[Paper Review] Momentum Contrast for Unsupervised Visual Representation Learning
Paper Review

이번 포스트에서 리뷰할 논문은 self-supervised learning에 momentum encoder와 dictionary 구조를 사용한 Momentum Contrast for Unsupervised Visual Representation Learning([pdf]
Introduction
GPT와 BERT를 통해 알 수 있듯이 자연어 처리 분야에서는 비지도 표현 학습이 큰 성공을 거두었다. 하지만 컴퓨터 비전 분야에서는 지도 학습 기반의 사전 훈련 방법이 여전히 우세하다. 이는 signal space 차이에서 기인한다. 자연어에서는 단어(word), 하위 단어(subword) 등 이산적인(discrete) 신호 공간을 사용하여 토큰화된 사전을 구축하고 이러한 사전 위에서 비지도 학습이 이루어질 수 있다. 반면에 컴퓨터 비전 분야에서는 raw signal이 연속적이고 고차원 공간에 있기 때문에 구조화가 어렵고 사전 구축이 더 복잡하다.
최근 contrastive loss와 관련된 접근 방법을 사용하여 비지도 시각적 표현 학습에 대한 연구들이 있었다. 저자들은 이러한 방법들이 dynamic dictionaries를 구축하는 것으로 생각하였다. 딕셔너리에서 key는 데이터에서 샘플링되며 인코더 네트워크에 의해 표현된다. 인코더는 비지도 학습을 통해 dictionary look-up을 잘 수행하게 된다. 인코딩된 query는 해당하는 키와 유사하고 다른 키들과는 유사하지 않아야 한다. 학습은 contrastive loss를 최소화하는 방향으로 진행된다.

저자들은 이를 위해 학습이 진행되면서 크고(large) 일관성(consistent) 있는 딕셔너리가 구축되게 하였다. 더 큰 딕셔너리는 연속적이고 고차원의 시각적 공간을 더 잘 샘플링할 수 있을 것이다. 또한 딕셔너리의 key는 동일하거나 거의 유사한 인코더로부터 추출 되기 때문에 key와 query의 비교가 일관성 있게 이루어질 수 있다. 기존의 contrastive loss를 사용하는 방법들은 이러한 측면들을 모두 만족하지 못하였다. 예를 들어 비슷한 시기에 contrastive loss를 사용한 SimCLR도 많은 negative sample과 비교하기 위해서는 batch size를 키워야 했고, 이는 많은 computing cost를 발생시킨다.
저자들은 contrastive learning을 사용하여 비지도 학습에서 크고 일관성 있는 딕셔너리를 구축하기 위한 방법으로 'Momentum Contrast (MoCo)'를 제안한다. 저자들은 데이터 샘플들을 보관하기 위해 딕셔너리를 queue 구조로 사용하였다. 인코딩된 미니 배치 데이터들의 representation들이 queue에 enqueue되고 가장 오래된 representation들은 dequeue 된다. 이를 통해 미니배치의 크기에 의존적이지 않고, 큰 크기의 딕셔너리를 유지할 수 있다. 또한 딕셔너리의 key들은 이전 몇 개의 미니배치로부터 나오기 때문에, query 인코더에서 momentum-based moving average로 key 인코더를 느리게 update하여 key encoder의 일관성을 유지하였다.
MoCo는 contrastive learning을 위한 dynamic dictionary를 구축하는 방식이고, 다양한 pretext task와 함께 사용될 수 있다. 이 논문에서는 간단한 instance discrimination을 사용하고 있다. query는 동일한 이미지에서 생성된 encoding view와 일치하는 경우 해당 키와 매치한다. 이러한 pretext task를 사용하여 MoCo는 ImageNet 데이터셋에서 linear classification에서 경쟁력 있는 결과를 보여주었다.
비지도 학습의 주요 목적은 pretrained된 representation을 downstream 작업에서 fine-tuning 할 수 있도록 전달하는 것이다. 저자들은 detection 또는 segmentation과 관련된 7개의 downstream 작업에서, MoCo 방식이 우수한 성능을 냄을 보여주었다.
Method
Contrative Learning as Dictionary Look-up
저자들은 Contrastive learning은 dictionary look-up을 위해 인코더를 훈련하는 것이라고 한다.
