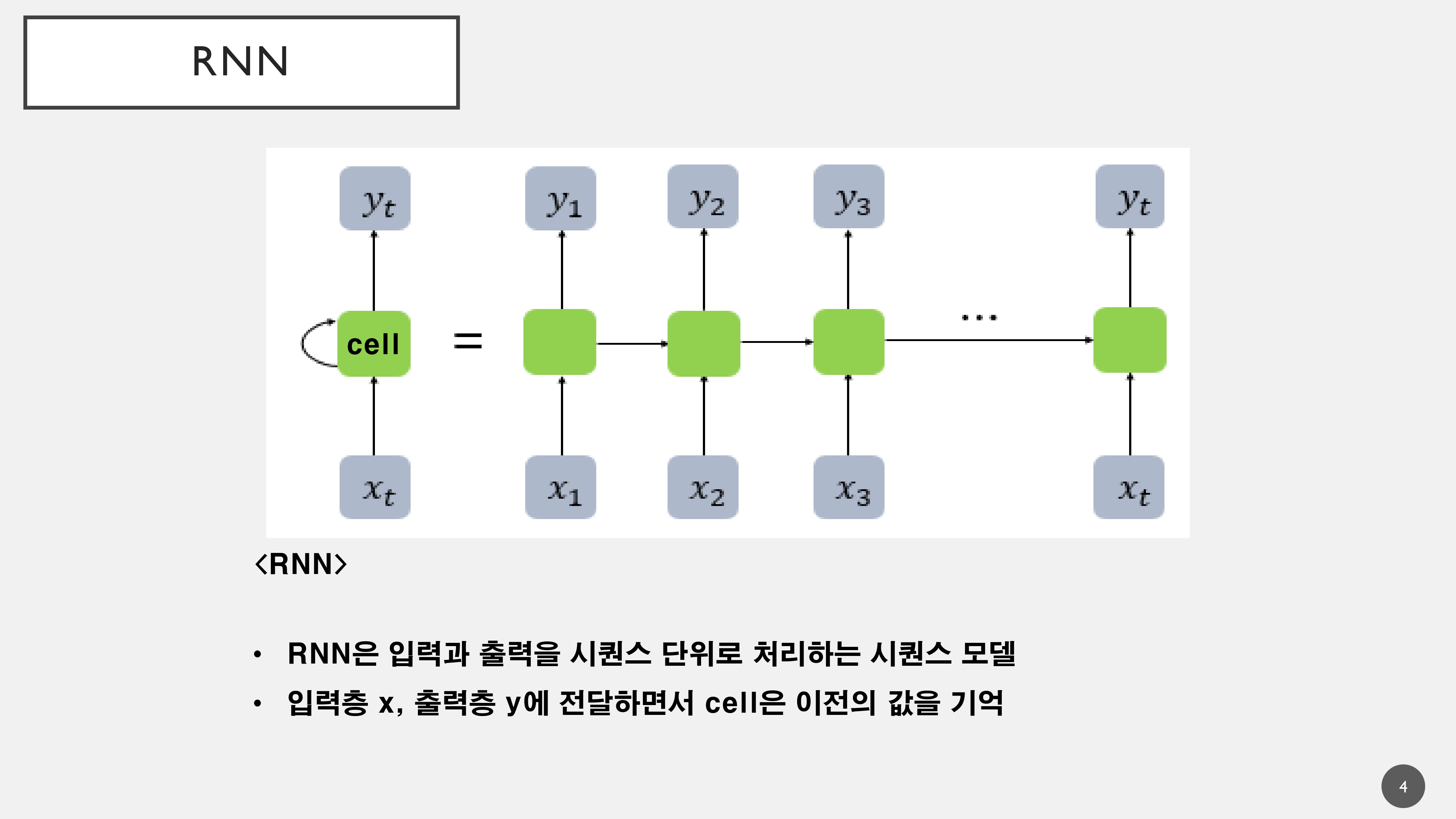
순환신경망(Recurent Neural Network)은 기존의 언어 모델링 및 기계 번역에서 주요한 역할을 해왔음
-
하지만, 병렬처리가 어렵고 Cell이 이전의 값을 기억하기 때문에 장기기억으로 넘어갈 경우 성능이 떨어지는 문제가 발생하였음
-
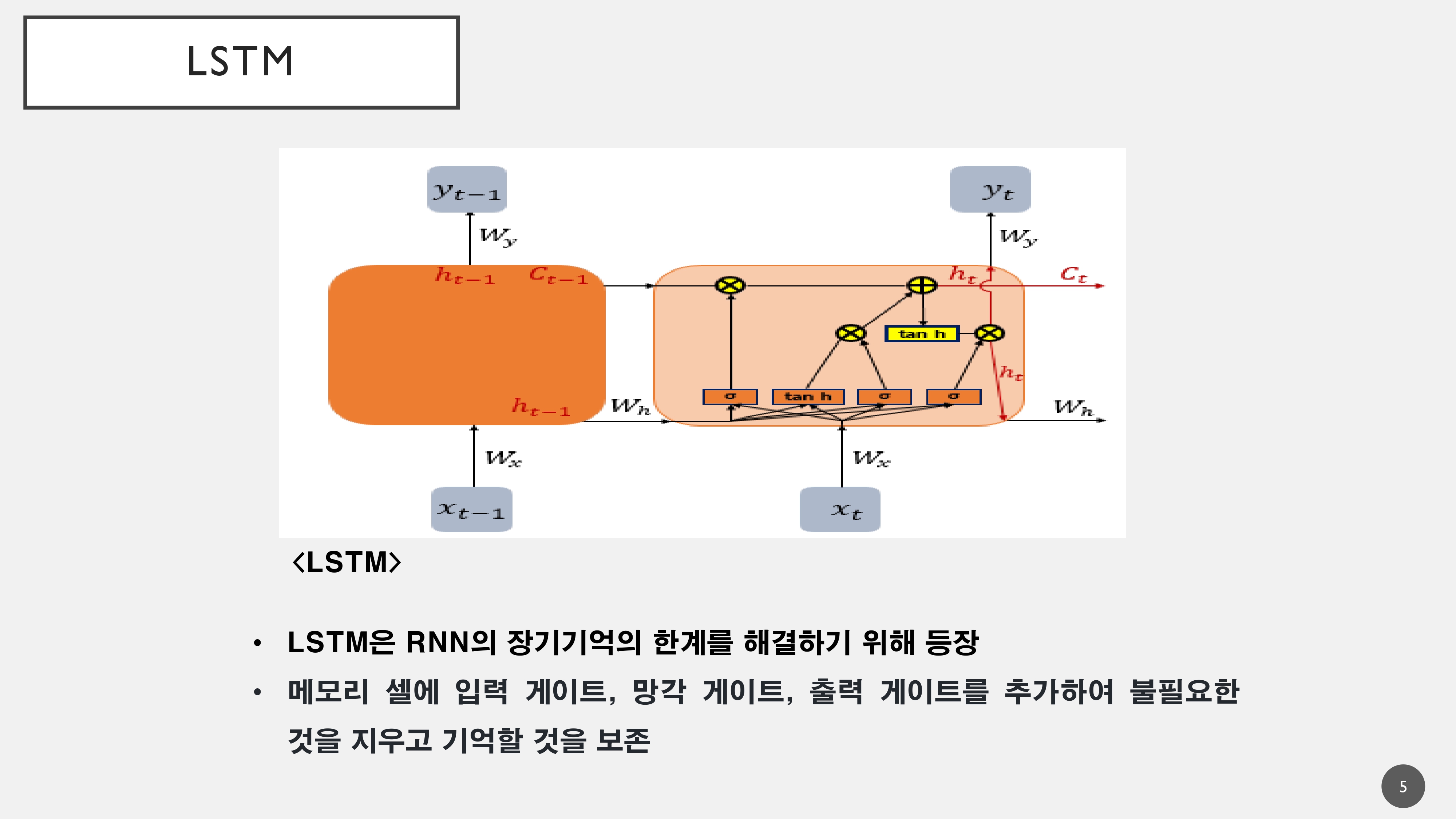
RNN이 가지는 장기기억의 고유한 문제를 해결하기 위해서 Memory Cell에 입력 게이트, 망각 게이트, 출력 게이트를 추가하여 불필요한 내용을 지우고 필요한 내용을 보존하면서 장기기억의 문제를 해결하였음
- 하지만, LSTM의 경우에도 언어 번역에 있어서 길이가 맞지 않는 경우 제대로 처리하기 어려운 문제점이 존재하였음
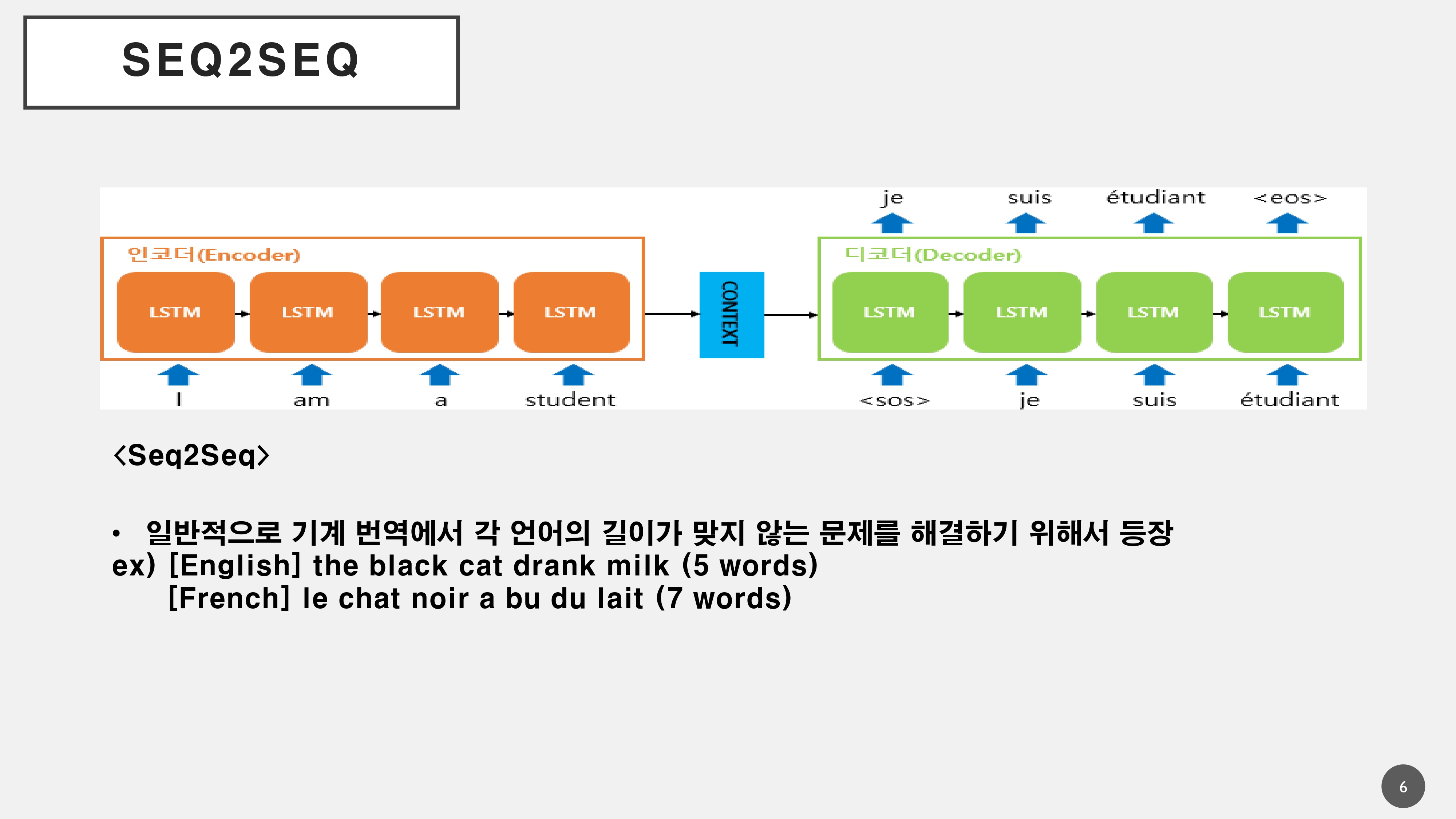
