DB는 disk에 저장되기 때문에 메모리로 load를 해야한다. 이는 cost가 크며, 좀 더 효율적으로 insertion과 deletion을 수행하기 위해 I/O 연산의 time complextiy를 계산하여 더 좋은 알고리즘을 찾아야한다.
External-memory model이라고도 불리며 notation을 알아보자.
- N: disk에 존재하는 N개의 레코드이다.
- M: 메모리의 크기이다.
- B: Block의 크기이다.
알고리즘의 시간 복잡도를 계산하듯, DB 연산을 위한 I/O 연산의 시간복잡도를 통해 어떤 알고리즘이 더 좋은지 알아보자.
메모리에서 cpu로 상호작용하며 발생하는 연산 수는 고려하지 않는다.
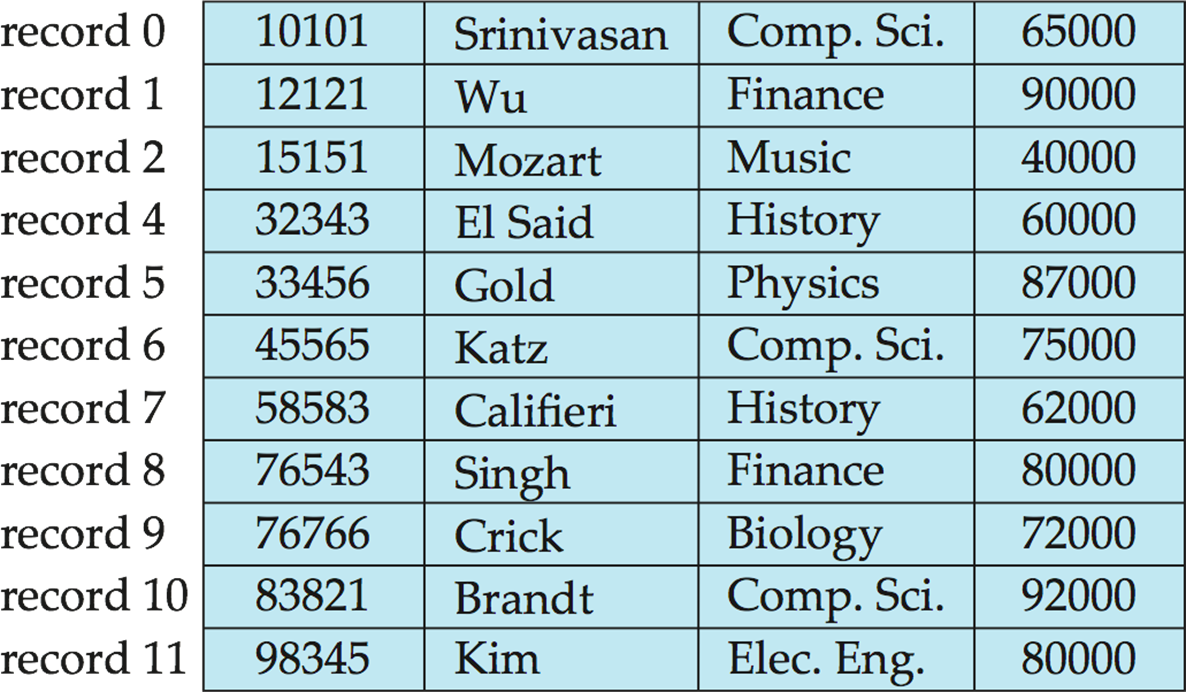
하나의 record를 삭제하고 나머지를 shift하는 deletion은 모든 block을 메모리로 올려야하기 때문에 시간 복잡도를 가진다. 선형시간을 가진다.
비효율적이다.
