MIPS architecture에서의 Pipelining을 알아보자.
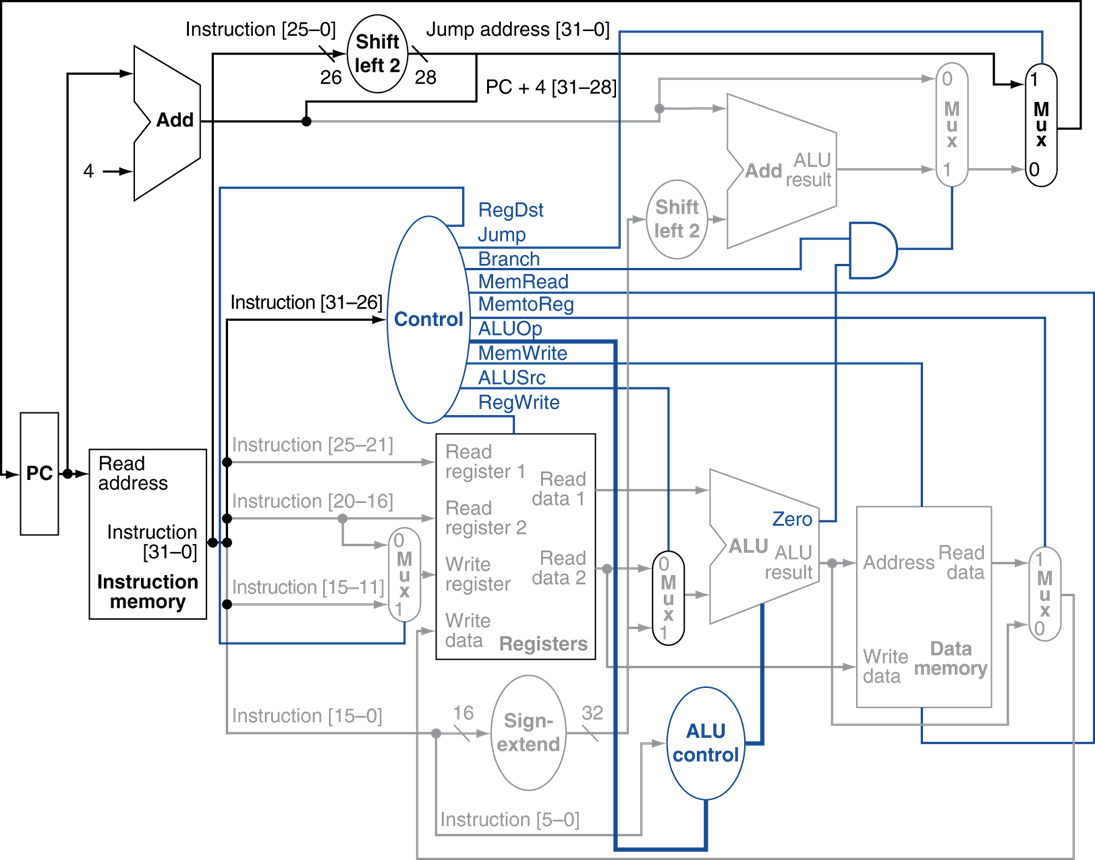
이전에 보았던 component들의 조합으로 위와 같은 MIPS 하드웨어 구현을 알아보았다.
여기서 가정은 모든 instruction들이 한 cycle로 수행이 되는 것이었고, load, store instruction이 가장 오래걸리기 때문에 이를 기준으로 한 cycle을 잡았다.
instruction memory -> register file -> ALU -> data memory -> register file 총 data path가 이만큼 걸린다.
그러나 Jump 같은 경우는 memory, register file 참조 업시 PC값만 단순하게 변경하면 된다.
모든 instruction은 load/store 연산 때문에 낭비되는 시간이 존재한다.
이를 개선해야한다. 이를 pipeline으로 해결한다.
