하나의 processor에서 여러 instruction을 동시에 실행해 속도를 더 빠르게 할 수 있다.
이렇게 동시에 여러 개의 instruction을 수행하는 것을 Instruction-Level Parallelism(ILP)이라 한다.
(멀티 프로세서와 다르다.)
ILP를 증가시키려면 두 가지의 옵션이 있다.
이전에 본 pipeline이다. pipeline의 stage를 증가시키면, ILP가 증가한다.
왜냐하면 stage가 5개면, 5개의 instruction이 동시에 수행된다. 10개인 경우엔 동시에 많은 instruction이 수행될 것이다.
그러나 한계가 존재한다. stage에 대한 task는 정해져있기 때문이다. 시간을 균등하게 분배하여 stage를 나눌 수 없다.
Multi issue
Multi issue란 pipe line을 여러 개 만드는 것을 의미한다. 만약 두 개의 pipeline이 존재한다면, 두 개의 instruction이 동시에 실행되고, 이에 대한 pipeline도 두 개씩 수행된다.
하나의 processor에 ALU 추가, datapath를 추가하여 구현할 수 있다.
그럼 CPI는 1보다 작아진다. Instruction Per Cycle로 보면, 1보다 커지는 것이다.
4GHz 컴퓨터에서 4-way multiple issue라면 16GHz로 수행할 수 있다. 이는 16 BIPS라 부른다.
그러나 의존성 문제가 더 많이 발생한다.
두 가지의 multiple-issue를 알아보자.
- Static multiple issue(Software): 컴파일러가 instruction을 그룹(issue slot)화하고 hazard를 감지하고 피한다.
- Dynamic multiple issue(Hardware): instruction 여러개를 읽어오고, 실시간으로 동시에 실행할 수 있는 instruction을 확인하고 괜찮으면 묶어준다.
컴파일러가 도와줄 수 있다.
hazard를 실시간으로 감지한다.
static multiple issue는 사실 reordering이다. 같이 수행될 수 있는 instruction들을 재배열하는 것이다.
당연히 dynamic multiple issue도 reordering이 발생한다.
dynamic branch prediction도 reordering이 발생한다. 이와 비슷하게 dynamic multiple issue도 reorder을 하여, instruction을 묶어 수행하다. 문제가 생기면 복원한다.
Speculation
예측을 개념화한 것이다. branch prediction도 이 개념을 사용하여 예측한다.
reorder한 것을 일단 실행하고, 나중에 correctness를 확인한다. 그리고 correct하지 않으면, rollback한다.
과정
multiple issue를 위한 reorder -> 수행 -> speculation -> wrong -> rollback
Compiler Speculation
컴파일러가 하는 추정은 만약 wrong하다면 rollback해야한다. reorder된 instruction 중간에 detect instruction이 필요하며, 만약 rollback 해야하는 상황을 위한 라이브러리 루틴도 존재한다.(오버헤드가 크고 하드웨어적으로 단순한다.)
Hardware Speculation
하드웨어 같은 경우, 추정하고 바로 결과 반영을 하지 않는다. 버퍼에 저장해 놓은 후, correct를 판별한다. 맞을 경우 반영하고 아닐 경우 다시 instruction을 수행한다.(rollback)
Exceptions
만약 추정해서 예외가 발생하면 어떻게 될까?
일어나지 않아야할 경우에 예외를 발생시키면 안 되기 때문에, 예외를 추정했더라도 조금 delay하고 correct를 판별하고 rollback 한다. 만약 correct면 발생시킨다.
VLIW
Static Multiple issue의 경우, instruction을 묶어 issue packets으로 변경하기 때문에, 하드웨어에게는 여러 task를 가진 하나의 instruction으로 받아들여질 것이다.
이를 Very Long Instruction Word(VLIW)라 부른다.
Hazards
이젠 pipeline때 처럼, 앞뒤 instruction뿐만 아니라, packet안의 instruction들, 가까운 packet 등을 고려해야한다. 이는 ISA마다 다르다.
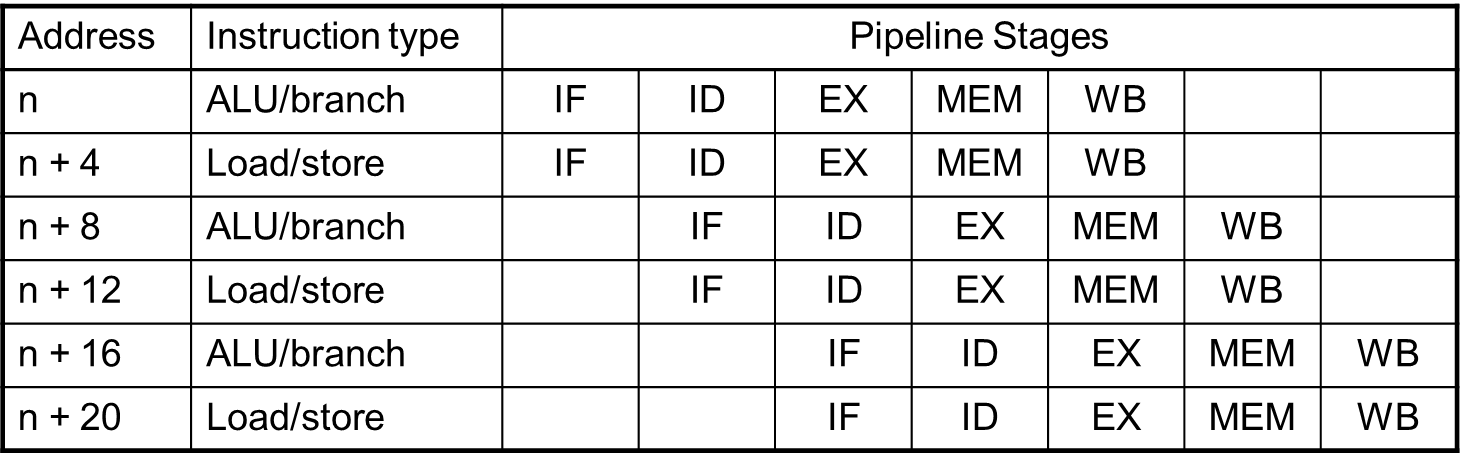
MIPS with static 2-way Issue
ALU/branch와 load/store을 분류하여 pipeline을 두 개로 만든 MIPS 2-way issue를 알아보자.
