간단한 disk I/O를 효율적으로 하기 위한 disk scheduling을 알아보자.
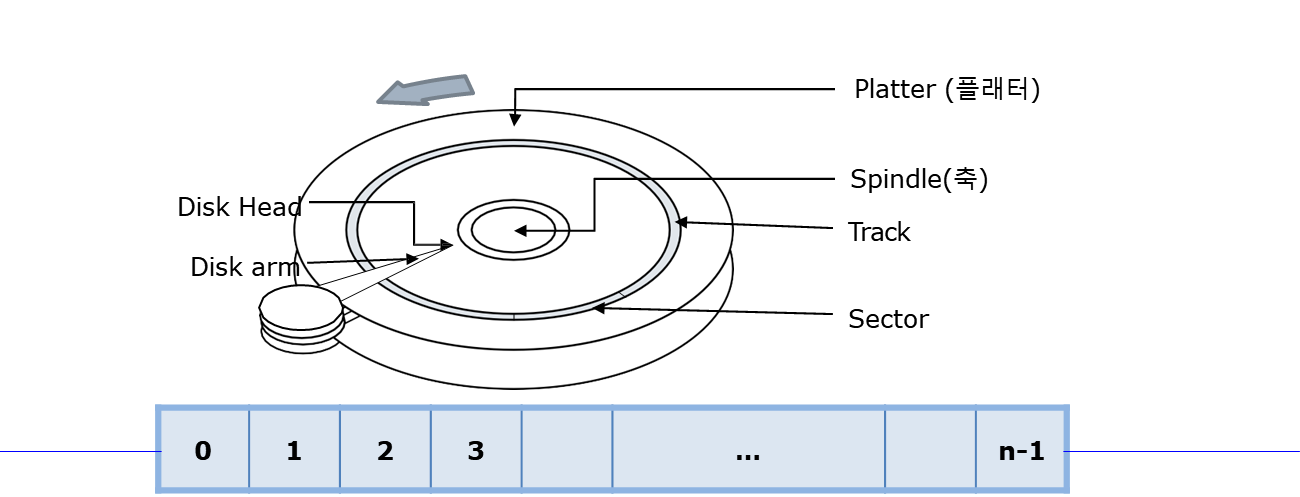
하드디스크는 다음과 같이 생겼다.
- Platter: 데이터가 저장되는 판이다.
- Spindle: 플래터를 움직이는 모터이다. RPM을 결정한다.
- Track: 플래터 위의 동심원이다. 플래터는 track으로 나뉜다.
- Sector: Track에 데이터가 저장되는 공간이다.
연속적인 sector를 탐색하는 것은 당연히 random access보다 빠르다.
Disk Layout
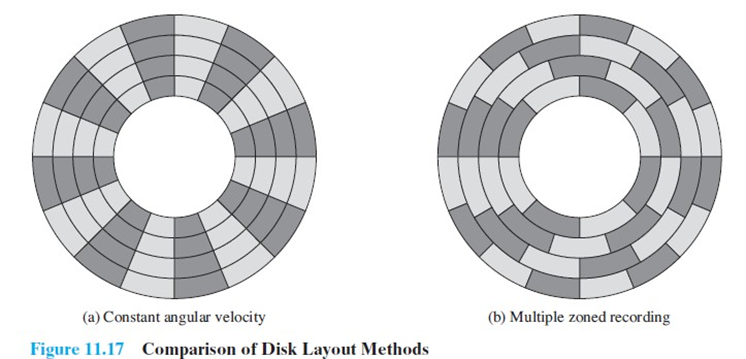
대부분의 시스템에서 sector는 고정된 길이를 가진다. 512~4KB byte이다.
오른쪽의 CAV 기법은 모든 track의 sector 수를 일정하게 두고 플래터의 각속도를 일정하게 두는 방식이다.
이 방법은 sector의 밀도가 떨어진다. spindle에서 멀어질수록 sector의 저장용랑은 커지는데 밀도가 떨어진다는 것이다.