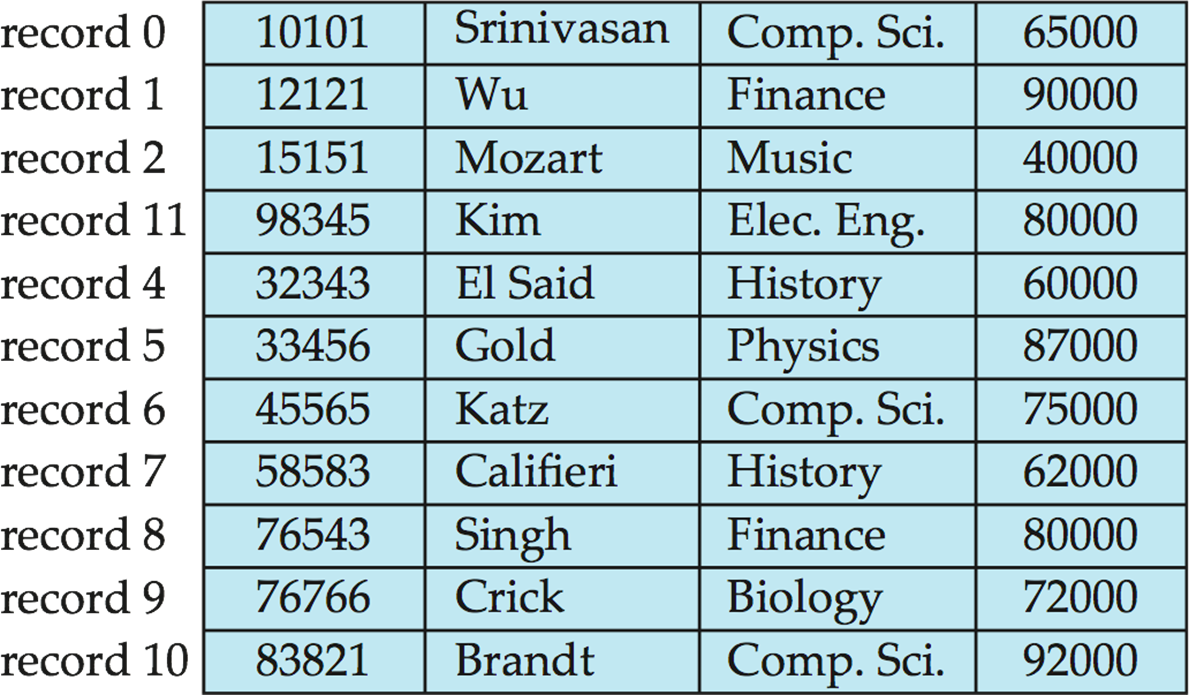
맨 마지막의 record를 삭제된 자리에 채워넣는 방법으로, 맨 마지막의 block과 삭제할 record가 존재하는 block을 메모리에 올려 삭제 후, 빈 자리를 마지막 record를 채운다. 두 개의 block load, write back이 소모되므로 시간 복잡도를 가진다.
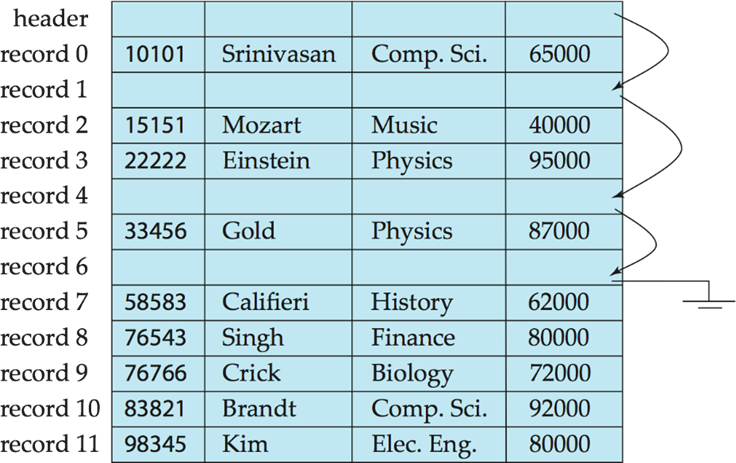
삭제 후 free list에 저장해야하는데, free list 맨 마지막 node에 저장하면 선형 탐색을 해야하므로 모든 block을 메모리에 다 load 해야한다. 그러나 header 맨 앞 node에 저장한다면 로 충분히 수행할 수 있다.
What happens in a block?
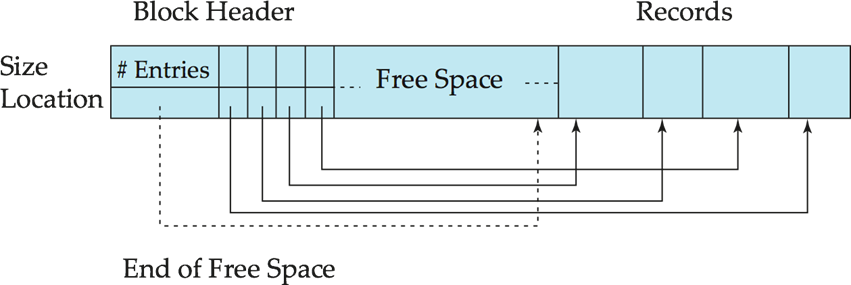
record의 값이 변수인 경우 fixed part인 왼쪽과 variable part인 오른쪽이 존재한다.
오른쪽 부분은 아래에서 위로 올라오며 record가 저장되는데, 저장을 위해서 Free Space에 저장될 것이다. 그리고 이를 가리키는 entry 하나를 할당한다. 하나의 block만 메모리에 올라가기 때문에 의 시간복잡도를 가진다. free list를 사용하여 deletion이 발생했을 때, 비어있는 공간보다 더 작은 경우, record 사이에 비어있는 공간이 발생할 수 있다.
더 큰 record를 삽입해야한다면 다른 곳에 저장해야할 수 도 있다.
이러한 경우를 타개하기 위해 record를 아래 부분으로 shift 해줘야 한다.
그럼 entry인 pointer 값을 변경해야한다.
shift + entry update는 모두 CPU 연산이므로 고려하지 않는다.
entry를 따로 관리하는 index 파일이 존재한다. index의 cell은 포인터를 가지고 있으며 entry를 가리킬 것이다.
Records in Files
파일에 레코드들을 어느 block에 위치시켜야 할까?
- Heap: 파일 아무데나 저장된다. 빈 공간에 저장하며 빈 공간을 관리하는 free space map이 존재한다. 순서에 상관없이 비어있는 곳에 record를 저장한다.
