MIPS ISA에서 pipeline으로 인해 발생하는 문제점을 알아보고 이를 어떻게 해결하는지 알아보자.
Structure hazards
Structure hazards: instruction fetch, lw/sw 수행은 모두 메모리에 접근해야한다.
lw/sw을 수행하며 메모리를 이미 사용하고 있기 때문에, instruction fetch를 위한 메모리 접근이 불가능해진다. 이를 위해 instruction을 따로 저장할 cache를 사용할 것이다.(다시)
Data hazards
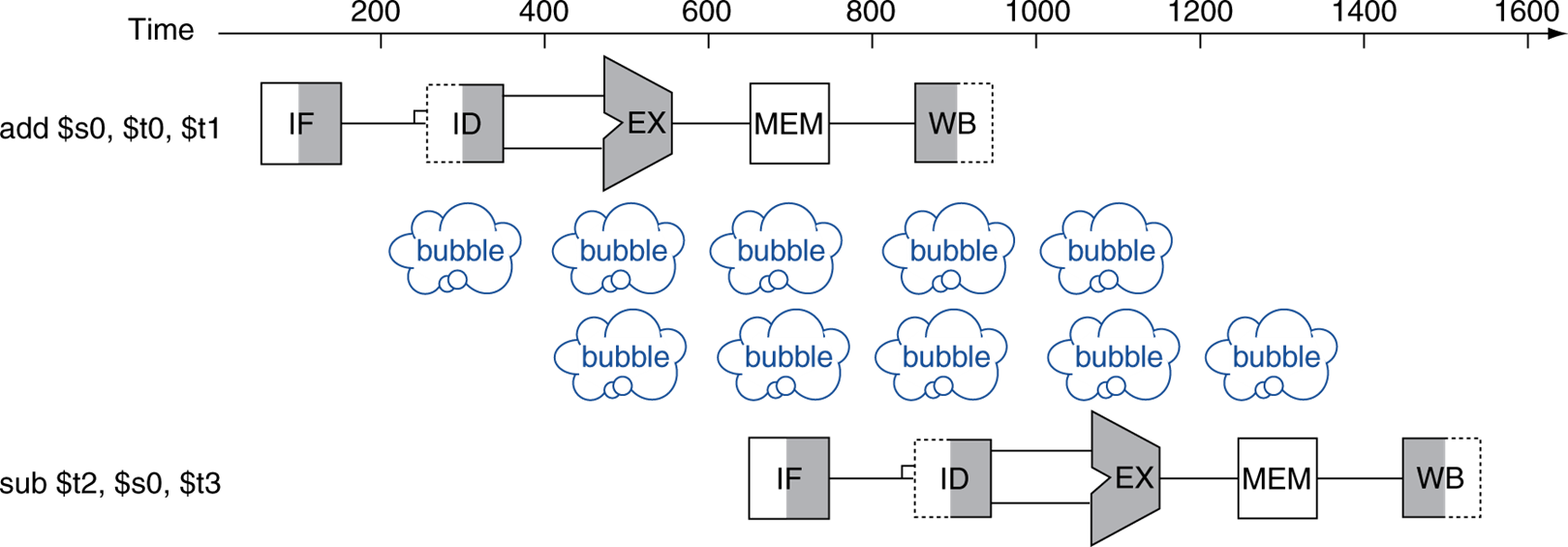
Data hazards: 만약 두 개의 instruction이 존재하고, R-format이라 하자. 첫 번째 instruction의 dst regsiter가 다음 instruction의 rt, rs register라면 레지스터에 저장될 때까지 대기(stall)해야한다.
이를 bubble이 생긴다. 또는 cycle을 대기한다 칭한다.
또는 lw 연산 수행 이후, R-format을 사용한다면, 이 때도 data hazard가 발생한다.

Solution
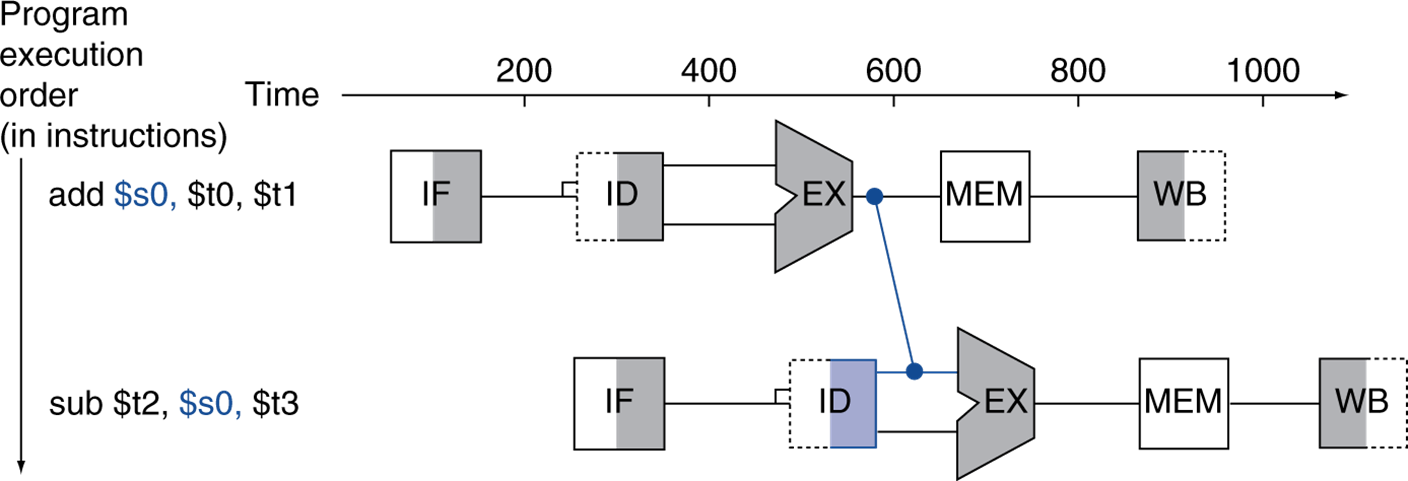
전자의 hazard에선 ALU의 결과값을 바로 다음 수행의 input으로 주면 해결된다. (datapath를 하나 더 늘린다.)
이를 Forwarding 또는 Bypassing이라 칭한다.
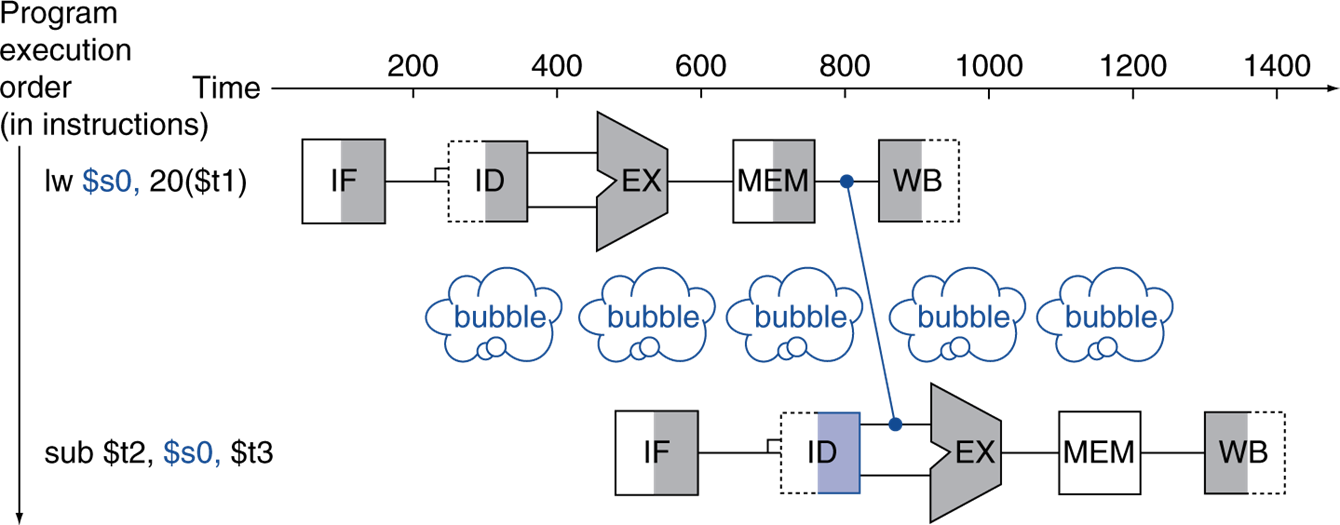
lw의 경우 MEM에 datapath를 하나 더 연결하여 해결할 수 있다. 하지만 이는 어쩔 수 없이 한 cycle stall이 발생한다.