그래서 오른쪽과 같이 바깥쪽의 sector를 늘려 바깥쪽의 density를 늘릴 수 있다. track이 바깥쪽으로 갈수록 sector의 수가 많아진다.
I/O latency
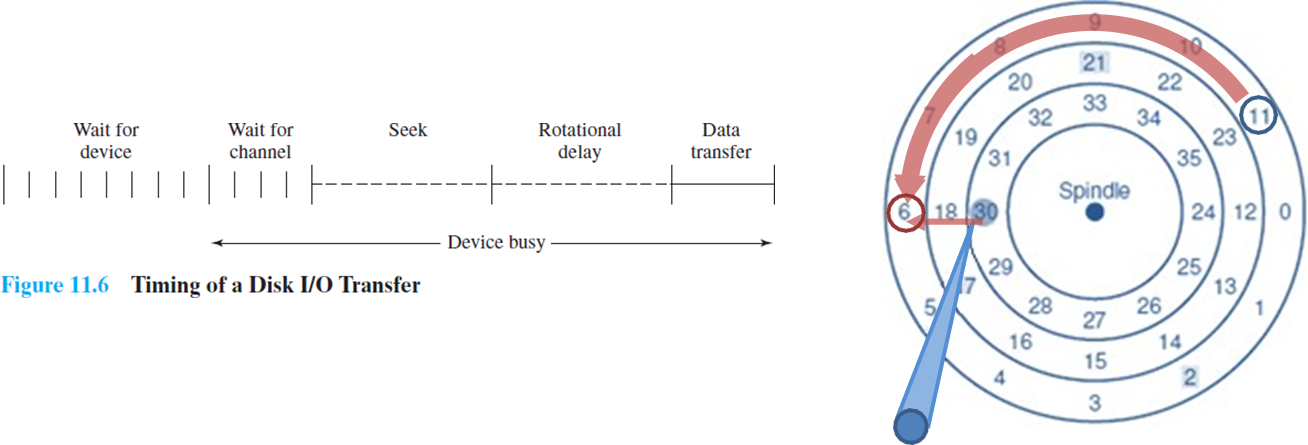
I/O latency는 다음과 같다.
- seek time: 드라이브는 disk arm을 track으로 옮겨야한다.
- rotational delay: track에서 원하는 sector로 가기 위해 platter가 회전하는 시간이다.
- transfer time: 데이터가 read되거나 wrtie되는 시간이다.
Disk Scheduling
disk scheduling 기법은 I/O 요청시 어떤 것부터 처리할지에 대한 전략이다.
이는 disk의 특정 track 읽기/쓰기 요청이 오면 queue에 저장해두고 커널이 어떤 것부터 처리할지 정한다.
FiFO
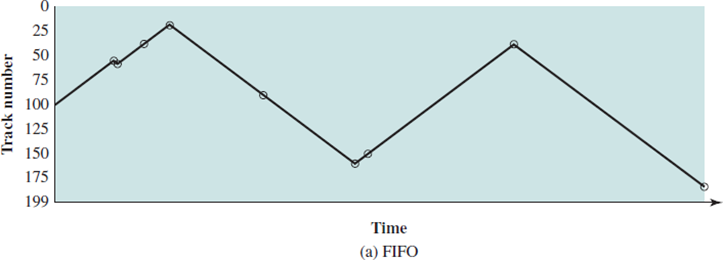
들어온 순서로 처리한다.
구현이 쉬우나 random access와 같이 동작한다. 디스크의 동작 자체를 아예 신경쓰지 않은 기법이다.
운좋게 요청이 온 track이 모여 있으면 성능이 좋겠지만 그럴리가 없다.
기아 현상이 없고 공평하게 처리된다.
SSTF
현재 처리된 track에서 가까운 track을 우선적으로 처리한다. seek time을 줄이기 위함이다.
