프로세스와 쓰레드의 차이와 멀티 프로세싱과 싱글 프로세싱 환경에서의 쓰레드의 장점과 단점을 알아보자.
프로세스는 프로그램의 instance를 의미한다. 이를 좀 더 자세하게 개념화한다면, instruction sequence의 실행 단위로 바라보았다.
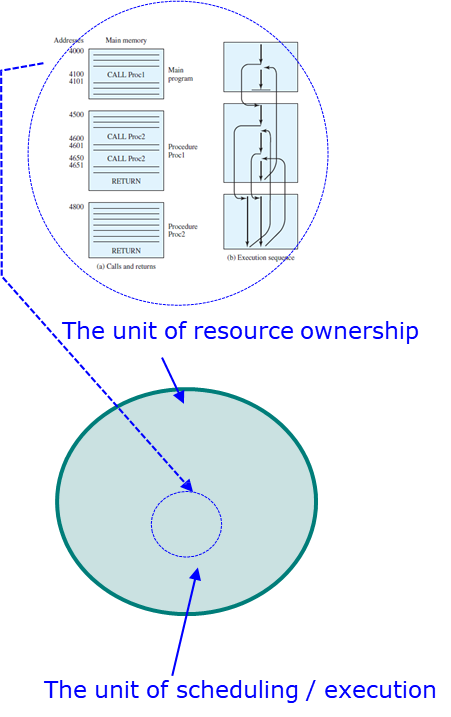
이는 두 가지의 단위로 나누어지는데, 자원 소유권의 단위와 실행(scheduling)의 단위이다.
정리하여 instruction sequence의 실행 유닛인 프로세스는 자원을 사용하고, OS에게 스케줄링 대상이 되는 단위로 세분화된다는 것이다.
지금까지 process를 하나의 execution sequence를 가진 것으로 가정하고 스케줄리 기법들을 알아
보았었다.
하지만 execution sequence는 프로세스마다 여러개가 존재할 수 있으며, 이것을 Thread라 부른다.
Multithreading
대부분의 소프트웨어는 멀티쓰레딩을 사용하여 구현되어 있다.
이 Multithreading이란 하나의 프로세스가 여러개의 실행흐름을 가지는 방식을 말하며 이는 concurrency(동시성)을 가진다.
이는 multiprocessing과 엄연히 다르며, Thread 생성은 Call stack(user/kernel)을 제외하고 모든 자원을 공유한다.
Concurrency
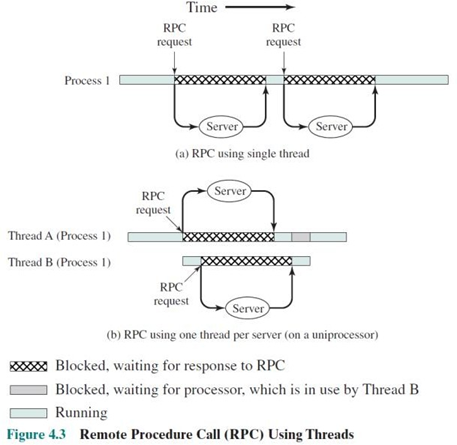
동시성은 이전에 multiprocessing으로 충족했었다, 그러나 이는 많은 overhead를 가지고 있으며 메모리 공간도 많이 차지한다. 자원을 공유하는 Thread를 사용하여, 더 빠르고 경제적으로 동시성을 보장할 수 있다.
process들을 동시에 수행하기 위해서 scheduling 알고리즘이 필요했다. 이는 이전에 보았듯이, single core 환경에선 process간의 interleaving으로 동시에 진행되는 것 같은 illusion을 제공했다.(멀티 코어 환경에선 병렬(parallelism)적으로 프로세스 처리가 가능하다.)

Concurrency는 parallelism과 다르다, Concurrency는 parallelism이 충족이 안되도 보장할 수 있다.
Thread로 이를 보장할 수 있다는 것이다.
