이제 page의 크기가 어떠한 영향을 끼치는지 알아보자.
페이지의 크키가 늘어나면 entry 수가 줄어든다. I/O 측면에서 page가 크면 locality가 있다면 효율이 증가한다. (I/O가 적게 발생하기 때문이다.)
TLB 측면에서 entry 수가 줄기 때문에 더 많은 메모리 공간을 커버할 수가 있다. entry의 크기가 동일하다 했을 때, page table의 entry가 줄기 때문이다.
그러나 조각이 커지니 내부 단편화가 커질 수 있다.(엄청 작은 메모리 요청에도 큰 조각이 할당된다.)
대규모 응용프로그램에 적합해 보인다.
TLB issue
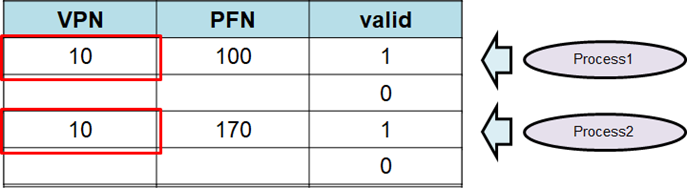
다음과 같이 page 번호가 같지만 프로세스가 다른 entry가 TLB에 들어있으면 어떻게 될까?
해결책
- process switch 시, valid bit을 모두 0으로 한다.
무조건 miss난다.- entry에 프로세스 pid를 저장한다. 하드웨어 complexity가 올라간다.
Page table size
32-bit 환경에서 페이지의 크기가 4KB일 경우 프로세스의 page table entry는 2^20개이다. 약 백만개의 entry가 존재하는 것이다. 각 entry가 4bytes를 차지한다고 했을 때, page table의 크기는 4MB가 된다. 1024개의 프로세스만 존재하면 4GB가 된다. 낭비가 씹오진다.
64bit는 말할 필요도 없다.
Combined paging and segmentation
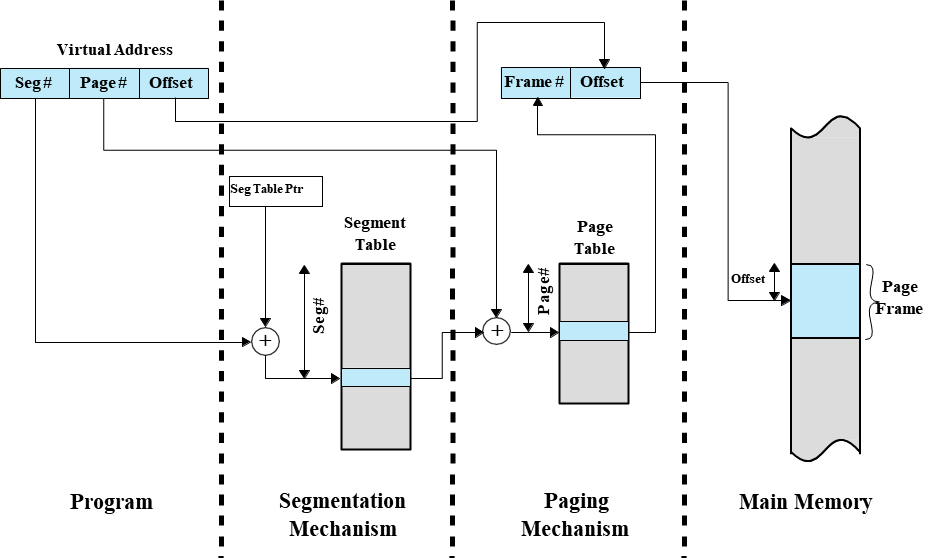
paging과 segmentation을 합치면 페이지 테이블 size를 줄일 수 있다.
모듈 단위로 segment를 쪼개면 이 segment를 page로 쪼갠다. 프로그램을 모듈단위의 가변길이인 segment를 나눈 뒤, 이 segment를 고정 길이의 page로 나눈다.
그럼 segment에 존재하는 page들만 table의 형태로 관리해줄 수 있는 것이다.
그럼 page를 기존의 segment로 관리한다면 2^32 중 2^12를 offset, 2^12를 page table의 개수, 2^8을 segment entry의 개수로 나눌 수 있다.
segment가 존재하지 않는다면 page 테이블도 존재하지 않는다. 그럼 이전과 같이 무조건적으로 4MB의 페이지 테이블을 가질 필요가 없는 것이다.
segment table은 다음과 같은 정보를 저장한다.
- Base: segment에 대한 page table 주소를 저장한다.
- Bound: page table의 entry 수를 저장한다.
- 그리고 다른 control bit이 포함될 수 있다. (protection bit 등)
장점으로 segment 단위의 sharing이 쉬워진다. paging으로 인한 외부 단편화가 존재하지 않는다.
하드웨어적 구현 복잡도가 높아진다. MMU의 도움이 필요하다.
하드웨어적 자원이 필요하다.
Hierarchical Paging
기존의 page table을 또 하나의 page table로 관리한다. 기존의 page table의 entry의 chunck들을 추가적인 page table의 entry로 관리하는 것이다.
장점은 page table들은 메모리에 연속적으로 저장될 필요가 없다.
사용되는 page들에 대한 entry chuck들만 메모리에 올려놓기 때문에 낭비되는 메모리 자원이 없다.
단점으로 메모리 접근이 두 번이나 필요하다.
이전에 4KB의 page table을 모두 메모리에 올렸었다면 여기선 4KB의 고정 테이블과 각각의 entry는 page가 정말로 할당된 page table entry chunck들의 시작 주소를 가리킨다.
만약 chunck의 invalid bit이 모두 0이라면 메모리에 할당하지 않는다는 것이다.
2-level, 4-level 모두 가능하다.
메모리 접근이 두 번 필요한데 이는 TLB의 caching으로 커버 가능하다.
Inverted Page Tables
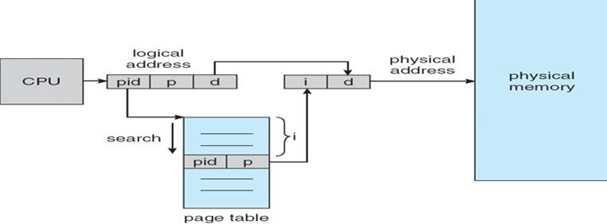
얘는 frame번호에 대해 매핑되어 있는 page 번호와 pid 정보를 가지는 테이블이다.
만약 frame의 순서로 관리하면 scan 시간이 선형시간이다. 그러나 hash table을 사용하면 좀 더 효율적으로 관리할 수 있을 것이다.
논리 주소는 <pid, p, d>로 관리하며 pid와 p의 정보와 맞는 frame 번호를 얻고 여기에 page 크기 값을 곱한 뒤, offset과 더해줘 물리 주소를 얻는다.
