이번에 따라할 노트북은 Introduction to Ensembling/Stacking in Python이다. (1)에서 전반적인 플로우를, (2)에서 EDA와 feature engineering을, (3)에서 modeling과 여러 classifiers를 집중적으로 봤다면 (4)에서는 복수의 classifiers를 결합하는 ensembling을 비중있게 다룬다.
보통 machine learning training은 training data로 model training을 하고 만들어진 model로 prediction을 한다. Ensembling은 두 개 이상의 base model을 결합하는 것이다.
그리고 stacking ensemble은 base models이 뽑은 prediction을 모아 다시 training set으로 사용해서 학습하는 방법이다. 따라서 stacking ensemble에는 first-level에서 사용할 여러 개의 base model이 필요하고 second-level에서 prediction data로 training할 다른 model이 필요하다.
여기서는 base model로 Random Forest classifier, Extra Trees classifier, AdaBoost classifeir, Gradietn Boosting classifier, Support Vector Machine, 5개를 사용했다. 그리고 second-level에서는 XGBoost를 사용했다.
Feature Engineering
Ensembling, stacking을 주로 다룬 글이기 때문에 feature engineering은 간략하게 코드만 적고 넘어간다. 이전 글과 비슷하게 진행했기 때문에 자세한 내용은 이전 글을 참조한다.
full_data = [train ,test]
# New feature : Name_length
train['Name_length'] = train['Name'].apply(len)
test['Name_length'] = test['Name'].apply(len)
# New feature : Has_Cabin
train['Has_Cabin'] = train['Cabin'].apply(lambda x: 0 if type(x) == float else 1)
test['Has_Cabin'] = test['Cabin'].apply(lambda x: 0 if type(x) == float else 1)
# New feature : FamilySize
for dataset in full_data:
dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1
# New feature : IsAlone
for dataset in full_data:
dataset['IsAlone'] = 0
dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1
# Fill null data : Embarked
for dataset in full_data:
dataset['Embarked'] = dataset['Embarked'].fillna('S')
# Fill null data : Fare
for dataset in full_data:
dataset['Fare'] = dataset['Fare'].fillna(train['Fare'].median())
# Categorize numeric feature : Fare
train['CategorialFare'] = pd.qcut(train['Fare'], 4)
# Fill null data & Categorize numeric feature : Age
for dataset in full_data:
age_avg = dataset['Age'].mean()
age_std = dataset['Age'].std()
age_null_count = dataset['Age'].isnull().sum()
age_null_random_list= np.random.randint(age_avg - age_std, age_avg + age_std, size=age_null_count)
dataset['Age'][np.isnan(dataset['Age'])] = age_null_random_list
dataset['Age'] = dataset['Age'].astype(int)
train['CategorialAge'] = pd.cut(train['Age'], 5)
# New faature : Title
def get_title(name):
title_search = re.search('([A-Za-z]+)\.', name)
if title_search:
return title_search.group(1)
return ""
for dataset in full_data:
dataset['Title'] = dataset['Name'].apply(get_title)
for dataset in full_data:
dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess', 'Capt', 'Col', 'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')
dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')
dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')
# Convert to numeric data & Simplify
for dataset in full_data:
dataset['Sex'] = dataset['Sex'].map({'female': 0, 'male': 1}).astype(int)
title_mapping = {'Mr': 1, 'Miss': 2, 'Mrs': 3, 'Master': 4, 'Rare': 5}
dataset['Title'] = dataset['Title'].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
dataset['Embarked'] = dataset['Embarked'].map({'S': 0, 'C': 1, 'Q': 2}).astype(int)
dataset.loc[dataset['Fare'] <= 7.91, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2
dataset.loc[ dataset['Fare'] > 31, 'Fare'] = 3
dataset['Fare'] = dataset['Fare'].astype(int)
dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1
dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2
dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3
dataset.loc[ dataset['Age'] > 64, 'Age'] = 4 ;
Ensembling & Stacking models
글에서는 stacking ensemble을 만들기 전에 여러 base classifier를 좀 더 편하게 다루기 위해 class를 만든다. 기존 SKlearn classifier의 train, predict, fit 함수를 extend하고 initialization 단계에서 training parameter를 정의하기 때문에 동일한 과정을 줄줄이 쓰는 수고를 덜었다.