- 이러한 문제를 해결하기 위해서 Seq2Seq를 활용하여 언어의 길이가 맞지 않더라도 시작에 있어 (sos)와 끝의 (eos)를 추가하여 번역을 할 수 있도록 하였음
ex)
[영문] The Black cat drank milk --> 5단어
[불문] le chat noir a bu du lait --> 7단어
[국어] 검은 고양이 우유를 마셨다 --> 4단어
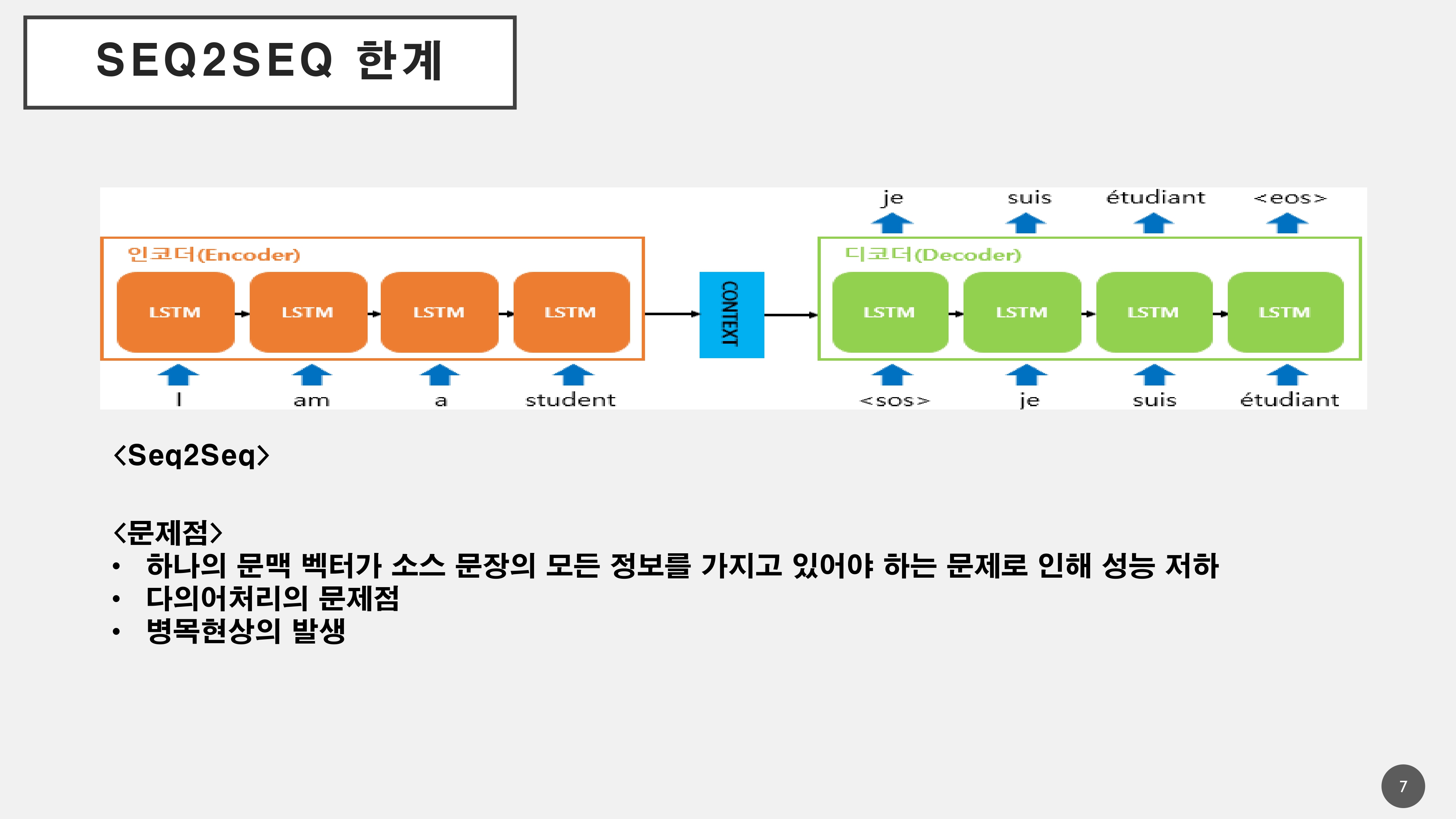
- 하지만, 이 또한 하나의 Context Vector가 소스 문장의 모든 정보를 담고 있기 때문에 병목현상이 발생하여 성능저하 문제가 발생하게 됨
- 다의어처리의 문제점이 존재
ex) 배를 먹었더니 배가 아프다.
먹는 배를 먹었더니 내 배가 아픈건가? 아니면 타는 배를 타고 먹는 배가 아픈가?에 대해 사람은 먹는 배를 먹고 사람의 배가 아프다를 인지하지만, 기계는 이를 인지하기 어려운 문제가 존재한다.
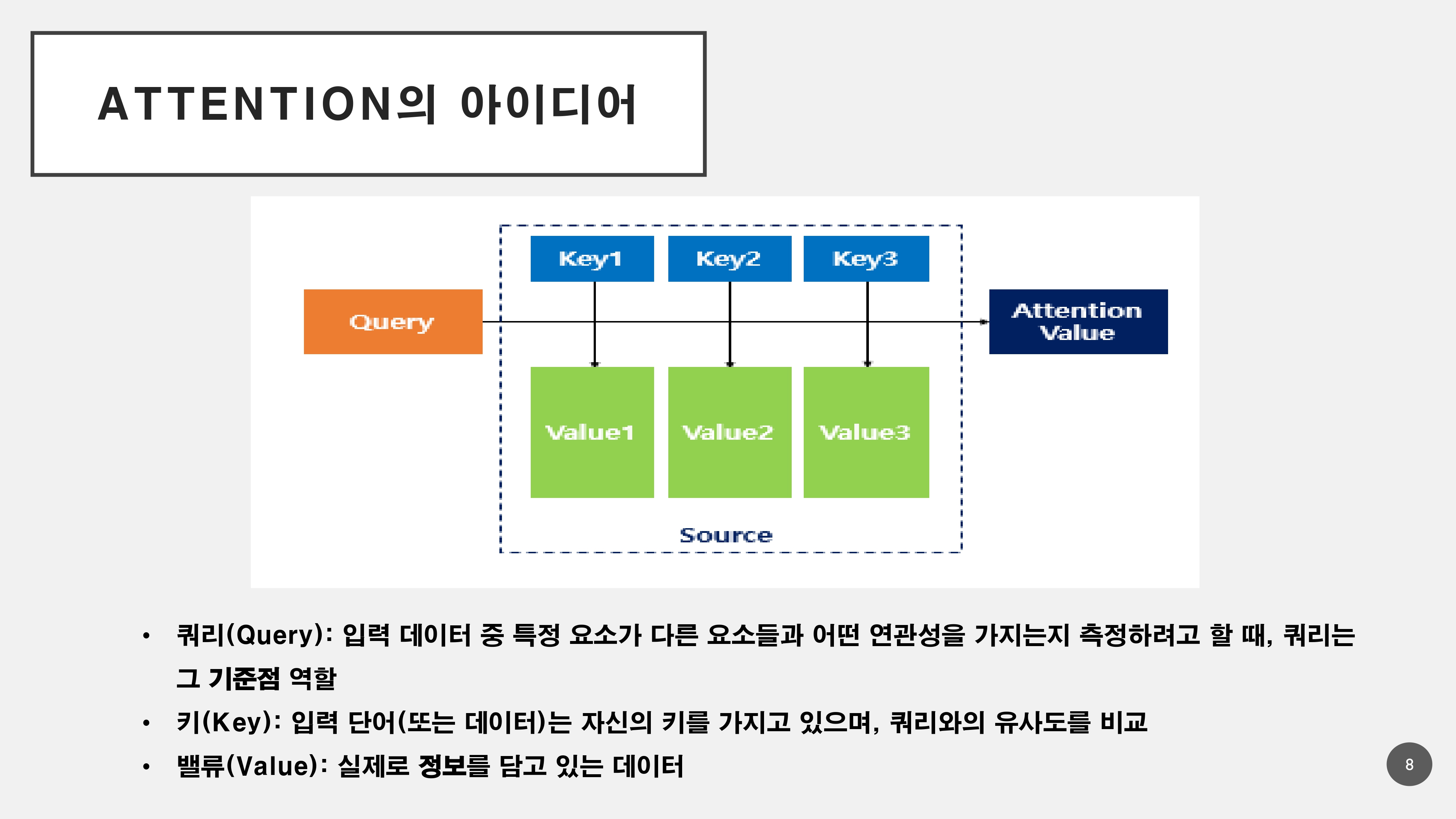
