Numpy
Numpy는 numerical Python의 약자로 파이썬에서 수학 연산을 해주는 라이브러리이다.
넘파이의 대략적 기능은 아래와 같다.
Features
- 행렬의 스칼라배는 행렬안의 모든 원소에 스칼라를 곱해야줘야 한다. 일일이 반복문으로 해결할 필요 없이 행렬에 대한 스칼라배를 지원해준다. 이를 batch이라고 한다.
- batch가 가능한 이유는 행렬에 대한 스칼라배는 결국 스칼라배를 하기 위한 수를 행렬로 만들어 하나씩 곱해줘야한다. 이를 지원해주는게 broadcasting이다.
- 행렬의 곱이나 합도 반복문으로 처리를 해주지 않고 array간의 연산을 지원해준다.
- 선형대수학(역행렬, 전치행렬 등), 난수 발생, 푸리에 변환 등의 연산을 지원한다.
Advanges
- Numpy는 C언어로 만들어진 라이브러리이기에 빠른 속도를 보장한다.
- Numpy는 데이터를 연속적인 메모리 공간에 저장한다. 다른 built-in 데이터 타입들과 독립적이다.
- 이러한 이유로 파이썬의 데이터 타입을 확인하지 않아도 되기 때문에 overhead가 들지 않는다.
- Numpy의 배열은 파이썬의 배열보다 메모리를 적게 사용한다.
Basics
randn
import numpy as np
data = np.random.randn(2, 3) # 난수 2x3 행렬생성
print(data) # 2x3의 난수 행렬batch
반복문 필요 없이 스칼라배, 행렬 덧셈 등을 지원한다. 블록 형태 메모리에 저장되기 때문에
한 번에 연산이 가능하여 속도가 빠르다.
print(data * 10) # data x 10 행렬
print(data + data) # data + data 행렬dtype, shape
shape는 행렬의 크기, dtype은 행렬에 있는 원소의 타입을 확인할 수 있다.
print(data.shape) # (2, 3)
print(data.dtype) # float64Creating Numpy's Array
파이썬의 built-in 타입인 list와 Numpy의 array 초기화를 알아보자.
data1 = [6, 7.5, 8, 0, 1] # built-in list
arr1 = np.array(data1) # list to numpy array
arr1 = np.zeros(10) # 1x10 matrix with all zeros
arr1 = np.zeros((3, 6)) # 3x6 matrix with all zeros
arr1 = np.arange(15) # 1x15 matrix with [0, 14]
arr1 = np.empty((2,3,2)) # 2x3x2 matrix with garbage values
행렬 초기화 목록

데이터 타입을 미리 지정하여 배열을 생성할 수도 있다.
arr1 = np.array([1,2,3]. dtype=np.float64)
arr1 = np.array([1,2,3]. dtype=np.int64)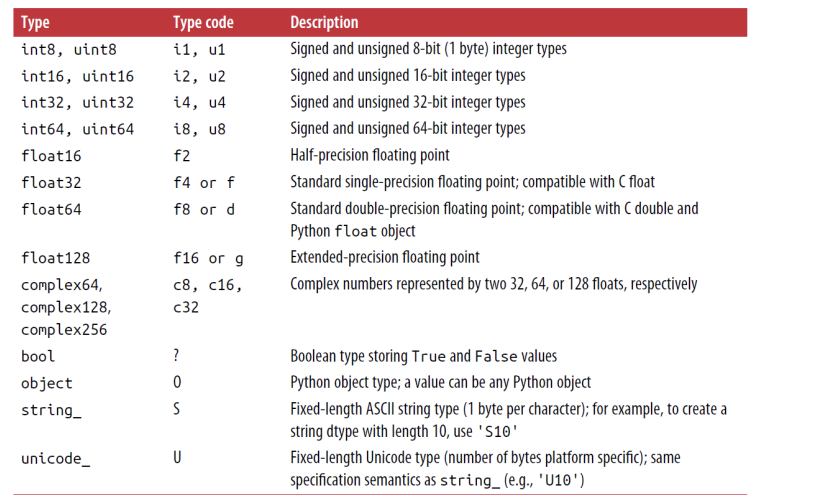
Data type casting
astype은 하나의 타입을 다른 타입으로 바꾸는 explicit converting or casting 이다.
