Transformers모델의 등장으로 자연어 처리 모델의 성능이 기하급수적으로 증가하였습니다. 이러한 Transformer모델의 성능을 컴퓨터 비젼 분야에도 적용할 수 있다면, 뛰어난 성능을 보일 것이라고 생각했기 때문에 Transformer모델을 컴퓨터 비젼분야에 적용한 것이 Vision Transformer모델이고 해당 모델의 등장으로 이미지 Classification작업에서는 SOTA를 달성하게 됩니다
하지만, ViT(Vision Transformers)의 경우에는 Classification 작업만 가능하며, 추가적으로 개선하여 Segmentation작업까지 가능하게 한 것이 Swin Transformers모델입니다.
개인적으로 공부를 진행하며 정리한 내용이기 때문에 부족한 부분이나, 틀린 부분이 있다면 조언 부탁드립니다.
Abstract
- Transformer모델의 등장으로 자연어 처리 분야에서는 사실상 표준이 되었지만, 컴퓨터 비젼분야에서는 적용이 제한적이다. 컴퓨터 비젼 분야에서도 어텐션을 CNN(합성곱 신경망)과 함꼐 사용하거나 CNN의 특정 구성요소를 대체하는 방식으로 적용되며, 전체적인 구조는 그대로 유지되는 경우가 많다.
- 해당 논문에서는 CNN 의존성이 필수적이지 않으며, 이미지 패치 시퀀스에 직접 적용된 순수한 트랜스포머 모델이 이미지 분류작업에서도 매우 우수한 성능을 발휘할 수 있음을 보인다.
- 대량의 데이터에서 사전 학습(pre-training)된 후, 중간 규모 또는 소규모 이미지 인식 벤치마크(예: ImageNet, CIFAR-100, VTAB 등)에 전이 학습(transfer learning)되었을 때,Vision Transformer(ViT)는 최신 CNN 모델들과 비교하여 뛰어난 성능을 달성하면서도 학습에 필요한 연산량을 크게 줄일 수 있음을 보여준다.
1. 서론
1.1 ViT의 성능분석
트랜스포머 모델의 최고 강점은 연산 효율성과 확장성이다. 이러한 덕분에 1000억 개 이상의 파라미터를 가진 초대형 모델을 학습하는 것도 가능해졌다. 모델과 데이터셋의 규모가 커질수록, 여전히 성능이 향상될 수 있다.
ViT모델의 등장 이전에는 ResNet계열의 전통적인 CNN 아키텍쳐가 SOTA모델로 자리잡고 있었다.
1.2 ViT의 접근방식
NLP에서 트랜스포머가 확장성 면에서 성공한 사례를 기반으로, 우리는 최소한의 수정만 가한 표준 트랜스포머를 이미지에 직접 적용하는 실험을 수행했다. 이를 위해, 이미지를 작은 패치(patch)들로 분할하고, 이 패치들의 선형 임베딩(linear embeddings) 시퀀스를 트랜스포머의 입력으로 제공했다. 즉, 이미지 패치를 NLP에서 사용하는 토큰(단어)과 동일한 방식으로 처리하여 모델을 학습하였다. 이 모델은 이미지 분류(image classification) 작업을 지도 학습(supervised learning) 방식으로 학습하였다. 이를 통해 전통적인 CNN계열의 모델들에 비해 더욱 뛰어난 성능을 발휘할 수 있었다.
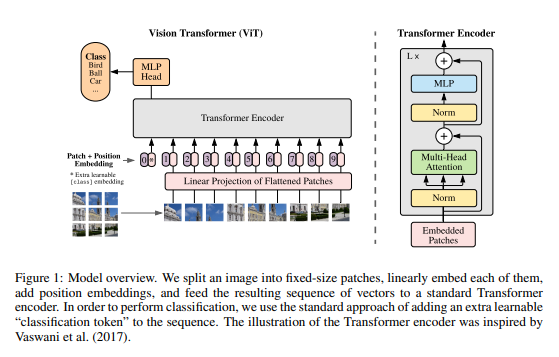
해당 Figure1은 ViT의 전체적인 아키텍쳐를 보여준다.
2. Vit
기존의 Transformer모델은 1D 토큰 임베딩 시퀀스를 입력 받는다. 하지만, 2D 이미지 데이터를 처리하기 위해 이미지를 작은 Patch단위로 변환하여 1D 시퀀스로 전달한다.
원본의 이미지에서 패치별로 분할하여 다음과 같이 나타낸다. 이러한 과정을 통해서 2D의 이미지가 1D의 시퀀스로 변환할 수 있게한다.
Transformer모델은 고정된 Vector차원으로 입력되기 때문에 각 패치를 펼친 후 학습 가능한 선형 변환을 적용하여 차원으로 맵핑해준다. 이러한 과정을 통해 나온 출력물을 Patch Embedding이라한다.