Compiler
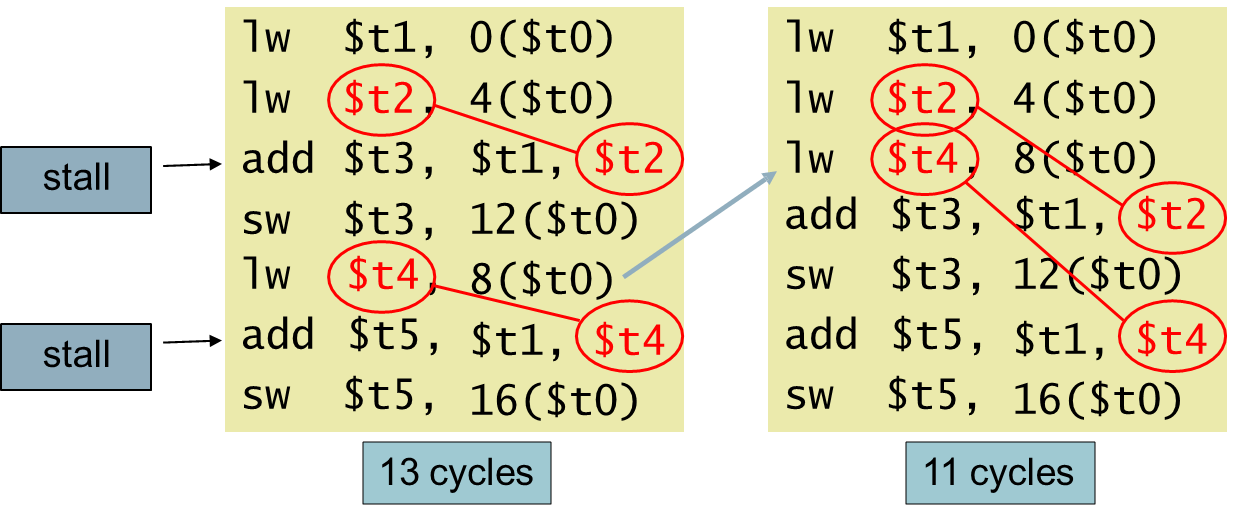
위와 같이 code reordering을 통해 해결할 수도 있다. (대부분 이 방법으로 해결 가능하다.)
Control hazards
branch를 할 때, 두 값을 비교하고 PC값을 변경해야줘야 한다. 그럼 이 과정을 수행할 때까지 PC값을 선택하지 못할 것이다. 만약 ALU까지 대기한다면 2 cycle stall이 발생한다.
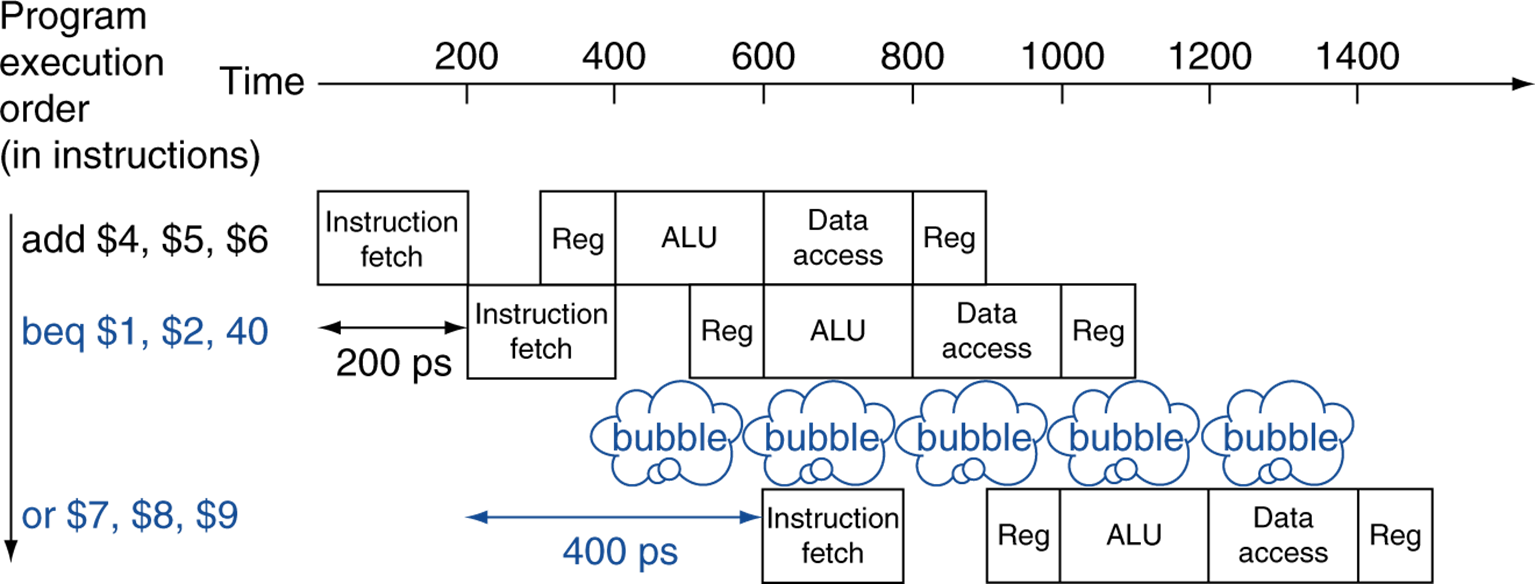
그럼 Reg 단계에 하드웨어를 추가하여, 레지스터값과 PC값을 미리 계산한다. 이래도 어쩔 수없이 1 cycle stall이 발생한다.
Branch Prediction
만약 pipeline이 더 길다면 branch를 하기위한 여부를 빠르게 알 수 없을 것이다. x86같이 decoding stage가 긴 ISA들은 branch 여부를 위한 연산을 미리 할 수 가없다.
이럴 경우 bracnh 여부를 예측하고 bracnh 뒤에 연산을 수행한다. 만약 branch를 해야한다면 이전의 연산을 전부 무시하고 Jump한다.
이를 Predict Not Taken라 칭한다.
