개발자가 구현한 프로그램의 실행 순서는 소스코드의 순서로 수행될 것 같지만 사실은 그렇지 않다.
성능을 위한 pipeline을 사용하고 hazard를 막기 위해 reordering, branch prediction 등이 발생한다.
만약 멀티 쓰레드, 멀티 프로세스 프로그래밍을 하지 않는다면 이 최적화를 하드웨어와 소프트웨어가 알아서 해준다. 그러나 멀티 쓰레드/프로세스 프로그래밍 한다면 메모리를 고려해야한다.
Memory model
메모리의 연산, 연산 순서 등은 디바이스마다 다르다. 이를 Memory Consistency Model(메모리 일관성 모델)이라 칭한다.
- Sequential consistency: 각각의 코어에서 reordering이 발생하지 않는다.
소스코드와 실행순서가 동일하다고 생각한다. 이 방법은 보수적인 메모리 모델로 reordering이 발생하지 않으며 최적화할 수 없다.- Relaxed(or weaker) consistency: 완화된 메모리 모델이며 reordering이 발생할 수 있다. 이를 위해 프로그래머는 fence instruction, 즉 병렬 프로그래밍에서 메모리 연산을 동기적으로 수행하게 할 수 있는 instruction을 말한다. 멀티 쓰레드 방법에서 공유하는 메모리를 접근할 때, reordering이 발생하면 프로그래머가 의도한대로 실행되지 않고 race condition이 발생할 수 있다. 이러한 이유로 메모리 접근에 fence를 쳐 동기적으로 메모리 연산을 할 수 있다.
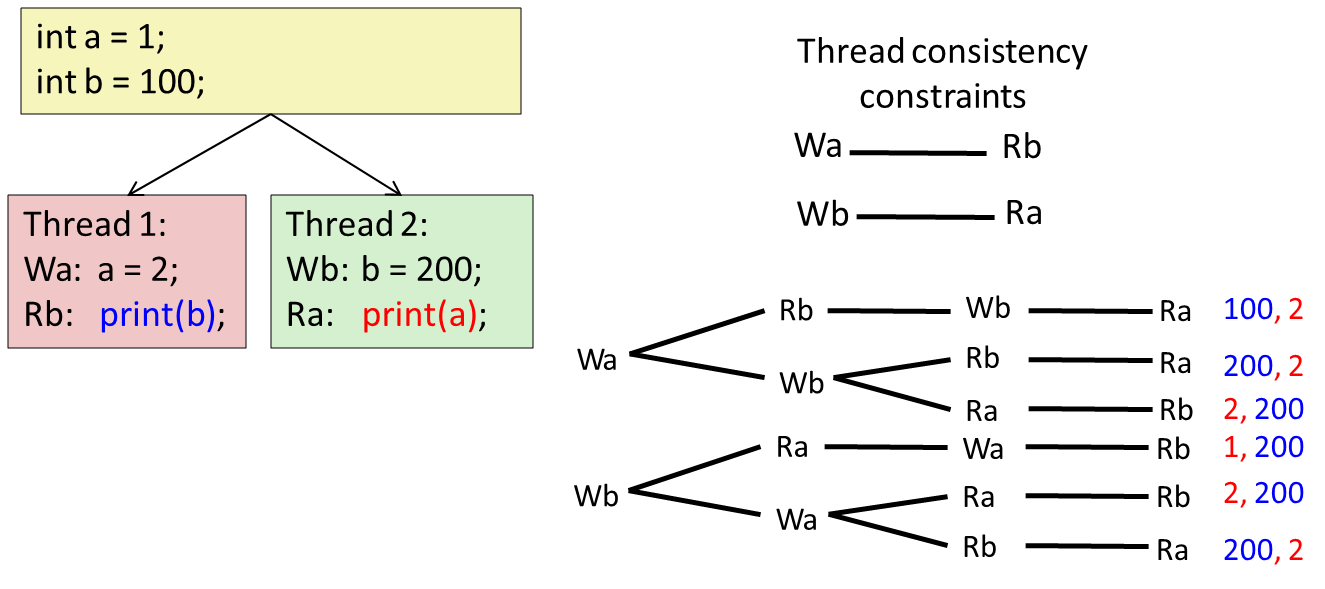
Sequential Consistency의 한 예시이다. 두 개의 쓰레드가 병렬적으로 왼쪽의 코드를 수행했을 때의 결과값이다. (100, 1), (1, 100)의 출력은 불가능하다.

왼쪽의 쓰레드는 reorder가 가능하다.(피터슨 알고리즘이다.)
피터슨 알고리즘이 현대의 아키텍쳐에서 동작하지 않는 이유는 위와 같이 reorder가 발새할 수 있기 때문이다. 왼쪽 쓰레드의 프로그램이 reorder된다면 x가 0이 출력될 수 있다.
Memory Barrier
병렬 프로그래밍을 수행할 때, 가끔가다 read, write 연산에 reorder가 발생하지 않고 특정 순서로 수행되어야 할 때가 있다. 이를 위해 barrier를 친다. 이 barrier가 소스코드에서의 sequence를 reorder할 수 없게 한다.
이전에 이야기한 fence instruction과 동일하다.