Pipleline
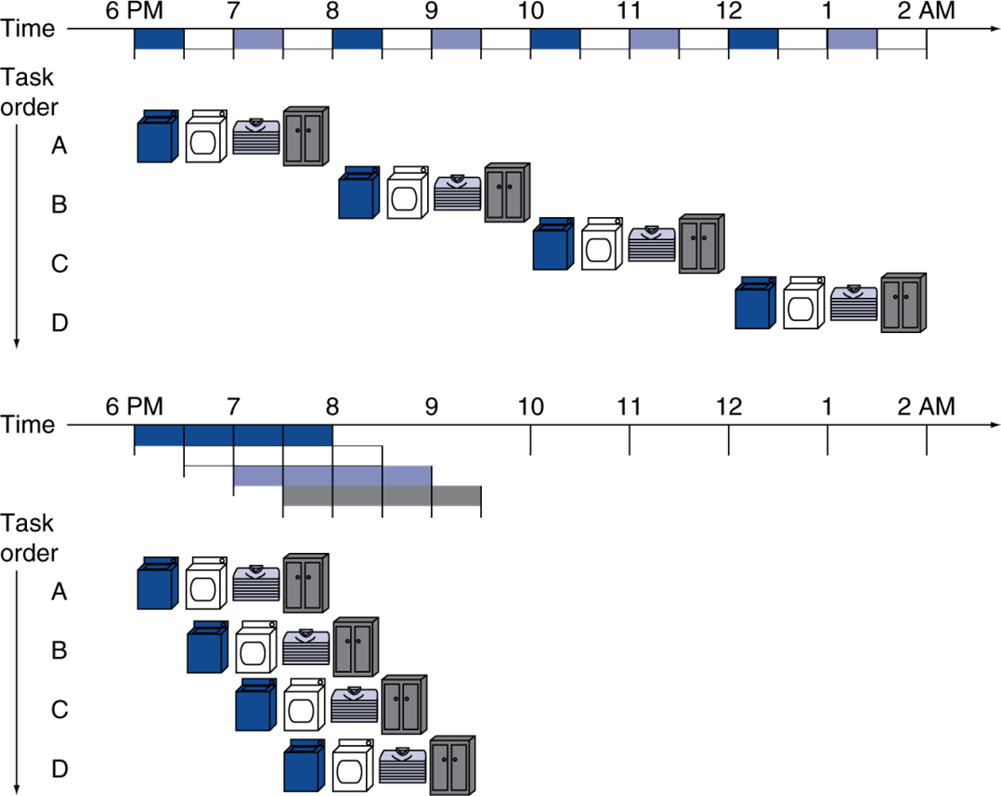
세탁 -> 건조 -> 옷장 까지의 일련의 수행을 하나의 instruction으로 보자.
위의 방식으로 하드웨어를 구현하였다면, 세탁기와 건조기 등 수행이 끝났을 경우 idle해진다.
이를 pipeline 형태로, 기계가 idle해졌다면, 다음 instruction을 수행하여 단위 시간에 더 많은 instruction을 수행할 수 있을 것이다.
cycle 중 일부분을 포착해보면, 다양한 instruction이 수행되는 것을 확인할 수 있을 것이다.
SpeedUp
- 네 개의 instruction: 8/3.5 = 2.3
8시간 걸리던 세탁이 3.5시간만에 끝이 난다.- 무한이 이루어질 경우: 2n/0.5n + 1.5 ≈ 4
2시간마다 instruction이 시작되다가, 0.5시간만에 instruction이 시작된다.
4배가 좋아진다.
이 원리를 사용하여 MIPS Pipeline을 구현한다.
Pipeline
하나의 instruction을 세탁기, 건조기와 같이 다섯 단계로 나눈다.
IF: Instruction fetch from memory
ID: Instruction decode & register read
EX: Execute operation or calculate address(Using ALU)
MEM: Access memory operand
WB: Write result back to register
그리고 레지스터 접근은 100ps, 나머지 stage는 200ps가 소모된다 가정하자.