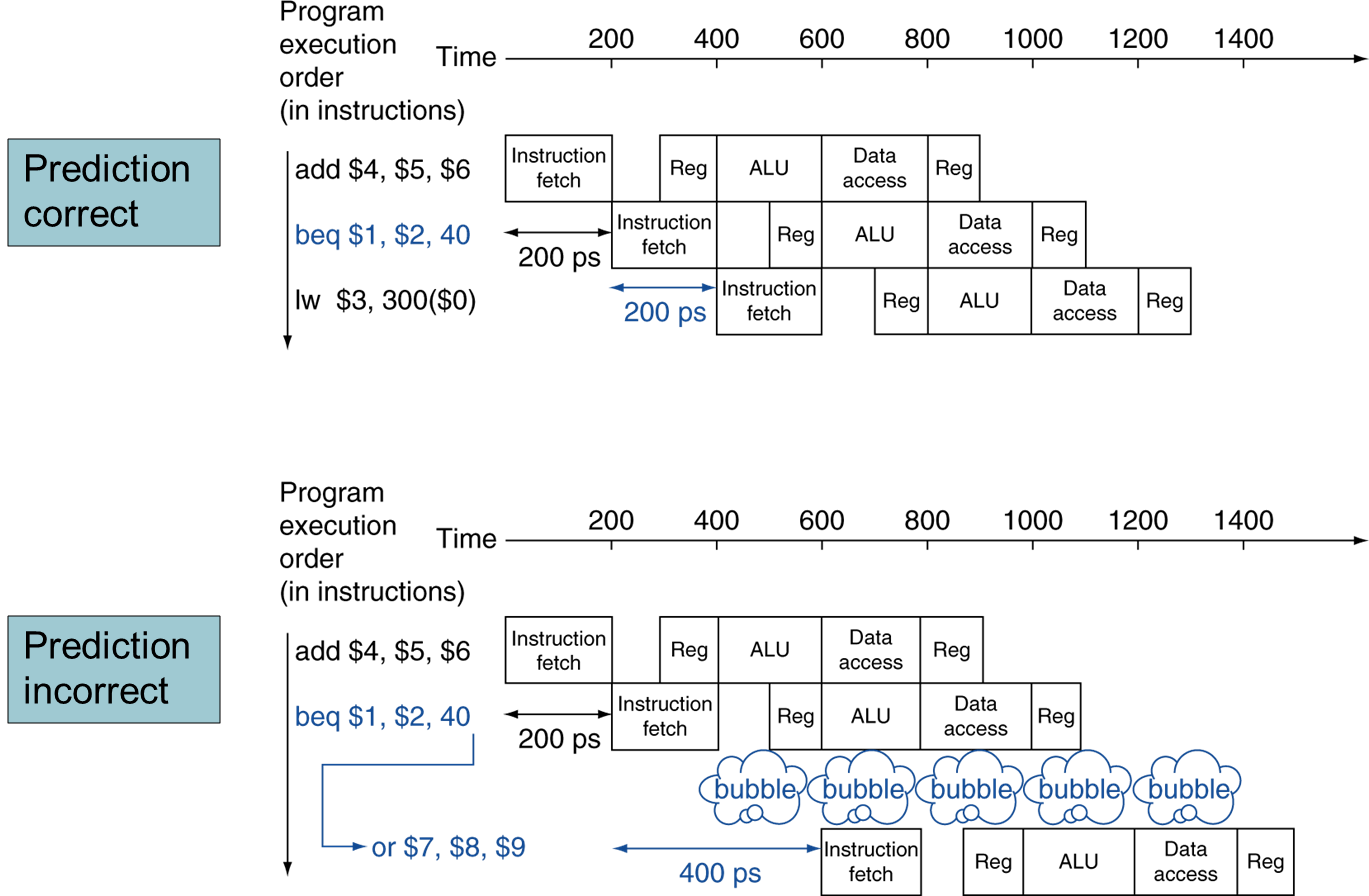
MIPS의 경우 위와 같이 바로 PC+4를 수행하고(bracnh가 발생하지 않을 것이라고 예상한다.), instruction을 수행한다. 만약 branch를 해야한다면 이전의 연산을 무시하고 bracnh한다.
More-Realistic Branch Prediction
(다시)
이전에 본 "무조건 bracnh 안 한다."는 Static branch prediction이라 칭한다.
이는 정적으로 bracnh 예측 방법이 미리 정해져 있다는 것이다.
static branch prediction 중 또 다른 하나는 forward branch는 정적으로 하지 않고 backward branch는 정적으로 하는 방법도 존재한다.
이는 for문과 if문을 생각해보면 된다. for문은 대개 branch를 하고, if문은 대개 일어나지 않는다.
또는 dynamic branch prediction도 존재한다. 이는 추가적인 하드웨어를 두어 branch의 history를 저장한다. 이를 기반으로 예측하며, Inst-decode 하자마자 바로 판단한다.
틀렸을 경우 1 cycle stall하는 것은 동일하다.
MIPS Pipelined Datapath
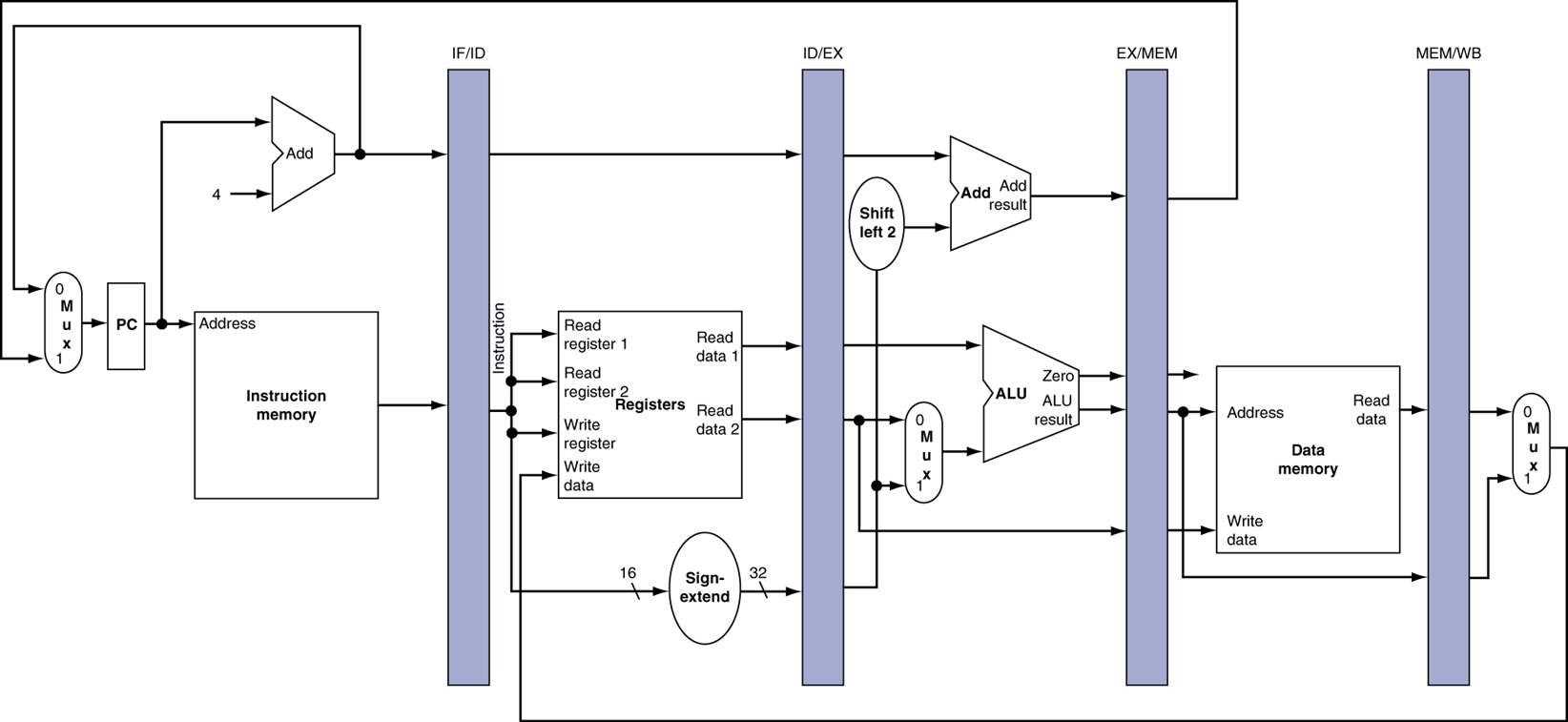
이전에 보던 datapath와 많이 달라졌다. 이는 pipeline을 위한 register들이 각각 page마다 추가되었기 때문이다. 정해져있는 page 시간마다 clock을 주어, 다음 page로 옮겨진다.
이는 레지스터의 성질을 이용한 것이다.
레지스터는 각각 IF/ID, ID/EX, EX/MEM, MEM/WB가 존재한다.
Single-Cycle Pipelined Diagram

한 사이클에 중첩된 instruction들을 diagram으로 표현한 것이다.