arr = np.array([1, 2, 3, 4, 5])
float_arr = arr.astype(np.float64) # Opposite can be done
string_arr = np.array(['1.22', '9.6', '-4.2'], dtype=np.string_)
string_arr = string_arr.astype(float)Vectorization
vectorization은 반복문 없이 한 번에 스칼라배나 행렬의 연산을 지원하는 기능이다.
arr = np.array([1., 2., 3.],[4., 5., 6.])
print(arr * arr) # 반복문 필요 x
print(arr - arr) # 반복문 필요 xBroadcasting
vectorization + 행렬의 연장이다. 크기가 다른 행렬끼리의 연산을 내부적으로 크기를 맞춰(늘려) 연산을 가능케 해주는 기능이다.
mean
- mean(0)은 nxm 행렬의 열의 평균을 배열로 반환한다. 1xm의 배열
- mean(1)은 nxm 행렬의 행의 평균을 배열로 반환한다. nx1의 배열
행 연장
4x3 행렬 + 1x3 행렬의 연산은 1x3 행렬을 같은 행의 값을 복사하여 4x3으로 만들어준다.
arr = np.array([[0, 0, 0],[1, 1, 1],[2, 2, 2],[3, 3, 3]])
arr_col_mean = arr.mean(0) # 얄의 평균 1x3 행렬
demeaned = arr - arr_col_mean # broadcasting, 4x3 행렬 + 1x3 행렬
print(demeaned.mean(0)) # [0., 0., 0.]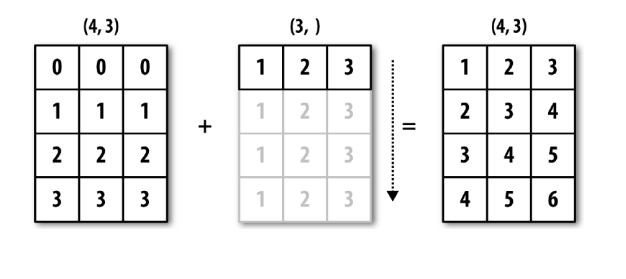
열 연장
열 연장은 행 연장과 다르게 열의 값이 정해지지 않는다. (4,)의 크기를 가지기 때문에
이를 reshpae를 이용하여 (4,1)로 바꾸어 주어야 한다.
arr = np.array([[0, 0, 0],[1, 1, 1],[2, 2, 2],[3, 3, 3]])
arr_row_mean = arr.mean(1) # 행의 평균 4x? 행렬
# demeaned = arr - arr_col_mean # broadcasting, 4x3 행렬 + 4x? 행렬 broadcasting 실패
arr_row_mean = arr_row_mean.reshape((4, 1))
demeaned = arr - arr_row_mean
print(demeaned.mean(0)) #[0, 0, 0, 0]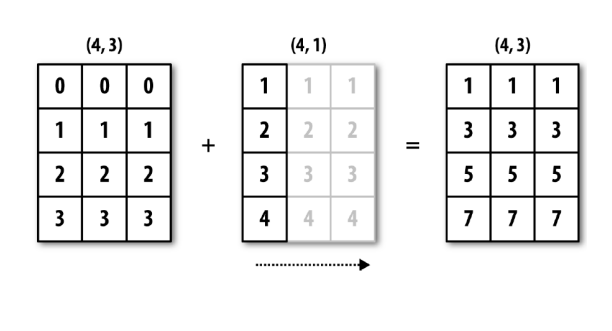
3차원 broadcasting
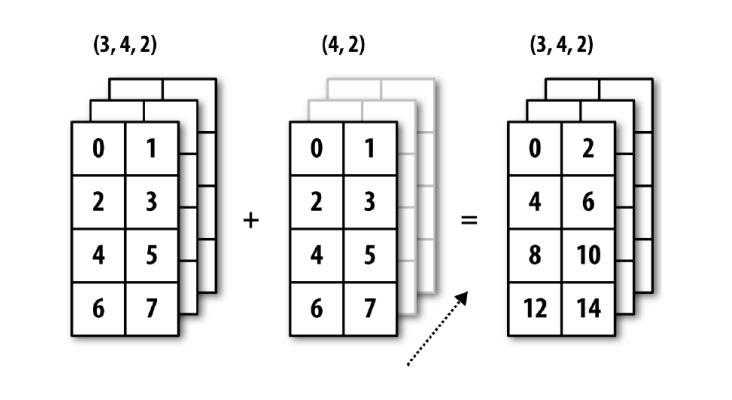
~~3차원은 나중에 할란다...~
Indexing and Slicing
파이썬에서 지원하는 slicing과 동일하게 지원한다.