그럼 한 번에 레지스터를 네 번 읽을 수 있어야하며, 두 번 레지스터에 write할 수 있어야 한다.
ALU도 두 개가 필요하다.
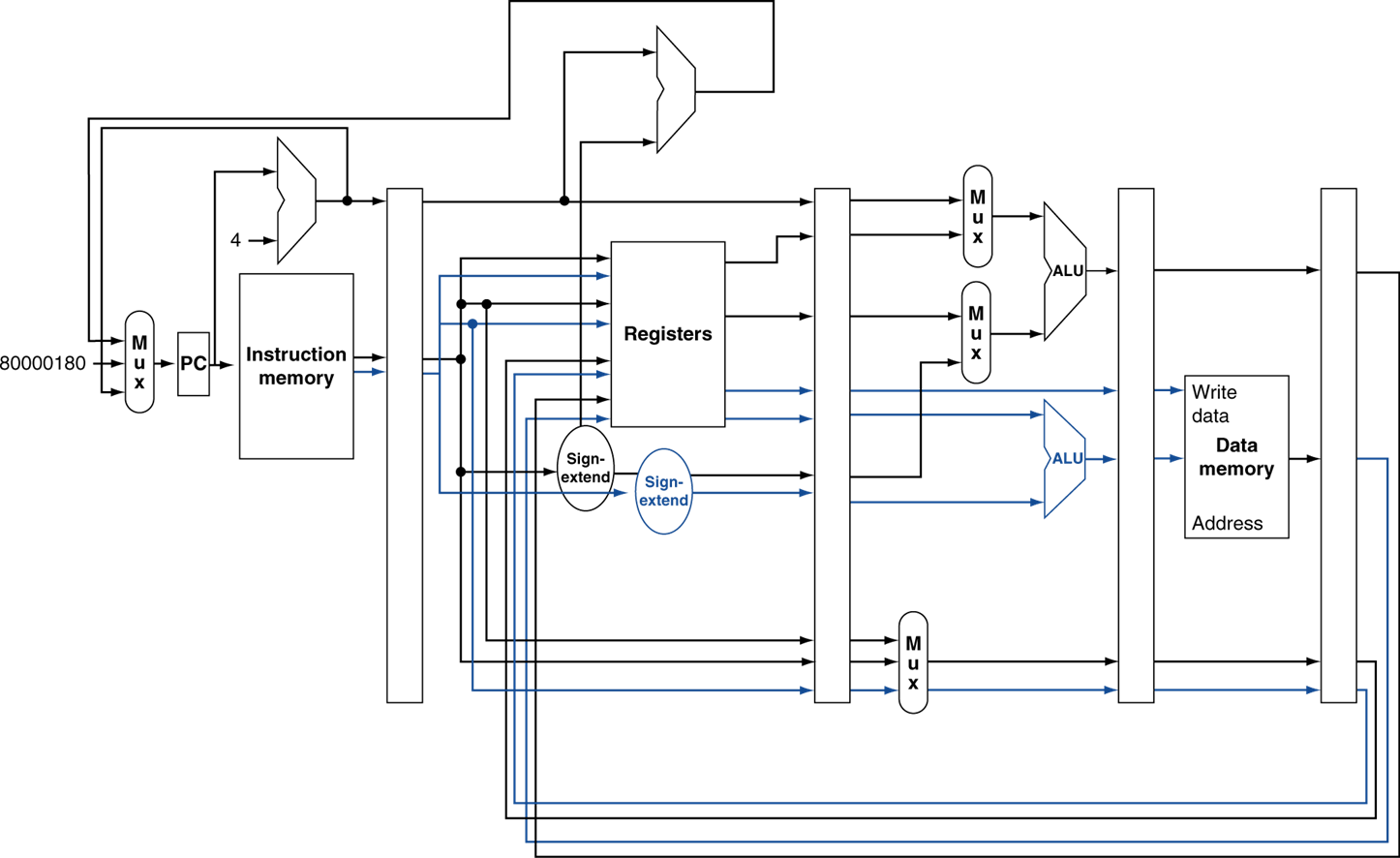
read를 위한 path 네 개 그리고 wrtie을 위한 path 네 개(레지스터 번호와 값)가필요하다.
Hazards in the 2-way Issue
EX data hazard가 존재하지만 이는 이전에 보았던 것과 같다. 그러나 multiple-issue에선 해결할 수 없다. 떼어 놓아야 한다. 그럼 한 사이클 stall이 발생한다.
Load-use hazard 얘는 무조건 한 사이클 stall이였는데, 현재 instruction 두 개를 동시에 수행하니 2 cycle stall이 발생한다.
그러므로 scheduling이 강하게 요구된다.

IPC=1.25
무조건 4 cycle이 요구된다. 이를 해결할 수 있는 방법이 있을까?
loop를 풀면 된다. 여러 loop에서 수행해야할 것을 한 번에 수행하면 굉장히 빨라질 것이다.
그러나 반복 횟수가 홀수면은 안 된다. 적어도 반복 횟수가 몇의 배수인지 알아야 한다.
unrolling한 만큼의 레지스터가 추가적으로 필요하다.