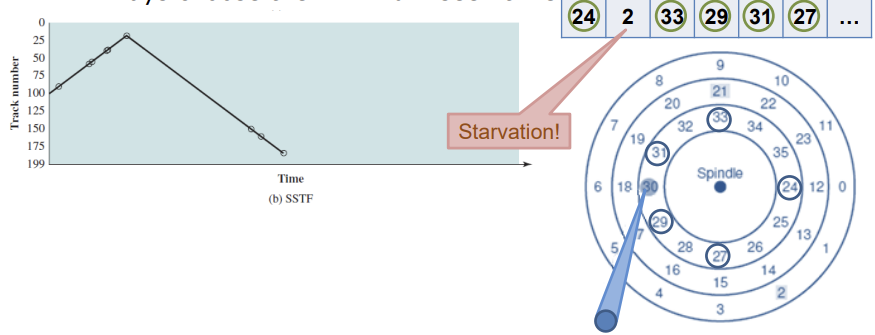
오른쪽은 요청된 sector의 시점으로 본 schedule이다.
이 부분은 기아 현상이 발생한다. 동적으로 가까운 track의 요청만 온다면 당연히 seek time이 긴 track엔 기아현상이 발생할 것이다.
SCAN(Elevator algorithm)
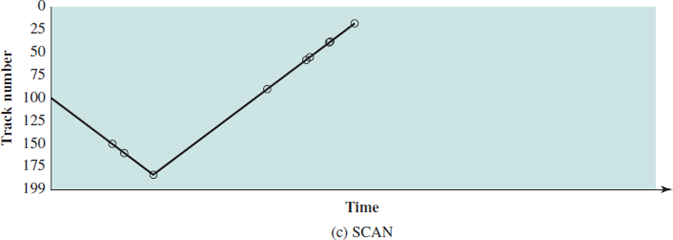
이 방법은 track을 처리하는 방향으로 쭉 움직인다.(마지막을 만날 때까지) 그리고 마지막을 만나면 방향을 바꿔 다시 움직인다. 한 번 쭉 훑은 곳을 다시 훑기 때문에 반대편엔 많은 요청이 쌓여있을 것이다. 그런데 동적인 상황에 track이 움직이면서 계속 같은 방향의 track에 요청이 온다면 반대편엔 엄청 많은 요청이 쌓이게 될 것이다.
C-SCAN(Circular SCAN)
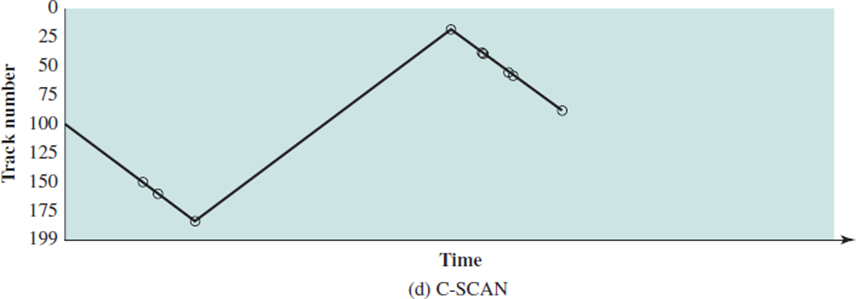
이 방법은 역방향으로 트는게 아니라 마지막 트랙을 만났을 때 아예 반대방향으로 움직인다.
하지만 여전히 한쪽에 요청이 쌓이는 것을 막을 수 없다. 언제? 일단 가는 방향의 track에 요청이 동적으로 계속 쌓일 때이다. 동일한 track에 요청이 쌓인다면 하나의 track에 대해 disk I/O 독점이 일어난다. 다른 방향의 track에 기아현상이 발생하는 것이다.
N-Step SCAN
그럼 환영으로 돌면서 골고루 처리해주며 독점을 막기 위한 방법이다. 특정 track에 대해 N개를 담는 queue를 통해 정해둔 N개를 처리하면 다음 track으로 움직인다.동일한 track에 들어온 추가적인 요청은 다른 queue에 담아두고 나중에 처리한다.
N이 너무 크다면 일반적인 SCAN과 동일하게 동작할 것이다.