이러한 문제들을 해결하기 위해서 Atention 메커니즘으로 단어와 단어의 연관성을 파악하기 위해 Q, K, V로 나누어서 메커니즘이 진행된다.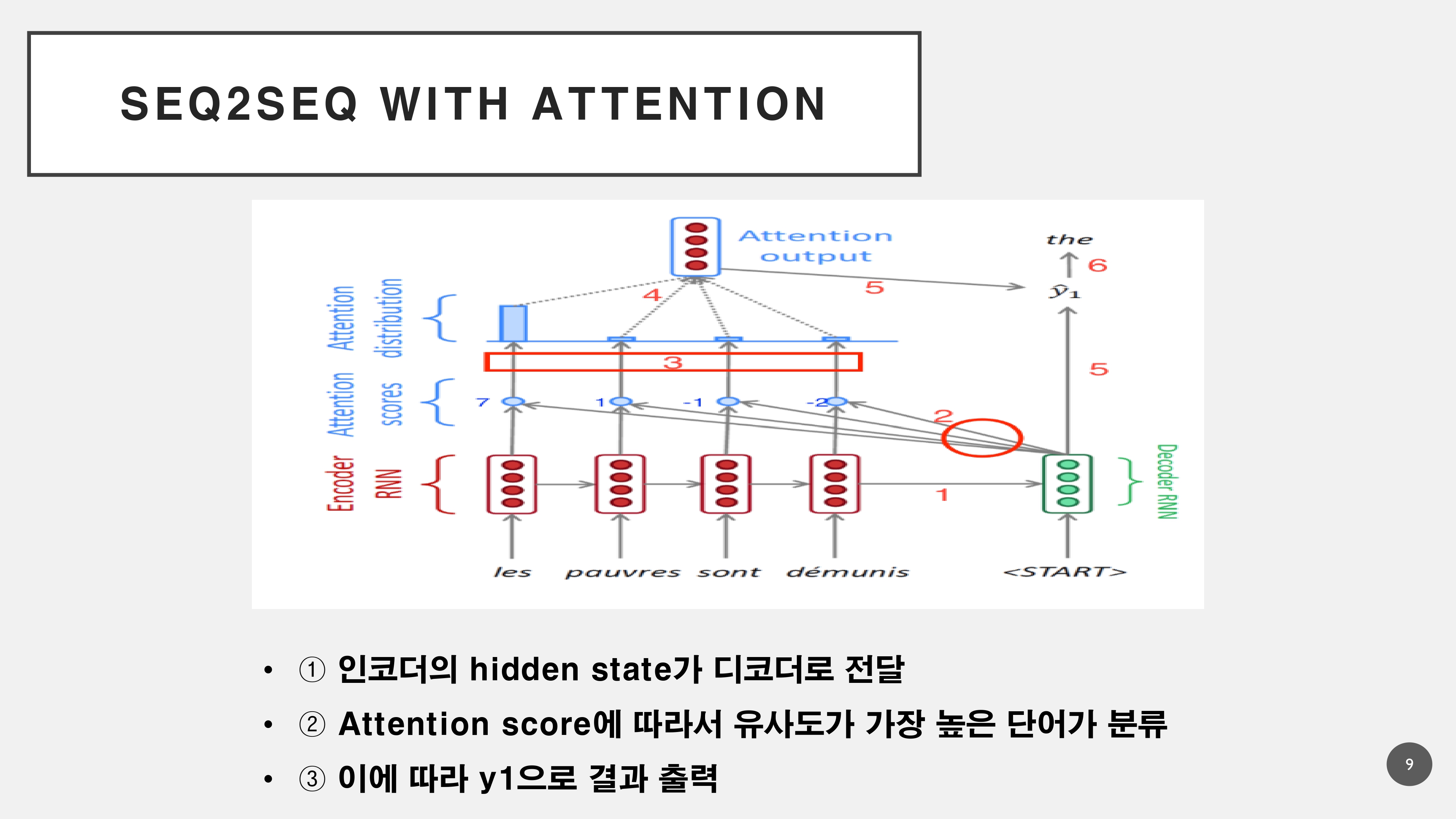
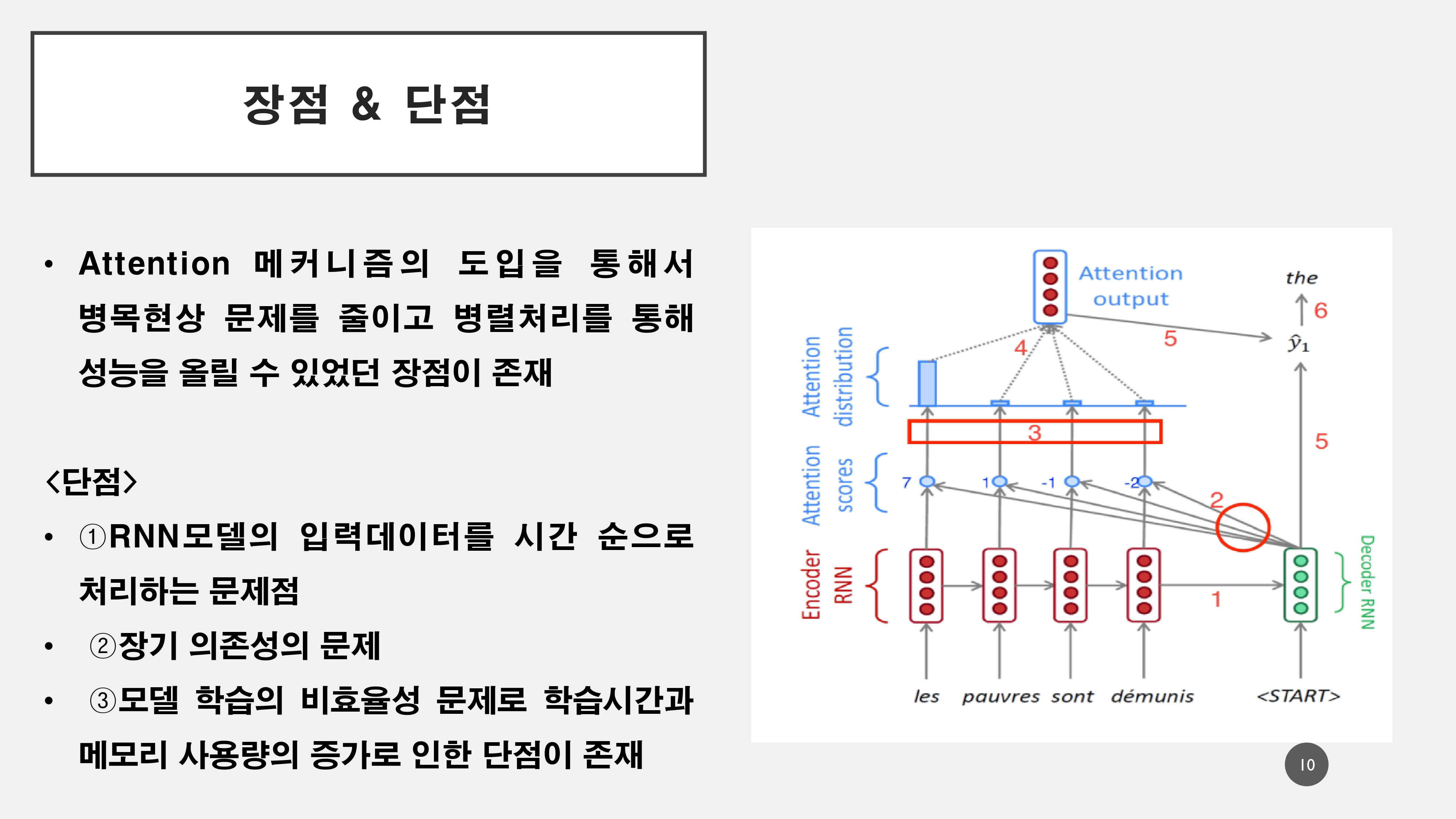 이러한 Attention 메커니즘을 도입하여 등장했던 것이, Seq2Seq & Attention 모델로 RNN모델이 가지는 고유한 문제점으로 인해서 Transformer모델로 대체된다.
이러한 Attention 메커니즘을 도입하여 등장했던 것이, Seq2Seq & Attention 모델로 RNN모델이 가지는 고유한 문제점으로 인해서 Transformer모델로 대체된다.
모델 구조
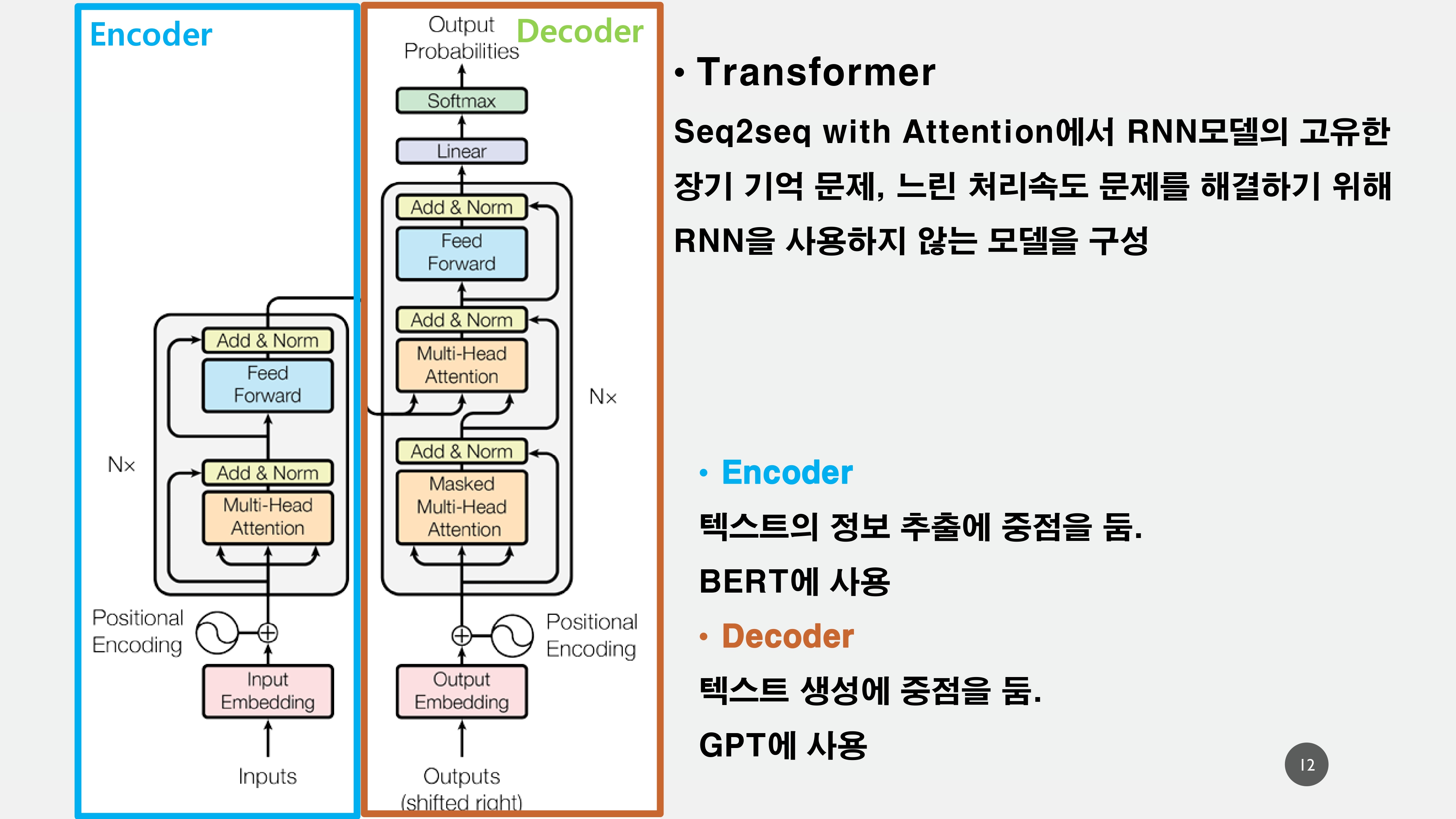
전체적인 Transformer model의 구조는 위와 같다.