또한 BERT에서 사용된 CLS Token을 활용한다. [CLS]토큰은 문장 전체의 요약 벡터 역할을 수행하여 Transformer 구조에서 문맥 정보를 압축하는 역할을 수행한다.
각각의 이미지 패치에 CLS토큰을 부여하여 해당 이미지가 어떤 클래스에 속하는지를 표현하고 최종적으로 Transformer모델을 통과하며 이를 번 반복하여 마지막의
해당 토큰 벡터만을 활용하여 최종 분류에 사용하게 된다.
학습에는 기존에 사용된 Transformer와 동일한 Encoder구조에서 학습을 하게 되고 이후 출력된 내용이 사전 학습 시에는 MLP Head를 분류 헤드로 사용하고 미세조정 시에는 단일 선형 분류 헤드를 사용한다.
또한 기존의 Transformer모델과 같이 이미지 패치의 위치 정보가 존재하지 않기 때문에 패치 임베딩에 위치 정보를 추가해주기 위해 Positional Embedding을 진행한다.
Inductive bias(귀납적 편향)
CNN의 경우에는 이미지 처리에 특화된 구조를 가지고 있으며, 국소성(Loacality), 변환 등변성(Translation Equivariance), 공간공유(Weight Sharing)을 통해 적은 데이터로도 강력한 성능을 낼 수 있으나, ViT의 경우에는 Self-Attention을 기반으로 하여, 지역적 특성을 학습하지 않기 때문에 '대용량'의 데이터를 입력 시켜서 학습을 시켜야 한다.
Hybrid Architechure
ViT는 순수한 Transformer 모델뿐만 아니라, CNN과 결합한 하이브리드 모델도 가능하다. CNN의 특징 맵(feature map)을 Transformer의 입력으로 사용할 수 있다. 이 경우, CNN에서 추출된 특징 맵을 패치 형태로 변환하고, 패치 임베딩 프로젝션 𝐸를 적용하여 Transformer 입력 시퀀스를 생성하고 패치 크기를 1×1로 설정하여 CNN 특징 맵의 공간 차원(spatial dimensions)을 단순히 펼쳐서(Flattening) Transformer 차원으로 변환하는 것과 동일하다. 이 방식에서는 클래스 토큰(Class Token)과 위치 임베딩(Position Embedding)을 기존 ViT 방식과 동일하게 적용한다.
3. Result
- 일반적인 CNN(ResNet)은 적은 데이터에서도 성능이 우수하지만, 대규모 데이터에서는 ViT가 더 강력할 가능성이 있음.
-
ViT의 효율적인 이유
- CNN처럼 공간 필터를 학습하는 것이 아니라, Self-Attention을 활용하여 정보 추출
-연산량을 최적화하면서도 글로벌 패턴을 학습할 수 있음
-패치 단위로 처리하기 때문에 연산량이 CNN 대비 일정하게 유지됨 -
마지막으로, Self-Supervised Learning(자기 지도 학습) 방식으로 ViT를 학습하는 작은 실험을 수행
Self-Supervised Learning이란?
-레이블(정답) 없이 데이터의 패턴을 학습하는 방법
-일반적으로 대규모 데이터에서 강력한 표현 학습을 가능하게 함
-대표적인 방법: SimCLR, MoCo, BYOL, DINO 등
레이블이 부족한 환경에서도 ViT의 성능이 향상될 가능성이 큼
CNN 기반의 Self-Supervised 모델과 비교해도 강력한 표현 학습 능력을 가질 수 있음

위의 그림은 ViT모델이 분류 시에 어떤 부분을 Attention하는지를 알 수 있다.
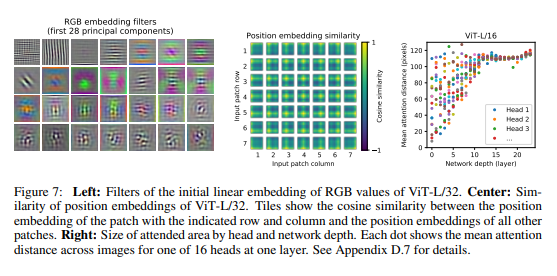
좌측 부터 Embedding의 Filter를 확인하였을 때, 각 Filter의 기능이 저차원의 CNN Filter 기능과 유사함을 알 수 있다. 중간 이미지는 포지션 임베딩을 진행 후 1D로 펼쳐 주었을 때, 해당 이미지 패치가 각각의 위치에 제대로 있는가, 즉 이미지 패치 간의 공간 정보가 잘 학습됨을 알 수 있다.
"""다양한 모델과 비교한결과값에 대해서는 설명하지 않겠습니다. """