인코딩된 query 와 딕셔너리의 key인 인코딩된 샘플들 을 고려해보자. 와 일치하는 딕셔너리 내의 key 가 있다고 가정하자. contrastive loss는 가 자신과 positive인 와 유사하고 다른 모든 key(negative samples)들과는 유사하지 않을 때 loss 값이 낮은 함수이다. 유사성은 dot product로 측정되며, 이 논문에서는 InfoNCE라는 contrastive loss를 사용하였다.
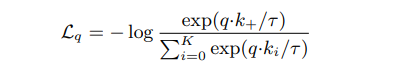
여기서 는 temperature 하이퍼파라미터이다. 함수에서 분모는 하나의 positive sample과 K개의 negative sample에 대한 합으로 이루어진다. 직관적으로 이 loss는 를 로 분류하려는 (K+1)개 classifier에 대한 로그 손실이다. Contrastive loss 함수는 여러 버전의 NCE(Negative Contrastive Estimation) loss와 margin-based loss로 구성될 수 있다.
Contrastive loss는 query와 key를 나타내는 인코더의 objective function으로 작용한다. 일반적으로 query의 representation은 로 나타내며, 여기서 는 인코더이고 는 query 샘플이다. 마찬가지로 key는 로 표기된다. 인코더와 입력은 pretext task에 따라 다양한 형태로 나타낼 수 있다. 입력 와 는 이미지, 패치, 패치 세트로 구성된 문맥일 수 있다. 인코더 와 는 동일할 수도 있고, 일부는 공유되거나 일부는 다를 수도 있다.
Momentum Contrast
저자들의 관점으로 Contrative learning은 이미지와 같은 고차원 연속적인 입력으로 이산적인 딕셔너리를 구축하는 방법이다. 이 딕셔너리는 key가 무작위로 샘플링되며 key 인코더가 훈련 중에 update하는 dynamic 특성을 가지고 있다. 저자들은 많은 양의 부정적인 샘플 집합을 포함하는 큰 딕셔너리로 좋은 representation을 학습히고 동시에 딕셔너리 key를 일관성 있게 유지할 수 있도록 Momentum Contrast를 제안하였다.
Dictionary as a queue
저자들이 제안하는 방식은 데이터 샘플들의 queue를 통해 딕셔너리를 유지하는 것이다. 이를 통해 바로 이전 미니 배치에서 인코딩된 키를 재사용할 수 있다. queue의 도입으로 딕셔너리 크기를 미니 배치 크기와 분리할 수 있다. 딕셔너리 크기는 일반적인 미니 배치 크기보다 훨씬 크게하고 하이퍼파라미터로 유연하게 설정할 수 있다. 딕셔너리의 샘플들은 점진적으로 교체된다. 현재 미니 배치가 딕셔니리에 enqueue되고, queue의 가장 오래된 미니 배치가 dequeue를 통해 제거된다. 딕셔너리의 크기가 크고, enqueue와 dequeue 과정을 통해 딕셔너리는 전체 데이터의 샘플된 부분집합을 나타낼 수 있다. 가장 오래된 미니 배치를 제거하는 것은 해당 미니 배치는 인코딩된지 가장 오래되었기에 최신의 key와 가장 일관성이 없기 때문에 dequeue를 통해 제거한다.
Momentum update
queue를 사용하면 딕셔너리를 크게 만들 수 있지만, key 인코더를 backpropagation을 통해 update하는 것은 처리하기 어려울 수 있다. 왜냐하면 gradient가 queue 내의 모든 샘플로 전파되어야 하기 때문이다. 간단한 해결책은 query 인코더 에서 key 인코더 를 복사하여 key 인코더에서는 backpropagation을 통한 update를 하지 않는 것이다. 하지만 이러한 방식은 실험에서 좋지 않은 결과를 보여주었다. 저자들은 이 실험에서 좋지 않은 결과가 key representation 일관성을 감소시키는 빠르게 변화하는 인코더에 기인한다고 보았다. 따라서 이 문제를 해결하기 위해 momentum update를 제안하였다.
의 매개변수를 로, 의 매개변수를 로 나타낸다면, 다음과 같이 를 업데이트한다.