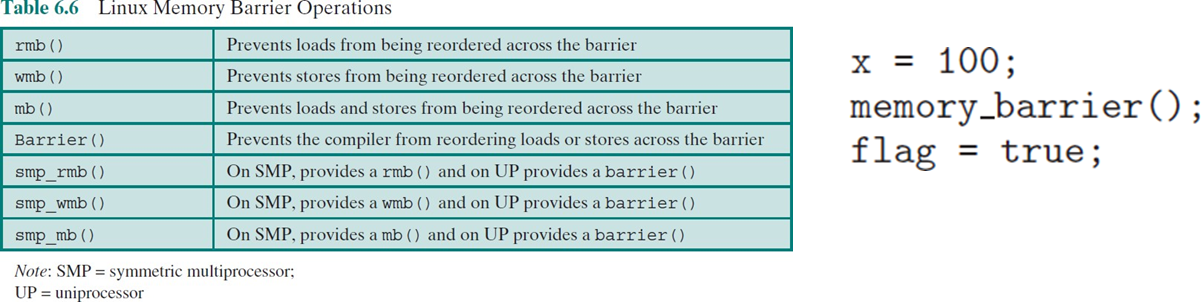
오른쪽 코드를 확인하면 barrier를 통해 x와 flag에 write하는 코드는 reordering이 발생하지 않는다.
Memory Management
메모리는 커널 영역, 유저 영역 두 가지로 분리된다. 또한 프로세스가 생성될 때마다 OS는 유저 영역을 동적으로 나누어 프로세스에게 할당해준다. 이를 memory management라 칭한다.
이는 멀티 프로그래밍에서 중요한 기능 중 하나이다.
고려해줘야 할 것은 다음과 같다.
- Relocation
- Protection
- Sharing
- Logical organization
- Physical organization
Relocation
프로세스를 메모리에 로드할 때, 어느 영역에 올라갈지 미리 알 수 없다. 게다가 메모리에 이미 존재해서 위치를 안다고 해도 디스크로 다시 swap-out 될 수 있다.
location은 계속 바뀔 수 있는데, 이에 대해 메모리 관리를 해야한다.
게다가 메모리에 존재할 때, 다른 프로레스에게 방해받으면 안 된다. 메모리 자원을 보호해야한다.
Protection
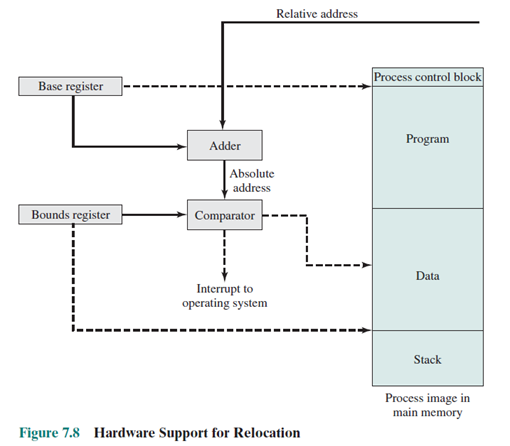
그런데 protection을 어떻게 해야할까? runtime에 주소변환을 수행하기 때문에 동적으로 protection을 수행하면 된다.
base register의 값과 상대주소를 더해 절대주소로 찾아간다. bound register의 값과 비교해 이를 넘어가면 예외를 발생시킨다.
Sharing
다양한 프로그램이 메모리를 사용할 때, 동일한 라이브러리를 사용한다면 이를 모두 로드할 필요는 없다. 그러므로 다양한 프로세스가 사용하는 데이터나 커널은 모두 메모리에 하나만 두고 공유한다.
Logical Organization
논리적 구조란 모듈레벨로 구조화하는 것을 의미한다.
이는 메모리에 각각의 모듈에 보호와 공유를 지원해야한다. 이는 프로세스레벨로 보는 것이 아니다. 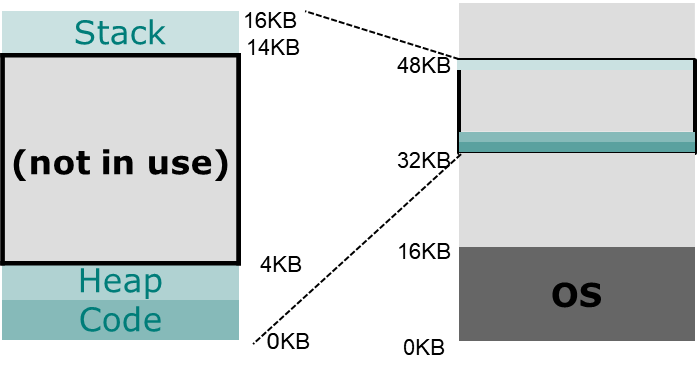
stack, heap 등을 모듈화 하여 보호, 공유를 달리한다.
예를 들어 code 영역은 읽기전용 protection을 적용한다. 이게 훨씬 더 효과적이다.
paging, segmentation이 이러한 요구 사항을 반영한다. 그러므로 보호, 공유가 용이하다.
Physical Organization
물리적 구조는 메모리의 계층구조, 용량, 접근 속도, 비용 등을 유저에겐 해당되지 않는다. 커널이 관리하는 요소들이다.
캐시 RAM 접근은 시스템이 처리할 일이다.
Types of Addresses
- Symbolic address: 소스코드 레벨의 변수, 함수의 주소이다. (컴파일 이후 상대주소이다.)
- Logical address: 프로그램 안의 상대 주소이다. symbolic address가 컴파일 된 후 상대주소로 변경된다. 이는 프로세스 안의 상대주소이다. 상대주소는 0에서 시작한다.
- Physical address: 실제 메인 메모리의 주소이다. loader가 프로그램이 메모리에 올라갈 때, 물리적 주소를 생성한다.