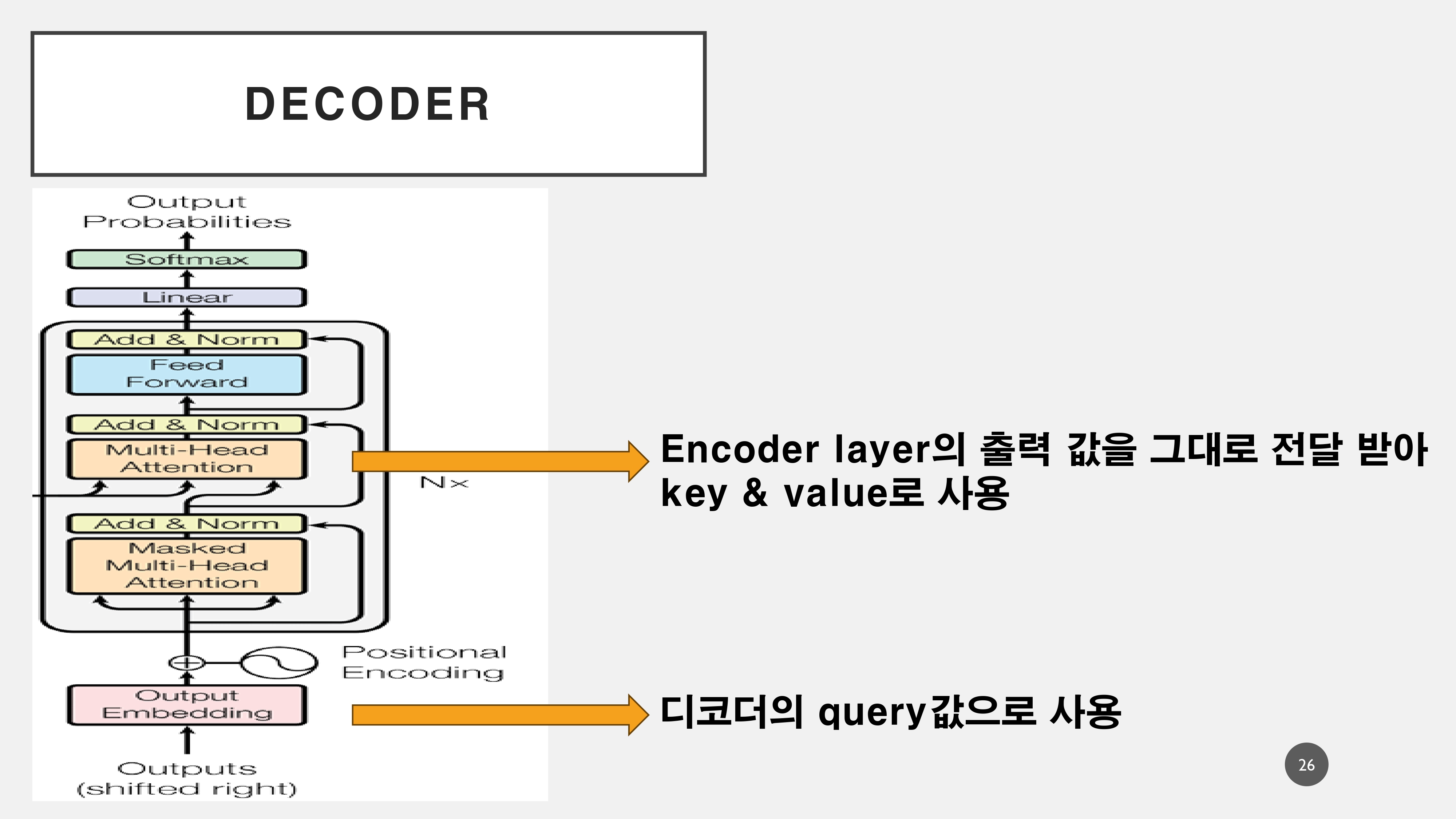
Encoder부분은 Bert에서 활용되고 있으며, Pre-trained된 Encoder를 활용하여 Decoder부분만 따로 활용하여 GPT에서 활용되고 있다.
모델의 구조에 대해서는 아래에서 하나하나 살펴보겠다.
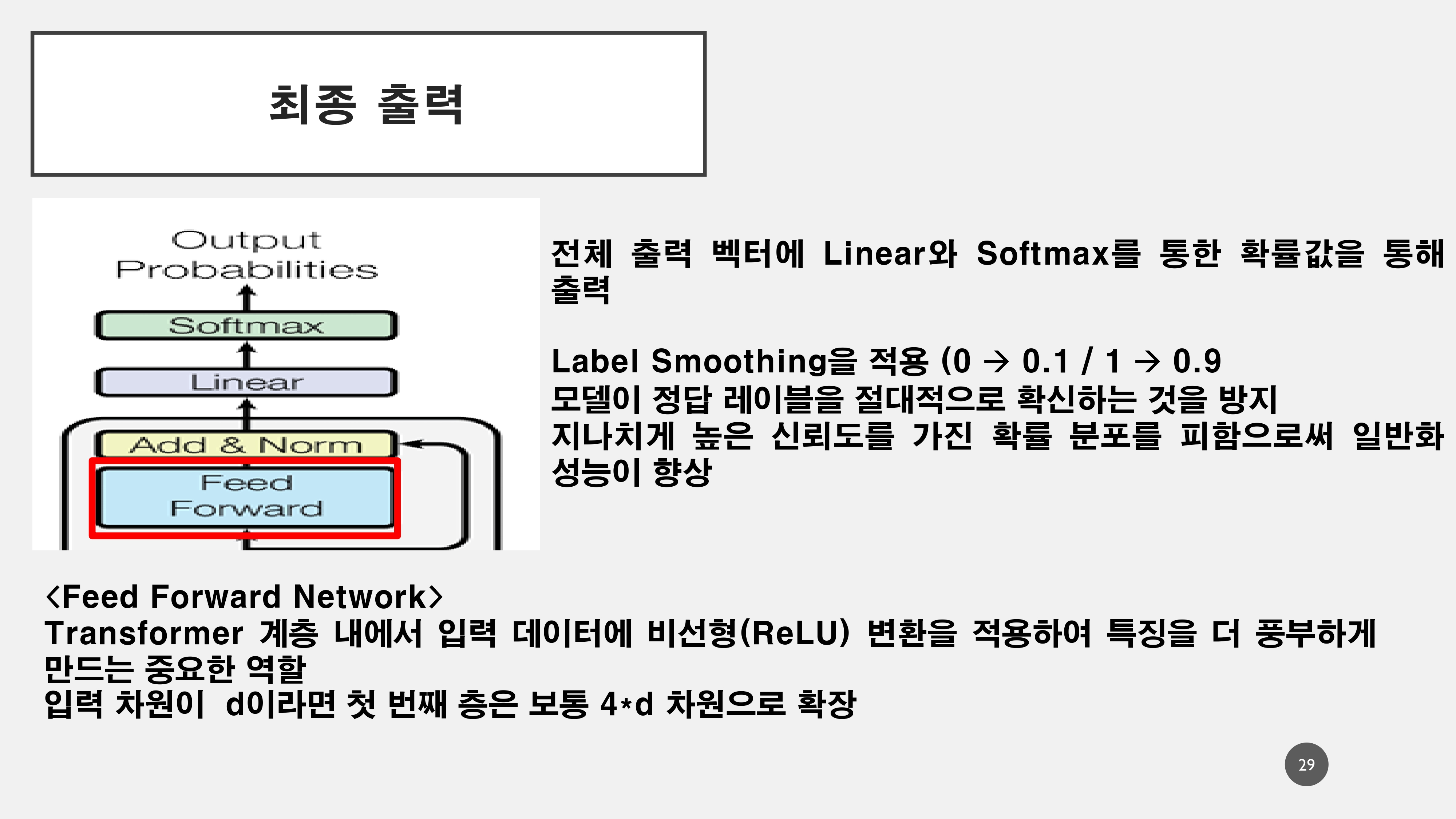
1. Positional Encoder
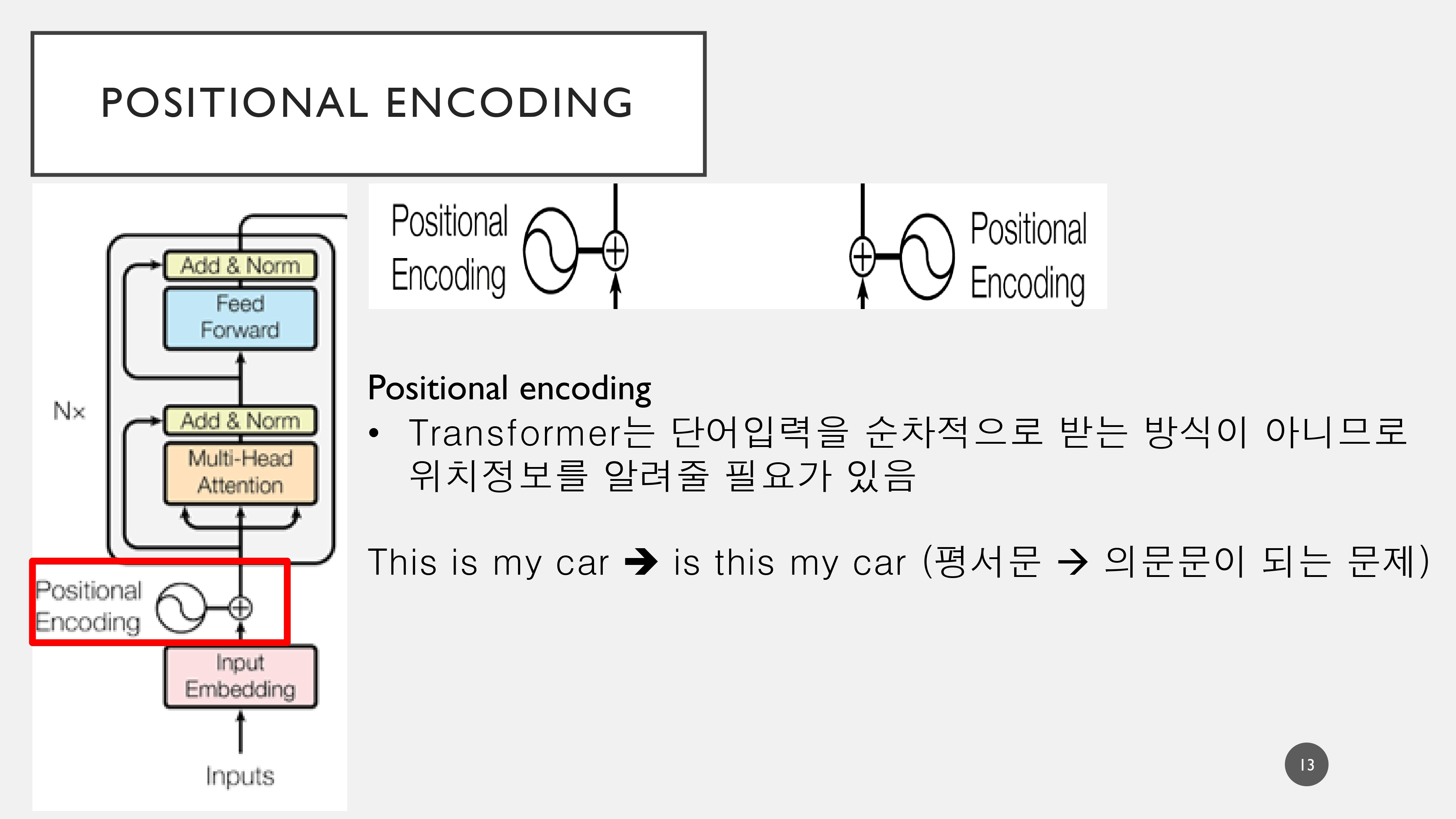
Transformer는 단어의 입력에 있어서 순서를 가지는 것이 아니라, 어떤 단어에 집중(attention)할 것인지에 대한 attention score를 매기기 때문에 언어의 순서정보(위치정보)를 정해줄 필요가 있다.