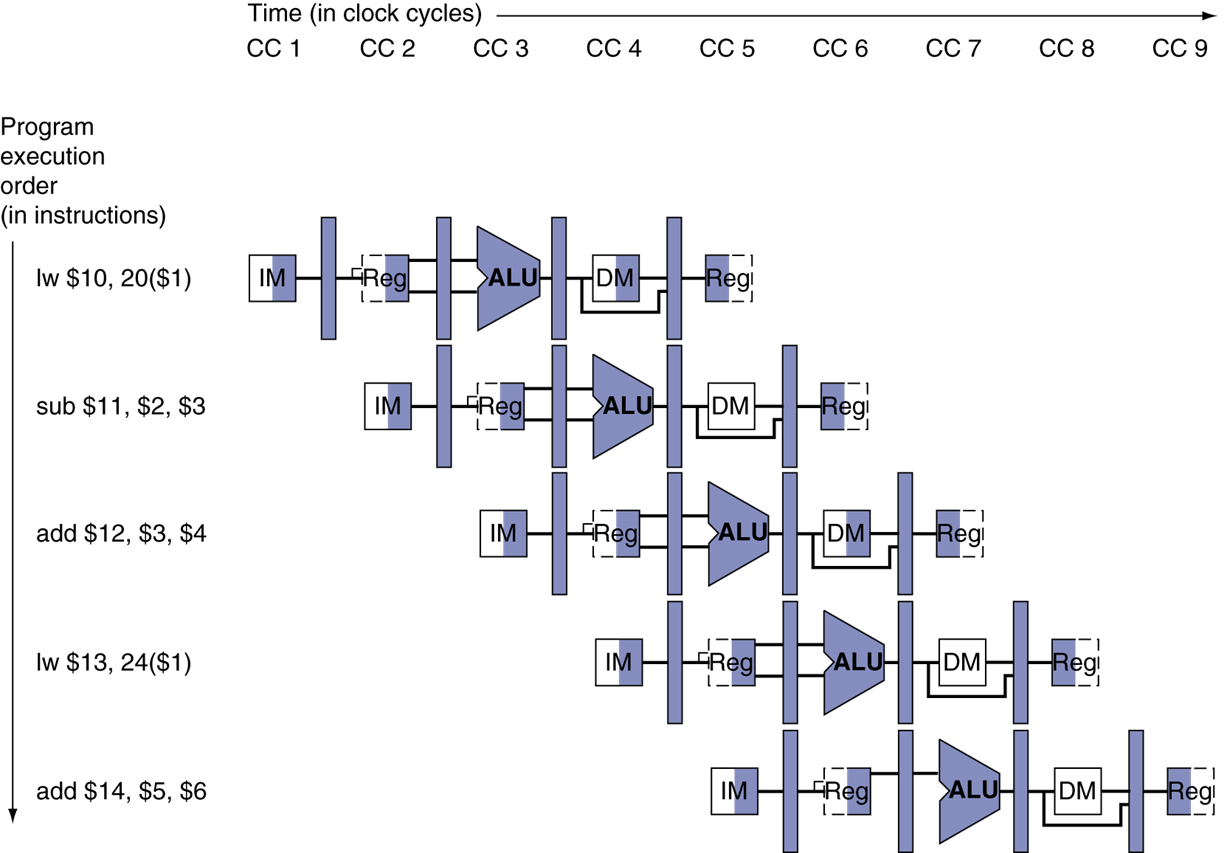
Multi-Cycle pipeline diagram 모습이다. 앞쪽은 읽기, 뒷쪽은 쓰기이다.
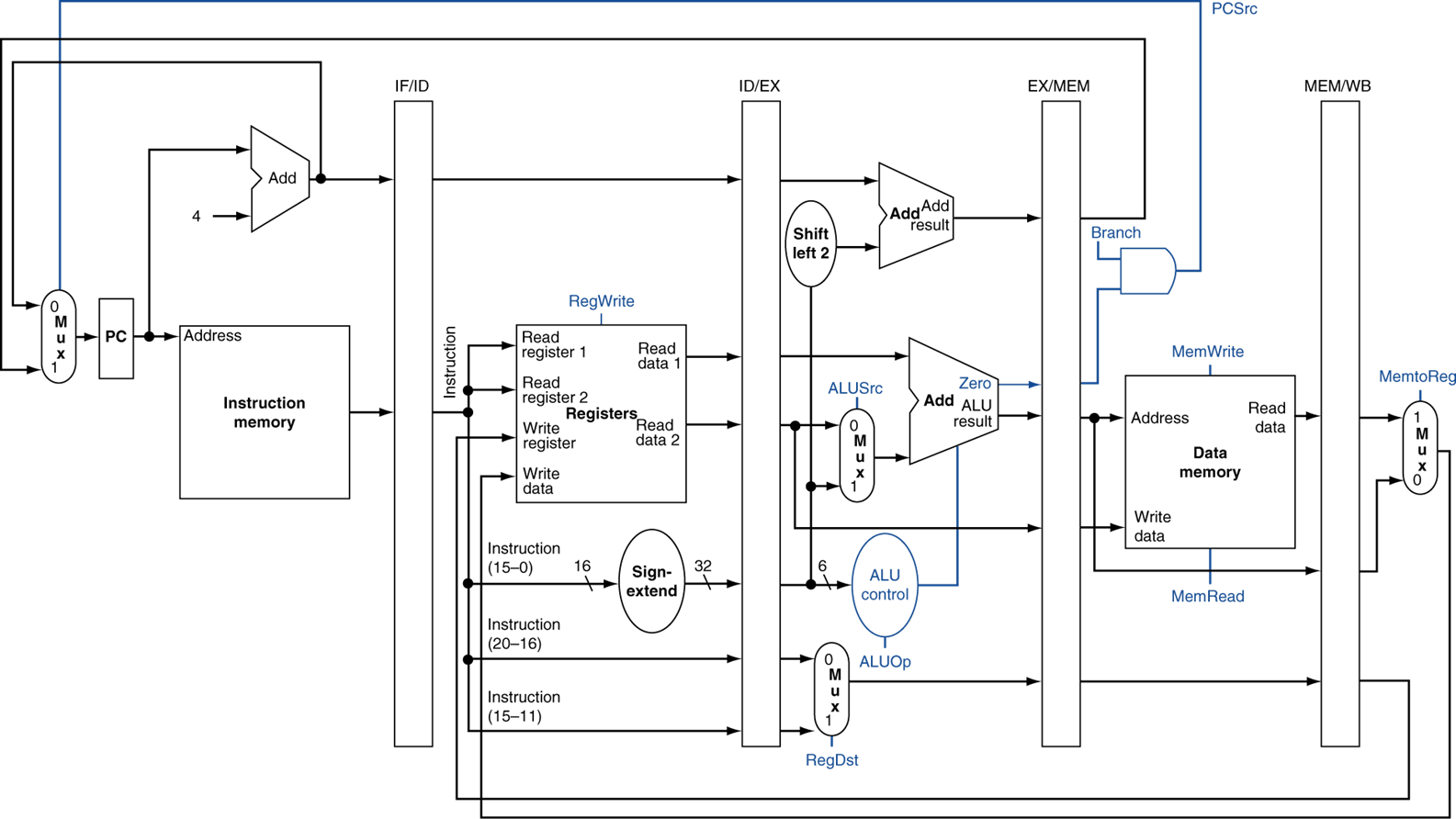
pipeline datapaht에 control이 추가된 부분이다.
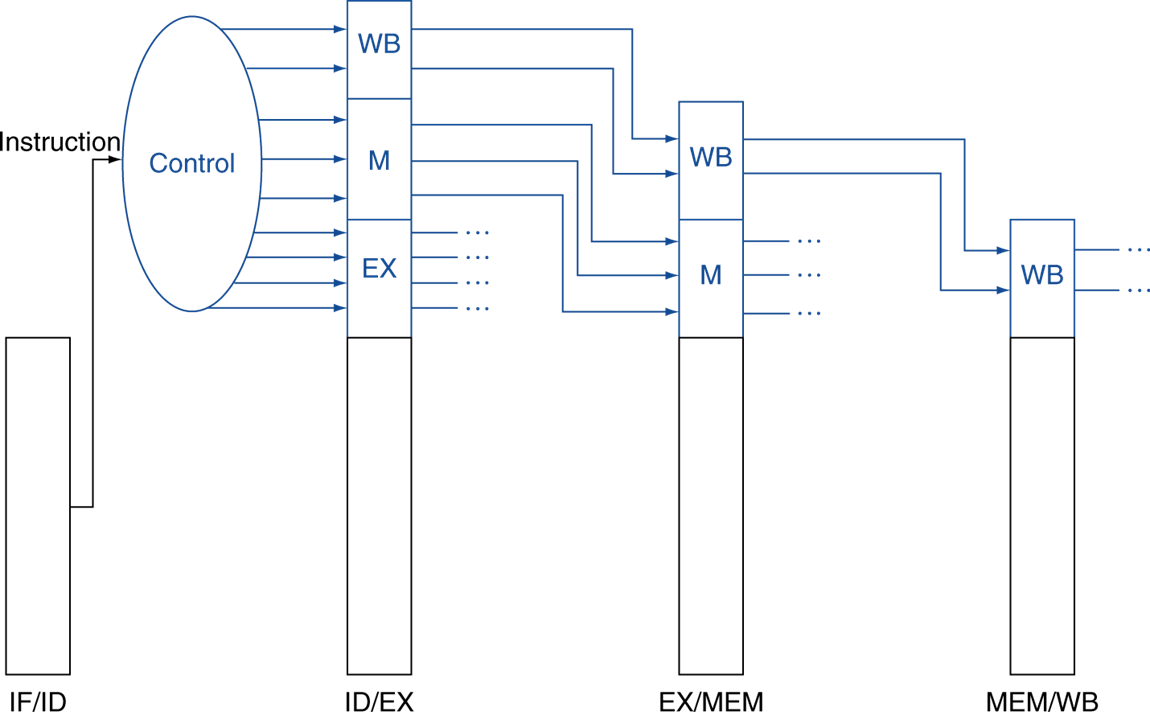
control signal을 보내주는 하드웨어이며 instruction으로부터 해석되어 전달된다.
control도 당연히 레지스터를 통해 넘겨줘야 한다.