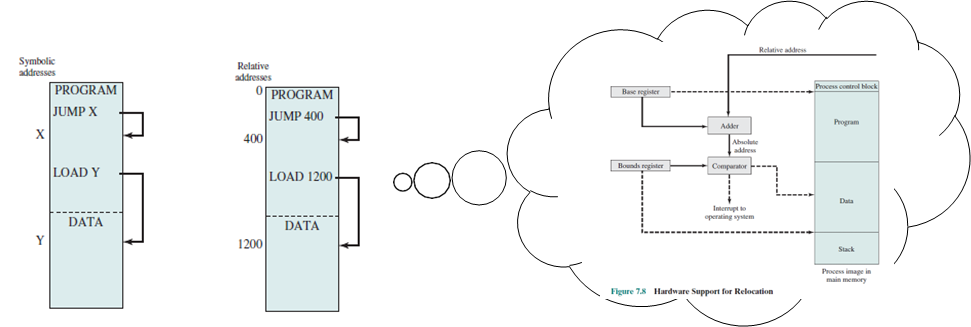
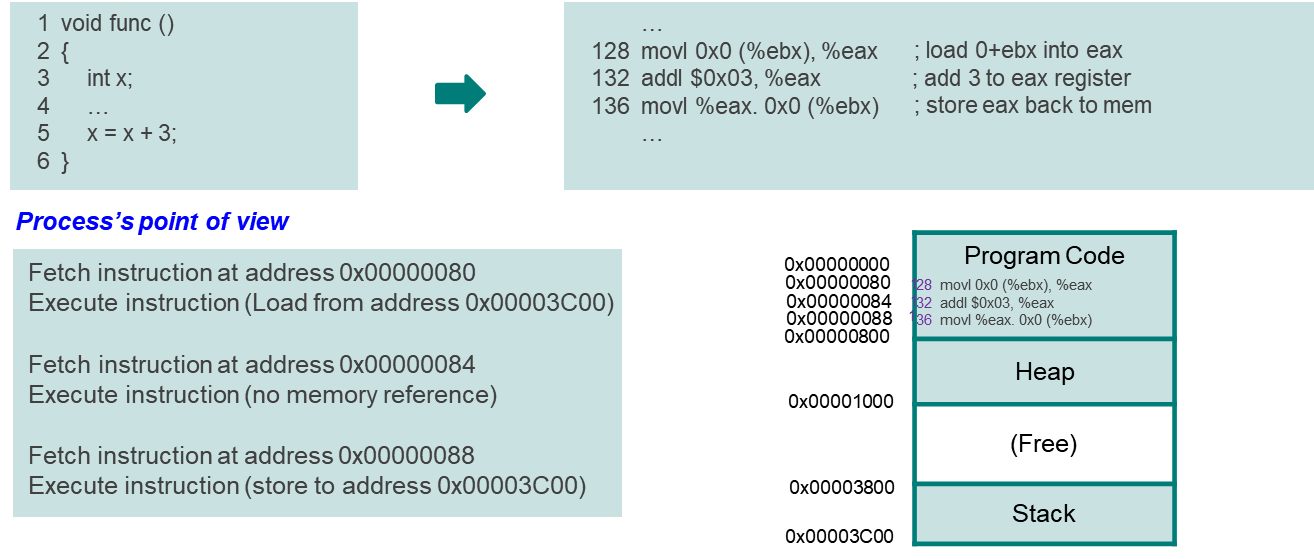
프로세스에서의 상대주소를 통해 instruction을 fetch한다. 데이터를 가져올 때도 stack의 상대 주소를 사용한다.
실제론 MMU를 사용해 동적으로 물리주소를 계산하여 가져온다.
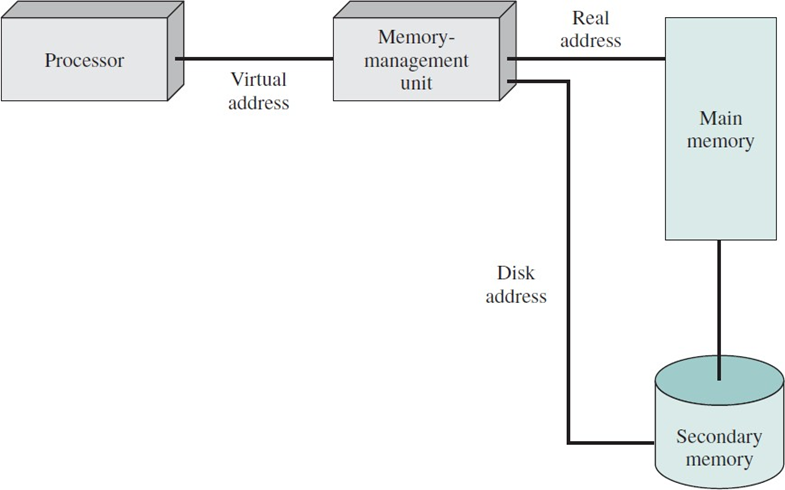
디스크도 접근 가능하다.