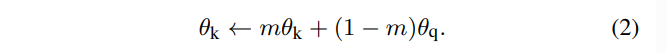
여기서 은 [0, 1) 범위 내의 모멘텀 계수이다. query encoder의 매개변수인 만 역전파를 통해 업데이트된다. 식 (2)의 모멘텀 업데이트는 가 보다 더 부드럽게 진화하도록 만듭니다. 따라서 queue 내의 key들이 서로 다른 인코더에 의해 인코딩되지만, 인코더들 사이의 차이를 작게 만들었다. 실험에서는 상대적으로 큰 모멘텀 (m = 0.999)이 작은 값 (m = 0.9)보다 훨씬 더 좋은 결과를 나타내며, 이는 느리게 변화하는 key 인코더가 queue를 활용하는 핵심 요소라는 것을 보여준다.
Relations to previous mechanisms
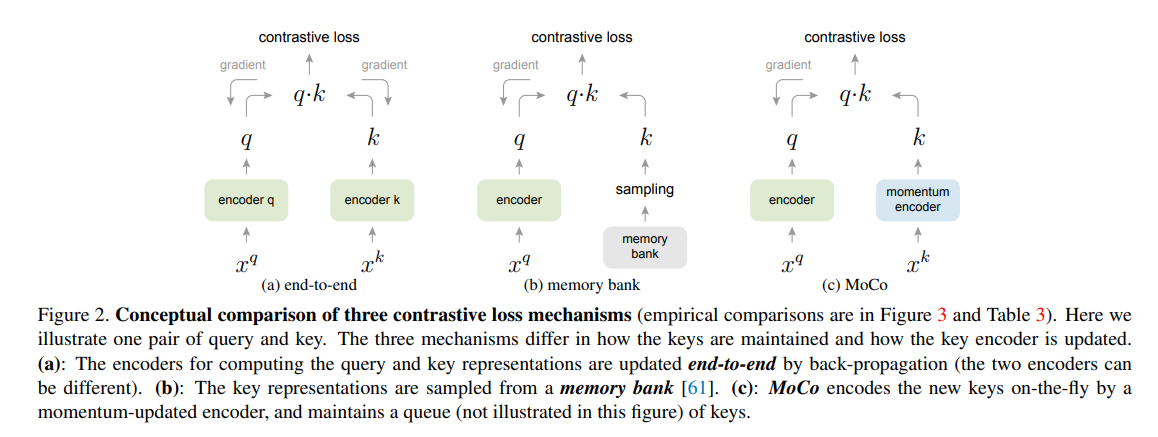
MoCo는 contrastive loss를 사용한다. Figure 2에서 MoCo를 기존의 두 가지 일반적인 메커니즘과 비교한다. 이들은 딕셔너리의 크기와 일관성 측면에서 서로 다른 특성을 보인다.
첫 번째로, Figure 2 (a)의 back-propagation을 통한 end-to-end update 방식은 현재 미니 배치의 샘플을 딕셔너리로 사용하므로 key가 동일한 인코더의 매개변수에 의해 일관되게 인코딩된다. 그러나 딕셔너리의 크기는 미니 배치 크기와 결합되며 GPU 메모리 크기에 제한을 받는다. 최근에 제안된 몇 가지 방법들은 pretext task에 기반하는데, 이러한 경우 여러 위치에서 큰 딕셔너리 크기를 구성할 수 있다. 이러한 pretext task는 입력을 패치화하거나 수용 영역 크기를 사용자가 정의하는 등 특별한 네트워크 디자인을 요구할 수 있기에 해당 네트워크를 다른 작업으로 transfer하는 것이 복잡해질 수 있다.
두 번째로, Figure 2(b)는 memory bank 접근 방식이다. memory bank는 데이터셋의 모든 샘플의 representation을 포함한다. 각 미니 배치에 대한 딕셔너리는 memory bank에서 무작위로 샘플링되며 backpropagation은 없다. 따라서 큰 딕셔너리 크기를 지원할 수 있다. 그러나 memory bank에 있는 샘플의 representation은 마지막으로 볼 때마다 업데이트되므로 샘플링된 키들은 사실상 지난 epoch 동안의 여러 다른 단계의 인코더에 대한 것이기 때문에 일관성이 떨어진다. 저자들이 제안하는 MoCo는 모든 샘플을 추적하지 않고 기존의 memory bank 방식보다 더 메모리 효율적이며 수십억 규모의 데이터에서 훈련될 수 있다.
Pretext Task
Contrastive learning은 다양한 pretext task를 활용할 수 있다. 저자들의 초점은 새로운 사전 작업을 설계하는 데 있지 않기 때문에, pretext task로 instance discrimation을 따른다.