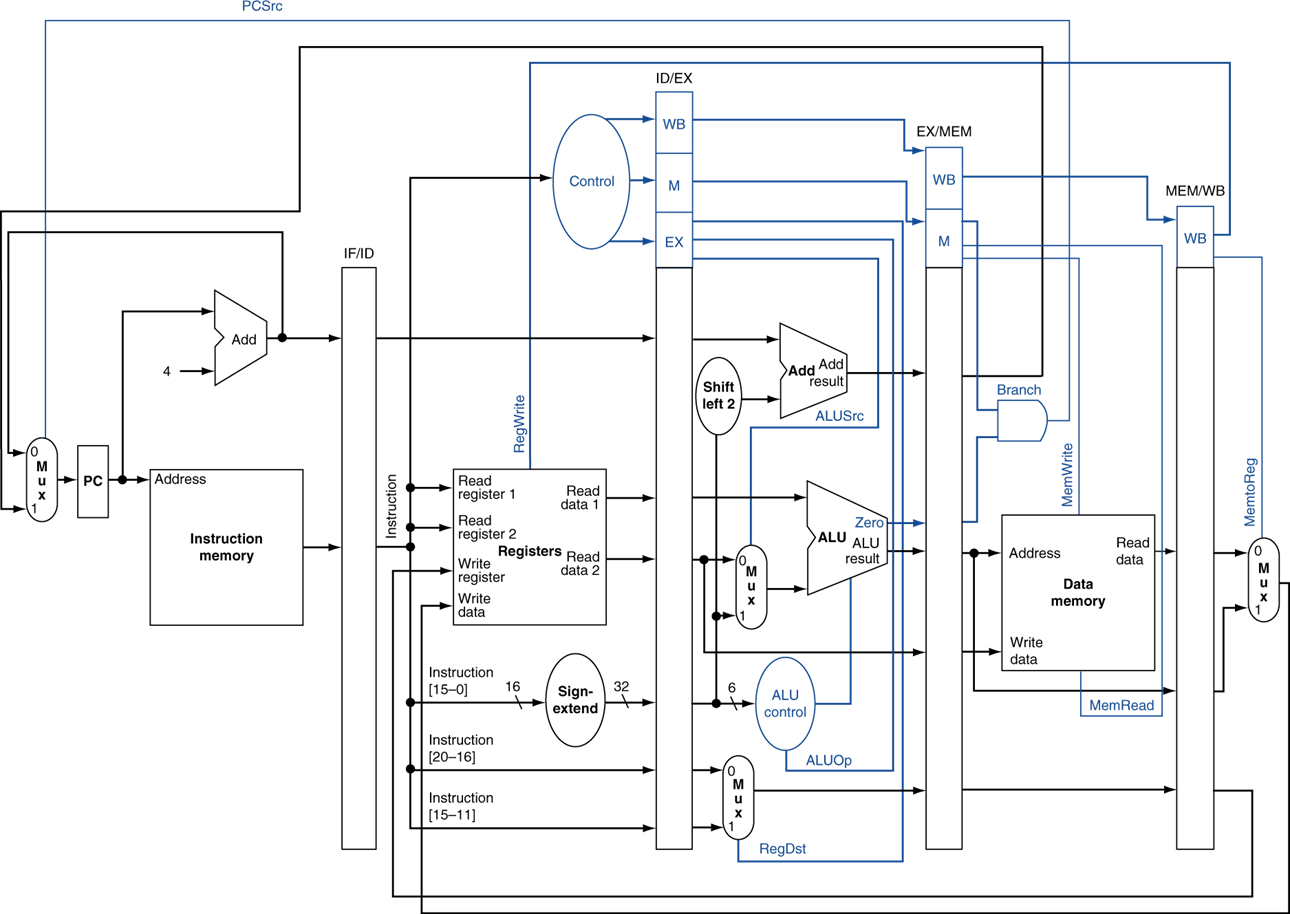
전체 모습이다.
Data hazards in a row
sub $2, $1,$3
and $12,$2,$5
or $13,$6,$2
add $14,$2,$2
sw $15,100($2)
위와 같이 $2 레지스터를 반복해서 사용하는 경우는 어떻게 해결해야 할까?
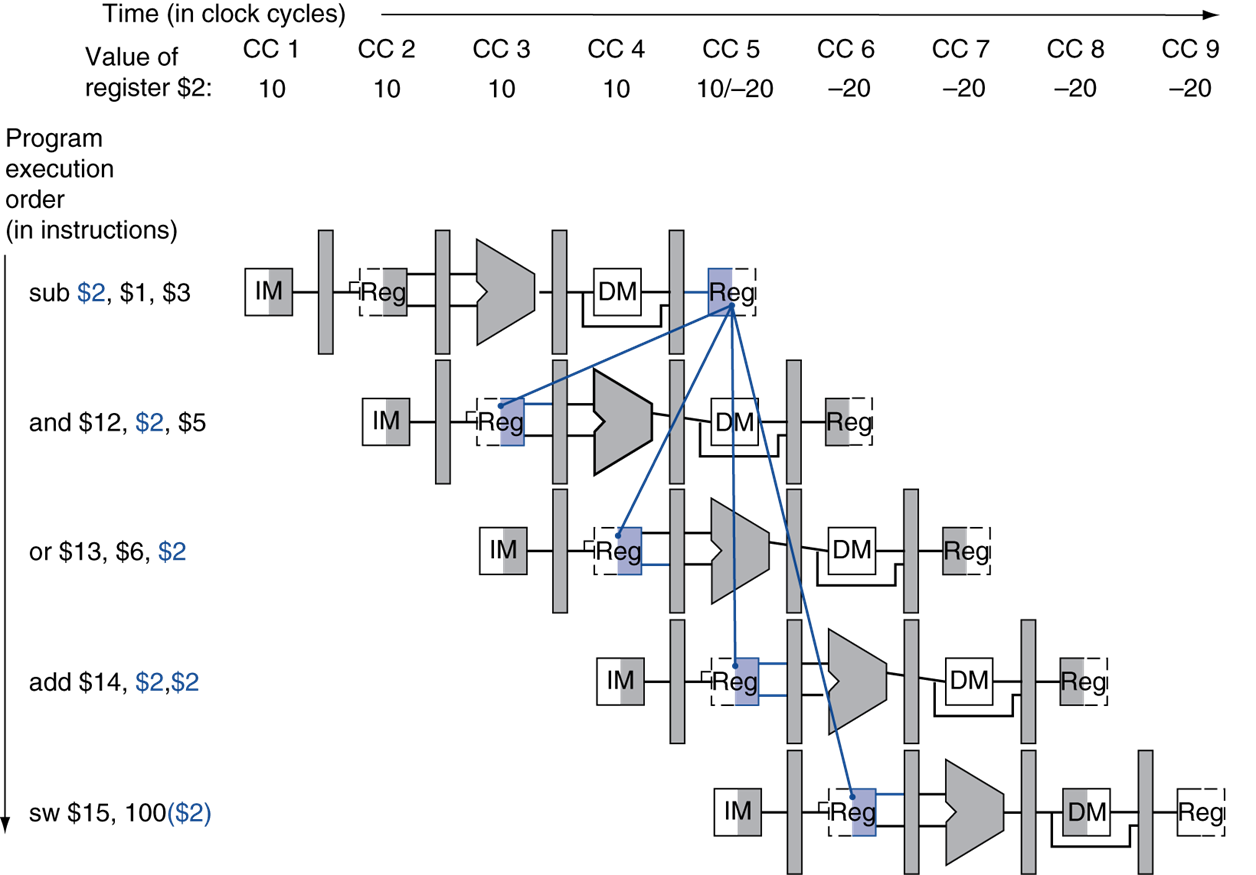
sub의 ALU 결과를 and를 위해 ALU의 input으로 전달해주면 된다. 그럼 이 때, 이전에 본 stage마다의 register를 사용하여 datapath를 연결하고 전달해준다.
or의 경우, datapath를 두 개의 레지스터에 연결하고 두 번 넘겨주고 ALU의 input으로 전달해준다.