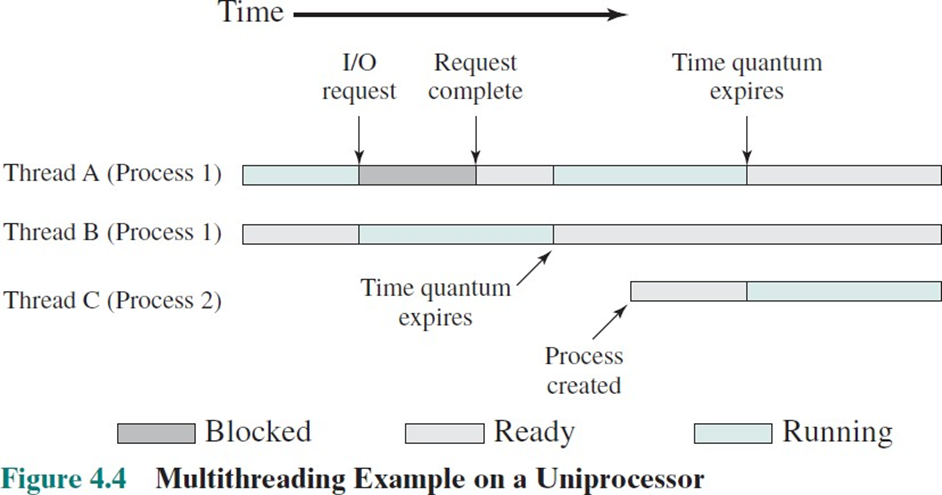
위와 같이 sigle core 환경에서 Thread의 동시성을 확인할 수 있다.
Motivation
멀티 쓰레드가 필요한 이유가 뭐였을까? 만약 웹 서버에서 다수의 client를 처리해야하는 상황에 놓여있다 했을 때, 이를 fork() syscall을 사용하여 multiprocess로 처리했었다.
프로세스를 계속해서 생성한다면 모든 자원을 복사해야하기 때문에 cost가 굉장히 커진다.
그렇다면, multithread 방법을 사용하여, execution sequence를 concurrent하게 처리하여, 클라이언트의 네트워크 연결 요청과 데이터 송수신을 multiprocessing 보다 훨씬 적은 비용으로 처리할 수 있게 된 것이다.
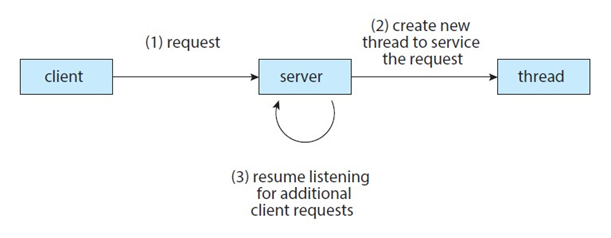
프로세스에서 클라이언트의 네트워크 연결 요청을 받고 쓰레드를 생성하여 데이터 송수신을 처리하는 모습이다.
쓰레드는 core의 할당도 지정할 수 있다.
e.g. 몇번 processor에서 수행
MultiThreading's Benefits
- Responsiveness: 응답시간이 좋아진다. 하나의 thread가 block 되어도, 다른 thread가 수행된다. e.g. I/O와 사칙연산이 overlap될 수 있다.
single thread는 sequential하게 쓰레드를 수행하고, multi thread는 병렬적으로 기다릴 수 있다.- Economy of time: multiprocessing은 fork()마다 계속해서 프로세스 정보를 복사, 수정해야한다.
그러나 Thread 같은 경우엔 실행 단위이기 때문에, 자원을 공유한다.(Thread Control Block과 추가적 Call stack만 필요하다.) process switch보다 thread switch가 더 효율적이다.
이렇게 concurrency를 위한 overhead가 작다.- Resource Sharing
process는 자원을 공유(e.g. shared memory)하기 위해서 커널로 모드 스위치가 필요하다. 쓰레드는 user-level에서 공유할 수 있다.- Parallel Processing: 멀티코어 architecture에서, 멀티 쓰레드를 모두 할당하여 쓰레드 수만큼 성능이 좋아진다.(Parallelism)
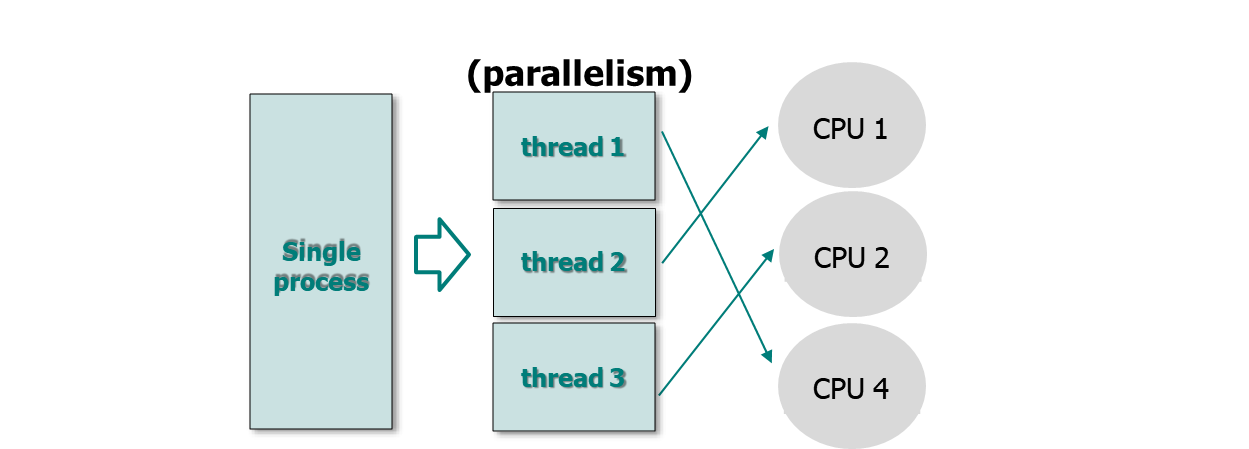
Multithreading on Multicore
속도가 얼마나 상향됐는지를 확인하기 위해, single processor의 속도를 multi processor의 속도로 나누어줘야 한다.