동일한 이미지에서 파생된 query와 key는 positive sample pair가 되고, 그렇지 않은 경우는 negative sample pair가 된다. 동일한 이미지의 두 개의 random view를 무작위 데이터 증강을 통해 positive sample pair로 구성한다. query와 key는 각각 인코더 와 에 의해 인코딩된다. 인코더는 어떤 합성곱 신경망이든지 될 수 있다.

알고리즘 1은 이 pretext task를 위한 MoCo의 pseudocode이다. 현재 미니 배치에서 query와 해당하는 key를 인코딩하여 positive sample pair을 구성한다. negative sample pair는 queue에서 가져온다.
Technical details
저자는 인코더로 ResNet을 채택하였다. 마지막 fully-connected layer(after global average pooling layer)는 fixed-dimensional output(128D)을 갖는다. 이 output 벡터는 L2-norm으로 정규화된다. 이는 query 또는 key의 representation이다. Temperature parameter τ는 0.07로 설정하였다. 데이터 증강 기법은 다음과 같다. 무작위로 크기 조정된 이미지에서 224×224 픽셀 crop을 취한 다음, random color jittering, random horizontal flip, random grayscale conversion을 수행한다.
Shuffling BN
인코더 와 는 standard ResNet과 동일하게 Batch Normalization(BN)을 갖고 있다. 실험에서 BN을 사용하면 모델이 좋은 representation을 학습하지 못하는 것으로 나타났다. BN에 의해 샘플들 사이의 intra-batch communication이 information을 누설하기 때문에 모델은 pretext task를 cheat하면서 low-loss solution을 쉽게 찾아내는 것으로 것으로 보여진다.
저자들은 이 문제를 shuffling BN으로 해결한다. 여러 개의 GPU에서 훈련하며, 각 GPU별로 샘플에 대해 독립적으로 BN을 수행한다. key 인코더 의 경우, 현재 미니 배치 내의 샘플 순서를 GPU 사이에 분산하기 전에 섞고 (인코딩 후 다시 섞음), query 인코더 의 미니 배치 샘플 순서는 변경하지 않는다. 이렇게 하면 query와 해당 positive sample을 계산하는데 사용되는 배치 통계가 두 개의 다른 부분집합에서 가져온 것임이 보장된다. 이는 효과적으로 cheating 문제를 해결하고 BN에서 학습을 더욱 유리하게 만든다.
Experiments
저자들은 두 가지 데이터셋(ImageNet-1M, Instagram-1B)을 이용하여 비지도 학습을 수행하였다.
-
ImageNet-1M (IN-1M): ImageNet 훈련 데이터셋으로, 약 1,000개의 클래스(일반적으로 ImageNet-1K라고도 함)에 약 1,280만 개의 이미지가 있다. 이 데이터셋은 클래스 분포가 균형 잡힌 것으로 잘 알려져 있다.
-
Instagram-1B (IG-1B): Instagram에서 가져온 약 10억 개(940M)의 공개 이미지 데이터셋이다. 이 이미지들은 ImageNet 카테고리와 관련된 약 1,500개의 해시태그로부터 구성되었다. 이 데이터셋은 실제 세계 데이터와 유사하게 불균형 분포를 가지고 있다.
Linear Classification Protocol
Linear classification protoccol을 위해 frozen features에서 linear classification을 하였다. 먼저 ImageNet-1M에서 unsupervised learning을 수행한다. 그 후 feature(weight)를 freeze하고 supervised linear classifier(FC-layer + softmax)를 훈련한다. 이 classifier를 ResNet의 global average pooling feature로 100 epoch 동안 훈련하였다. ImageNet validation dataset에서 1-crop, top-1 classification accuracy를 확인하였다.
저자들은 grid search를 이용하여 최적의 inital learning rate은 30이고 weight decay는 0임을 찾았다. 이러한 하이퍼파라미터 값들은 특징 분포(예: 크기)가 ImageNet 지도 학습과 크게 다를 수 있다는 문제에 대해 우리가 다시 다룰 것입니다(4.2절).
Abalation : contrastive loss mechanisms
Figure 2의 세 가지 메커니즘을 비교하였다. contrastive loss 메커니즘의 영향에 집중하기 위해 모두 동일한 pretext task 방식을 사용하였고 contrastive loss로 모두 InfoNCE를 사용히였다.