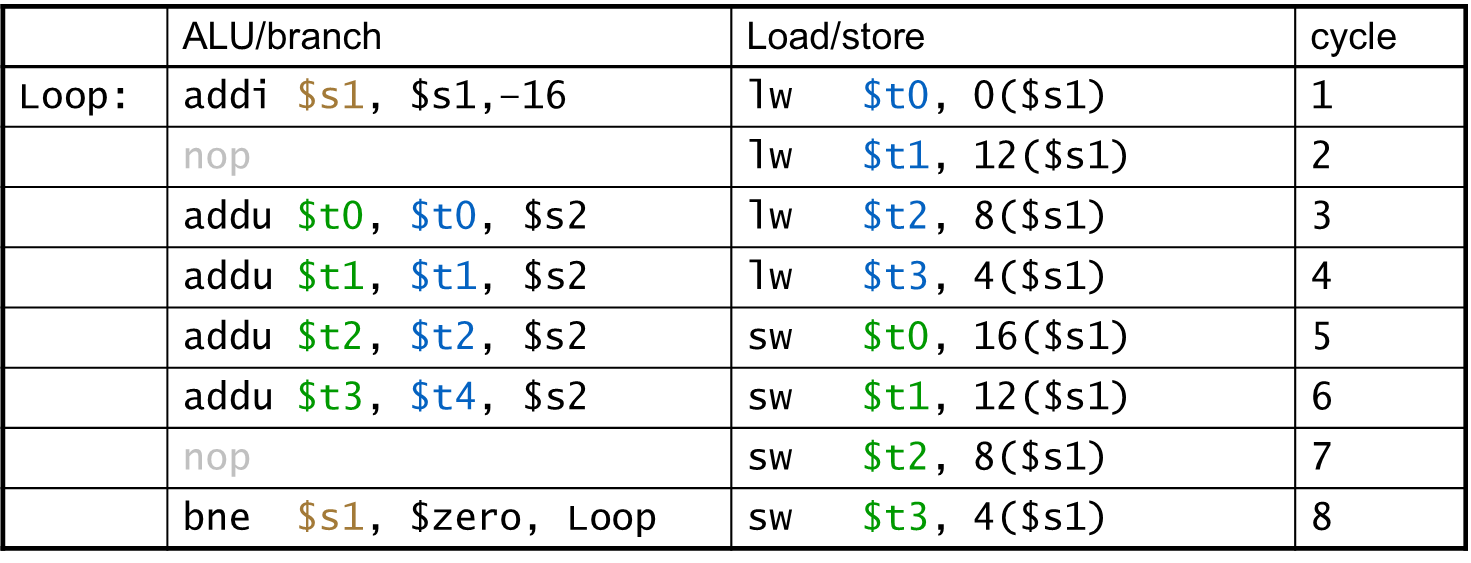
IPC=1.75
4번의 loop를 하나의 loop로 만들었다. 3개의 레지스터가 더 필요하다.
단점으로 레지스터가 많이 필요하고 소스코드가 길어진다.
Dynamic Multiple Issue
Superscalar processor가 dynamic multiple issue를 보장한다. CPU안의 하드웨어가 다 처리한다.
컴파일러가 도와주지 않아도 동작한다. 컴파일러가 잘못 컴파일 해도, 알아서 rollback 가능하다.
reorder후 issue는 out-of-order로 되지만, 실제의 코드 순서인 in-of-order의 결과값과 동일하게 수행됨을 보장해야한다.
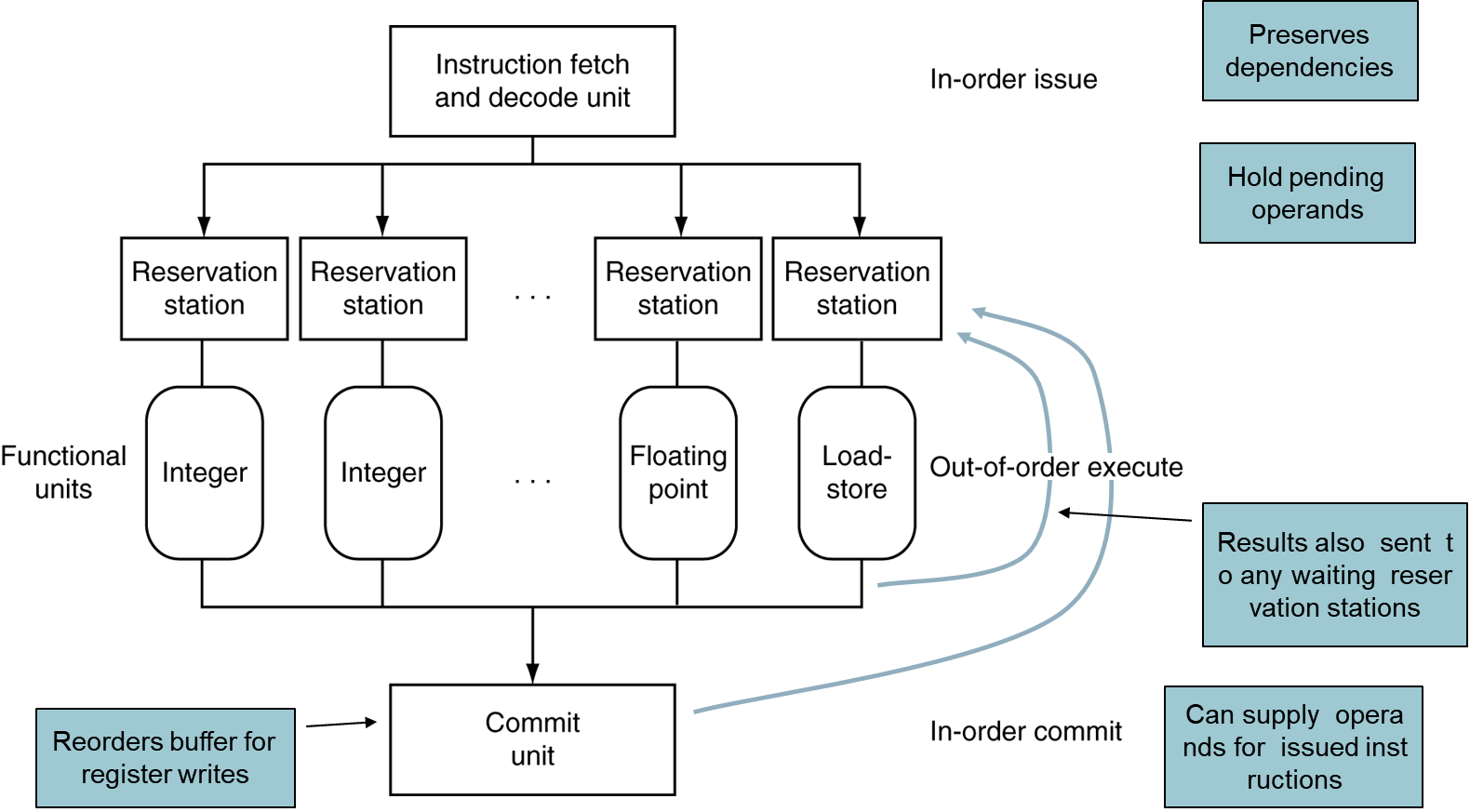
instruction을 한꺼번에 읽어와 decode한다. reservation station에서 dependency를 check한다. 만약 dependency가 있으면, 여기서 hold한다.