암달의 법칙에 의해 다음과 같은 수식을 얻는다.
S는 Serial processing이 요구되는 코드 블락의 portion이다. 나머진 쓰레드를 통해 병렬적으로 처리가 가능하다.
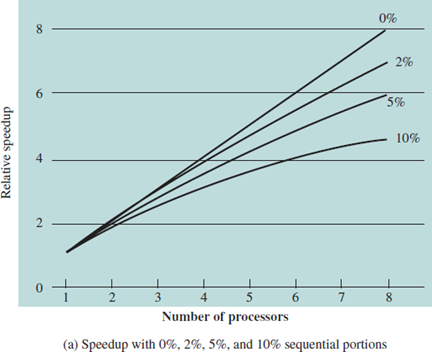 S가 10%만 되어도 속도 향상이 더디다.
S가 10%만 되어도 속도 향상이 더디다.
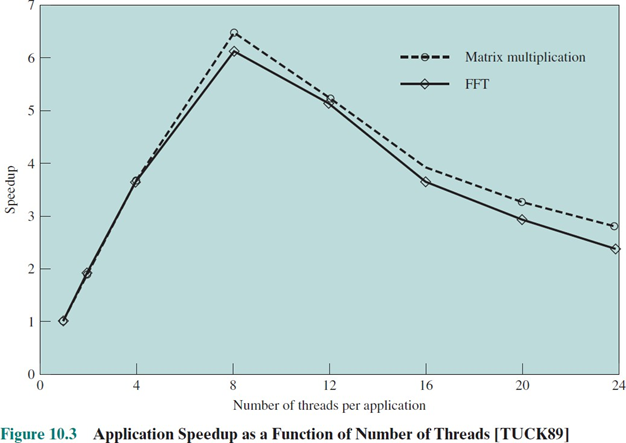
core의 수가 16개일 경우, 두 개의 application을 수행할 때, 각각 task에 몇 개의 쓰레드 수가 최적일까?
당연히 8개일 것이다. core 수만큼의 thread를 만드는 것이 당연히 최적일 것이다.
하지만 그 이후엔, Thread switch에 대한 overhead(rescheduling)가 굉장히 클 것이다. concurrency를 위해 선점도 많이 해야할 것이며, cache 성능도 떨어질 것이다.
프로그래머들은 이러한 사항을 고려해야하만 한다. Thread에 평등한 task를 부여해야하며, 독립적인 task를 구별해야한다. 마지막으로 race condition 문제도 고려해야한다.
Multithreaded Process Model
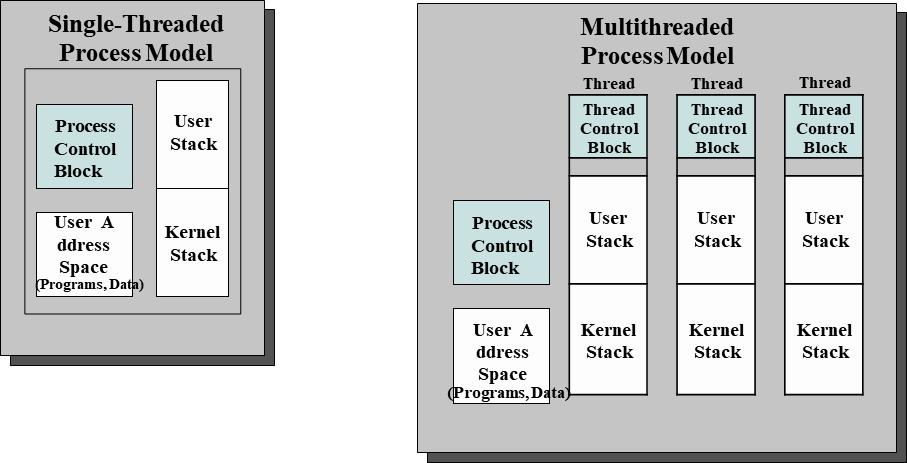
TCB는 쓰레드 식별자, 상태정보, 프로세서 state info 등 필요하다. 나머지는 공유한다.
