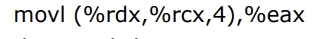
Array, Pointer, and Structure
Derived types
C언어의 기본타입(Basic types) 중 float을 다룬적이 있다. 이번엔 기본 타입의 확장(Derived types) 중 세 가지를 다룰 것이다.
C언어의 pointer, array, strcture의 기본 문법이 아닌 내부 동작 방식을 어셈블리어로 확인하며 알아보자.
기본적인 연산자 중 (), [], *, & 연산자들을 알아보자.
- (): 함수의 매개변수 선언부이다.
- []: 배열의 선언이나 인덱싱 연산자이다.
- *: 주소의 값을 참조하는 역참조 연산자이다.
- &: 주소를 반환하는 주소 연산자이다.
Array
array는 프로그래밍 언어의 초반부에서부터 등장하는 자료구조이다.
특징
- 인접한(contiguosly) 메모리에 할당된다.
- 같은 타입(homogeneous)의 데이터를 저장한다.
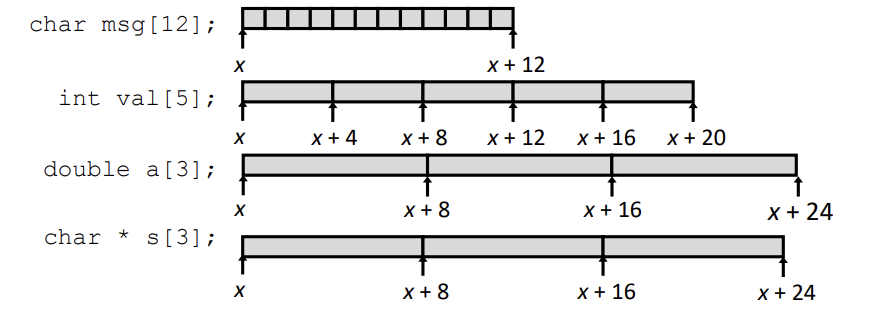
- 배열의 크기는 N*K이다.(N은 원소의 개수이고 K는 데이터 타입의 크기이다.)
- 배열의 식별자(identifier) A는 배열의 시작 주소(첫 번째 원소의 주소)를 반환한다.
식별자 A는 포인터처럼 사용된다.
A == A[0], (A + i) == A[i], &A[2] == A+2
초기화 방법 등을 제외하고, 배열은 포인터와 거의 비슷하게 동작한다.
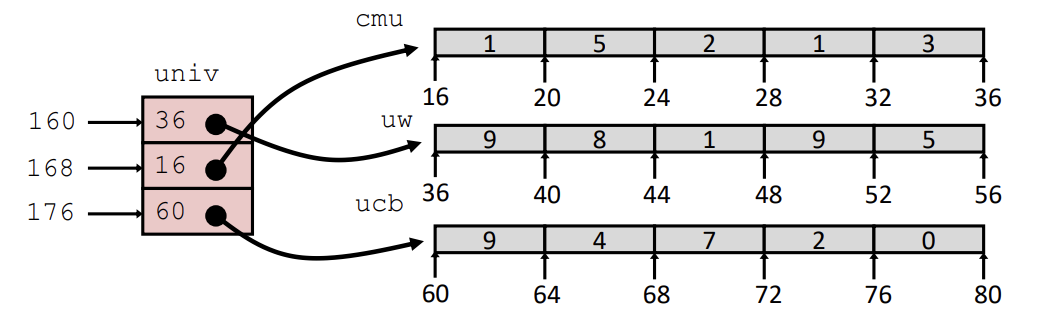
위의 사진은 배열의 indexing 방식이다. 데이터 크기만큼 배열의 시작 주소에 더해 원소를 참조한다.
정수 타입의 A[3]은 내부적으로 A + 12(4 * 3)가 된다.
배열 데이터의 저장공간
배열은 식별자와 크기만 저장하면 된다. 그 이후엔 저장된 데이터 타입의 크기를 사용하여 원소에 접근한다.
- 식별자 A(시작주소)는 %rdx에 저장한다.
- 인덱스는 %rcx에 저장한다.
위의 사진은 네 번째 인덱스의 원소를 %eax 레지스터에 옮기는 어셈블리어이다.
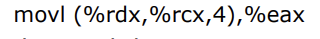
Two-Dimensional Array
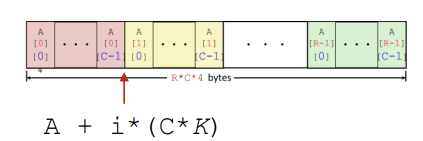
- 배열의 크기는 RCK이다.(R:row, C:column)
- A[i]는 내부적으로 A + (C*K)*i가 된다.
- A[i][j]는 내부적으로 A + (C*K)*i + j*K가 된다.
2d array in assembly code