연산 수행뒤, commit unit 버퍼에 임시 저장된다. 레지스터 또는 메모리에 반영되기 직전이다.
만약 Reservation station에서 instruction의 피연산자를 위해 commit unit에서 값을 받을 수 있다.
commit unit에선 reorder가 수행될 것이다.
Regsiter Renaming
지금까지 했던 것들이 다 Register Renaming개념을 사용한 것이다. 원래 사용해야 했던 레지스터의 정보를 사용하지 않고 commit unit의 정보를 사용하거나, Functional unit의 결과를 사용할 수 있다. 레지스터의 값이 아니라 다른 정보를 사용한다.
피연산자를 위해, reorder buffer 또는 레지스터 파일에서 가져올 수 있다. 이를 reservation station으로 복사해온다. 그 이후 필요가 없다면 레지스터를 덮어쓸 수 있다.
(복구가 필요하다면 reservation station의 값으로 복구할 수 있다.)
만약 피연산자를 가져올 수 없다면 functional unit에서 가져올 수 있다.
레지스터에 바로 업데이트 할 필요없다.
정보는 하나만 저장되면 된다. 굳이 중복 저장해놓을 필요 없다. 하드웨어는 레지스터에 정보가 commit unit 이던 어딘가에 저장되어 있다는 것을 알아야한다.
instruction에 레지스터 끼리의 연산을 레지스터를 참조하는 것이 아닌 다른 곳에서 가져온다. operand(레지스터)의 위치를 바꿔야 하기 때문에, register renaming이라 불린다. 이는
Register Renaming
Speculation Summary
branch의 경우, branch 해야할 곳을 commit unit에 저장해두었다가 조건의 결과가 나와야 branch를 해야한다.
Load speculation의 경우 메모리에서 값을 정확하게 읽히지 않은 상태, 읽을 수 없는 상태일 때 예측한다. sw 이후에 lw가 온다면 sw 이전에 lw를 한다. 실제로는 더 많은 예측이 발생한다.
그러나 사실 lw는 최악의 경우의 200cycle 가까이 소모될 때도 존재한다. lw를 위한 더 많은 예측이 요구된다.
lw를 수행할 때의 다른 예측들을 알아보자
- 주소를 위한 레지스터 값을 추정한다.(레지스터값이 update 되기 이전에)
- 읽어올 값 자체를 예측한다.(최근에 예측한적이 있다면)
- store 이전에 load를 미리 실행한다.
- store가 되어야 할 값을 load의 값으로 바로 사용한다.
이러한 이유는 lw는 사이클이 너무 많이 필요하기 때문에 예측할 수 밖에 없다. 기다리기 너무 아깝기 때문이다.
당연히 예측이 참이기 전까지 commit하지 않는다.
Why dynamic scheduling?
왜 동적 multiple issue를 사용할까? 컴파일러 reorder는 한계가 존재한다.
이유는 다음과 같다.
- lw는 고정된 사이클을 같지 않는다. 몇번의 stall을 넣어야 할지 예측할 수 없다 !
- branch는 동적으로 결정된다. branch 앞뒤로 스케줄링을 하는데 한계가 존재한다.
- 동일한 ISA라도 하드웨어가 다르면 hazards가 다르다.(datapath가 늘어난다거나, pipeline이 다를 수 있다.)
컴파일러가 reorder을 해도 다른 디바이스에서 유효하지 않을 수 있다.
그럼 컴파일러가 모든 microarchitecture의 지식을 다 가지고 있어야한다. 그래야 유효한 reorder가 필요한데, 이럼 너무 복잡해진다. 실제로는 컴파일러는 general한 해석을 하고 나머진 동적으로 수행하는 것이 좋다. 실제 컴퓨터들은 다 동적 multiple issue를 사용한다.
Multiple Issue Summary
- multiple issue는 배수로 증가하지 않는다. dependency 때문이다.
- 어떤 프로그램은 추정 불가능한 dependency를 가질 수 있다. (pointer chasing)
- 어떤 프로그램은 병렬화는 충분히 활용할 수 없다. n-way issue를 모두 활용하기 어려운 경우가 많다.(위랑 같은 얘기)
- 메모리 때문에 n-way가 충분히 활용되지 않을 수 있다.(다음장에 배운다)
- 이러한 어려움들을 어느정도 극복할 수 있는 추정이 존재한다.