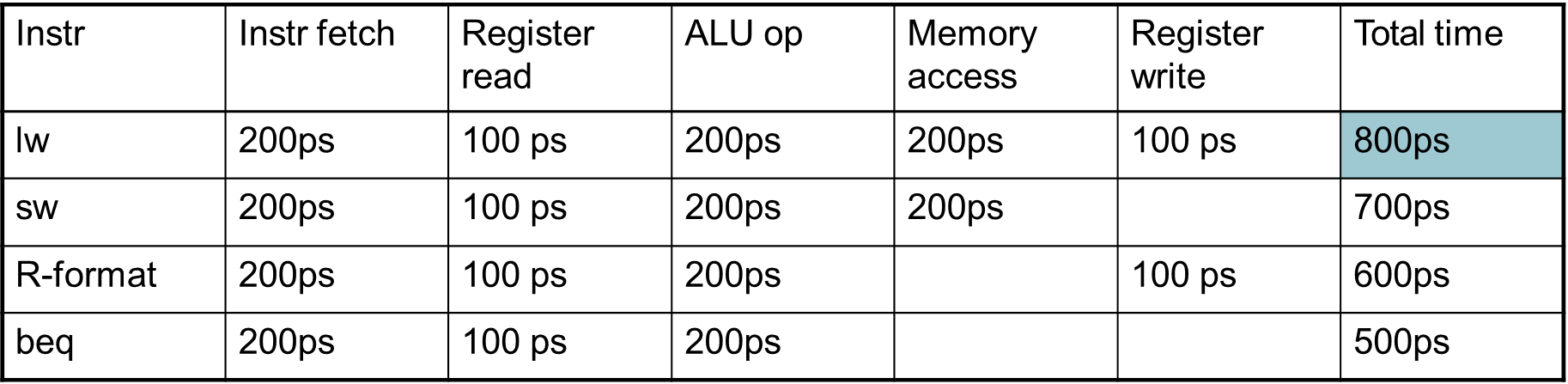
각각의 instruction이 total time만큼 소모되나 이를 병렬적으로 수행하여 수행시간을 감소시킨다.
메모리에 접근을 안하는 instruction일 경우에도 정적으로 5 page를 나누어 놓고 pipeline을 구현하기 때문에, 무조건 대기 상태에 머물러야 한다. 즉 모든 instruction은 5 page가 있다는 형식으로 pipeline이 구현된다.
그리고 page의 길이는 정적으로 고정된다 했는데, 이는 가장 긴 연산의 한 cycle로 고정되며 200ps로 고정한다 가정한다.
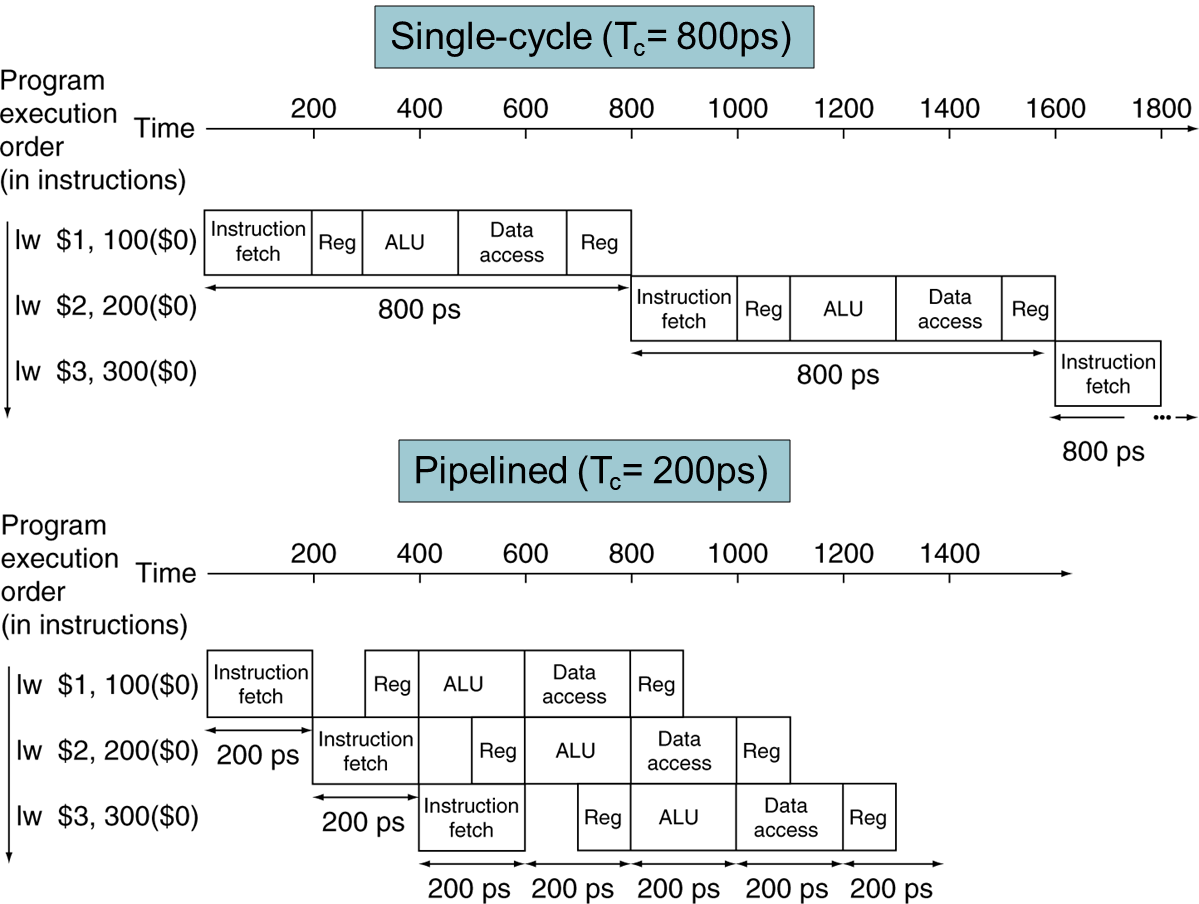
위와 같이 pipeline이 구현되며 모든 instruction이 위와 같은 시간을 소모한다.(사용하지 않는 page는 대기한다.)
그렇다면 4배정도 빨라진 모습을 볼 수 있다.
하지만 하나의 instruction은 관점으론 대기시간으로 인해 Turnaround time은 늘어날 수 있다.
(latency가 늘어난다.)
pipeline 구현에 있어서, 모든 stage가 다 동일한 시간을 소모한다면 다음과 같은 Speedup을 얻을 수 있다.
1000ps가 걸렸을 경우, 5개의 stage로 나누어 pipeline을 구현하면 200ps가 걸릴 것 같다.
하지만 대기 시간 때문에 latency가 늘어나 정확히 stage 개수만큼 속도가 빨라지지 않는다.
이는 쓰루풋이 증가한다. 하지만 instruction 하나당 turnaround time은 증가한다.
Pipelining in MIPS
- MIPS와 같은 경우 모든 instruction이 32bit이기 때문에 decode가 간단하다.
하지만 x86같은 경우는 instruction이 너무 다양하기 때문에 decode에 불리하다.- instruction format이 간단하고 규칙적이기 때문에 decode와 register에서 값을 읽어오는 것을 한 번에 처리할 수 있다.
Instruction fetch는 첫 번째, decode와 register 접근은 두 번째 stage로 지정한다.- load/store의 경우에도 ALU를 사용해야하기 때문에, 세 번째 stage에 ALU 연산, 네 번째 stage에 memory 접근으로 지정한다.
- 메모리 접근이 한 cycle로 수행된다고 가정한다. 메모리 접근을 다섯번째 stage로 지정한다.
원래는 더 오래걸리지만 쉽게 이해하기 위함이다.