- arr[row, col] == arr[row][col] 형태의 indexing을 지원한다.
- [4:6] 4부터 5까지이다. 1차원이면 4~5 index, 2차원이면 4~5까지의 열 또는 행이다.
- [:] 전부이다. [:3] 처음부터 2까지이다. [3:] 3부터 끝까지이다.
- [-5:] 뒤에서 5 번째 인덱스 부터이다.
- C언어와 유사하게 배열의 전달은 참조 방식이다.
- 값 복사만을 위해 .copy() 함수를 사용할 수 있다.
arr = np.arange(10) # 0~9의 배열 생성
print(arr[5:8]) # 5~7 index 원소 출력
arr[5:8] = 12 # 5~7 index 원소 12로 변경
arr_slice = arr[5:8] # index 5에서 7까지의 배열 생성 후 전달
arr_slice[1] = 1234 #원본값과 arr_slicies 모두 변경2 dimentional array
arr2d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(arr2d[2]) # [7, 8, 9] #1차원 배열 전달
print(arr2d[0][2]) # 3
print(arr2d[0, 2]) # 3 as same as this line above3 dimentional
arr3d np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]])
print(arr3d[0]) # [[1, 2, 3], [4, 5, 6]]
arr3d_copy = arr3d[0].copy() # 위의 2x3 배열 전달
arr3d[0] = 42 # arr3d[0]의 모든 값 42로 변경
arr3d[0] = arr3d_copy # 기존의 값으로 변경
print(arr3d[1, 0]) # arr3d[1][0]의 1차원 배열 출력2 dimentional array slicing
2차원의 slicing도 간단하다. 밑의 규칙을 보자
- arr[:2, 1:] shaple(2, 2) 형태의 2차원 배열을 반환한다. :2는 열 1까지이고 1:는 행1부터이다.
비어있는 경우는 끝까지 slicing한다는 뜻이다.- arr[2] == arr[2, :] == arr[2:, :]
위의 경우 차례대로 2번째 열, 2번째 열 그리고 행 전부, 2 번째 열부터 끝까지, 행 전부
2가 2차원 배열의 마지막이기 때문에 잘 작동하는 것이다.arr2d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) print(arr2d[:2]) # [[1, 2, 3], [4, 5, 6]] print(arr2d[:2, 1:]) # [[2, 3], [5, 6]]
Boolean Indexing
하나의 행렬을 indexing 하는 방법 중 하나이다. 특정 배열을 원하는 조건에 따라 인덱싱할 동일할 열의 크기를 가진 배열을 하나 더 생성한다. 그 조건에 맞게 인덱싱을 한다.
input
output
~연산자
input
output
| 기호를 사용하여 or 형태로 사용할 수도 있다.

Fancy Indexing
list를 사용하여 인덱싱을 할 수 있다.
- arr[[2, 3, 4, 5]]는 인덱스 2, 3, 4, 5를 출력한다.
- 2차원일 경우 arr[[2, 3, 4, 5], [3, 4, 5, 6]]은 arr[2][3], arr[3][4], arr[4][5], arr[5][6]을 각각 출력한다.
Transposing Arrays and Wapping Axes
- array.T는 전치행렬을 리턴한다.
- array.dot(array.T)는 특정 행렬과 전치 행렬의 dot product를 리턴한다.
- np.dot(array, array.T) 형태도 가능하다.
위는 모두 2차원 행렬에서 주로 사용하는 방법이다.
3 dimentional array Transposing
axis의 개념부터 알아보자.
axis란 배열의 축이라고 생각하자. 2차원 배열로 따졌을 때 행과 열이다.
3차원 배열은 2차원 배열을 담고 있는 1차원 배열이라 생각해보자. 그럼 1xn 형렬에 2차원 배열이 담겨있는 것이다. 이는 이는 NxMxR shape의 3차원 배열이라 하자.