Real Stuff
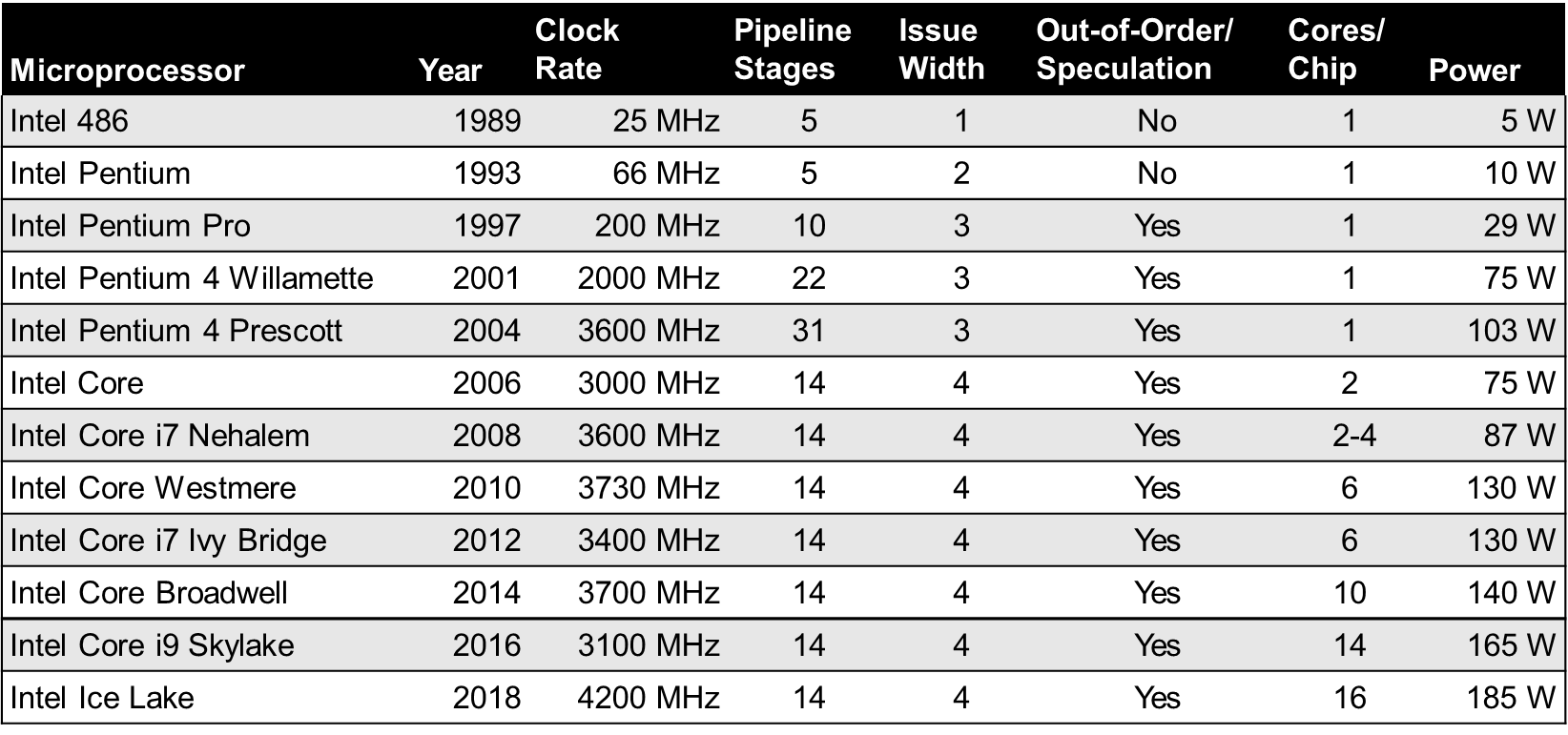
pipeline stage가 늘어나면 당연히 clock도 빨라진다. 그런데 컴퓨터가 엄청 복잡해진다. 추정과 복구 과정이 많이 필요하다. 그럼 power가 많이 필요하다.
결국 코어 수를 늘리는 방향으로 컴퓨터는 진화하였다.
issue 수도, 너무 늘리면 효용성이 떨어진다. dependency가 많기 때문이다.
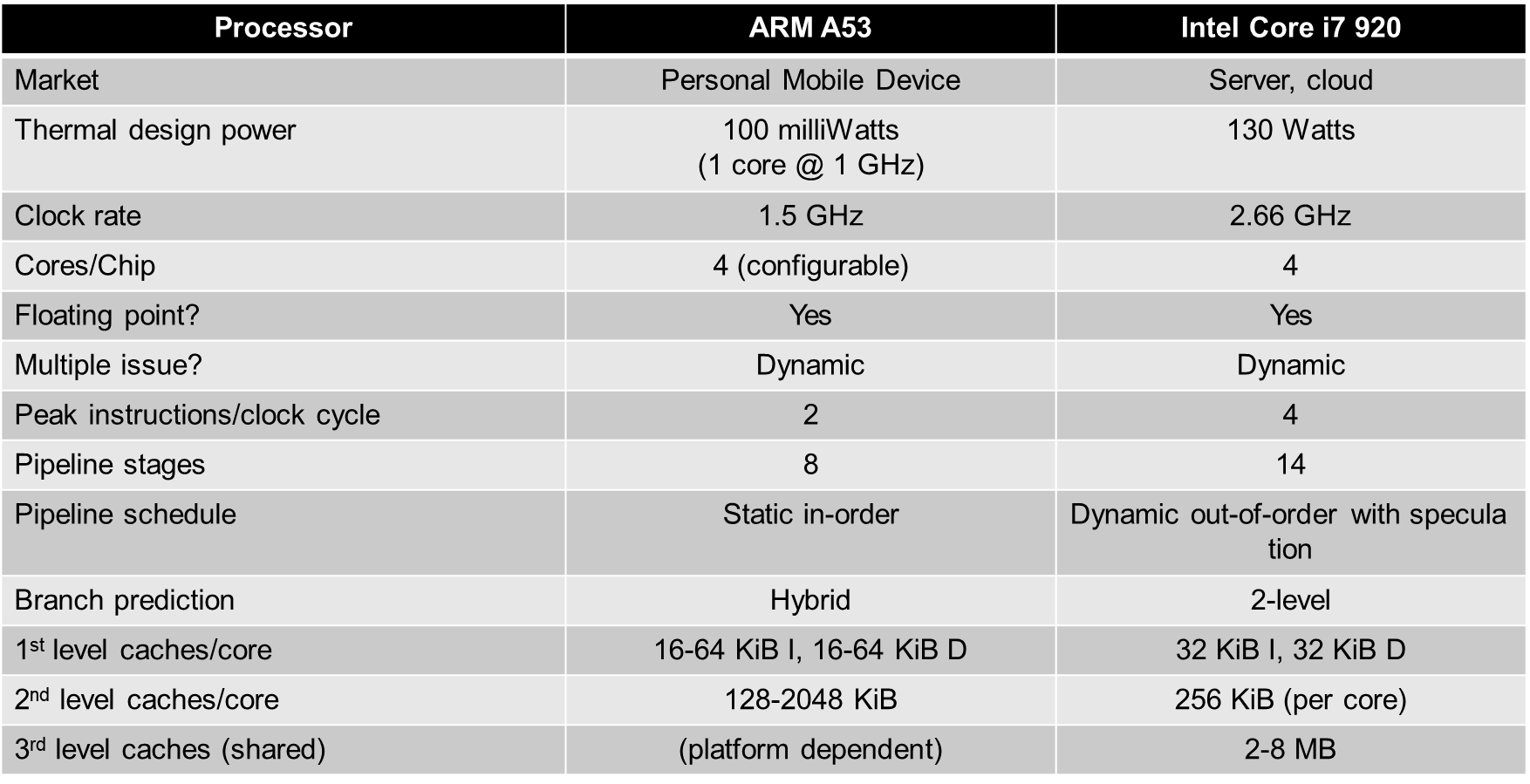
코어 수가 같으니 clock rate만으로 성능차이를 생각했겠지만, ILP 개념을 배웠으니 Intel CPU가 더 좋다는 것을 알 수 있다.
pipeline schedule만 본다면, Intel은 dynamic out-of-order issue와 추정을 사용한다.
