이번에는 Titanic Top 4% with ensemble modeling 글을 따라할 참이다. 글을 쓰는 시점에서는 score가 0.78인데 더 올릴 수 있을지 확인해보자.
Outlier Detection
이 글은 feature engineering을 하기 전에 outlier를 찾아 제거하는 과정을 거친다.
먼저 각 feature의 IQR(InterQuartile Range) 값으로 outlier 여부를 정하는 threshold를 설정한다.
이를 토대로 두 개 이상의 feature에서 outlier로 분류되는 값은 데이터에서 완전히 제거한다.
def detect_outliers(df, n, features):
outlier_indices = []
for col in features:
q1 = np.percentile(df[col], 25)
q3 = np.percentile(df[col], 75)
iqr = q3 - q1
RM EKDMA
outlier_step = 1.5 * iqr
outlier_list_col = df[(df[col] < q1 - outlier_step) | (df[col] > q3 + outlier_step)].index
outlier_indices.extend(outlier_list_col)
outlier_indices = Counter(outlier_indices)
multiple_outliers = list(k for k, v in outlier_indices.items() if v > n)
return multiple_outliers
outliers_to_drop = detect_outliers(train, 2, ['Age', 'SibSp', 'Parch', 'Fare'])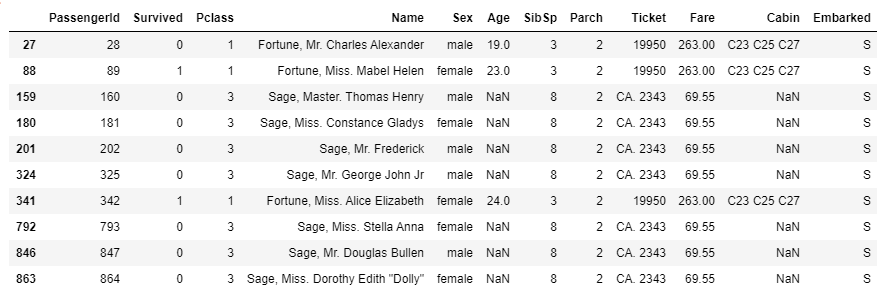
fare 혹은 sibsp 값이 매우 높은 사람을 outlier로 판단했다.
Filling missing values
그 다음 null 값을 제거하였다. fare는 null값이 1개여서 median으로 보간하고 embarked는 2개여서 mode로 보간했다. null 값이 많은 age와 cabin에 좀 더 집중하였다.
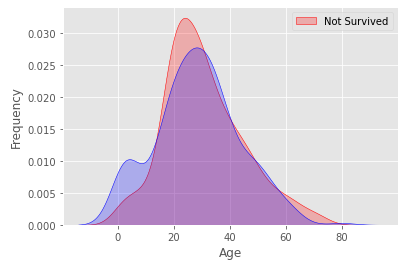
Age에서 두드러지는 점은 20살 이하 어린 계층에서 생존 확률이 높게 나왔다는 점이다. null 값을 가진 row에서 어린 계층을 뽑아내면 잘 보간했다고 볼 수 있다.
따라서 어떤 feature가 age와 밀접한 관련이 있는지 살펴보았다.
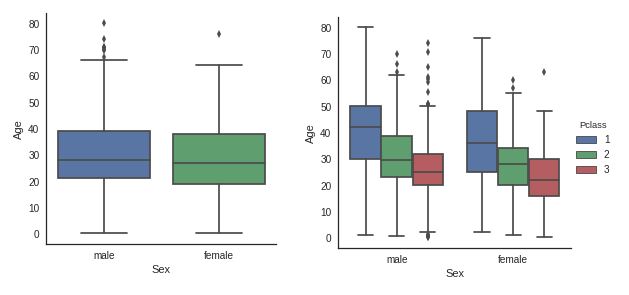
성별에 따라 나이 편차가 보이지 않으나 pclass에서는 높은 계급의 사람이 나이도 많은 것을 볼 수 있다.