그 이후는 forwarding이 필요없다.
Detecting Forwarding
forwarding은 그럼 두 가지의 경우가 존재한다. 그럼 ALU의 input은 총 세 가지의 경우의 수가 생기며 이를 control signal로 제어해줘야 한다. 이를 알기 위한 수식은 다음과 같다
EX/MEM과 비교
- EX/MEM.RegisterRd = ID/EX.RegisterRs
- EX/MEM.RegisterRd = ID/EX.RegisterRt
MEM/WB와 비교
- MEM/WB.RegisterRd = ID/EX.RegisterRs
- MEM/WB.RegisterRd = ID/EX.RegisterRt
위의 RegisterRd는 레지스터 넘버를 의미한다.
추가로, RegWrite signal이 on인지와 $zero 레지스터가 아닌지 확인해야한다.
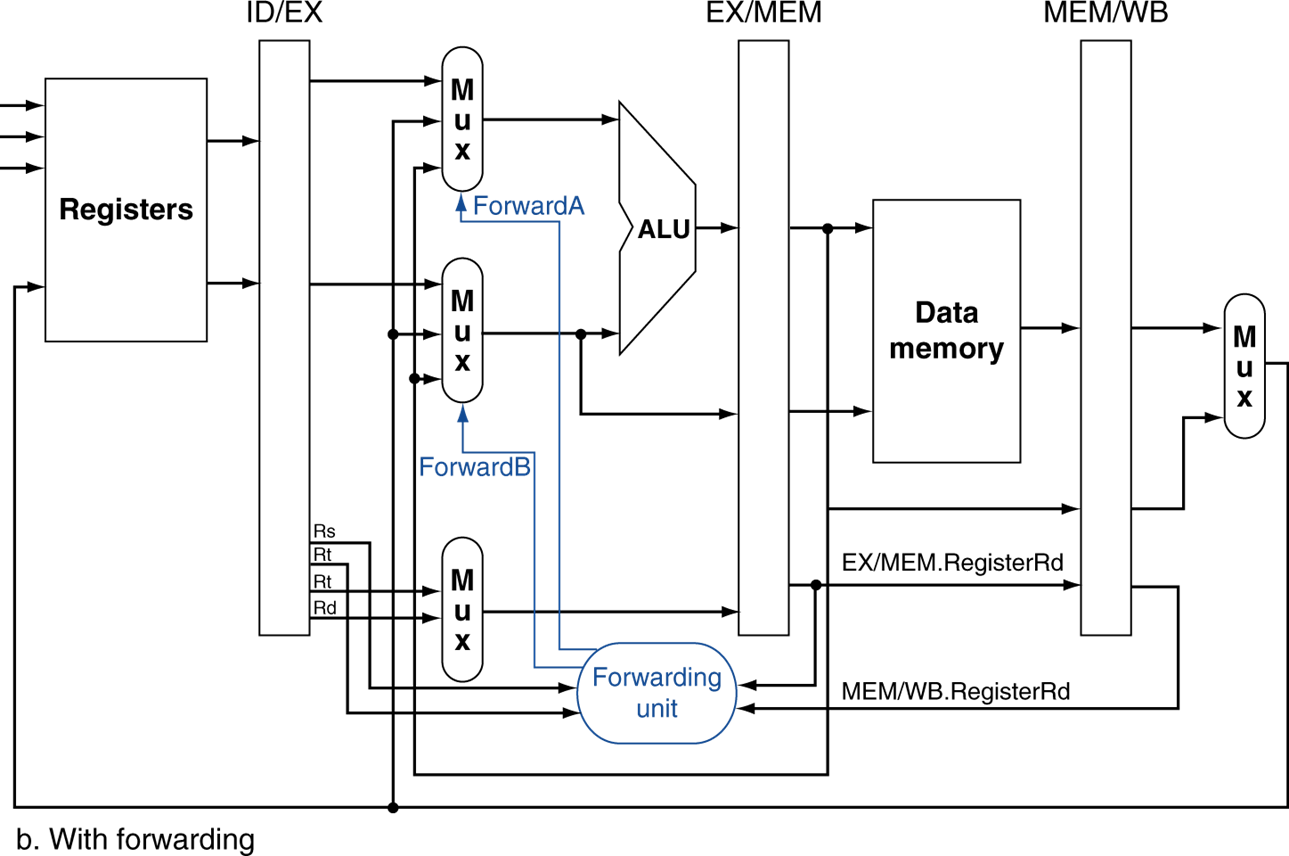
위의 그림을 보면 1단게, 2단게 forwarding을 위한 추가된 datapath들이 보인다.
게다가 비교를 위한 레지스터 넘버도 필요한 stage를 위해 레지스터로 넘겨주고 있다.
Double Data Hazards
add $1 $1 $2
add $1 $1 $3
add $1 $1 $4
$1에 대한 data hazard가 두 번 발생하면 어떻게 해야할까?
1단계 포워딩인지, 2단계 포워딩인지 확인을 해야한다.(다시)
- if (MEM/WB.RegWrite and (MEM/WB.RegisterRd ≠ 0)
and not (EX/MEM.RegWrite and (EX/MEM.RegisterRd ≠ 0)
and (EX/MEM.RegisterRd = ID/EX.RegisterRs))
and (MEM/WB.RegisterRd = ID/EX.RegisterRs)) ForwardA = 01- if (MEM/WB.RegWrite and (MEM/WB.RegisterRd ≠ 0)
and not (EX/MEM.RegWrite and (EX/MEM.RegisterRd ≠ 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRt))
and (MEM/WB.RegisterRd = ID/EX.RegisterRt))
ForwardB = 01
2단계 포워딩도 만족할 수 있으므로 2단계 포워딩에 대한 조건을 위와 같이 변경해야한다.
(!1단계 포워딩 and RegWrtie and Rd !=0 and 2단계 포워딩)
그럼 double data hazard 상황에, 1단계 포워딩을 수행할 수 있을 것이다.