하지만 ARM은 static하게만 가능하다. 메모리 관련 추정을 안 한다는 것이다.
ARM Cortex-A53
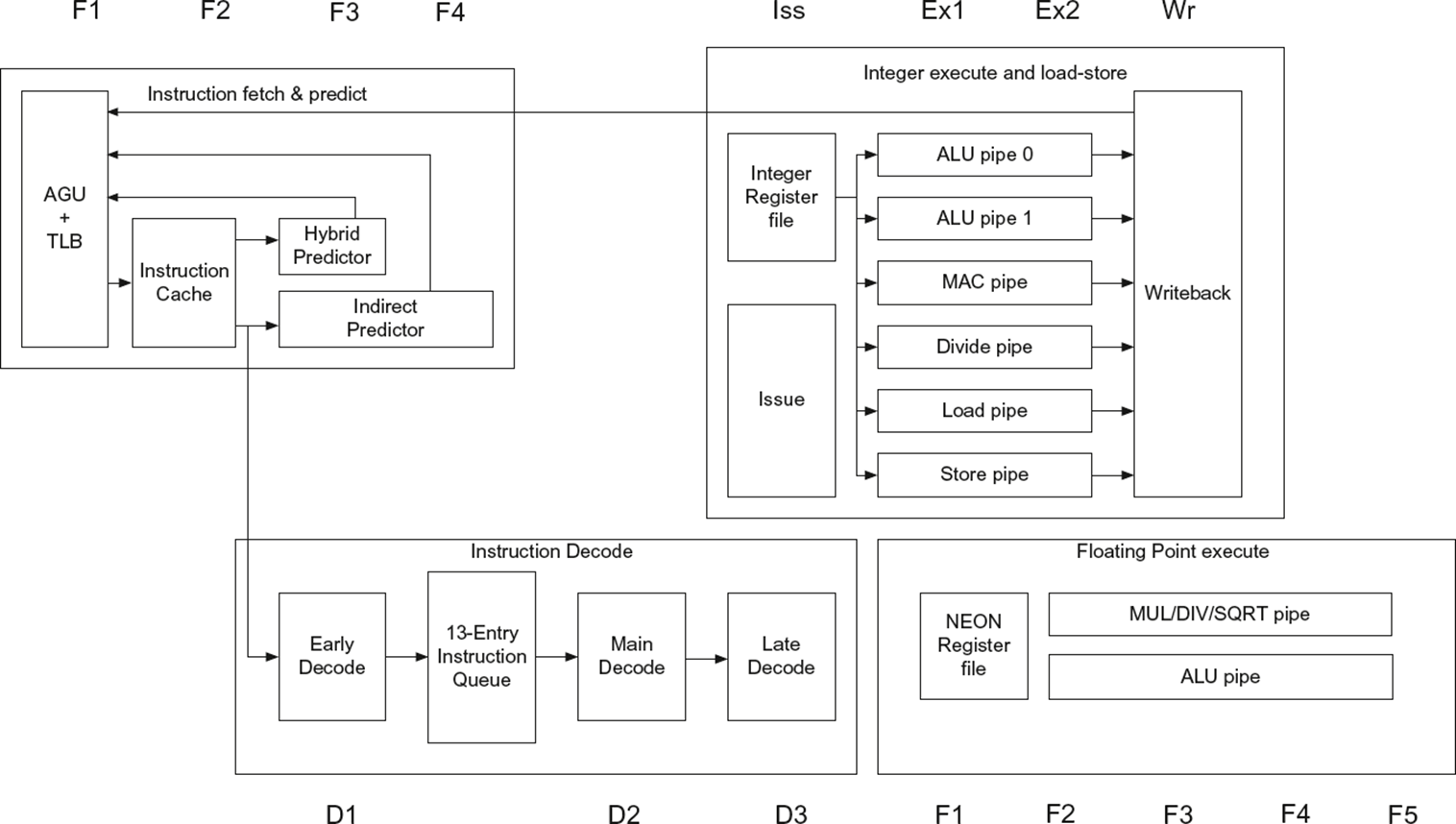
실제로 6개의 pipeline이 있는게 아니라 2개만 있다. load와 store도 하나로 묶인다.