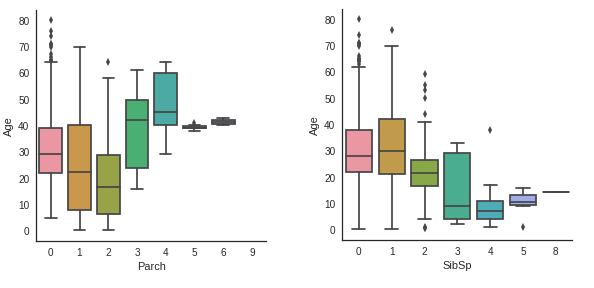
Parch 값이 큰 승객일수록 나이가 많고, SibSp 값이 큰 승객일수록 나이가 적었다.
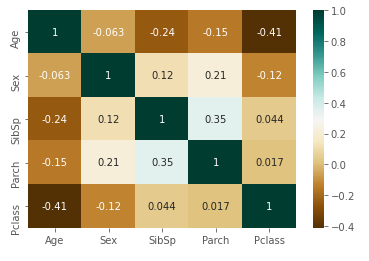
Heatmap으로 correlation을 살펴보면 Sex를 제외하고 SibSp, Parch, Pclass, 세 개의 feature가 Age와 관련있다는 것을 알 수 있다. 따라서, Age null 값을 메꾸기 위해 사용하는 feature로 SibSp, Parch, Pclass를 선택하였다.
SibSp, Parch, Pclass가 동일한 row를 모아 median을 구하고 그 값을 null 대신 채웠다. 만약 모두 동일한 사람이 없다면 전체 Age의 median으로 채웠다.
Feature Engineering
이 글 역시 이름에서 Mr, Mrs, Miss 등의 정보를 추출하여 새로운 feature를 만들었다.
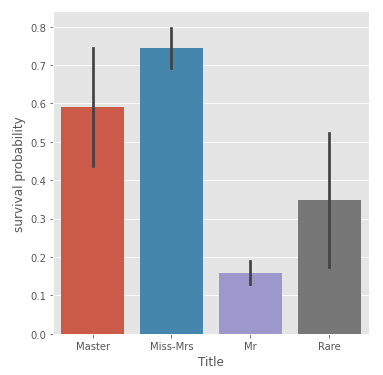
여성인 Miss-Mrs와 아이인 Master의 생존 확률이 높다는 것을 알 수 있다.
SibSp와 Parch의 경우 둘을 묶어 가족 인원 수를 구하고 크게 4개의 그룹으로 나누었다.
dataset['Fsize'] = dataset['SibSp'] + dataset['Parch'] + 1
dataset['Single'] = dataset['Fsize'].map(lambda s: 1 if s == 1 else 0)
dataset['SmallF'] = dataset['Fsize'].map(lambda s: 1 if s == 2 else 0)
dataset['MedF'] = dataset['Fsize'].map(lambda s: 1 if 3 <= s <= 4 else 0)
dataset['LargeF'] = dataset['Fsize'].map(lambda s: 1 if s >= 5 else 0)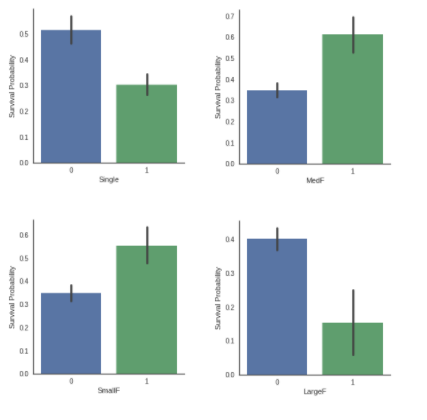
가족 구성원이 2~4명에 해당하는 Small과 Medium에서 생존 확률이 높다는 것을 알 수 있다.
Embarked feature와 새로 만든 Title feature에 one-hot encoding을 적용한다.
dataset = pd.get_dummies(dataset, columns=['Title'])
dataset = pd.get_dummies(dataset, columns=['Embarked'], prefix='Em')Cabin
이전과 다르게 이 글은 null값이 많은 cabin을 버리지 않았다. null값을 갖는 승객이 cabin을 갖지 않았다고 해석하였다. (cabin이 선실인지 몰랐다)
cabin에서 null 값을 임의의 글자(여기서는 X)로 치환하였다.