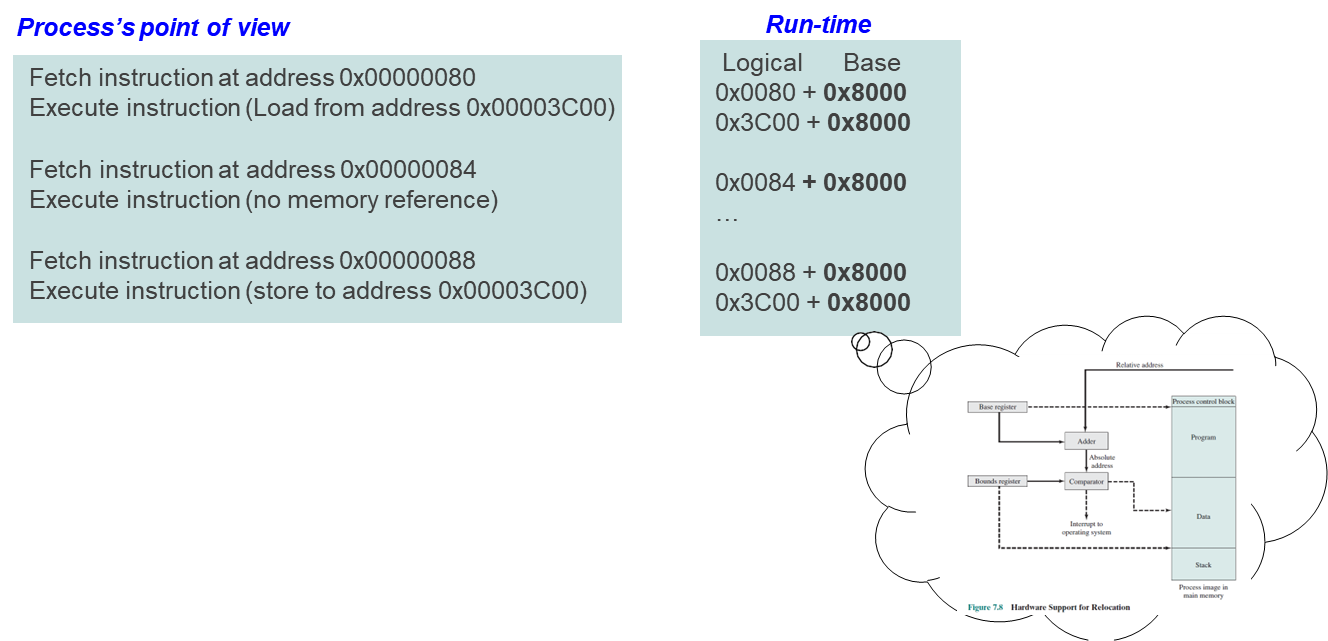
위와 같이 동적으로 base resigster와 더해 물리 주소를 구하여 instruction을 가져온다.
Memory Allocation
메모리 할당을 위한 다섯 가지 방법을 알아본다.
- Fixed partitioning: 고정분할, equal size, unequal size 두 가지 방식이 있다.
- Dynamic partitioning: 동적할당
- Buddy System
- Paging
- Segmentation
Fixed Partitioning
고정분할 방식을 알아보자.
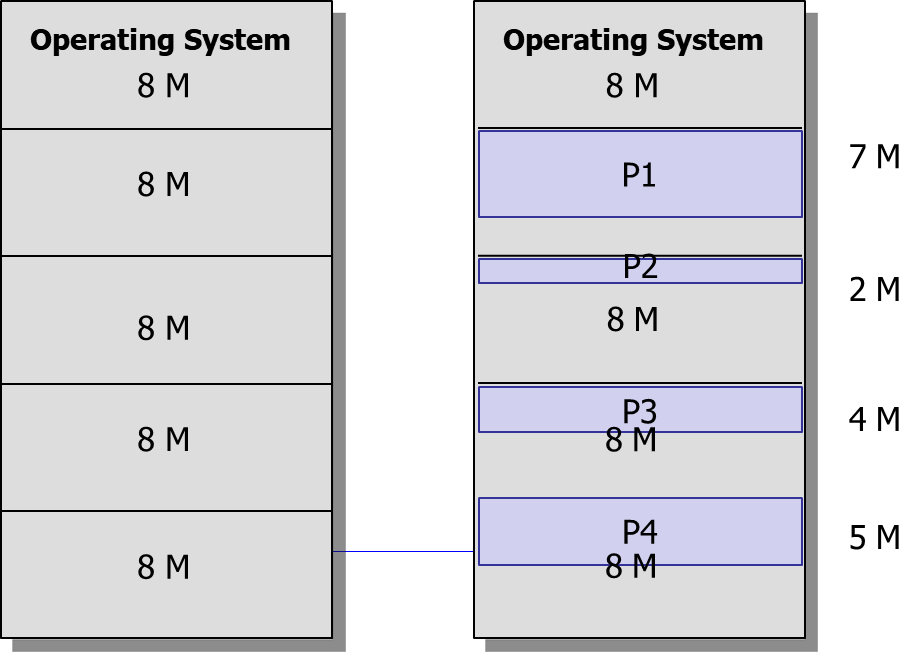
고정된 사이즈로 bounary를 치고 프로세스를 할당한다면 멀티 프로그래밍 제약, 프로세스 사이즈 크기가 제약된다.
이는 또한 할당된 프로세스의 크기가 무조건 8M일 수 없기 때문에 내부에 낭비되는 공간이 발생한다 이를 내부 단편화라 칭한다.
또한 크긷 제한되기 때문에 프로그램을 조각을 내서 메모리에 할당되는 overlay 방법도 사용됐었다.
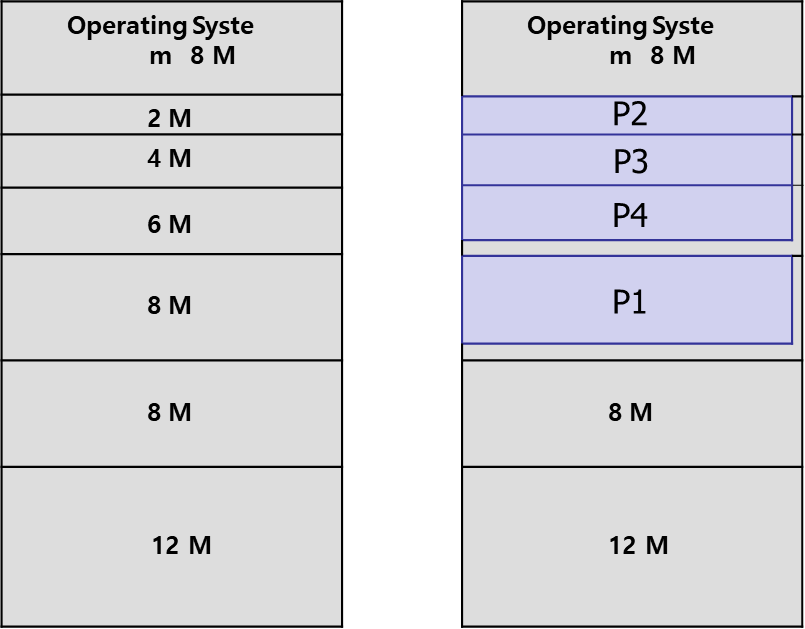
다음과 같이 비균등하게 boundary를 치는 방법도 존재한다. 그러나 이도 많은 제약이 존재하는데, 8M 사이즈의 프로세스가 세 개로 제약된다. 임베디드 시스템은 프로세스가 정해져있기 때문에 채택할 수 있는 방법이다.