ntrain = train.shape[0]
ntest = test.shape[0]
SEED = 0
NFOLDS = 5
kf = KFold(n_splits=NFOLDS, random_state=SEED, shuffle=True)
class SKlearnHelper(object):
def __init__(self, clf, seed=0, params=None):
params['random_state'] = seed
self.clf = clf(**params)
def train(self, x_train, y_train):
self.clf.fit(x_train, y_train)
def predict(self, x):
return self.clf.predict(x)
def fit(self, x, y):
return self.clf.fit(x, y)
def feature_importance(self, x, y):
print(self.clf.fit(x, y).feature_importances_)
return self.clf.fit(x, y).feature_importances_custom class인 SKlearnHelper는 initialize할 때 parameter로 clf, seed, params를 받는다. clf는 사용할 sklearn classifier를 뜻한다. seed는 random seed, params는 해당 clf에 사용할 parameter를 뜻한다.
Out-of-Fold Prediction
Stacking의 기본은 base classifier의 prediction을 second-level model의 training input으로 사용하는 것이다. 그러나 base classifier를 training할 때 단순히 training set 전체를 사용하여 prediction을 만들고 이를 사용하여 second-level model을 train해서는 안 된다. base model이 prediction 단계에서 이미 test set을 보았기 때문에 second-level model이 overfitting할 가능성이 커지기 때문이다.
Out-of-Fold prediction은 이처럼 stacking ensemble에서 발생할 수 있는 문제를 해결하는데 사용된다. Out-of-Fold prediction은 model training에서 사용하지 않은 데이터로 prediction하는 것을 의미한다.
def get_oof(clf, x_train, y_train, x_test):
oof_train = np.zeros((ntrain, ))
oof_test = np.zeros((ntest, ))
oof_test_skf = np.empty((NFOLDS, ntest))
for i, ((train_index, test_index)) in enumerate(kf.split(x_train)):
x_tr = x_train[train_index]
y_tr = y_train[train_index]
x_te = x_train[test_index]
clf.train(x_tr, y_tr)
oof_train[test_index] = clf.predict(x_te)
oof_test_skf[i, :] = clf.predict(x_test)
oof_test[:] = oof_test_skf.mean(axis=0)
return oof_train.reshape(-1, 1), oof_test.reshape(-1, 1)Generate First-level Models
앞서 언급한 5개의 classifier로 prediction을 만든다. 각 classifier에 사용할 parameter를 정의하고 직접 만든 SKlearnHelper class로 object를 만든다음 out-of-fold prediction을 하는 순서로 진행된다.
# Put in our parameters for classifiers
rf_params = {
'n_jobs': -1,
'n_estimators': 500,
'warm_start': True,
'max_depth': 6,
'min_samples_leaf': 2,
'max_features': 'sqrt',
'verbose': 0
}
et_params = {
'n_jobs' : -1,
'n_estimators': 500,
'max_depth': 8,
'min_samples_leaf': 2,
'verbose': 0
}
ada_params = {
'n_estimators': 500,
'learning_rate': 0.75
}
gb_params = {
'n_estimators': 500,
'max_depth': 5,
'min_samples_leaf': 2,
'verbose': 0
}
svc_params = {
'kernel': 'linear',
'C': 0.025
}
# Create 5 objects that represent our models
rf = SKlearnHelper(clf=RandomForestClassifier, seed=SEED, params=rf_params)
et = SKlearnHelper(clf=ExtraTreesClassifier, seed=SEED, params=et_params)
ada = SKlearnHelper(clf=AdaBoostClassifier, seed=SEED, params=ada_params)
gb = SKlearnHelper(clf=GradientBoostingClassifier, seed=SEED, params=gb_params)
svc = SKlearnHelper(clf=SVC, seed=SEED, params=svc_params)
# Create our OOF train and test predictions. These base results will be used as new features
et_oof_train, et_oof_test = get_oof(et, x_train, y_train, x_test)
rf_oof_train, rf_oof_test = get_oof(rf, x_train, y_train, x_test)
ada_oof_train, ada_oof_test = get_oof(ada, x_train, y_train, x_test)
gb_oof_train, gb_oof_test = get_oof(gb, x_train, y_train, x_test)
svc_oof_train, svc_oof_test = get_oof(svc, x_train, y_train, x_test)Feature importances generated from the different classifiers
First level classifier의 각 feature importance를 python의 plotly를 사용하여 interactive scatterplot으로 그렸다. plotly 코드는 생략하고 결과만 이미지로 업로드한다.