first forwarding
- if (EX/MEM.RegWrite and (EX/MEM.RegisterRd = 0)
and (EX/MEM.RegisterRd = ID/EX.RegisterRs))
ForwardA = 01- if (EX/MEM.RegWrite and (EX/MEM.RegisterRd = 0)
and (EX/MEM.RegisterRd = ID/EX.RegisterRt))
ForwardB = 01
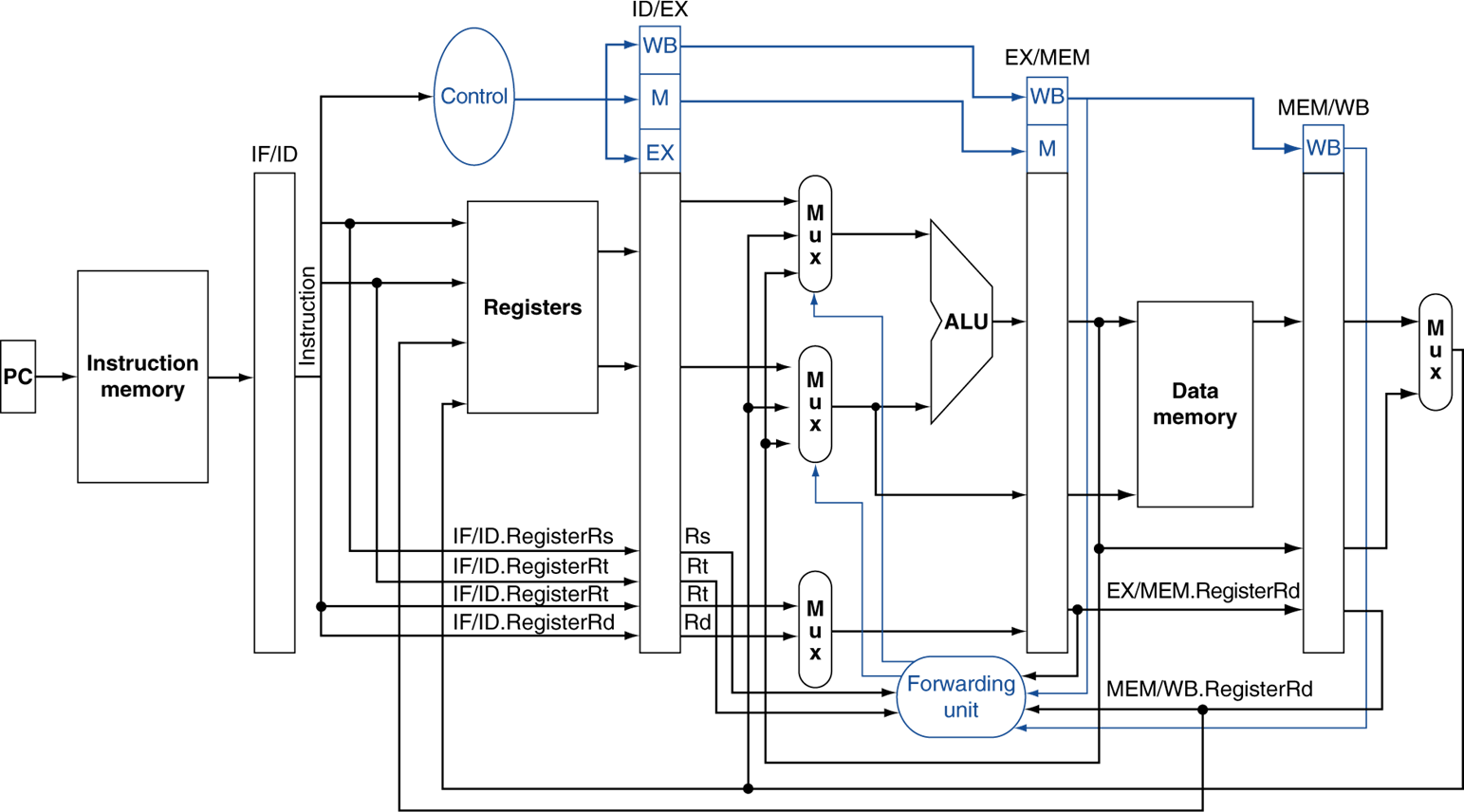
최종 datapath이다.
Load word instruction
Load word와 같은 경우는 두 번째 forwarding을 사용하면 해결할 수 있다.
한 cycle은 이전에 보았듯이 무조건 쉬어야 한다.
ID/EX.MemRead and
((ID/EX.RegisterRt = IF/ID.RegisterRs) or
(ID/EX.RegisterRt = IF/ID.RegisterRt))
ID/EX를 읽는 이유는 lw 연산일 경우 MemRead가 true인지 확인하기 위해서이다.
여기에 추가로 ID/EX의 RegisterRt와 이전 instruction의 IF/ID의 레지스터 정보가 같을 경우에, 한 cycle bubble을 준다.
이 때 IF/ID 레지스트의 정보(lw 이후 instruction의 정보)를 그대로 두고, PC를 업데이트 하지 않는다.(ID/EX 레지스터에 0을 준다.) 그리고 이후의 모든 control signal을 0으로 set한다.
이를 nop(no operation)이라 칭한다.
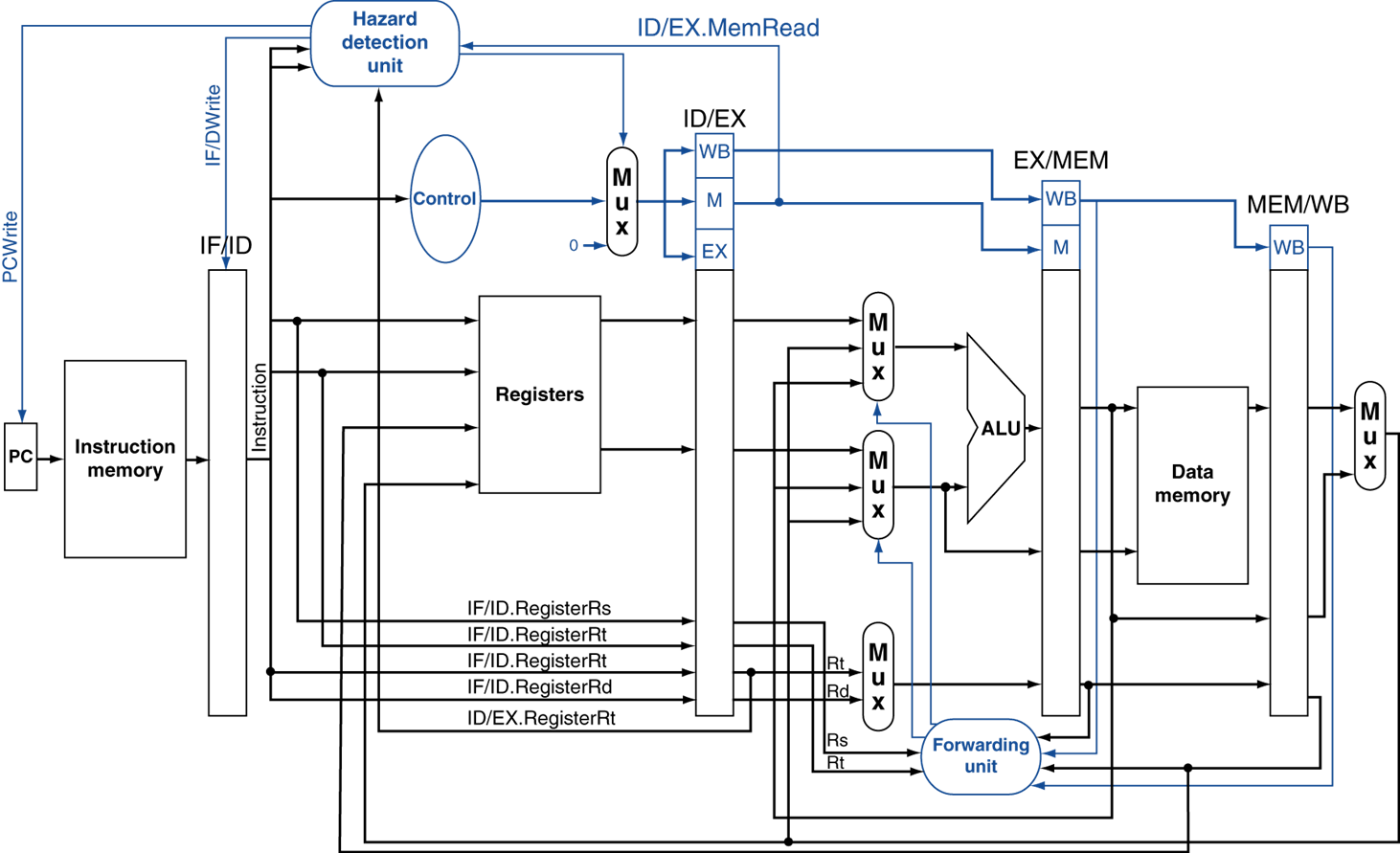
위의 control signal 부분이 추가된 datapath이다.
Branch Hazard
이전에 본 bracnh hazard를 막기 위해 register file 부분에서의 비교하는 하드웨어와 adder가 필요하다 했다. 그래도 하나의 stall이 필요하다 했다.
Data hazard for Branches

forwarding 가능하다.