구현 방식은 다음과 같이 모든 공간에 대해 queue를 두어 처리할 수 있다. 딱 맞는 공간의 queue에서 할당될 때까지 기다린다. 내부 단편화를 최소화할 수 있다.
다음으로 하나의 queue만 두는 것이다.
이는 유연하게 동작하며 빠르게 처리할 수 있다.
고정분할 방식은 단순하게 구현될 수 있고 OS의 개입이 적다. 그러나 메모리 활용률이 떨어지고 내부 단편화가 큰 문제이며 멀티 프로세싱과 프로세스의 크기가 제약된다.
그러므로 옛날에는 컴퓨터 성능으로 메모리에 할당될 수 있는 프로세스의 수도 고려했었다.
Dynamic partitioning
동적분할 방식은 runtime에 메모리가 분할되어 프로세스에게 할당된다. 가변길이의 partition을가지는 것이다.
이 방법은 프로세스가 요구한 만큼의 메모리 공간을 할당받는다.
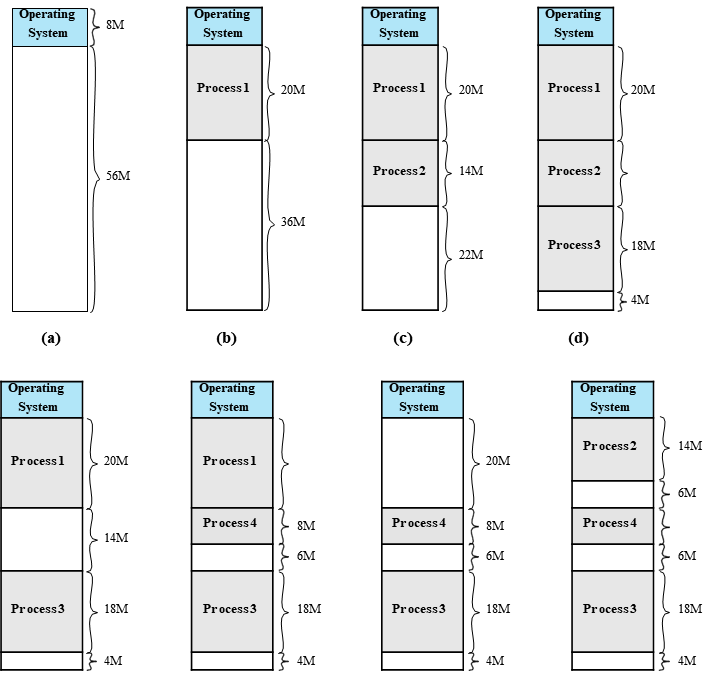
이 방법은 프로세스가 swap-out, swap-in 될 때마다 free memory 공간이 생기는데 이 공간은 프로세스크기에 따라 낭비될 수 있다. 아예 할당이 안될수도 있다는 것이다. 이를 외부 단편화라 한다. free space를 한 block에 몰아 메모리 활용률을 증가하기 위해 CPU를 사용해 shift 작업이 필요하다.
동적 할당을 위한 세 가지 전략이 존재한다.
- First-fit: 메모리를 처음부터 scan하여 할당할 수 있는 block을 선택한다.
- Next-fit: 제일 최근에 할당한 block부터 scan하여 할당할 수 있는 block을 선택한다.
- Best-fit: 요청받은 크기와 차이가 제일 작은 block을 할당한다.
모든 block을 탐색해야하기 때문에 이름과 다르게 성능이 안 좋다. 오히려 Best-fit으로 인해 외부 단편화가 발생하여 memory compaction의 주기를 짧게 만들 수 있다.
오히려 worst-fit 전략을 사용하는 것이 좋다. block 크기 차이가 가장 큰 block을 할당한다. 그럼 남은 할당도 재사용이 용이할 것이다.
요약하여, 내부 단편화는 발생하지 않지만 외부 단편화가 발생한다. 메모리 사용이 효율적이지만 CPU를 통해 shift를 지속적으로 수행해야한다.
Buddy System
buddy system은 2의 지수승으로 block이 할당된다. 가장 가까운 2의 지수승 크기의 block을 할당하는 것이다.