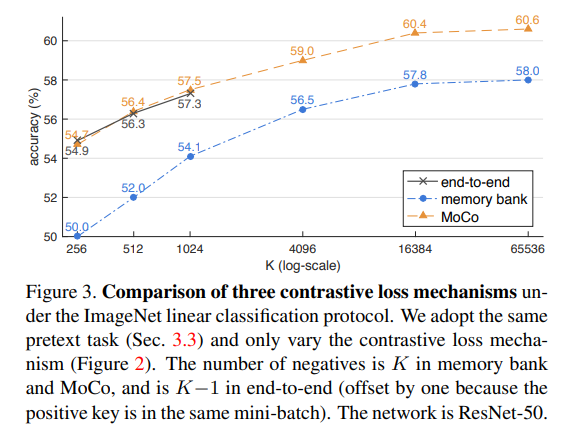
결과는 Figure 3과 같다. 전반적으로, 모든 메커니즘은 더 큰 K에서 높은 성능을 보여준다.
K가 작을 때 end-to-end 메커니즘은 MoCo와 유사하게 성능을 보여준다. 그러나 end-to-end 메커니즘은 딕셔너리 크기가 미니 배치 크기에 제한된다.
memory bank 메커니즘은 더 큰 딕셔너리 크기를 지원할 수 있다. 그러나 MoCo보다 2.6% 더 성능이 낮다. memory bank의 key들은 이전 epoch 동안 완전히 다른 인코더로부터 추출되어 일관성이 없다.
Ablation : momentum
아래 표는 MoCo의 여러 모멘텀 값들로 ResNet-50 정확도를 보여준다.
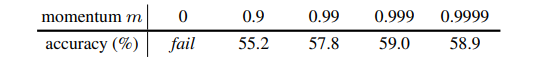
m이 0.99 ∼ 0.9999인 경우 합리적으로 잘 수행되며, 느리게 update 되는 key 인코더가 유용하다는 것을 보여준다. m이 너무 작으면 정확도가 상당히 떨어지며, 모멘텀이 없는 극단적인 경우 train loss가 진동하고 수렴하지 못한다. 이러한 결과들은 일관된 딕셔너리의 구축이 필요함을 보여준다.
Comparison with previous results
이전 비지도 학습 방법들과 공정한 비교를 위해 accuracy vs #parameters의 trade-offs를 보여준다. ResNet-50 뿐만 아니라 2배, 4배 더 넓은 채널을 가진 변형된 R50의 결과도 보여준다. K = 65536이고 m = 0.999를 설정했다. Table 1은 비교 결과이다.
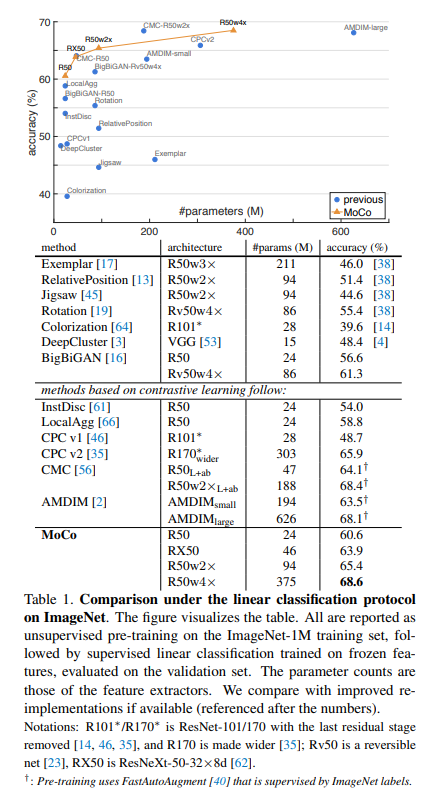
MoCo는 경쟁력 있는 성능를 보여주며 60.6%의 정확도를 달성하였다. 모델 크기가 유사한 다른 모델들보다 더 나은 결과를 보여준다. MoCo는 더 큰 모델에서 성능이 좋아지고 R50w4×에서 68.6%의 정확도를 달성하였다.
저자들이 제안한 MoCo는 특정 pretext task를 위해 customized architecture design이 필요하지 않고 standard ResNet-50을 사용하여 경쟁력 있는 결과를 보여주었다.