예를 들어 This is my car 와 같이 평서문이 위치 정보를 상실하여 is this my car와 같이 의문문이 되는 불상사가 일어날 수 있다.
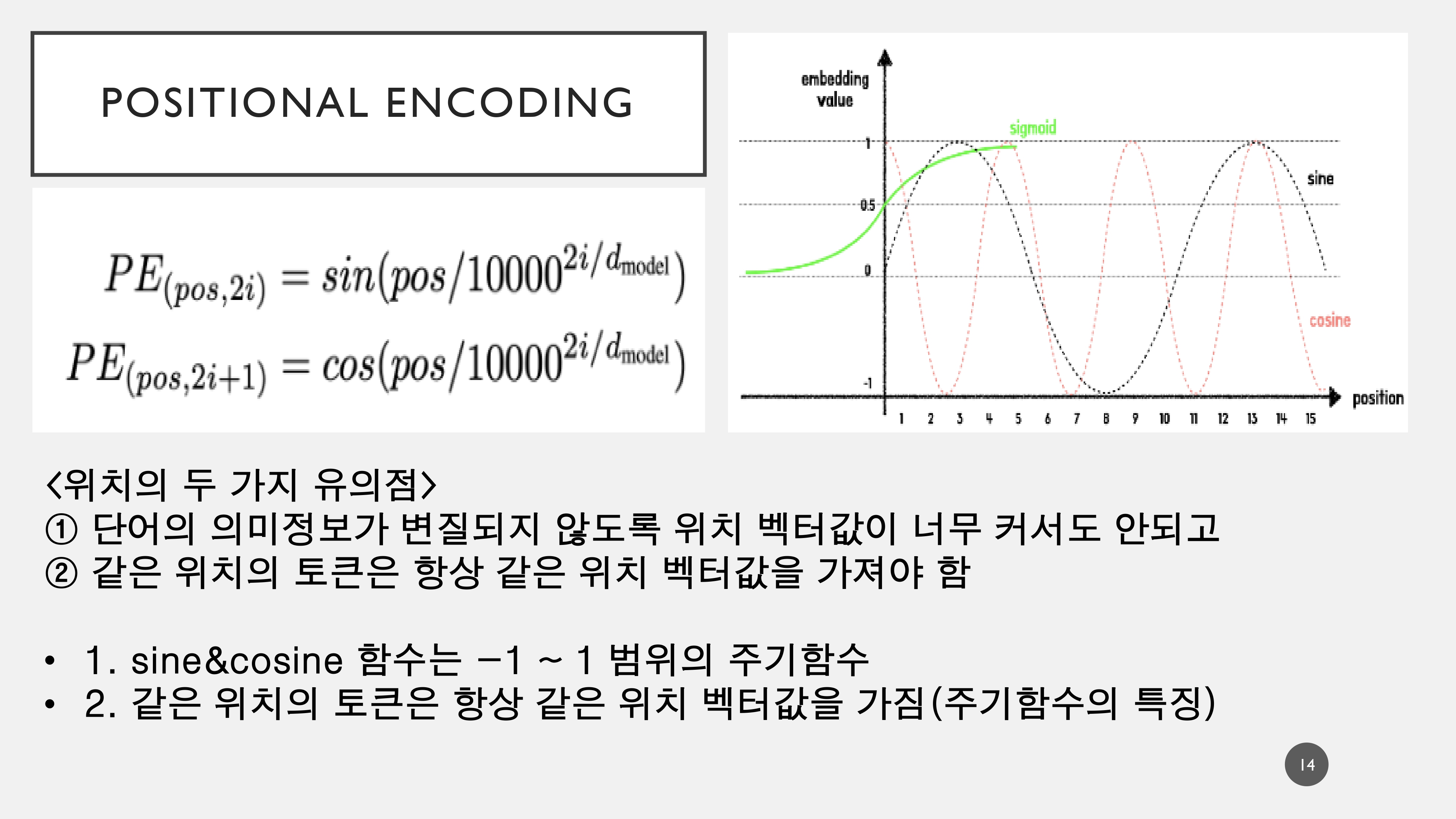
이러한 위치 정보는 의미가 변질되지 않도록 벡터값이 너무 커서도 안되고 같은 위치의 토큰은 항상 같은 위치의 벡터값을 가져야 하기 때문에 Sine&Cosine의 주기함수의 특징을 활용하여 수식으로 표현한다.
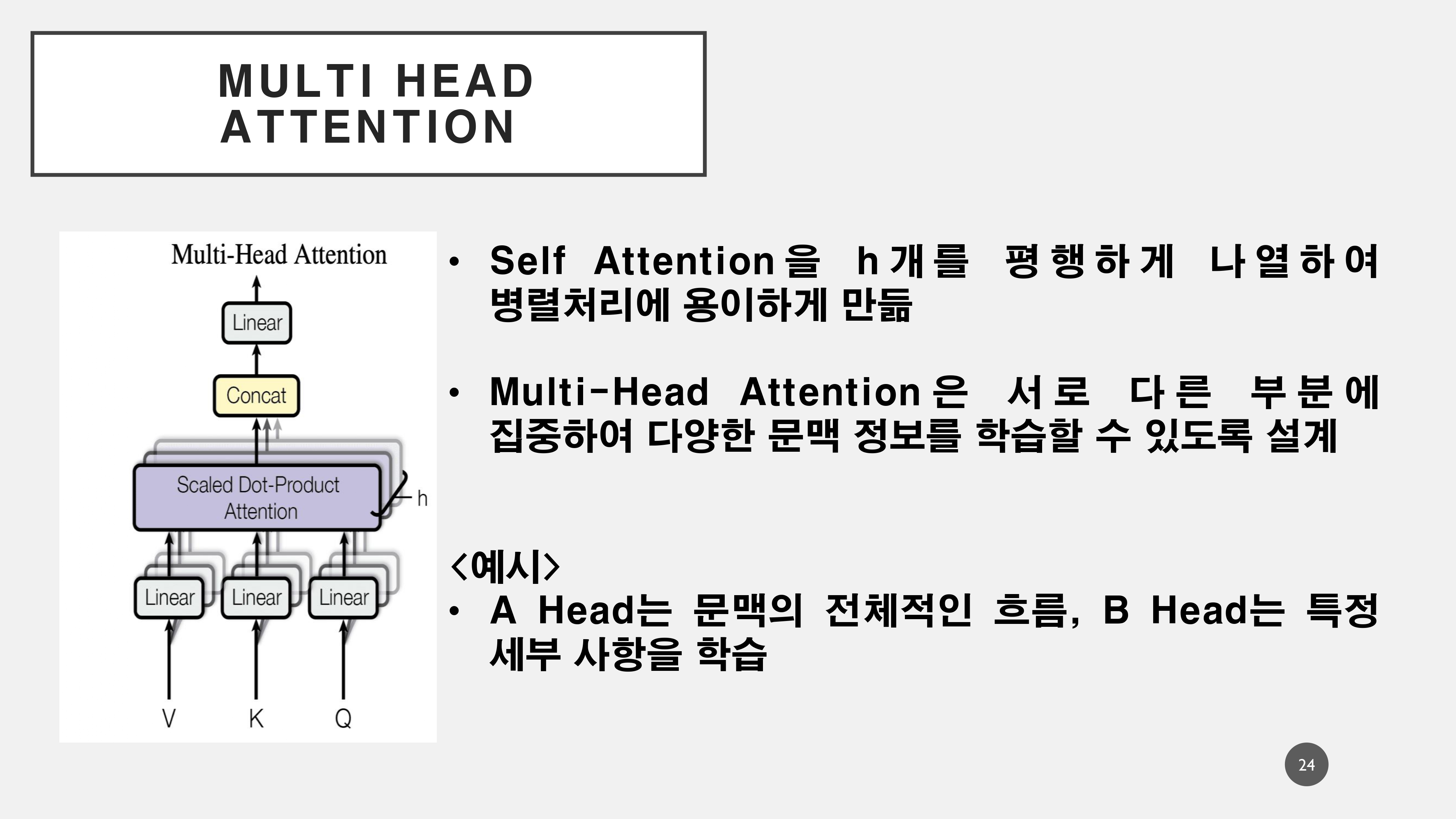
2. Multi-Head Attention(Self Attention)
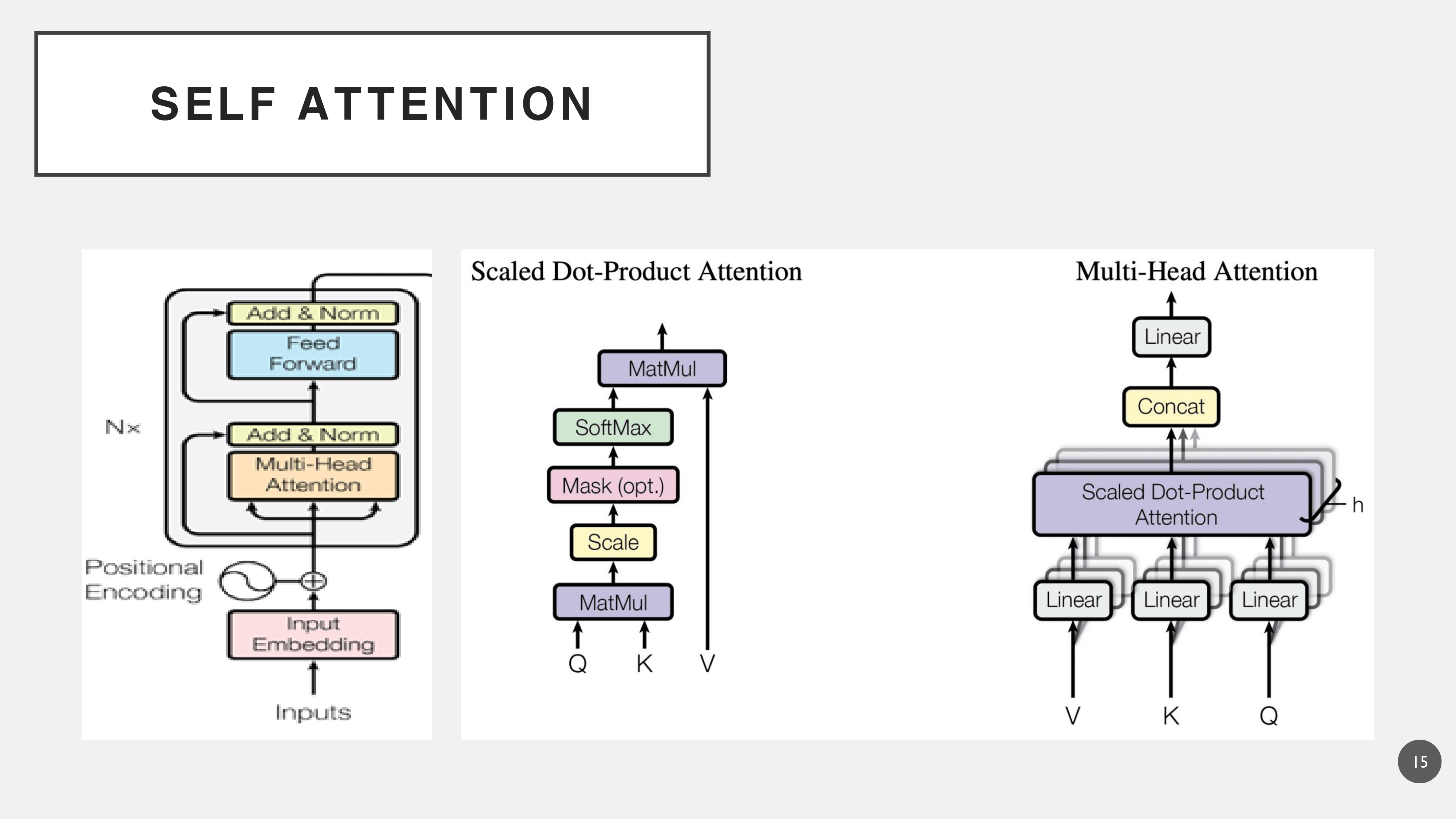
