이번 포스트에선 Linux Scheduling을 알아본다.
초기의 linux는 single-queue scheduling 방식이었다. processor와 process의 수가 증가함에 따라 확장성의 문제가 발생하고 이를 O(1) scheduling으로 해결하게 되었다.
현재는 CFS를 사용하며 핵심을 살펴본다.
O(1) Scheduler
O(1) 스케줄러를 살펴보자. CFS 이전까지의 스케줄링 방식이다.
리눅스 2.4까지는 single queue 방식이었다.
이는 queue가 존재하고 processor들이 있을 때, idle하다면 그냥 queue에서 process를 가져와 처리하면 되었다.
하지만 이는 affinity가 떨어져, 캐시 성능 저하가 발생하였다.
두 번째 문제로, race condition 문제로, locking이 발생한다. queue에서 processor가 process를 선택할 때, 다른 processor들은 queue에 접근하지 못했던 것이다.
이러한 이유로 O(1)에선 multiqueue 방식으로 발전하였다.
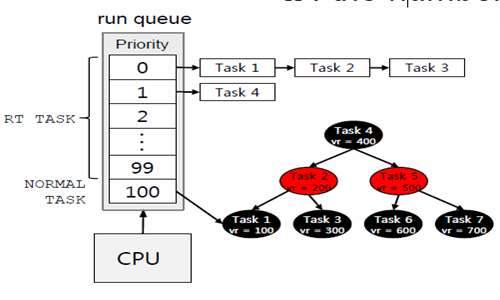
O(1)은 priority-based 스케줄러로 우선순위가 0에서 139까지 존재하며, 우선순위별로 queue를 유지한다.(숫자가 낮을수록 우선순위가 높다.)
스케줄러는 우선순위가 높은 큐에서 프로세스를 선택한다. 하나의 큐에서는 Round-Robin의 형식으로 동작한다.
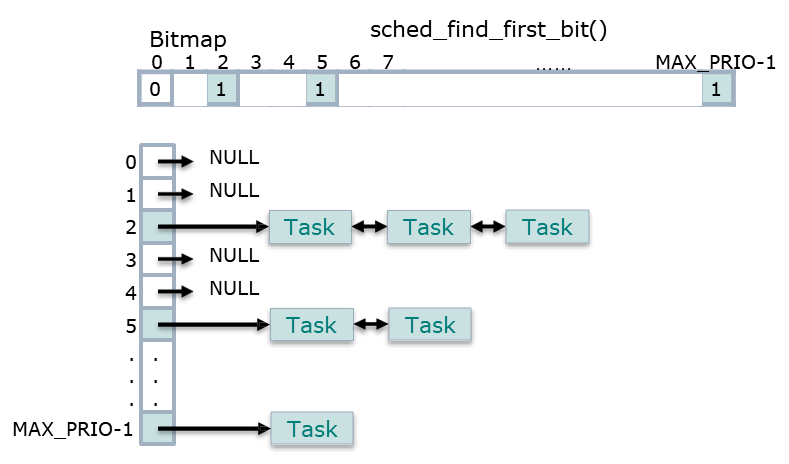
우선순위가 높은 process를 탐색해야하는데, 이것을 빠르게 하기 위해 Bitmap 자료구조를 사용한다. bitmap이란 우선순위에 해당하는 process의 유무를 140개의 bit으로 저장하는 테이블이다.(없으면 0, 존재하면 1이다.)
위의 이미지와 같이, 선형탐색으로 프로세스가 존재하는 가장 우선순위가 높은 queue를 선택할 수 있다.
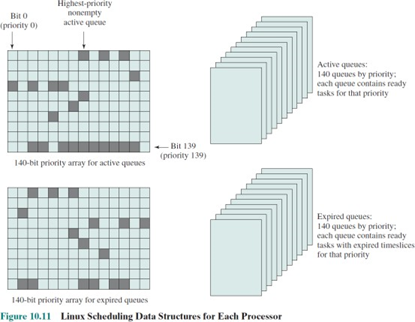
active/expried run queue
위에서 본 140개의 queue는 active queue이다. 그러나 이와 같은 하나의 집합이 또 존재한다.
active queue에 프로세스가 삽입될 때, CPU 시간 할당량을 부여받은 채 삽입된다.
그리고 프로세스 처리가 되어 시간 할당량을 모두 소진하면 expired queue로 들어간다.
그럼 시간이 지나면 active queue는 모두 expired queue로 옮겨질 것이다.
모두 옮겨졌을 때, active queue의 pointer를 expired queue로 swap한다.
이는 long process들의 starvation을 해소할 수 있다. 그리고 0~99까지의 real-time process들을 active queue에 유지할 수 있을 것이다.
추가로 process migration도 지원한다.
Why O(1)?
스케줄러의 이름이 O(1)인 이유는 프로세스의 수가 증가함으로써, 프로세스의 삽입, 삭제이 모두 상수시간이 소모되기 때문이다. 특정 프로세스를 찾는 것이 아니라, 특정 우선순위에 있는 프로세스를 찾는 것이기 때문이다. (최악의 상황에 우선순위 139까지 탐색하므로 140 즉, 상수시간이 소모된다.)
How it works
- 스케줄러는 active queue에 프로세스를 삽입한다.
- 프로세스들이 time slice를 소진할 때마다, expired queue로 이동한다.
- active queue가 empty가 되면, active queue와 expired queue의 포인터를 변경한다.
process swithc에 필요한 process를 찾는 즉, 140개의 큐 중 프로세스가 존재하는 큐를 찾는 연산은 최악의 경우에 140번이 걸리므로, O(1) 스케줄러이다.