이 논문의 초점은 general한 contrastive learning 메커니즘에 대한 것이며, 정확도를 더 개선할 수 있는 특정 pretext task 같은 기타 요소들은 연구하지 않았다. MoCo v2는 본 논문의 초기 버전을 확장한 것으로 data augmentation 및 output projection head을 변형하여 R50로 71.1%의 정확도를 달성했다.
Transferring Features
비지도 학습의 주요 목표 중 하나는 transferrable한 feature를 학습하는 것이다. MoCo를 다양한 task에 transfer하여 ImageNet supervised pretraining과 비교하였다.
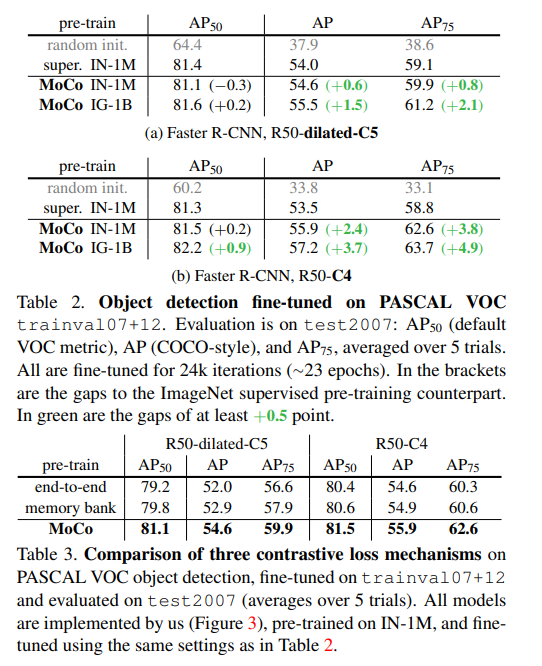
Pascal VOC 데이터셋에 fine tuning하여 object detection에 대한 학습을 진행하여 얻은 evaluation은 위 표에 그 결과가 나와있다.
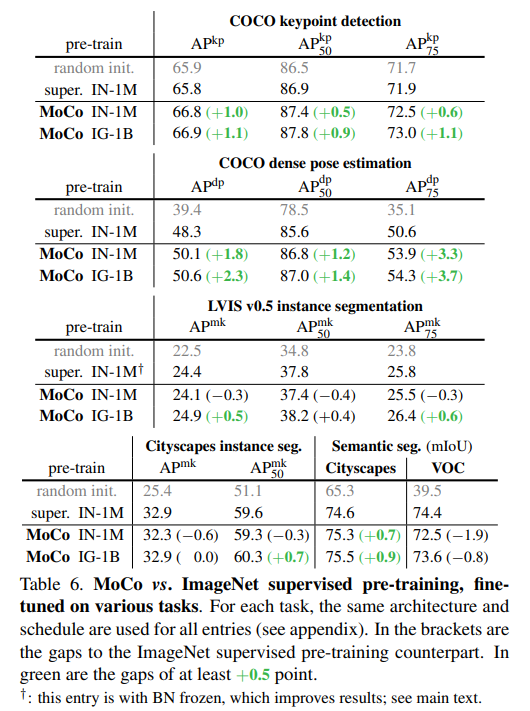
또한 COCO, LVIS, Cityscapes 에 대한 detection 및 segmentation결과이다. MoCo를 통해서 학습한 모델의 localization성능이 대부분 더 좋아지는 것을 확인할 수 있다.
Conclusion
MoCo는 크고 일관성있는 dictionary를 이용하여 ssl을 진행하며, queue와 momentum update를 이용하여 학습의 효율성을 향상 시켰다. 미니 배치 사이즈를 키우지 않고도 dictionary를 통해 더 효율적으로 negative sample을 관리하였으며, 해당 방법은 previous method에 비해서 SOTA의 성능을 보여주었다.
MoCo에서는 pretext task로 간단한 instance discrimination을 사용하였는데, 저자들은 masked auto-encoding과 같이 다양한 pretext task를 시도해볼 수 있다고 하였다.
MoCo에서 dictionary를 사용하면서 SimCLR의 문제점인 미니 배치 사이즈에 대한 의존도를 개선했지만, 여전히 딕셔너리의 사이즈에 따라 negative sample의 개수가 한정된다는 단점이 존재한다.