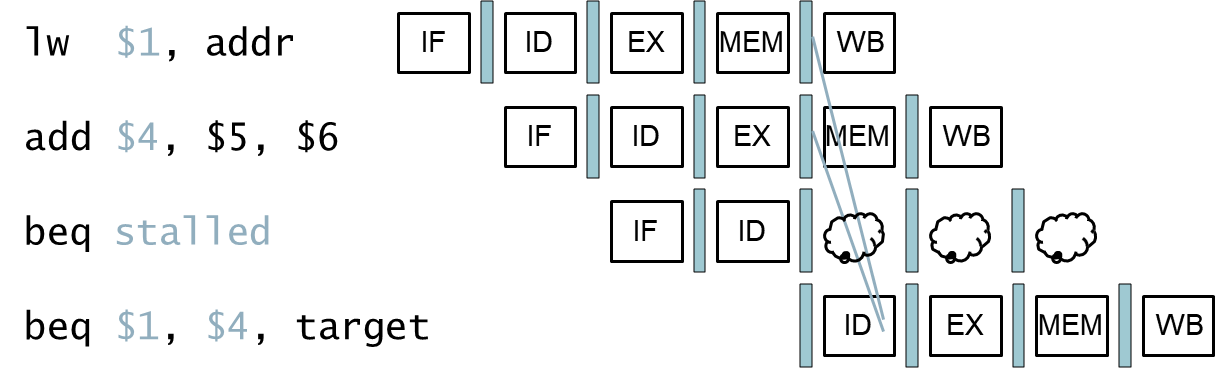
얘는 불가능하다. 비교하는 놈이 바로 위에 있으면 안 된다.
Dynamic Branch Prediction
branch로 인한 페널티는 너무 심하기 때문에 동적 예측을 사용해야한다.
대개 prediction으로 커버된다. x86은 17 cycle 가까이 손해볼 수 있으므로 여기에 힘을 많이 쓴다.
branch의 PC주소를 하드웨어 저장공간에 indexing하여 저장하고 이에 대한 taken/notTaken을 1,0으로 표시하는 방법으로 저장한다. 1이면 taken으로 PC를 바꾸고, 0이면 PC+4를 수행하는 식이다.
하드웨어의 크기로 하위 몇비트를 볼지 결정한다.
one-bit predictor

위와 같은 FOR문 같은 경우, taken으로 가다 not taken을 만나면 not taken으로 변경되고 바로 taken이 발생하기 때문에 최소 두 번의 손실을 겪는다.
two-bit predictor
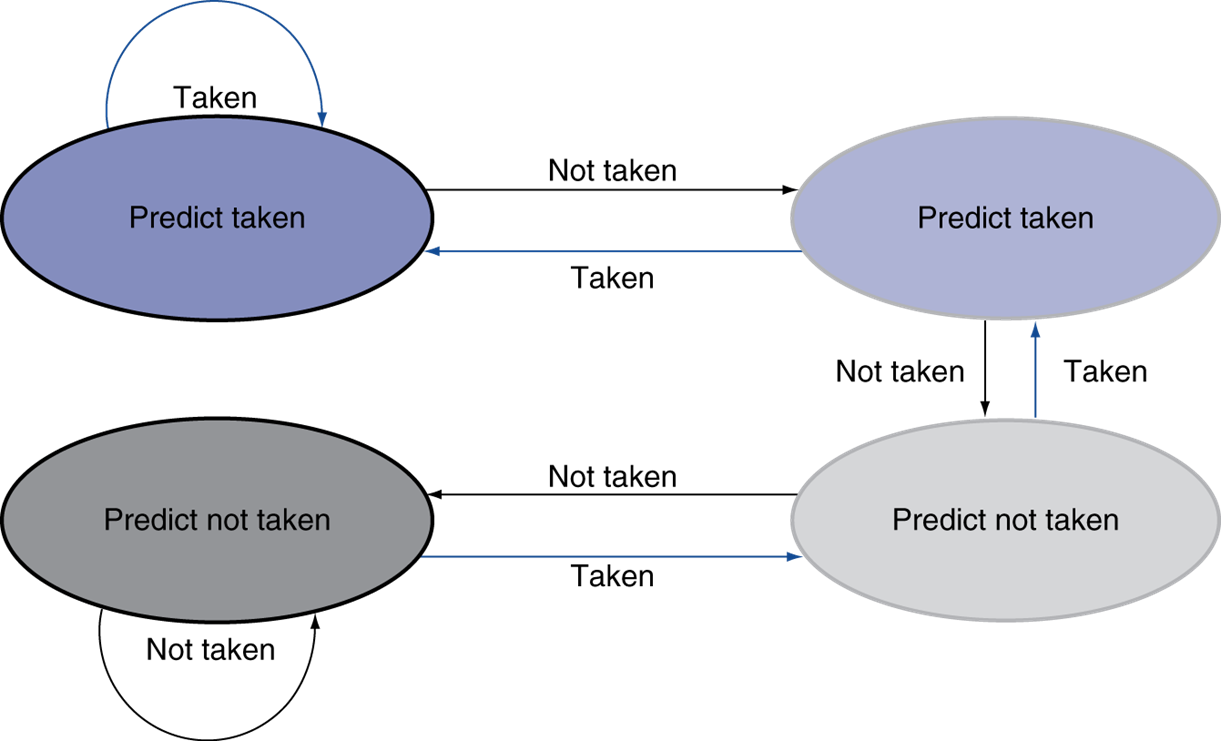
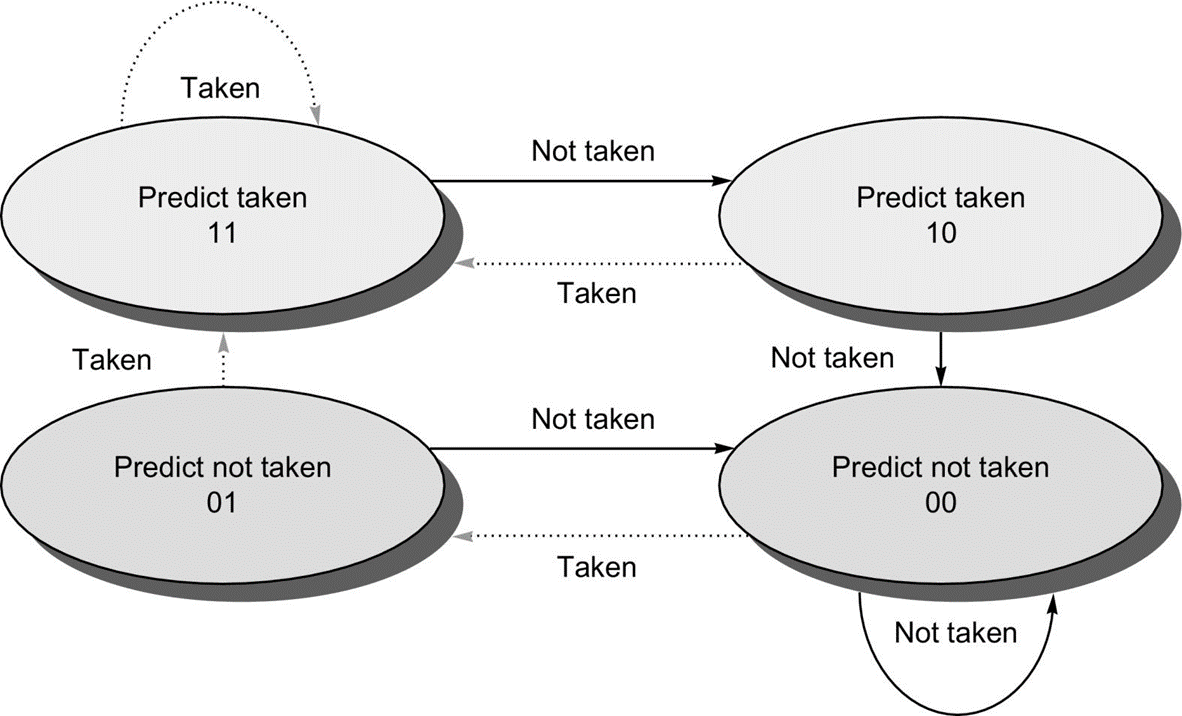
위와 같은 2bit predcitor로 처리할 수 있다. 둘의 차이는 not taken 두 번 발생시, taken으로 돌아오기 위한 조건이 다르다. 후자는 not taken 상황에 두 번 틀려야 taken으로 돌아오고 전자는 taken 한 번 발생시 돌아갈 길이 존재한다.
추가로 점프해야할 곳은 instruction을 읽어서 수행했는데, 이를 사실 cache에 저장해놓는다.