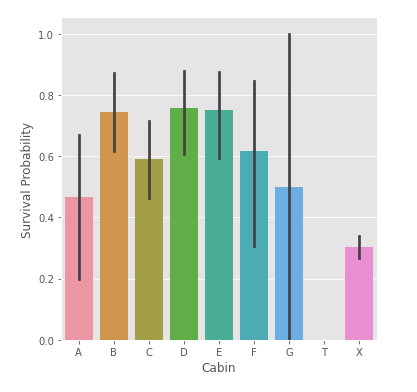
Cabin을 가진 승객이 워낙 적어 이렇다할 분석을 하기 힘들지만 Cabin이 없는 사람(X)보다 있는 사람의 생존 확률이 더 높은 것만은 알 수 있다. 특히 B, C, D, E, F가 그러하다. 이것 역시 one-hot encoding을 적용한다.
Ticket
Ticket 역시 cabin과 비슷한 과정을 거쳤다. Ticket 이름이 Cabin과 관련있다는 가정 하에 prefix가 같으면 cabin이 선상에서 가까이 위치해있을 거라 추측한 것 같다. 따라서, Ticket에서 prefix를 추출하여 Ticket feature를 수정하였다.
마지막으로 Pclass에 one-hot encoding을 적용하고 나면 training에 사용할 데이터 준비가 끝난다.

Modeling
kfold cross validation을 사용하여 classifier의 accuracy를 비교하였다. 사용한 classifier는 총 10개로 다음과 같다.
- SVC
- Decision Tree
- AdaBoost
- Random Forest
- Extra Trees
- Gradient Boosting
- Multiple layer perceptron
- KNN
- Logistic Regression
- Linear Discriminant Analysis
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, GradientBoostingClassifier, ExtraTreesClassifier, VotingClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV, cross_val_score, StratifiedKFold, learning_curve
kfold = StratifiedKFold(n_splits=10)
random_state=2
classifiers=[]
classifiers.append(SVC(random_state=random_state))
classifiers.append(DecisionTreeClassifier(random_state=random_state))
classifiers.append(AdaBoostClassifier(DecisionTreeClassifier(random_state=random_state), random_state=random_state, learning_rate=0.1))
classifiers.append(RandomForestClassifier(random_state=random_state))
classifiers.append(ExtraTreesClassifier(random_state=random_state))
classifiers.append(GradientBoostingClassifier(random_state=random_state))
classifiers.append(MLPClassifier(random_state=random_state))
classifiers.append(KNeighborsClassifier())
classifiers.append(LogisticRegression(random_state=random_state))
classifiers.append(LinearDiscriminantAnalysis())
cv_results = []
for classifier in classifiers:
cv_results.append(cross_val_score(classifier, x_train, y=y_train, scoring='accuracy', cv=kfold, n_jobs=-1))
cv_means = []
cv_std = []
for cv_result in cv_results:
cv_means.append(cv_result.mean())
cv_std.append(cv_result.std())
cv_res = pd.DataFrame({"CrossValMeans":cv_means, "CrossValerrors": cv_std, "Algorithm": ['SVC', 'DecisionTree', 'AdaBoost', 'RandomForest', 'ExtraTrees', 'GradientBoosting', 'MultipleLayerPerceptron', 'KNeighbors', 'LogisticRegression', 'LinearDiscriminantAnalysis']})
g = sns.barplot('CrossValMeans', 'Algorithm', data=cv_res, palette='Set3', orient='h', **{'xerr': cv_std})
g.set_xlabel('Mean Accuracy')
g = g.set_title('Cross validation scores')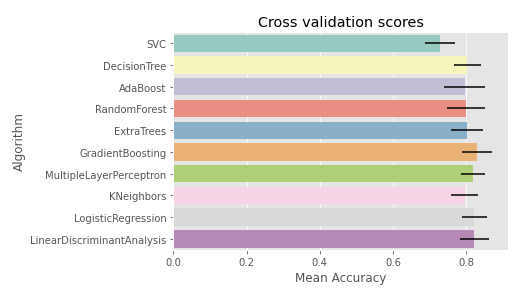
이 글에서는 SVC, AdaBoost, RanomForest, ExtraTrees, GradientBoosting을 ensemble modeling에 사용하였다. 선정 기준은 모르겠으나 그대로 따라해보자.