decoding이 3개의 단계로 나누어져 있다. (MIPS는 교육용이라 엄청 간단하다)
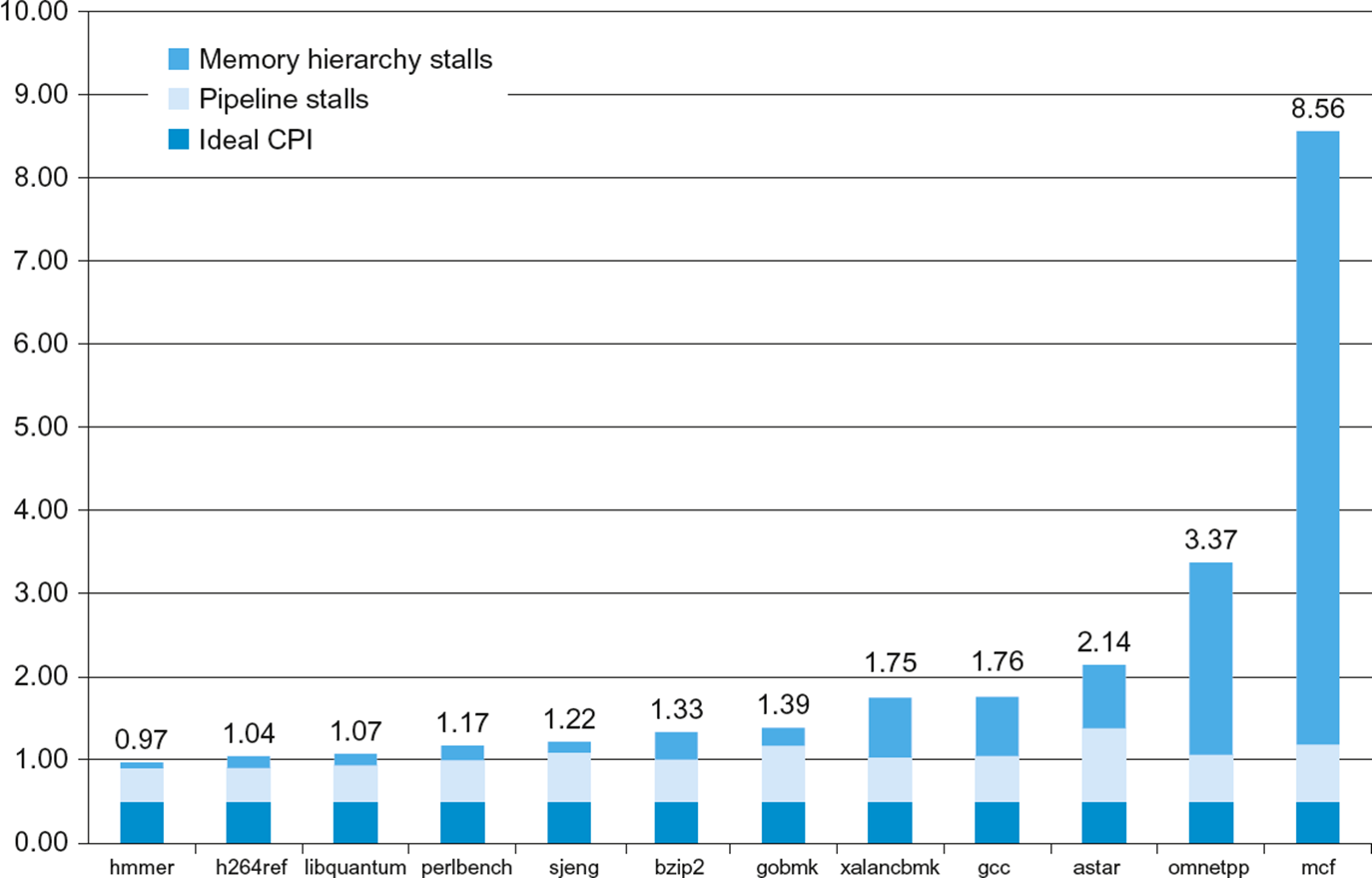
dependency나 brach로 인한 stall이 이상적인 CPI를 거의 두 배로 늘린다.
몇몇 program들은 메모리 때문에 성능이 많이 저하된다.
Intel Core i7
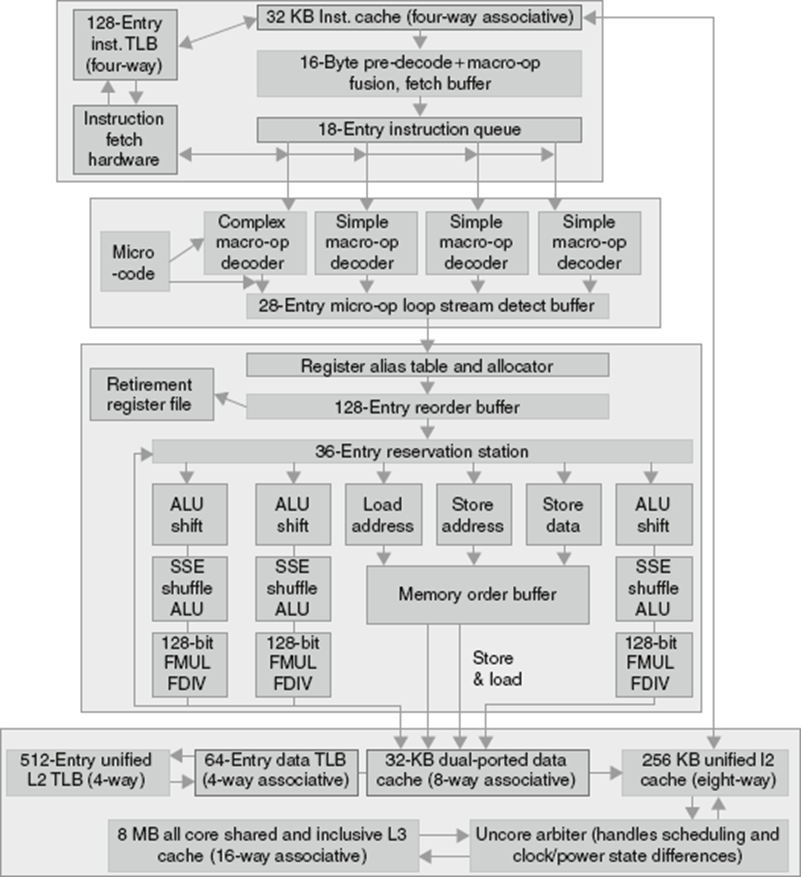
reservation station도 재한다.
Instruction을 많이 읽어와서 queue에 저장한다.