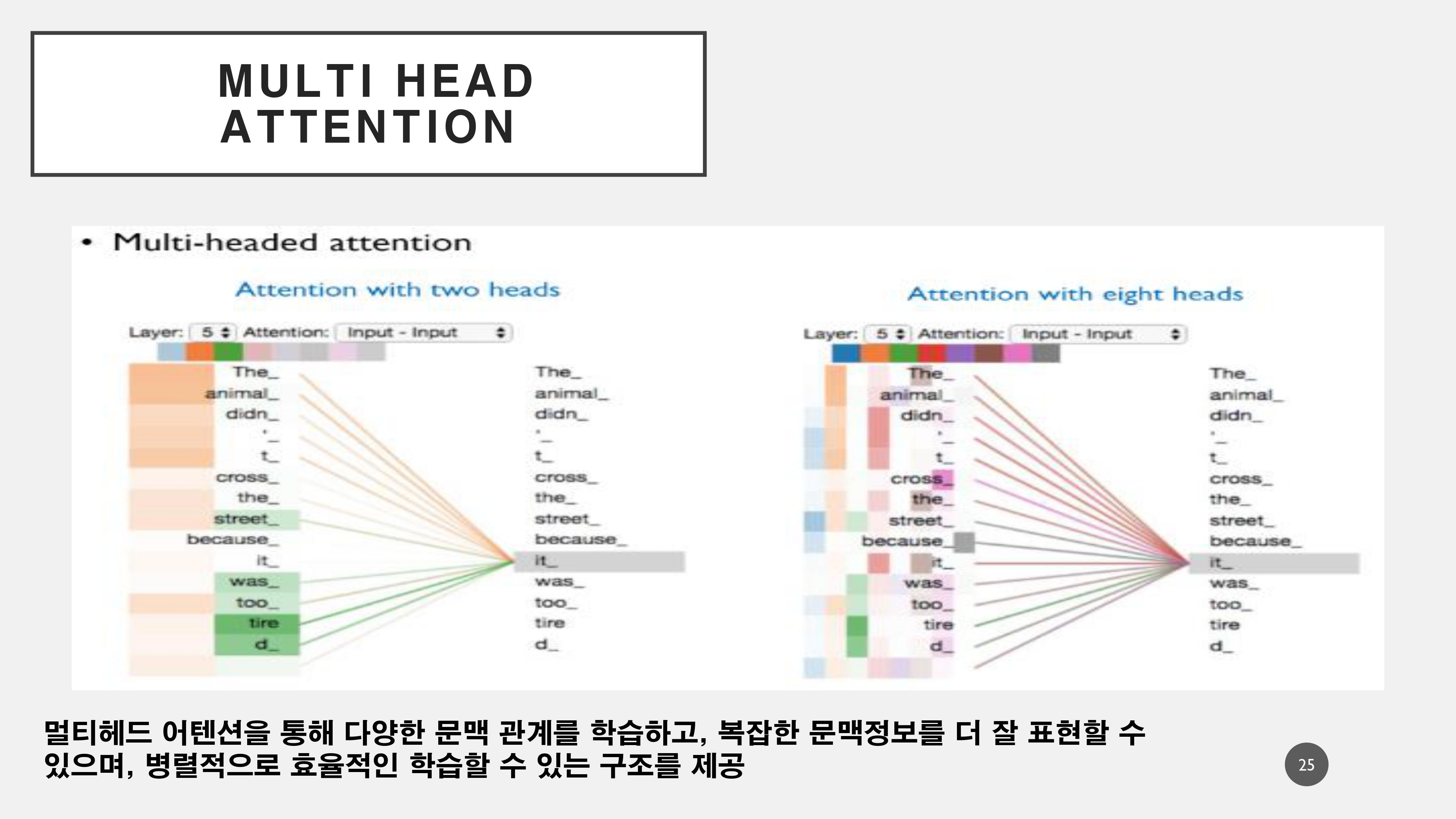
멀티헤드 어텐션이란, 셀프 어텐션을 여러 겹으로 겹쳐서 활용하여 복잡한 문장의 의미 정보를 병렬처리하여 더 빠르고 잘 추출할 수 있게 해준다.
이하, Attention과 Self Attention에 대해 추가적으로 설명하자면
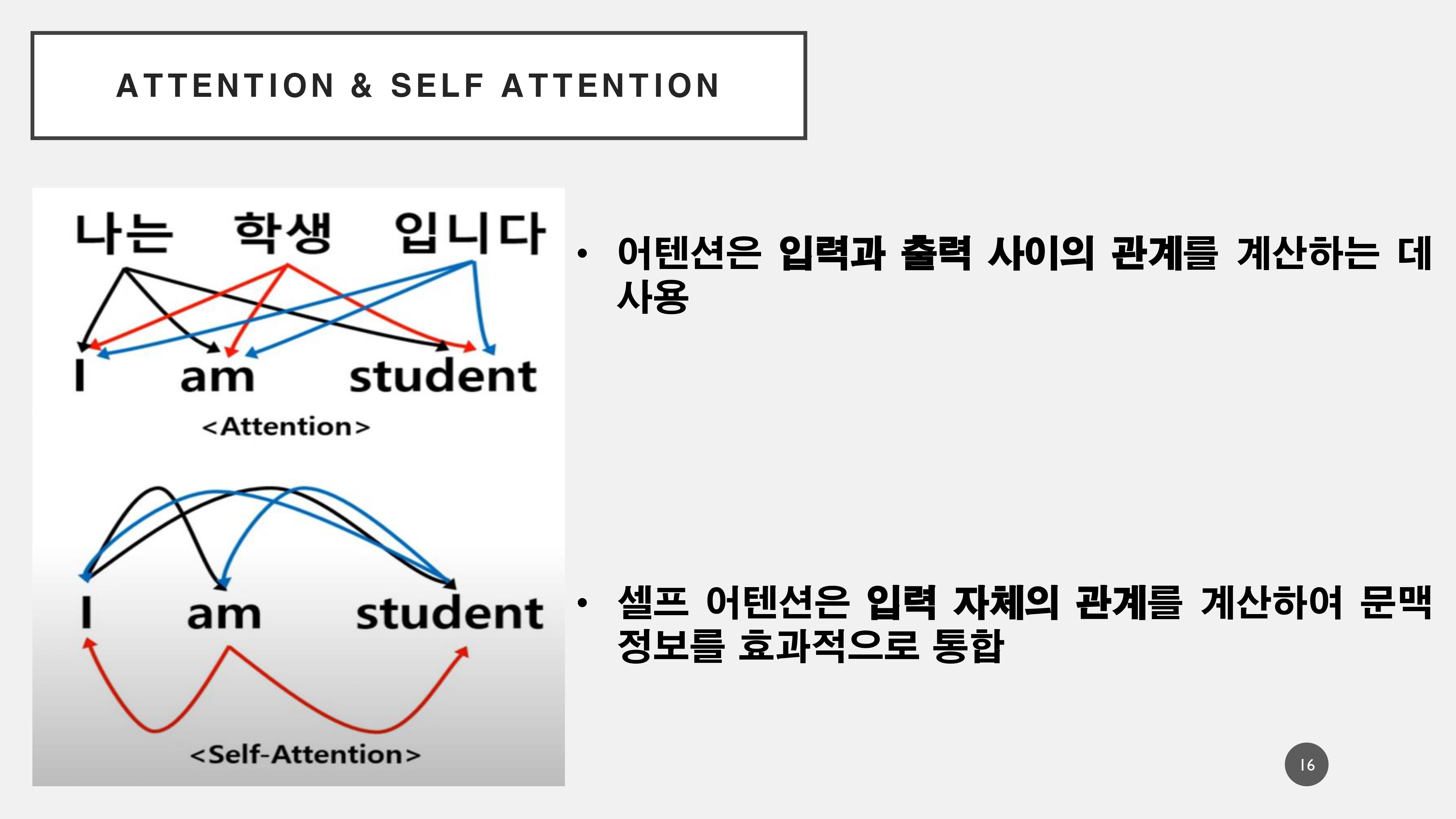
Attention 메커니즘은 입력과 출력에 있어서 각 단어간의 연관성을 추출하는 과정이라면, Self Attention은 말 그대로 입력 벡터 내의 단어 간의 집중도를 나타나게 된다. 이를 통해서 아래의 예문인 '배를 먹었더니, 배가 아프다.'에서 의미를 분리하며 다음에 올 수 있는 단어를 계산하게 된다.!