Hyperparameter tunning
SVC, AdaBoost, RanomForest, ExtraTrees, GradientBoosting 각각 grid search optimization을 사용했다.
1. SVC
SVMC = SVC(probability=True)
svc_param_grid = {
'kernel': ['rbf'],
'gamma': [ 0.001, 0.01, 0.1, 1],
'C': [1, 10, 50, 100,200,300, 1000]
}
gsSVMC = GridSearchCV(SVMC,param_grid = svc_param_grid, cv=kfold, scoring="accuracy", n_jobs= 4, verbose = 1)
gsSVMC.fit(x_train,y_train)
SVMC_best = gsSVMC.best_estimator_
SVMC_best_score = gsSVMC.best_score_- AdaBoost
DTC = DecisionTreeClassifier()
adaDTC = AdaBoostClassifier(DTC, random_state=7)
ada_param_grid={
'base_estimator__criterion': ['gini', 'entropy'],
'base_estimator__splitter' : ['best', 'random'],
'algorithm': ['SAMME', 'SAMME.R'],
'n_estimators': [1, 2],
'learning_rate': [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3, 1.5]
}
gsadaDTC = GridSearchCV(adaDTC, param_grid=ada_param_grid, cv=kfold, scoring='accuracy', n_jobs=-1, verbose=1)
gsadaDTC.fit(x_train, y_train)
ada_best = gsadaDTC.best_estimator_
ada_best_score = gsadaDTC.best_score_- RandomForest
RFC = RandomForestClassifier()
rf_param_grid = {
'max_depth': [None],
'max_features': [1, 3, 10],
'min_samples_split': [2, 3, 10],
'min_samples_leaf': [1, 3, 10],
'bootstrap': [False],
'n_estimators': [100, 300],
'criterion': ['gini']
}
gsRFC = GridSearchCV(RFC, param_grid=rf_param_grid, cv=kfold, scoring='accuracy', n_jobs=-1, verbose=1)
gsRFC.fit(x_train, y_train)
RFC_best = gsRFC.best_estimator_
RFC_best_score = gsRFC.best_score_- ExtraTrees
ExtC = ExtraTreesClassifier()
ex_param_grid = {
'max_depth': [None],
'max_features': [1, 3, 10],
'min_samples_split': [2, 3, 10],
"min_samples_leaf": [1, 3, 10],
"bootstrap": [False],
'n_estimators': [100, 300],
"criterion": ['gini']
}
gsExtC = GridSearchCV(ExtC, param_grid=ex_param_grid, cv=kfold, scoring='accuracy', n_jobs=-1, verbose=1)
gsExtC.fit(x_train, y_train)
ExtC_best = gsExtC.best_estimator_
ExtC_best_score = gsExtC.best_score_- GradientBoosting
GBC = GradientBoostingClassifier()
gb_param_grid = {
'loss': ['deviance'],
'n_estimators': [100, 200, 300],
'learning_rate': [0.1, 0.05, 0.01],
'max_depth': [4, 8],
'min_samples_leaf': [100, 150],
'max_features': [0.3, 0.1]
}
gsGBC = GridSearchCV(GBC, param_grid=gb_param_grid, cv=kfold, scoring='accuracy', n_jobs=-1, verbose=1)
gsGBC.fit(x_train, y_train)
GBC_best = gsGBC.best_estimator_
GBC_best_score = gsGBC.best_score_Feature Importance
AdaBoosting, ExtraTrees, RandomForest, GradientBoosting classifier가 prediction할 때 어떤 feature의 영향력을 많이 받았는지 알아보자. 상위 feature 중에서 겹치는 feature는 생존 확률과 비교적 연관되어있다고 결론을 내릴 수 있다.