Thread 생성은 간단하게, stack고 TCB만 생성하면 된다.
Process는 PCB 및 메모리 공간 할당, stack, data, code 등 부모의 것을 모두 복사한다.
User-level Thread
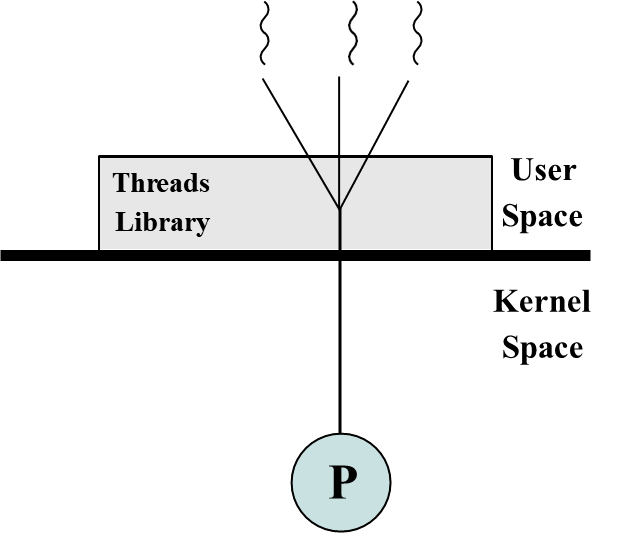
유저 레벨 Thread는 커널은 모른채, user-level에서 library 형태로 생성되는 쓰레드를 의미한다.
커너의 입장에선 하나의 프로세스와 하나의 쓰레드만 존재하는 것으로 보인다.
커널로 갈 필요가 없으니, Thread switch가 굉장히 빠르다.
library 형태이니, 어느 OS에서 사용가능하고 customizing하기 편리하다.
단점으로, 쓰레드의 모든 장점을 이용할 수 없다.
커널로 가지 못하니, 멀티 코어에 할당할 수 없다.
그리고 하나의 thread에 block이 발생하면, 모든 프로세스가 block되기에, system call을 unblock으로 변경해야한다.
Kernel-level Thread
KLT에선, 모든 쓰레드 관련된 task는 커널모드에서 수행된다.
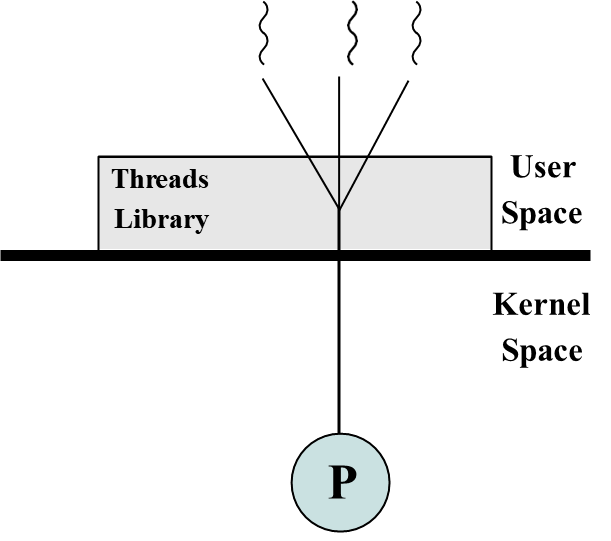
user-level에서 쓰레드 관리 코드는 없을 것이며, user-level의 단점이 모두 사라질 것이다.
병렬성이 보장되며, 하나의 쓰레드가 block된다고 하나의 프로세스가 block되지 않는다.

그러나 user-level과 비교하여 굉장히 느리다. 하지만 여전히 process보단 훨씬 빠르다.
동시성을 보장하기 위해, 모드 스위치 오버헤드가 너무 크다.
Combined ULT/KLT
둘을 모두 제공하는 방식이다. ULT는 KLT에 어느정도 매핑되어 있다. ![]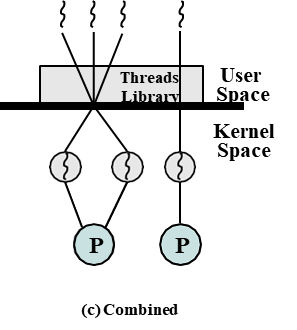
위와 같이 어느정도 매핑되어 있어, 멀티코어에 할당, 병렬수행 모두 가능할 것이다.