- Sequential: block이 존재할 때, block에 sequential하게 저장한다.
id와 같은 attribute를 search key로 지정하여 이에 맞게 정렬하여 저장한다.- Hashing: 어떤 attribute hash 함수를 사용하여 거기에 해당하는 block에 저장한다.
Sequential
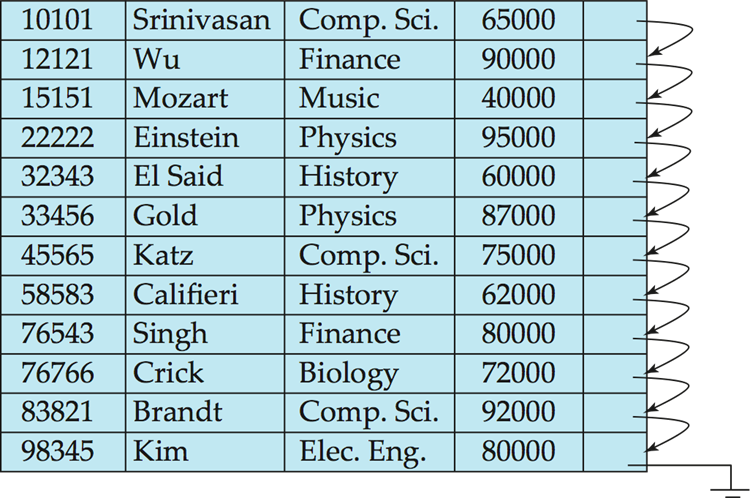
이렇게 id attribute를 search key로 지정하여 record를 저장하면 특정 record를 찾기 쉬울 것이고, 이러한 경우 범위가 있는 attribute를 search key로 지정했을 때 더 편할 것이다.
(e.g. 첫 번째 자리가 1인 경우 등)
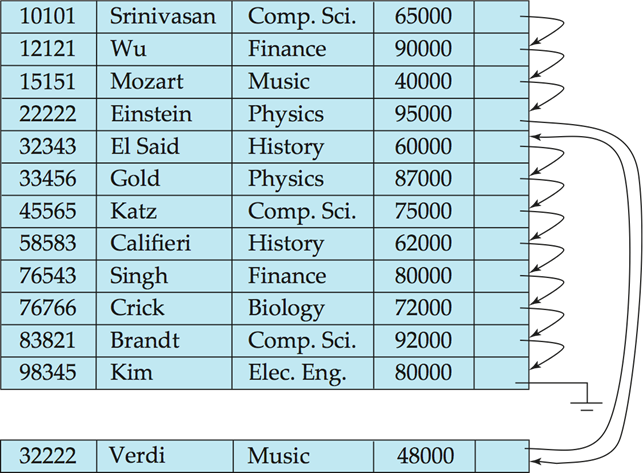
DB는 업데이트가 제일 중요하다. 중간에 insertion이 발생했을 때, 중간에 넣고 물리적으로 정렬하기 위해 shift할 것인가? overflow block을 따로 만들어, 여기에 저장하고 list와 같은 방법을 통해 논리적으로 연결해준다.
만약 insertion과 deletion 발생이 잦아 file의 구조가 완전히 무너진다면 다시 한 번 정렬해야한다.
삽입할 때, 삽입 block과 overflow block 간의 shift를 하여 최적화할 수 있다.
Block
block은 저장과 데이터 전송의 단위이다. 데이터베이스를 설계할 때 block의 메모리 이동을 최소화하는 것이 목표이다.
이를 위해 버퍼가 사용된다. 사용된 block을 메모리 버퍼에 남겨두는 것이다.
이를 관리하는 것이 버퍼 매니저이다.
버퍼 매니저는 찾고자하는 block이 버퍼에 존재한다면 메인 메모리의 block의 주소를 반환한다.(디스크로 가지 않음)
block이 버퍼에 없다면 버퍼 매니저는 block을 디스크에서 가져올 때, 버퍼에 저장한다.
버퍼에 저장할 때, 꽉 차있다면 block을 삭제한다. 만약 그 block이 최근에 업데이트가 되었다면 이를 디스크에 저장한다.(dirty block)
LRU(least recently used strategy)
LRU 방식은 OS에서 사용하는 방식으로 block을 가져올 때, 가장 오래 사용되지 않은 block을 삭제하는 기법이다.
이는 가장 최근에 사용된 block이 미래에도 사용된다는 가정을 기반한다.

그러나 위의 join 연산을 보면, 즉 테이블의 하나의 record에 대해 다른 테이블의 모든 record와 비교한다. 이를 순차적으로 수행한다. 이 존재하는 block을 메모리에 올려두고 의 block을 가져올 때, LRU는 좋지 않은 방법이다. 가장 오래된 block이 곧 사용될 것이기 때문이다. 그럼 반대로 가장 최근에 사용된 block을 버린다.
이를 MRU strategy(Most recently used) 방법이라 한다. 그리고 이 존재하는 block은 삭제되면 안되기 때문에 이와 같은 block을 pinned block이라 칭한다.
