DB가 디바이스에 어떻게 저장되는지 확인해보자. 하드디스크, 메모리, 캐시 등 하드웨어에서 어떻게 동작하는지 알아본다. 추가로 DB를 저장하는 소프트웨어적 자료구조를 알아본다.
Storage
DB에서 데이터를 사용해야할 때, 그때마다 디스크에서 메모리로 데이터를 가져온다면 굉장히 느릴 것이다. 이를 메모리에 미리 로드해놓고 사용해야 더 효율적일 것이다.
DB는 OS의 파일 시스템을 사용한다. 이 파일이 어떻게 저장되는지 확인해보자.
DB는 파일들로 저장된다. 하나의 파일은 records의 sequence로 구성되어 있다.
record는 fields의 sequence이다. field는 attribute의 값이다.
디스크에서 메인 메모리로 옮겨질 때는 block단위로 저장한다.(block은 여러개의 records를 가지고 있을 수 있다.)
필요한만큼 disk에서 계속 메모리로 로드한다면 당연히 엄청나게 비효율적일 것이다.(약 100~1000배 정도의 속도차이가 존재한다.)
file의 구조에서도 block 단위로 data를 나눠놓아야 한다.
파일의 크기는 content가 1 byte라도 block단위로 데이터가 저장되기 때문에 disk에 저장되는 크기는 더 클 것이다.
이제 파일의 구조를 확인하기 위해 다음을 가정한다.
- record의 크기는 고정되어 있다.
- 각각의 파일은 하나의 타입의 record만 존재한다.
- 하나의 relation은 하나의 파일에 완전하게 존재한다.(나뉘어서 저장되는 경우도 있다.)
Fixed length Records
record가 파일에 어떤 형태로 존재하는지 알아보자.
- record i는 n * (i - 1) byte에 저장되어 있다.
array와 비슷하게 동작한다.- block의 정해진 크기만큼 record를 저장한다. record의 크기가 넘칠 경우 다음 block에 저장한다.
- insertion은 그냥 끝에 추가하면 되지만 delete의 경우 shift를 할 것 같지만 그렇지 않다. 그냥 비워두고 다음 insertion에 채워준다. free list로 비어있는 cell을 관리한다.
맨 마지막 cell을 삭제된 cell에 채워 넣을 수도 있다.
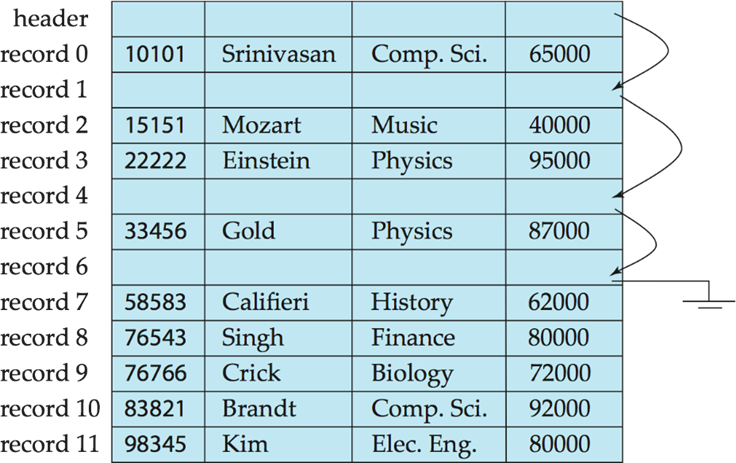
위와 같이 free list를 사용하여 free cell을 연결할 수 있다. 당연히 list의 header 앞에 넣는 것이 좋다.
Variable length Records
만약 varchar와 같은 타입을 사용하여 record의 크기가 달라지면 어떻게 처리해야할까?
 앞쪽은 fixed length와 변수인 field에 대한 정보 (offset, length)를 저장한다.
앞쪽은 fixed length와 변수인 field에 대한 정보 (offset, length)를 저장한다.
뒷쪽은 변수에 대한 data를 저장한다.
null 값이 존재하면 Null bitmap에 저장해놓는다. 만약 단지 구분자로 구분해 놓았으면 record하나를 다 탐색해야한다. 하지만 이 방법은 상수시간에 field값을 참조할 수 있다.
Records in Block
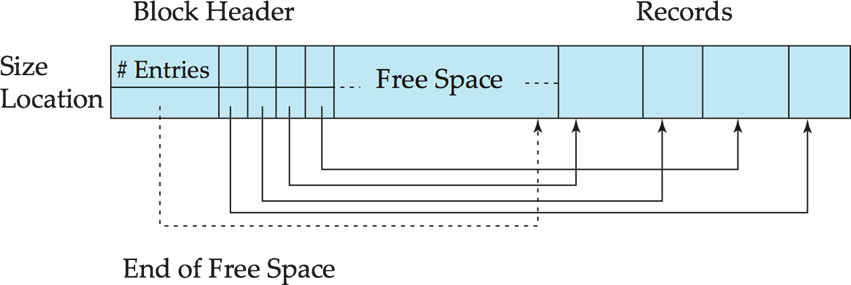
block header와 records로 나누어져있다. header엔 레코드의 정보(위치, 크기)가 담겨져 있다.
records 정보는 포인터로 나타낼 수 있다.
block header엔 record 개수, free space의 크기 등을 저장할 수 있다.
3번째 record를 가기 위해 주소값이 4 바이트라면, 4 * 3 = 12 byte로 이동한 뒤 포인터를 통해 레코드로 이동할 수 있다.