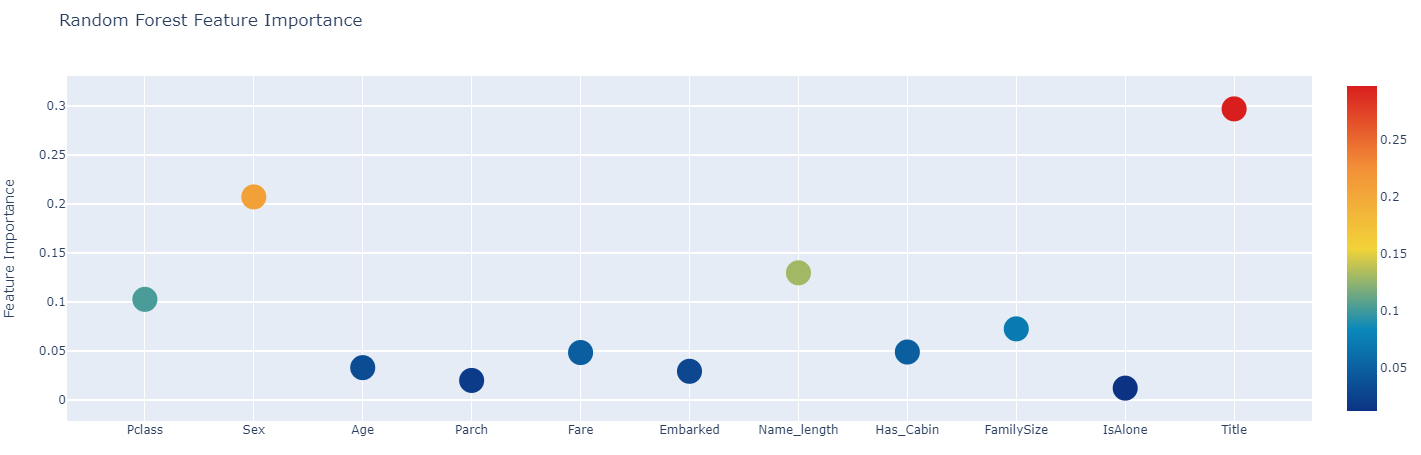
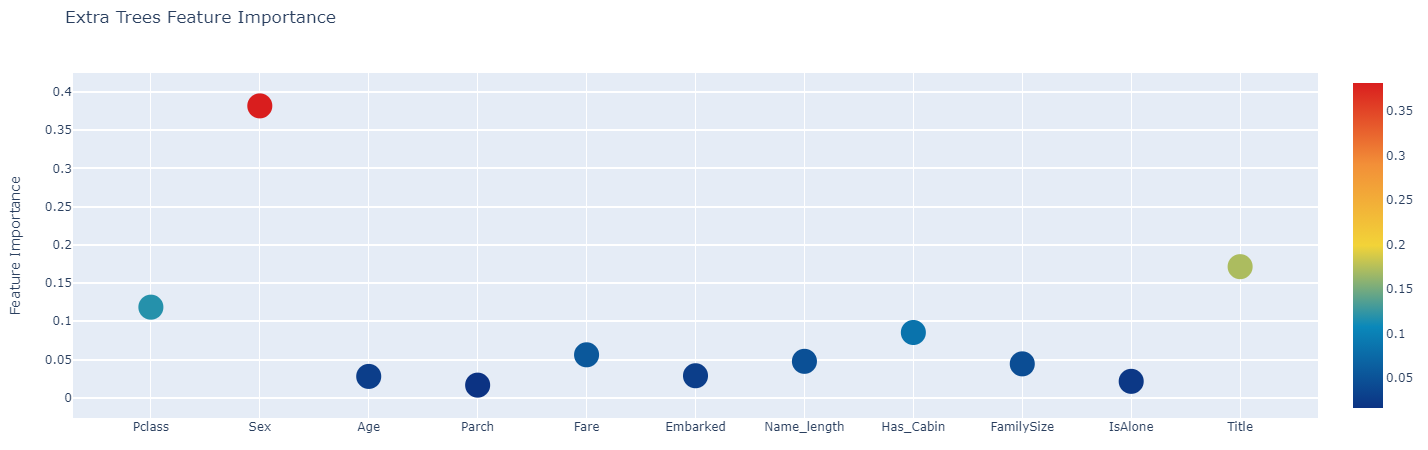
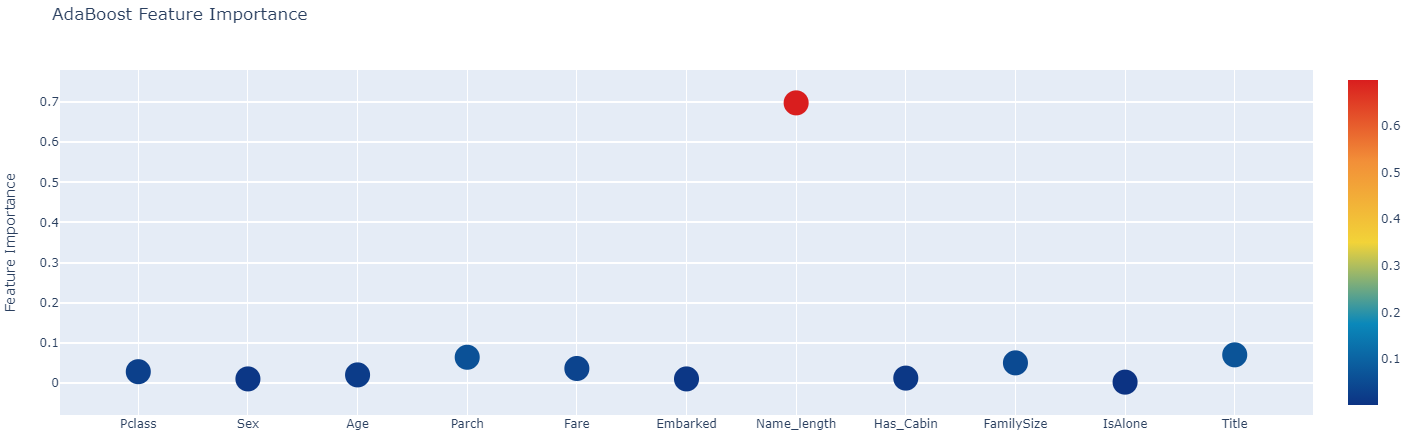
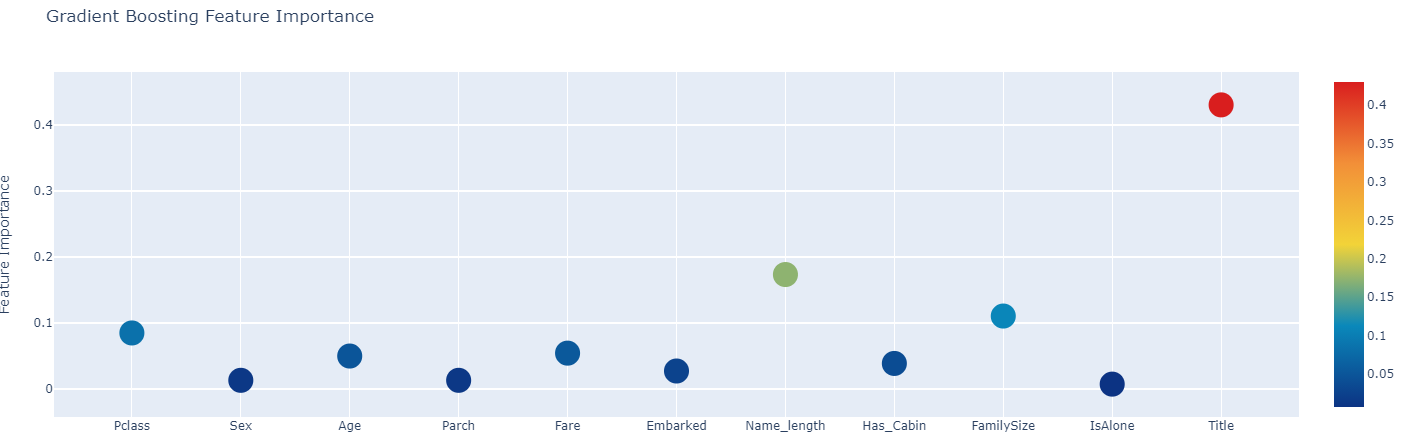
Generate Second-level Models
x_train = np.concatenate(( et_oof_train, rf_oof_train, ada_oof_train, gb_oof_train, svc_oof_train), axis=1)
x_test = np.concatenate(( et_oof_test, rf_oof_test, ada_oof_test, gb_oof_test, svc_oof_test), axis=1)
gbm = xgb.XGBClassifier(
n_estimator=2000,
max_depth=4,
min_child_weight=2,
gamma=0.9,
subsample=0.8,
colsample_bytree=0.8,
objective='binary:logistic',
nthread=-1,
scale_pos_weight=1).fit(x_train, y_train)
predictions = gbm.predict(x_test)