Propotional Share Scheduling
원래 리눅스는 유닉스 조금 스케줄링을 수정하여 스케줄링 알고리즘을 사용하다. O(1) 스케줄링 알고즘을 채택하였었다. 이후에, 멀티 미디어가 증가하며, 1초에 30 frame 이상 보장 등, CPU의 사용시간을 보장했어야 했다.
O(1) 스케줄링은 CPU 사용시간을 보장하진 못했다. 우선순위가 높다고 CPU 사용시간이 보장되지 못했다는 것이다.
이를 위해 Propotioanl Shar Scheduling이 개발되었다.
이 스케줄링의 원리는 weight(가중치)가 process에 주어지고, 이에 비례하여 CPU 사용시간을 할당받을 수 있다.
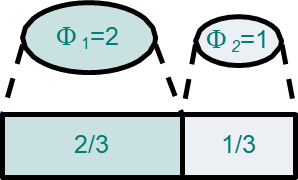
이는 bandwidth scheduling 또는 fair-share scheduling으로 불리운다.
이 스케줄링 알고리즘은 역사적으로 fair queueing이라는 이름으로 네트워크에 등장한다.(e.g. WFQ, WRR)
OS에선 이 스케줄링 기법을 이용한, Stride scheduling 그리고 linux의 CFS가 이 방식을 채택한 스케줄링 알고리즘이다.
Optimization Criteria
Propotional scheduling의 최적화를 위한 기준은 weight에 대해 얼마나 공정하게 CPU 사용시간을 보장할 수 있을지이다.
이는 정량적으로 계산할 수 있는 척도가 필요하다.
이를 Service Time Error를 계산하여 공정성을 보장한다.
오차는, 근사값에서 참값을 뺀다. i notation은 process의 식별 index이다.
위의 수식의 뜻은 p1과 p2의 weight의 비가 2:1일 때, 우항의 맨 마지막 부분은 로, 최적의 상황일 때(스케줄링을 잘 짜서), 할당받아야하는 CPU 사용시간이다.
이를 계산하면(t2, t1은 10, 0으로 가정, 10초간 수행) 만큼 할당받아야 한다는 것이다.
그리고 실제 알고리즘에서 할당받은 시간이 7.0초일 경우 의 값, 즉 할당받아야 하는 값과 실제로 할당받은 값의 차가 오차(0.4)가 되는 것이다. 모든 시간 구간에서 오차의 평균이 0이 되도록 하는 것이 목표이다.
추가로 스케줄링의 overhead가 작아야 한다. 수행시간이 작아야 한다는 것이다.
WFQ(Weighted Fair Queueing)
Propotional scheduling의 대표적인 알고리즘 주 하나인 WFQ를 알아보자.
이는 네트워크에서 사용되며 리눅스의 CFS에 많은 영향을 주었다. CFS를 더 잘 이해하기 위해 OS 스케줄링 알고리즘처럼 각색하여 알아보자.
- virtual time: virtual time이란, 어떤 process i의 t시간 까지의 누적 수행시간이다.(이를 정규화 한 것이다. 는 자신의 weight이다.)
A:B:C:D = 4:3:2:1 일 경우 A와 D는 4:1이다. 같은 1초에 대한 CPU 사용시간이 주어진다 해도, A는 1/4초가 되고 D는 1초가 될 것이다.
그리고 정규화된 누적 실행시간이 가장 작은 값이 우선적으로 스케줄링에서 선택한다.
- virtual finish time: virtual finish time이란 가상 시간에다가 단위 시간만큼 CPU 수행했을 때의 누적시간이다.
0초에서의 VT는 모두 0이고 A의 VFT는 1/4초일 것이다. B는 1/3일 것이다.
실제로는 VT를 구하고 VFT를 구하여, 이 값이 제일 작은 프로세스를 선택하게 될 것이다.
이후에는 VFT가 비만큼 증가한다. 이를 계속하며, 가장 작은 값을 scheduler가 선택하여 process를 처리한다.

만약 weight에 따라 Round-Robin을 수행하면 어떻게 될까? process마다 weight에 비례하는 time-slice를 주는 것이다. 이는 WRR 방식으로, 이는 Service Error Time에서 음수값이 나오는 것을 확인할 수 있다. 이 에러값이 최소가 되어야 좋은 알고리즘인데, 위의 에러 값의 하하는 -0.9인데, WRR 방식으론 -1.2가 나오는 것을 확인할 수 있다.
Completely Fair Scheduler(CFS)
2.6.23 버전 이후에 적용된 스케줄리 알고리즘이다. 이도 WFQ와 같이 정규화된 누적 실행시간이 가장 작은 프로세스를 선택하는 알고리즘이다. 리눅스에선 virtual runtime field라 불리며 이의 가장 작은 값을 가진 프로세스가 선택된다.
n개의 프로세스가 존재하면 O(n)로 프로세스를 선택할 수도 있다.
그리고 BST를 사용하여 O(lgN)으로 처리할 수도 있다. 리눅스는 Red Black Tree를 사용한다.
여기서 가장 왼쪽의 leaf node를 선택하면 된다.
Heap을 선택하지 않은 이유는 leaf node의 task가 sorting된 결과를 보기위해 Red Black Tree를 이용한다.
O(1)과 마찬가지로 멀티 프로세스를 위해, Multiple queue를 지원한다. ?