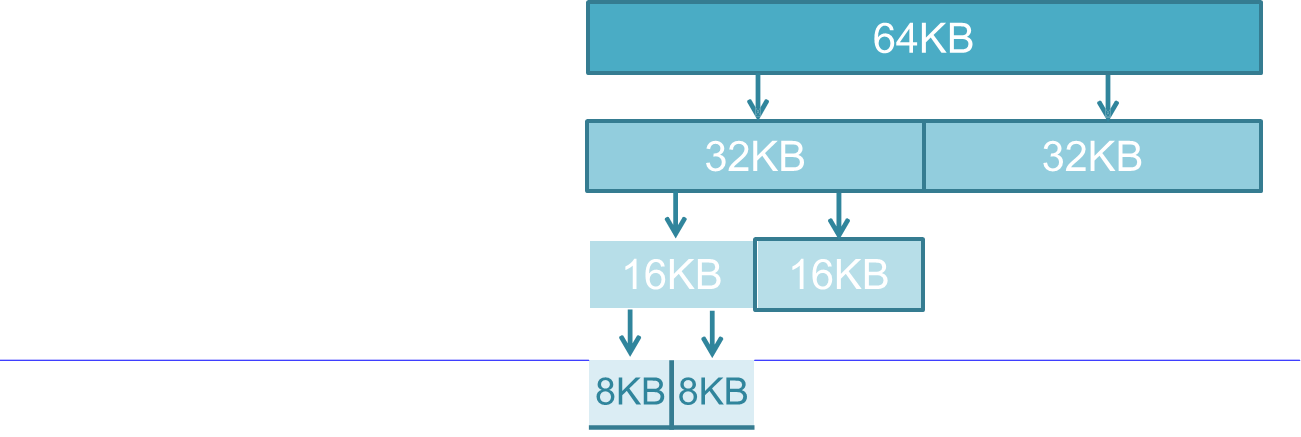
다음과 같이 동적으로 분할하여 할당하고 free list가 존재하면 합병한다.
dynamic fixed partition, 즉 하이브리드이다.
compaction이 자동으로 된다.
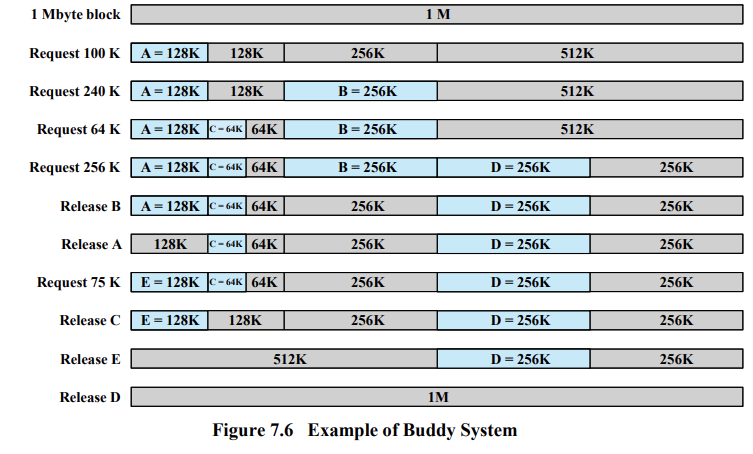
계속해서 분할되며 할당되고 free되면 합병된다.
Paging
paing은 분산적재 기법 중 하나이며 프로세스를 고정된 크기로 분할하고, 메모리도 고정된 크기로 관리하며 프로세스를 적재한다.
page는 process의 덩어리 단위이다. 이 page와 같은 크기로 분할된 메모리의 한 덩어리를 frame이라 칭한다.
그럼 프로세스가 조각나 메모리에 적재되기 때문에 어느 위치에 있는지 알아야한다 이를 위한 자료구조를 Page table 또는 Page mapping table이라 칭한다.(하드웨어인지 모르겠다.)
이는 frame 번호가 page 번호에 매핑되어 있다.
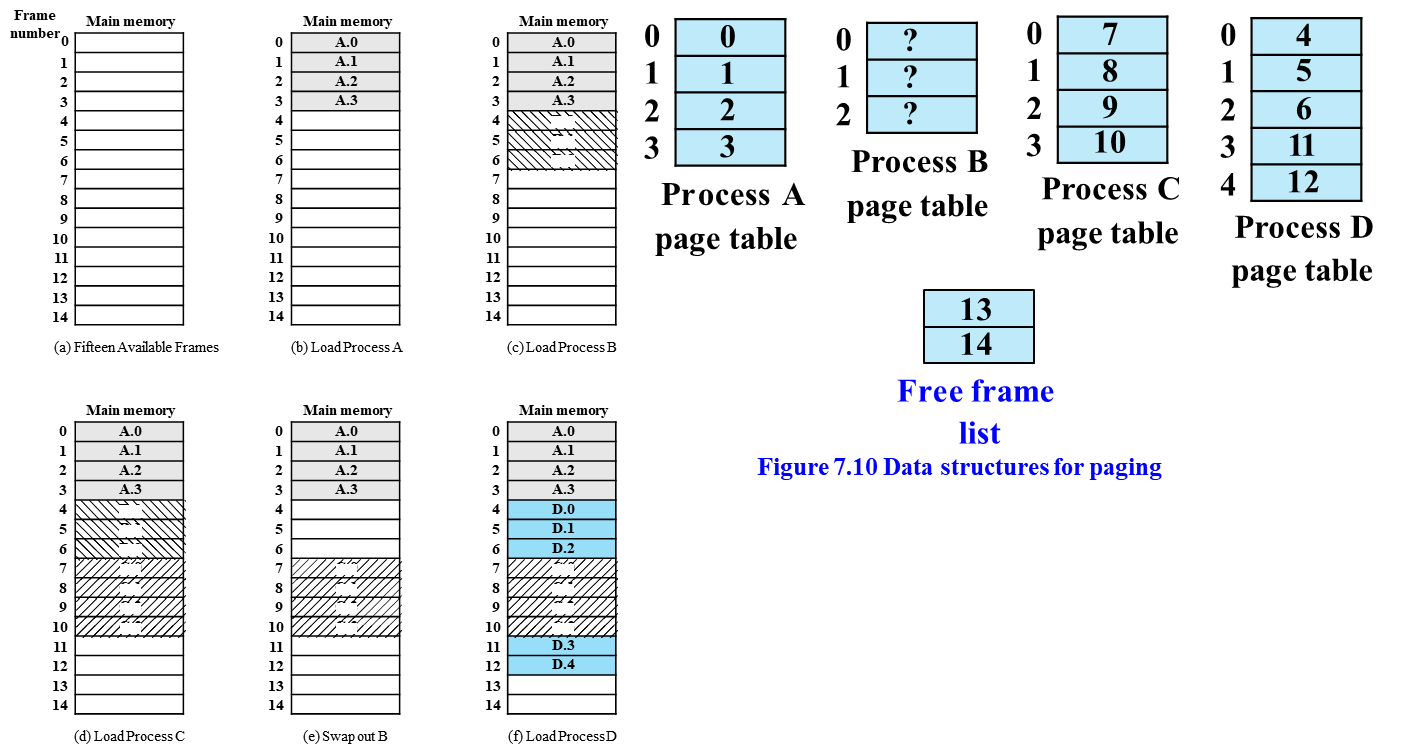
위와 같이 프로세스의 조각이 존재하는 frame 번호가 page 번호에 매핑되어 있다.