Multi-Level Array

위의 사진과 같이 포인터 배열을 만들어 배열을 저장할 수 있다.
위는 배열의 이미지이다. 크기는 Size*8 이다.


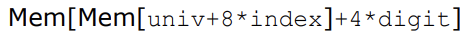
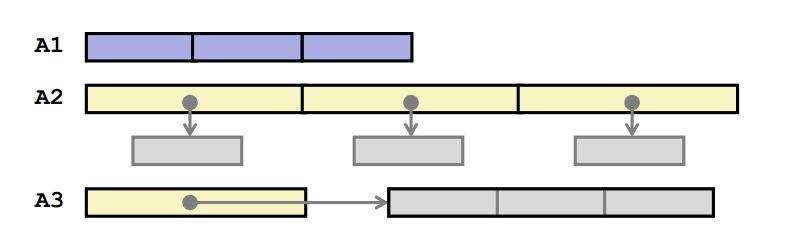
어셈블리어를 보면 메모리 참조를 두 번 하는 모습을 볼 수 있다. addq 부분에서 한 번, movl 부분에서 두 번 읽어온다.
Pointer
Pointers to functions
함수 포인터를 알아보자. C언어에서 함수는 변수가 아니지만 함수의 주소를 저장할 수 있는 함수 포인터가 존재한다.
- 선언은 int (*f)(para) 형태로 한다.
- f = function_name; 형태로 값을 저장한다.
- (* f)(arg); 형태로 함수를 호출한다.

함수 포인터도 일반 포인터와 같이 8 bytes의 크기를 가진다. 일반 함수의 크기는 1 byte이다.
f5 포인터 부분을 보면 리턴타입과 매개변수가 void *인 함수의 주소를 가리키는 3개의 포인터 배열이기 때문에
크기가 24 bytes 이다.
c언어의 포인터와 배열을 조합한 선언을 보고 크기와 어떤 기능을 하는지 알아보자.
- int A1[3]: 정수형 데이터 3개를 원소로 가지는 배열이다. 12 bytes
- int *A2[3]: []의 우선순위가 더 높기 때문에 정수형 포인터 변수 3개를 가지는 배열이다. 24 bytes
- int (*A3)[3]: ()의 우선순위가 더 높기 때문에 정수형 데이터 3개를 가지는 배열을 가리키는 포인터이다. 8 bytes
- int *A1[3][5]: 2번과 같은 이유로 크기는 120 bytes이다.
- int (*A2)[3][5]: 3번과 같은 이유로 8 bytes이다.
- int (*A3[3])[5]: 2,3번과 같은 이유로 24 bytes이다. 정수형 데이터 5개를 가지는 3개의 배열의
주소를 원소로 가진다.
- int (*(*x[3])())[5]: 좀 어려운 놈이다. 매개변수가 없는 3개의 함수의 주소를 가지는 함수 포인터 배열이다.
5개의 배열의 주소를 가지는 정수형 포인터를 리턴한다.
Structure
배열이 같은 타입(homogeneous)의 데이터를 저장하는 타입이었다면, 구조체(Stucture)는
다른 타입(Heterogeneous)을 데이터를 저장하는 타입이다.