각각 축의 크기를 axis0(3차원 행), axis1(행), axis2(열) 라고 두고 transpose나 swapaxes 함수를 사용할 수 있게 된다.
transpose

그렇다면 위의 사진의 output은 무엇일까? axis 0과 1을 교환해야한다. 그런데 위의 3차원 배열은
2x2x4 형태를 띠고 있기에, axis0과 axis1을 교환해도 값이 변경되면 안 된다고 생각했다.
하지만 값은 바뀌어 있었다.
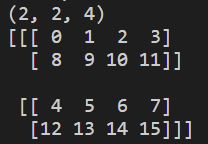
위의 사진과 같이 크기는 동일했지만 arr[0][1]과 arr[1][0]이 swap 되어 있었다.
이유는 아래 링크의 이미지를 참고하자.
이는 stackoverflow의 답변을 확인하자.
swapaxes

위의 사진은 이해하기 쉬울 것이다. 2x2x4 3차원 배열의 axis 교환이 이루어진다.
axis1과 axis2를 교환한다면 2x4x2 배열이 된다. 그렇다면 3차원 배열안의 2차원 배열(행렬)을 전치행렬로 바꿔주면 된다. 이 원리는 위의 링크를 참조하면 이해하기 굉장히 쉬울 것이다.
Universal Functions
Universal Function은 넘파이 각각 원소를 빠르게 처리해주는 함수를 뜻한다. 이전의 함수들과 비슷하게 반복문이 필요하지 않다.
Unary 함수부터 알아보자.
np.sqrt(arr)
각 원소의 제곱근을 가진 넘파이 배열 반환 arr1 = np.sqrt(arr2) == np.sprt(arr2, arr1)
np.exp(arr)
각 원소가 e의 지수가 되는 값들을 가진 넘파이 배열 반환
Binary 함수를 알아보자.
np.maximum(arr1, arr2)
두 배열을 인자로 받아 각 원소 중 값이 더 큰 원소를 가진 배열 반환
np.modf(npArr)
하나의 배열의 나머지와 몫 부분을 순서대로 반환한다.
np.meshgrid(points, points)
매개변수로 두 개의 일차원 배열을 전달한다면 두 개의 이차원 배열을 반환한다.
첫 번째 반환된 배열의 하나의 행의 모든 원소는 같다. 반대로 두 번째 반환된 배열의 하나의 열의 모든 원소는 같다.
np.where(arr1, arr2, boolArr)
xarr = np.array([1.1, 1.2, 1.3, 1.4, 1.5])
xarr = np.array([2.1, 2.2, 2.3, 2.4, 2.5])
cond = np.array([True, False, True, True, False])
result = [(x if c else y)
for x,y,c in zip(xarr, yarr, cond)]
result = np.where(cond, xarr, yarr) # 두 값이 동일.위의 코드와 같이 np.where은 조건과 값 두 개를 받는다. 그런데 조건이 배열이라면 값은 그냥 스칼라 값이여도 배열이 생성된다. 그 배열은 boolarr의 형태를 그대로 가져간다.
axis=1 or axis=0
arr.mean(axis=1)은 행에 대한 평균. 모든 열에 대해 연산을하니
axis=0은 반대이다.
arr.cumsum()
arr.cumsum()은 누적합을 담고 있는 배열 반환
arr.any() & arr.all()
boolean 타입의 넘파이 배열을 arr라고 칭하자.
arr.any()는 true가 하나라도 있으면 true 반환. 아니면 false
arr.all()는 원소가 모두 true라면 true 반환. 아니면 false
arr.sort()
arr.sort() 오름차순 정렬
arr.sort(axis=1) 행 부분 오름차순 정렬
np.unique(arr)
arr의 중복원소가 제거되고 오름차순으로 정렬된 배열을 반환
np.in1d(arr1, arr2)

x.dot(y) == np.dot(x, y) == x @ y
벡터의 내적이다. 이차원 배열이면 행렬의 곱셈이다.
np.linalg.inv() & np.linalg.qr()
qr 분해와 역행렬을 구하는 함수
np.random.normal(size=(4, 4))
표준정규분포를 따르는 난수를 원소로 가지는 4x4 행렬 반환
seed