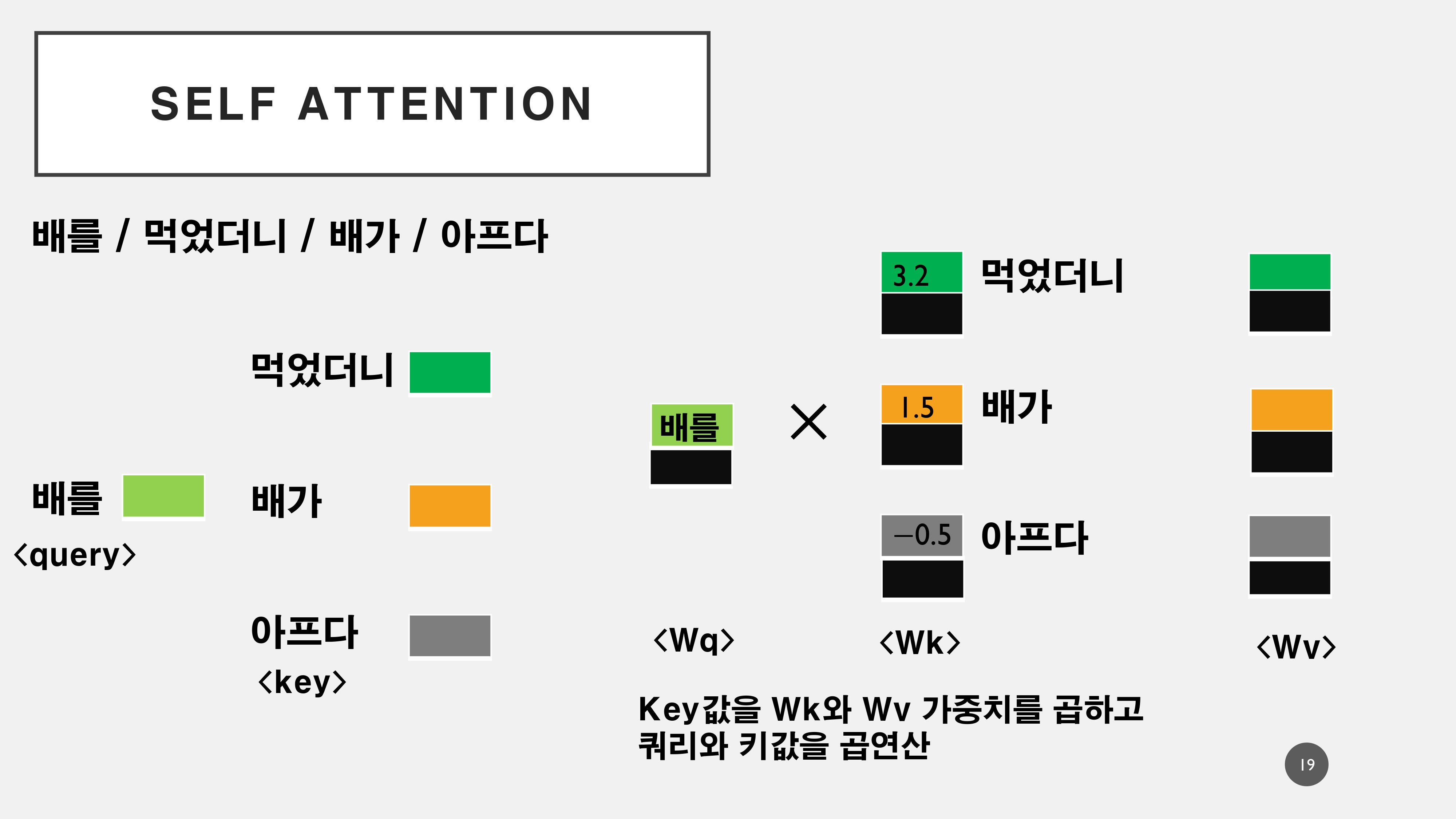
연산과정은 위와 같다. 각각의 단어를 Q, K, V로 나누게 된다. 이는 Wq, Wk, Wv의 세 개의 다른 가중치 행렬로 곱하여 Q, K, V를 만든다. 이를 통해서 생성된 Q*K값을 내적하여서 연산과정을 통해서 각 토큰에 대한 어텐션 가중치를 구하게 된다.
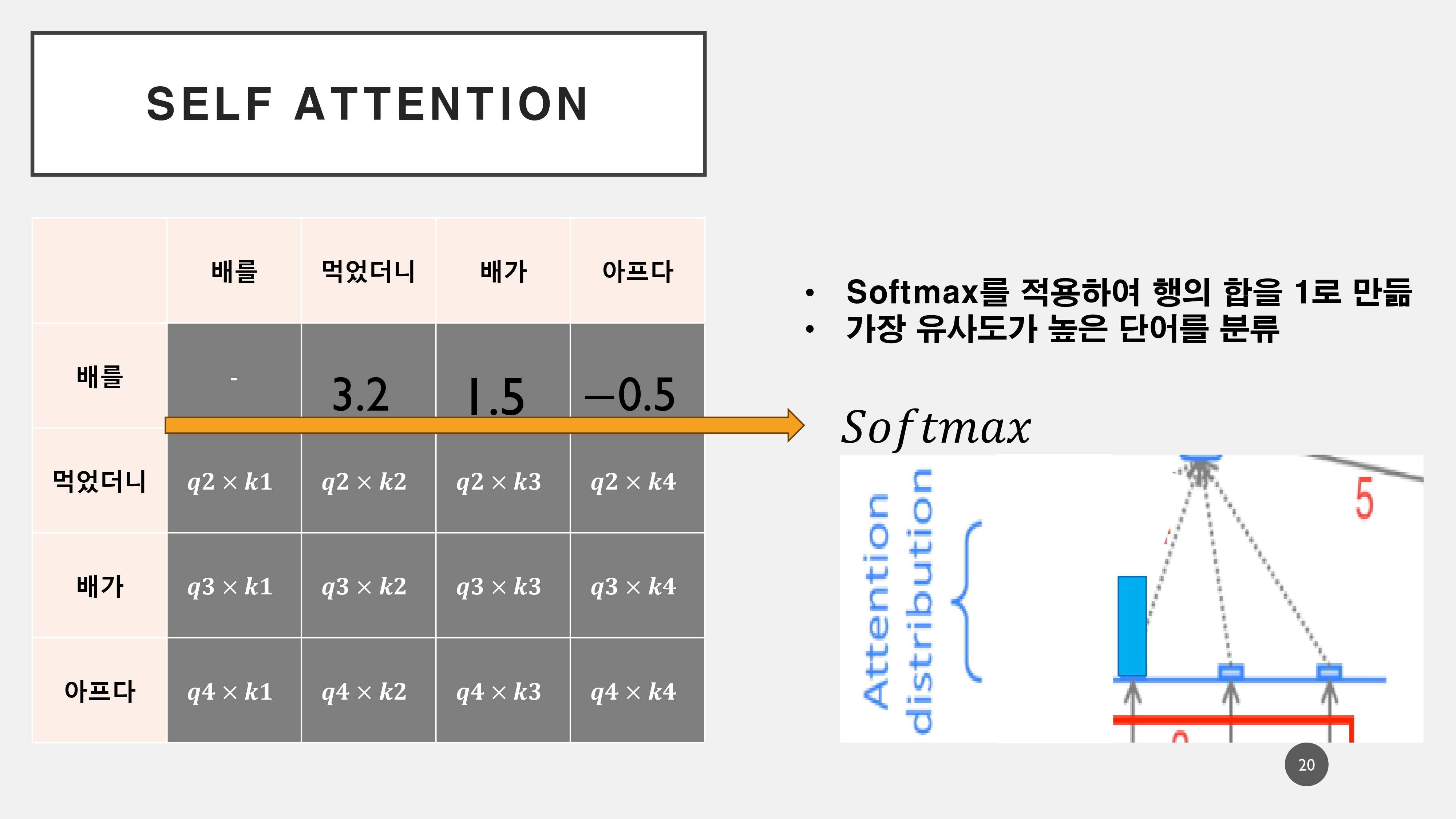
이해하기 편하도록 '배를'이라는 토큰에서의 어텐션 과정을 생략하였으나, 실제로는 스스로의 어텐션 스코어가 가장 높게 나오게 된다. 