남은 free space는 list로 관리한다.
Address Transition
이전에 본 base register로 주소를 알 수가 없다. page가 저장된 물리주소는 분산되어 있을 것이기 때문이다.
그러므로 이전에 못본 방법이 필요하다.
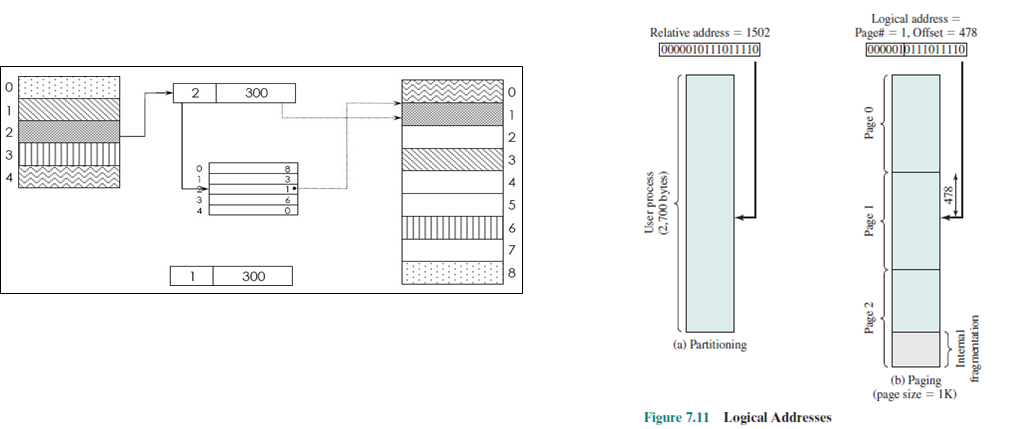
16bit 주소체계에서 하나의 page가 1KB라면 이를 위한 10bit가 필요하다. offset으로 사용된다.
거기에 나머지 6bit로 페이지의 번호를 관리할 수 있다. 총 64개의 page를 생성할 수 있다.
이렇게 수행하면 논리주소와 상대주소가 동일해진다. 2의 배수로해야 하드웨어 구현이 편해진다.
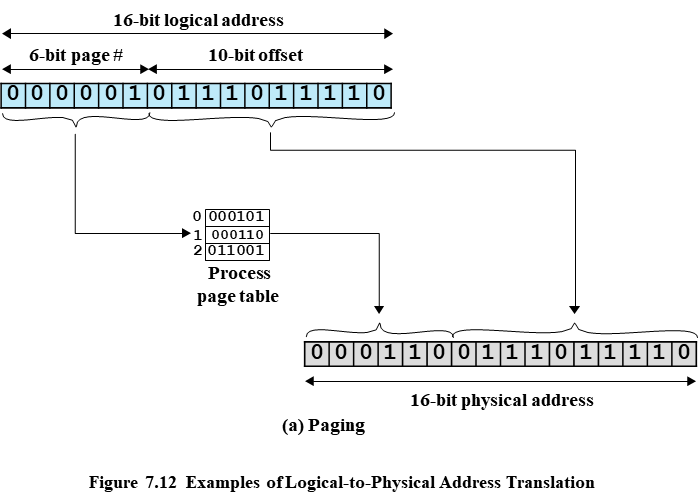
그럼 6bit을 통해 indexing을 하여 page table에서 frame 번호를 구할 수 있다.
frame 번호에 2^10을 곱하고 offset을 더하면 된다.
이는 left shift로 쉽게 구현될 수 있다.
Segmentation
segmentation도 분산적재 중 하나이다. 그런데 덩어리가 가변길이다.
이를 segment이라 한다. 모듈단위로 조각을 낸다.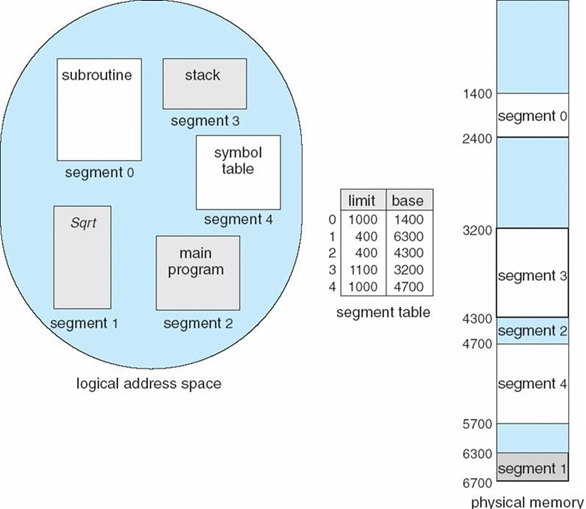
이를 위한 Segmentation table이 필요하다. 이는 base, bound register의 값과 같이 물리적인 시작 주소가 테이블에 저장된다. 그리고 길이도 필요하다. 이를 넘으면 안 된다.