nrows = ncols = 2
fig, axes = plt.subplots(nrows = nrows, ncols = ncols, sharex="all", figsize=(15,15))
names_classifiers = [("AdaBoosting", ada_best),("ExtraTrees",ExtC_best),("RandomForest",RFC_best),("GradientBoosting",GBC_best)]
nclassifier = 0
for row in range(nrows):
for col in range(ncols):
name = names_classifiers[nclassifier][0]
classifier = names_classifiers[nclassifier][1]
indices = np.argsort(classifier.feature_importances_)[::-1][:40]
g = sns.barplot(y=x_train.columns[indices][:40],x = classifier.feature_importances_[indices][:40] , orient='h',ax=axes[row][col])
g.set_xlabel("Relative importance",fontsize=12)
g.set_ylabel("Features",fontsize=12)
g.tick_params(labelsize=9)
g.set_title(name + " feature importance")
nclassifier += 1 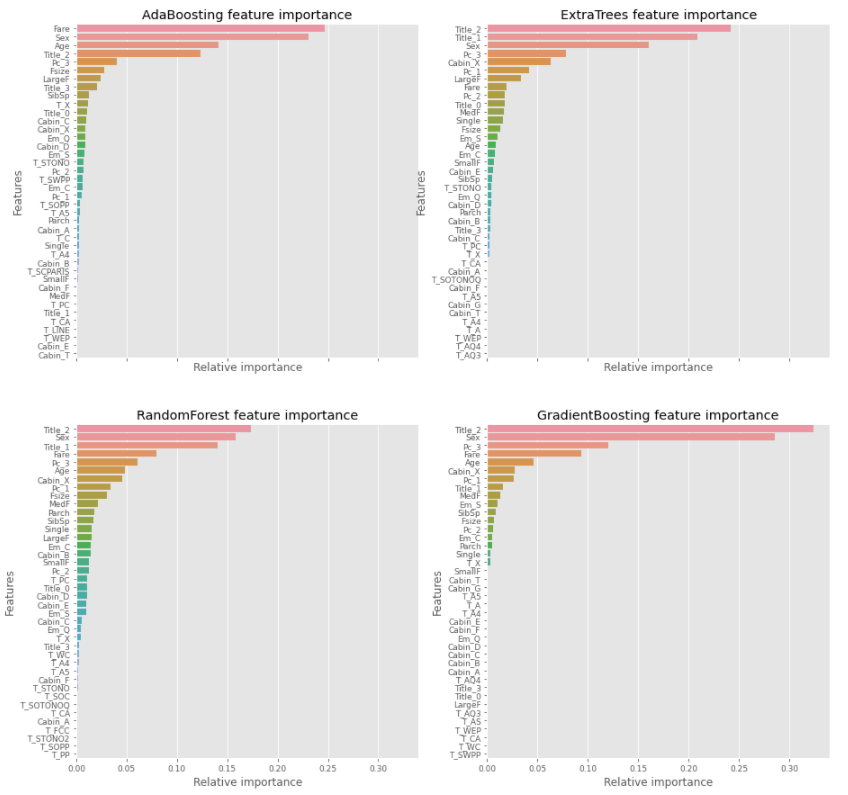
각 classifier에서 top4를 정리하면 다음과 같다.
| Rank | AdaBoosting | ExtraTrees | RandomForest | GradientBoosting |
|---|---|---|---|---|
| 1 | Fare | Title 2 (Sex) | Title 2 (Sex) | Title 2 (Sex) |
| 2 | Sex | Title 1 (Age) | Sex | Sex |
| 3 | Age | Sex | Title 1 (Age) | Pc_3 |
| 4 | Title 2 (Sex) | Pc_3 | Fare | Fare |
공통적으로 Fare, Sex, Age 관련 feature가 top rank에 속해있다. Title 1은 Master로 Age와 관련된 변수이고 Title 2는 Miss/Mrs로 Sex와 관련된 변수이다.
Ensemble Modeling
이 글에서는 voting classifier로 앞서 말한 5개의 classifier를 결합했다.
votingC = VotingClassifier(estimators=[('rfc', RFC_best), ('extc', ExtC_best), ('svc', SVMC_best), ('adac', ada_best), ('gbc', GBC_best)], voting='soft', n_jobs=-1)
votingC = votingC.fit(x_train, y_train)
test_survived = pd.Series(votingC.predict(test), name='Survived')
results = pd.concat([idtest, test_survived], axis=1)결과

점수가 0.77751이 나왔다. 기존의 점수와 비슷하게 나왔다. Nonnumeric feature를 가공하고 classifier를 다루는 부분에서 많은 것을 배웠다.