이를 통해서 다음의 토큰에 대해서 연산하게 되고 각 스코어를 통해서 '배'라는 단어에서의 의미를 분할하게 된다.
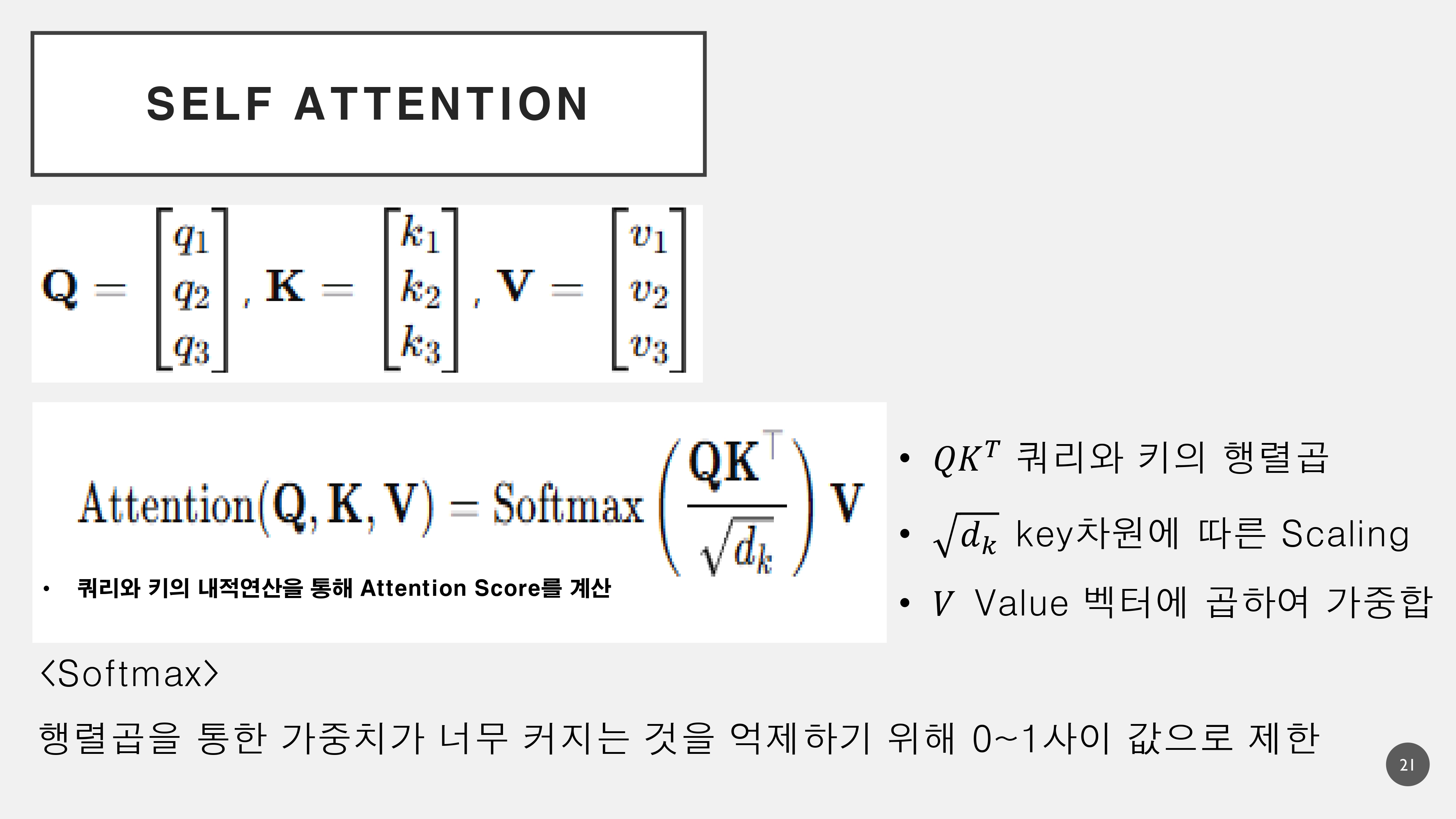
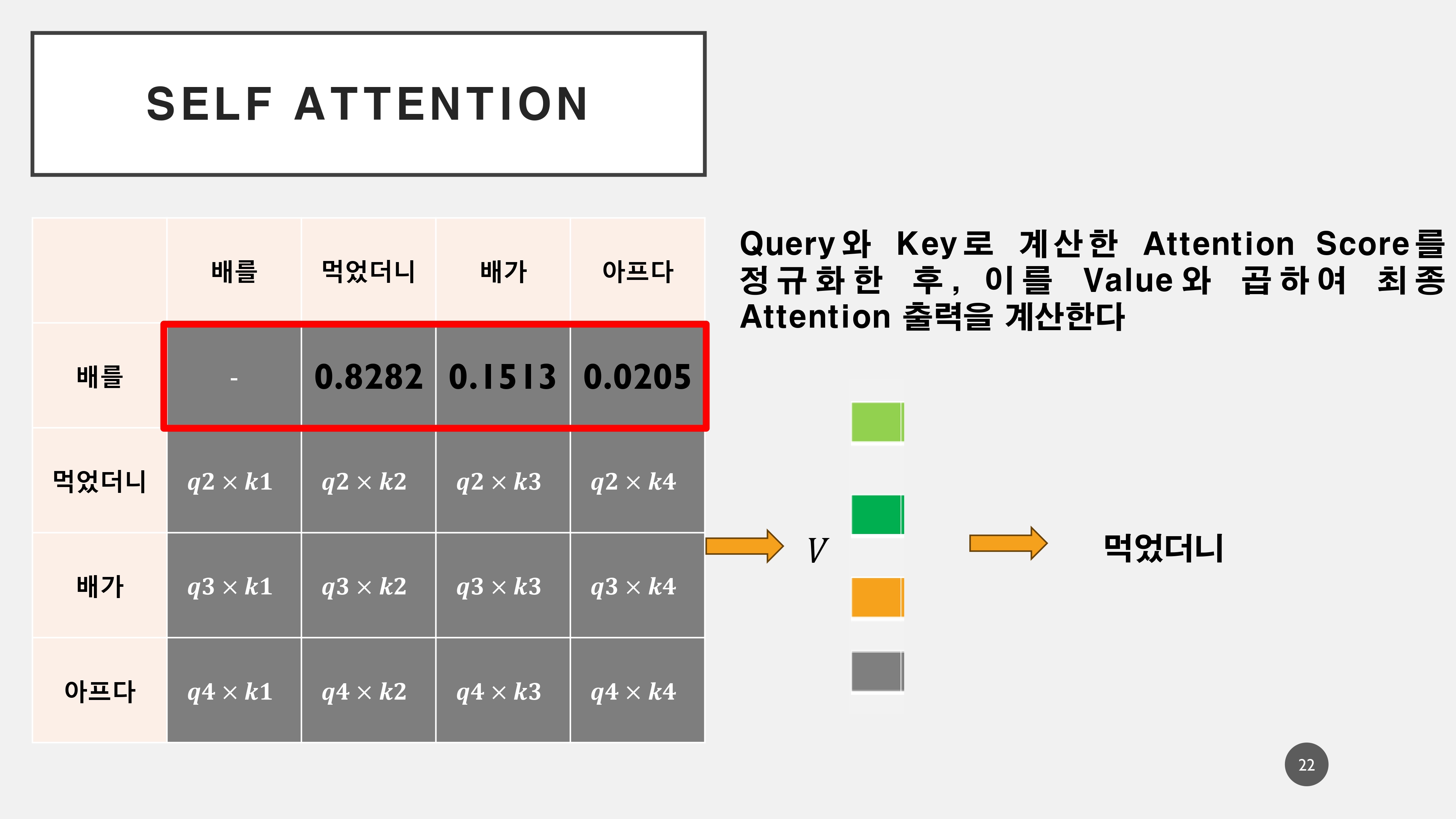
3. Decoder
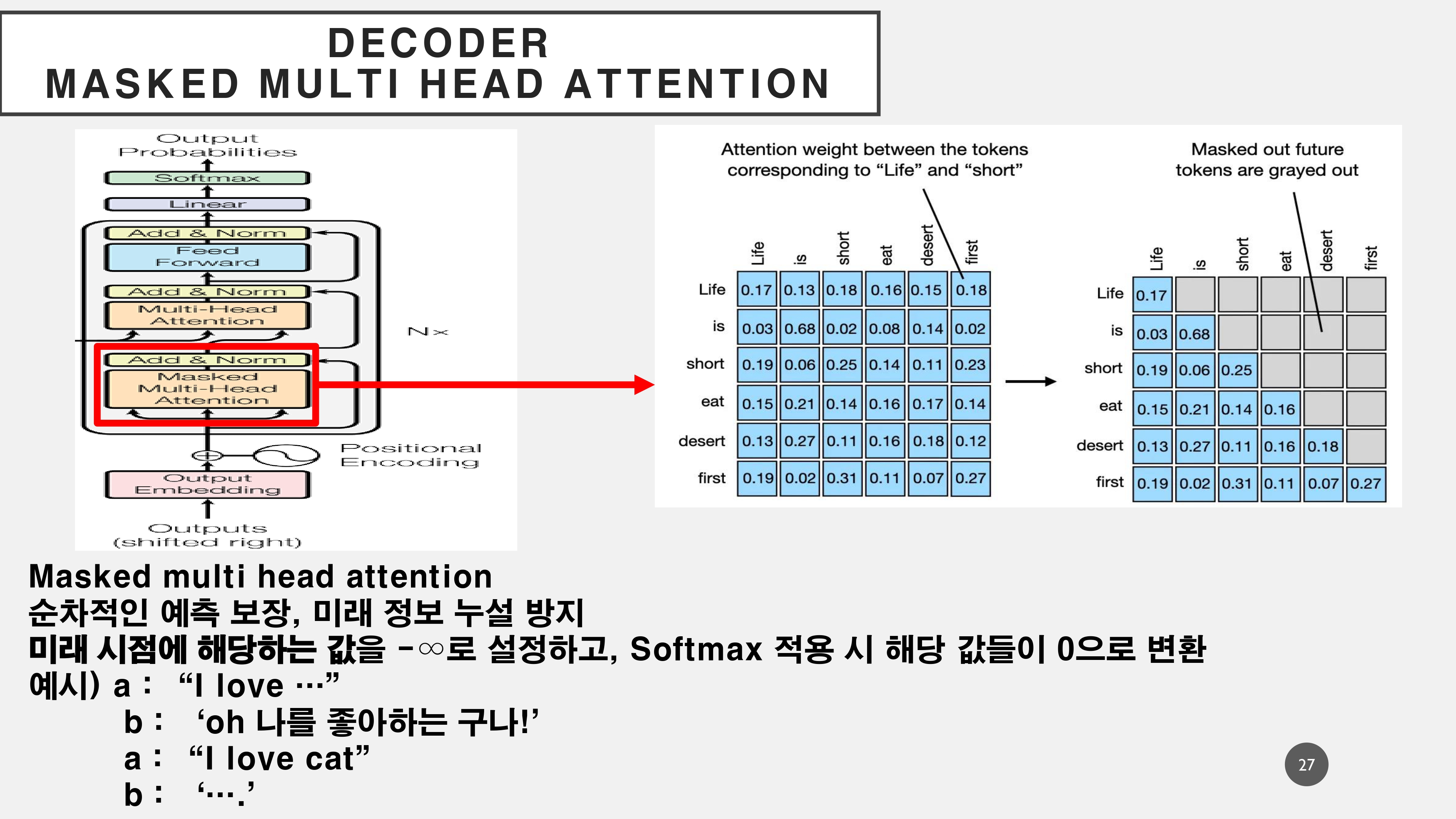
4. Masked Multihead Attention
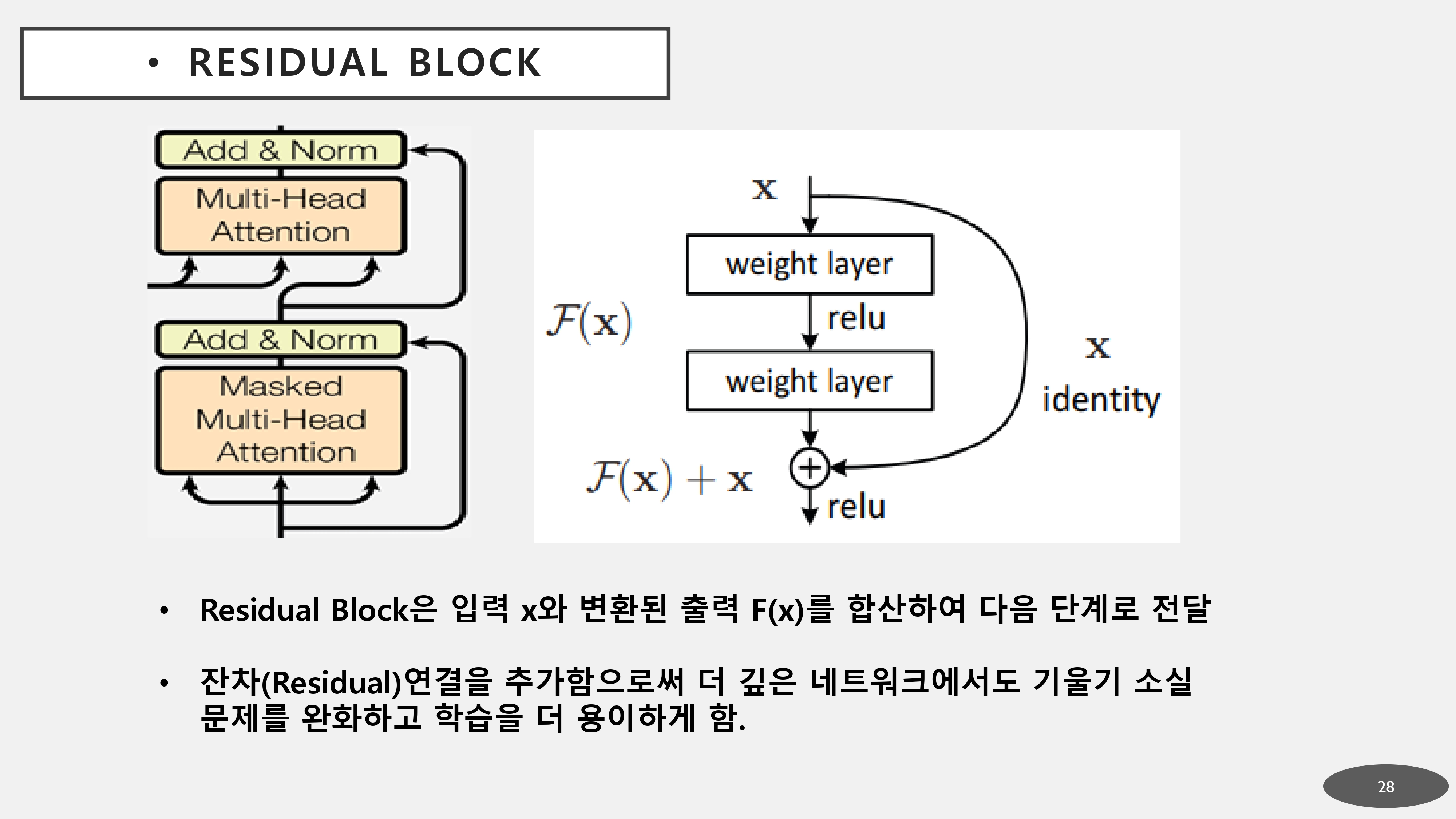
5. Residual connection