intel은 instruction이 굉장히 복잡하기 때문에(크기 차이도 크다.) 이러한 이유로 micro operation을 만들어놓았다. 이전 세대와의 호환성 때문에, instruction을 없애지 않고, instruction을 조각으로 나눠놓고 pipeline을 수행한다. (microoperation)
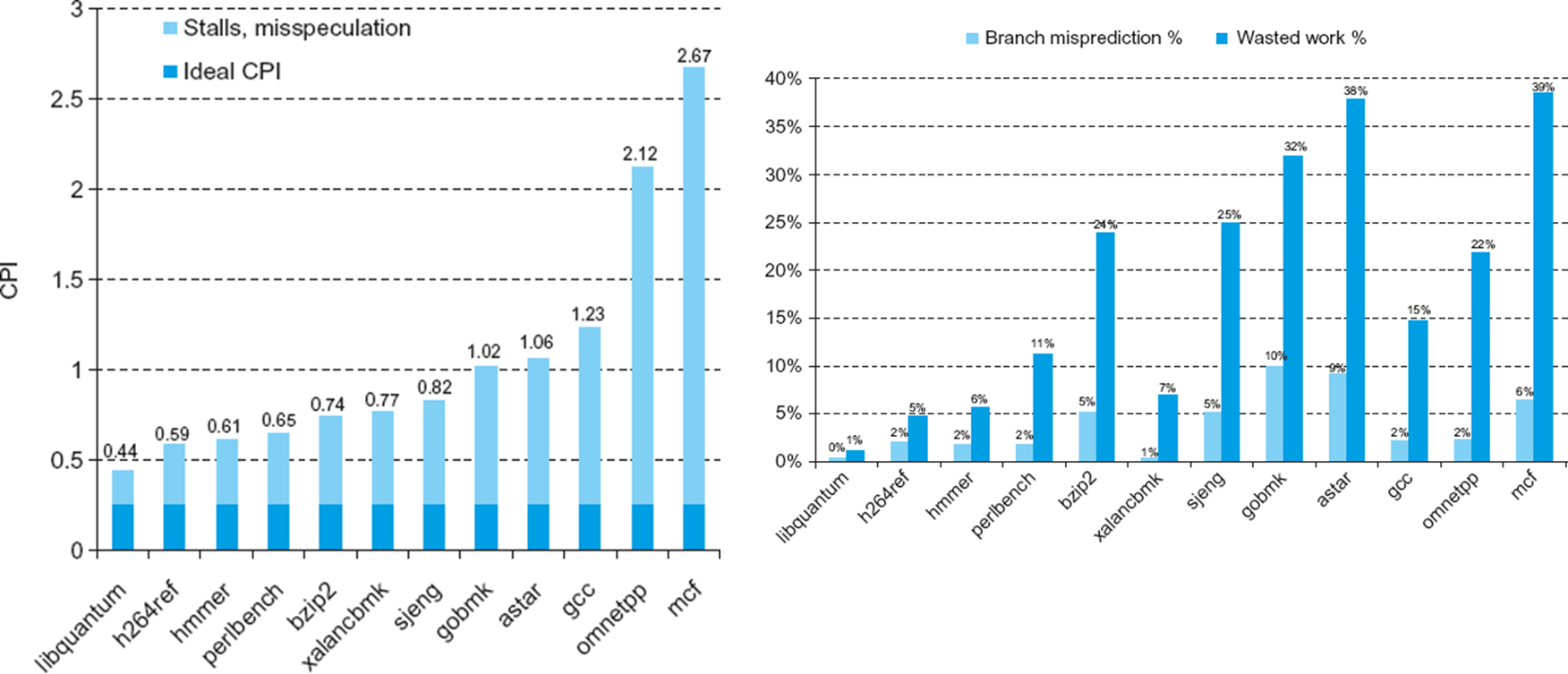
얘네는 너무 복잡해서(추정도 복잡하다.) 정확하게 어디서 stall이 발생했는지 추측하기 힘들다.
오른쪽에 잘못 추정했을 때, 얼마나 많은 일이 날라가는지 알 수 있다.
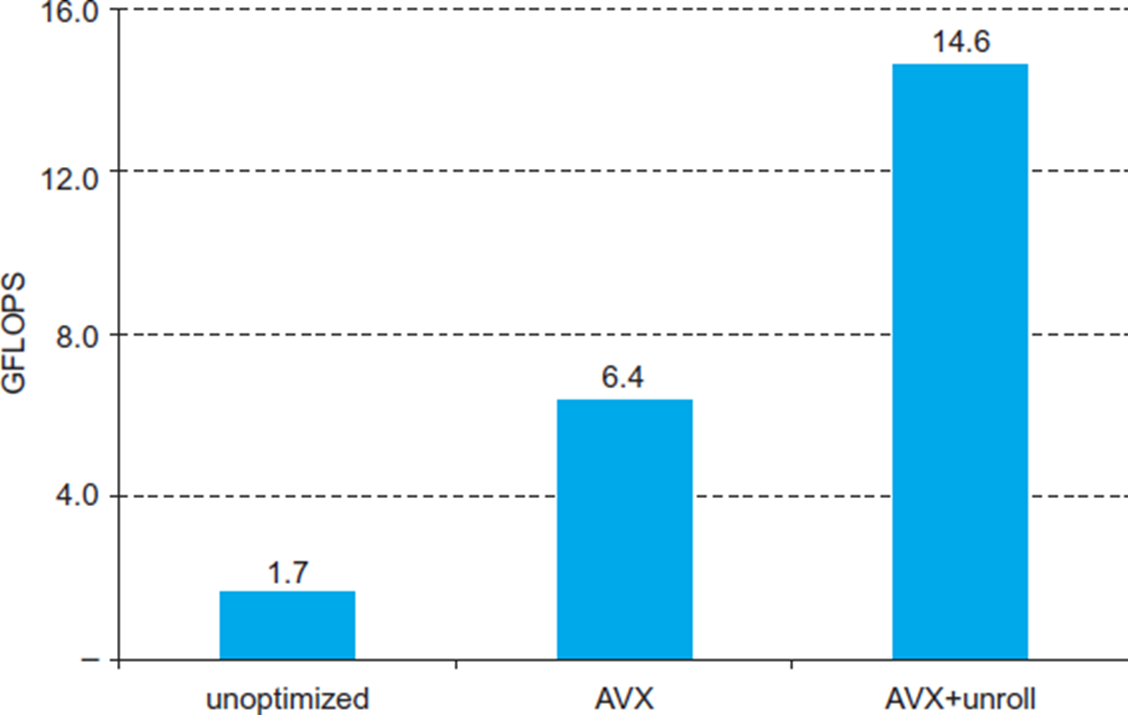
AVX + loop unrolling을 적용했을 때 거의 8배정도 성능이 향상된다.
Fallacies
MIPS를 보고 배운 pipeline은 쉬워 보인다. 사실 엄청 복잡하다.
Pipeline은 회로도가 복잡해질 수록 같이 발전한다. stage가 더 깊어진다.
사실 pipeline을 잘 만들기 위해서 ISA가 가장 중요하다.
인텔은 너무 복잡하기 때문에 micro operation으로 분해하는 것이다.
address mode도 많은 영향을 끼친다. x86같은 경우는 체크해야하는 것이 너무 많기 때문에 dependency 추정이 너무 복잡해진다.