이 조각들은 어디든 갈 수 있다.
장점으로 내부 단편화는 발생하지 않는다. 게다가 조각으로 관리하기 때문에 조각(모듈) 단위로 공유, 보호 할 수 있다.(page도 마찬가지이다. 그러나 segmentation이 더 용이할 것이다.)
외부 단편화는 발생한다.
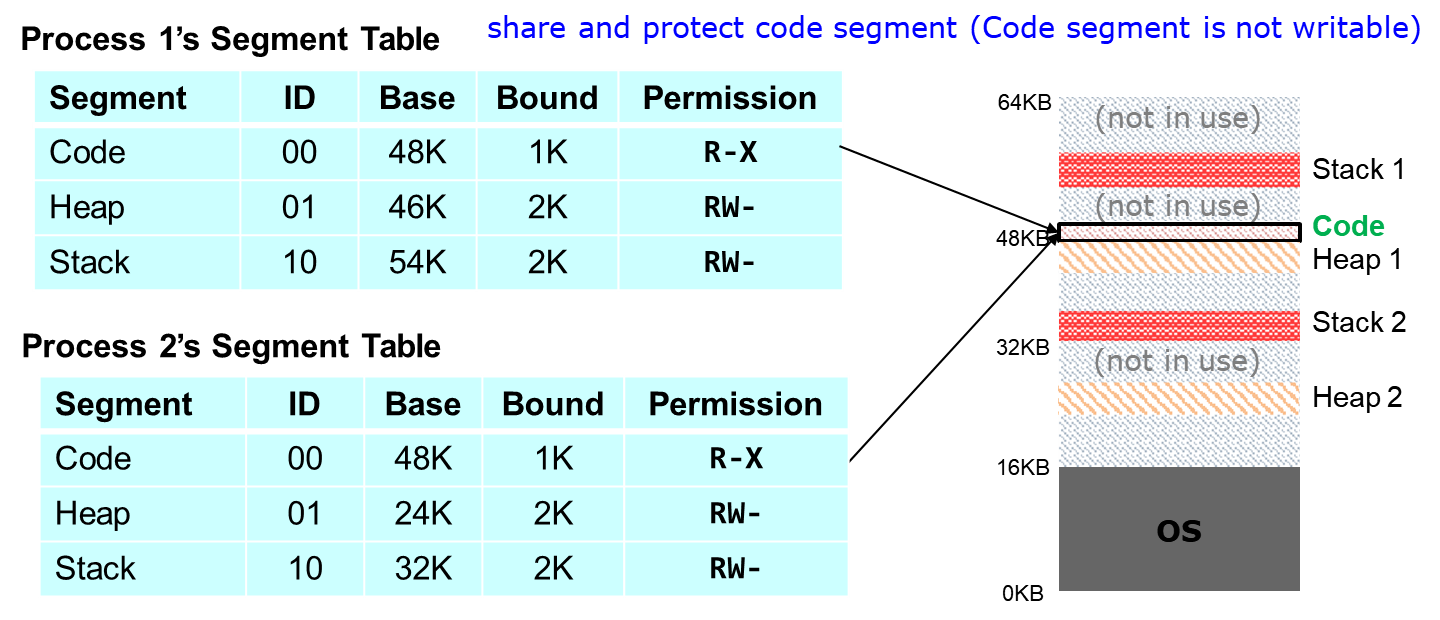
구현단계에선 이 테이블보다 더 많은 정보가 붙는다.
두 프로세스가 특정 segment를 공유하고 있고, segment 단위로 protection, 즉 permission을 부여할 수 있다.
Address Translation
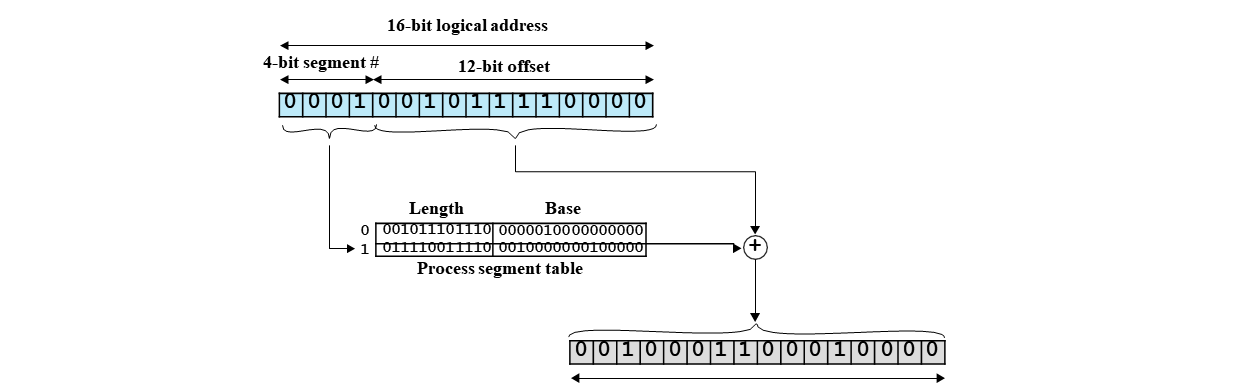
12 bit라고 해도, 4KB의 segment를 사용하는 것은 아니다.
4bit로 segment index를 관리하기 때문에 16개의 segment를 생성할 수 있다.
이는 offset이 length 보다 크거나 같으면 안 된다. offset을 base register 값에 더해 물리 주소를 얻을 수 있다.