특징
- 배열과 동일하게 밀접한(contiguously) 공간에 할당된다.
- 구조체의 식별자는 구조체의 원소의 첫 번째 주소를 가지고 있다.
- a, i, next 선언된 순서대로 저장된다.
- 순서에 따라 구조체의 할당된 크기가 달라진다.
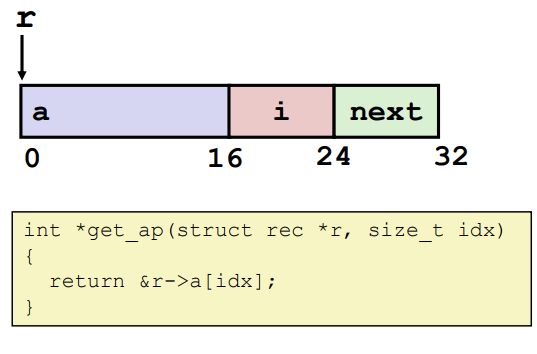
위 사진을 보면 r 구조체의 원소인 a배열에 접근하는 것을 확인할 수 있는데, 이는 배열의 인덱싱과 동일하게 작용한다. 데이터 타입의 크기(byte)를 구조체의 식별자에 더하여 원소에 참조한다.

어셈블리어를 확인해보자.
The size of structure changes depending on order of elements
x86-64 standard
"순서에 따라 구조체의 할당된 크기가 달라진다."라는 구조체의 특징은 구조체의 원소가 메모리에 할당될 때
K(data type)의 배수에 저장한다. 예를 들어, short type을 원소가 가진다면 원소의 시작주소는 2의 배수에 맞추어 메모리에 할당해야한다. char 타입은 1 byte이기 때문에 이러한 제약을 받지 않는다.
두 번째로 구조체의 끝 부분 주소가 가장 큰 원소의 배수여야한다는 점이다. int, double, short 타입의 원소를 세 개 가지는 구조체가 있다면 구조체의 주소 마지막 부분은 8의 배수여야한다.
이를 모두 충족한 상태를 Aligned 라고 칭한다.
offset
offset은 구조체의 시작주소에 +된 수를 의미한다. 예를 들어 구조체 A의 시작주소가 5이고, 원소에 정수 타입 데이터가 두 개 있다면, 첫 번째 데이터의 offset은 5이고 두 번째 데이터의 offset은 9이다.

Unaligned Data

Aligned Data

Array of structures

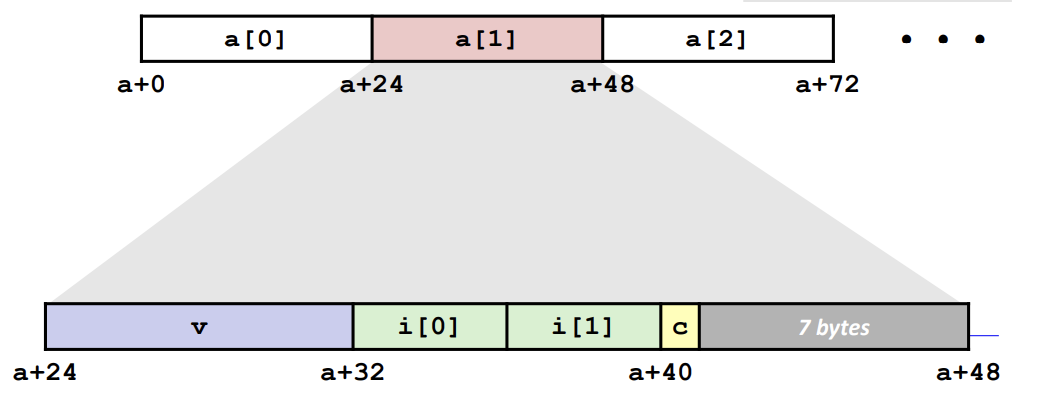
가장 큰 K의 배수로 구조체의 마지막 주소를 맞춰야 하는 이유는 위의 사진과 같다. 구조체를 배열로 사용할 때의 인덱싱을 위해서이다.


구조체 배열을 어셈블리어로 확인해보자. 이 구조체의 크기는 12 bytes이다.
그렇다면 배열은 12의 배수인 주소값을 가지고 있다. idx * 12로 인덱싱을 하고 그 구조체의 시작 주소 + 8로 j를 참조하는 것을 확인할 수 있다.
