분할적재 방법에 부분적재를 더한 virtual memory에 대해 알아본다.
이전에 본 paging과 segmentation 방법이 이해에 도움을 준다.
virtual 메모리는 disk에 존재하는 프로그램의 많이 사용되는 부분만 적재한다.
그리고 적재되지 않은 부분이 필요할 때 disk에서 memory에 적재해야한다 이를 page fault라 칭한다.
이 방법이 고안된 이유는, 프로그램의 10%가 실행시간의 90%를 차지하기 때문이다.
virtual memory는 마치 cache와 비슷하다. 시간적으로 보았을 때, 특정 코드가 전체 수행 시간을 담당하기 때문에 이 부분들만 적재해놓으면 된다. 그리고 다른 부분이 필요할 때 적재한다.
이는 시간적 지역성과 비슷하다.
그리고 프로그램의 데이타와 이의 사용은 분명 뭉처있다. 이는 또한 공간적 지역성과 비슷하다.
이렇게 부분적재를 한다면 메모리 공간을 넘어가는 크기의 프로세스들이 메모리에 존재할 수 있다.
프로그램의 개수, 크기 제약이 모두 사라지는 환각을 제공한다.
virtual memory는 secondary 메모리인 disk가 메인 메모리의 부분인 것 마냥 사용할 수 있게 해주는 메모리 관리 방법이다.
virtual address란 virtual memory의 주소이다. 이 주소는 disk의 도움을 받아 실제 물리 주소는 없지만 있는 것처럼 사용할 수 있는 주소이다.
반대는 real address이다.
Policy
가상 메모리를 위한 전략은 다음과 같다.
- Fetch Policy: 언제 디스크에 있는 부분을 메모리에 적재할 것인가에 대한 정책이다.
- Placement Policy: first fit, next fit, best fit과 같이 어느 영역에 할당할 것인가에 대한 정책이다.
- Replaceent Policy: 어떤 page가 들어와야할 때, 메모리에 할당된 page 중 어느 것이 swap-out 되는지 대한 정책이다.
- Resident Set Management: 부분 적재에 대한 frame 크기를 결정하는 정책이다.
- Cleaning Policy: 부분이 수정되었을 때, 언제 이를 disk에 write할 것인지에 대한 정책이다.
Fetch Policy
Fetch Policy에 대한 성능 비교는 page fault의 수이다. 이 수가 작아야한다.
- Demand paging: 페이지가 필요한 시점에 메모리에 적재한다.
- Preparing: 처음에 요구됐을 때, 다른 페이지들도 미리 적재한다. 나중에 배운다.
당연히 I/O 연산이 수행되기 때문에, 적재한게 불필요하면 비용이 너무 크다. 잘 안쓰인다.
Placement Policy
paging 기법의 가상 메모리는 아무 곳이나 들어갈 수 있기 때문에 성능에 영향을 많이 끼치지 않는다. 외부 단편화가 없기 때문에 그렇게 중요하지 않다. 현대 OS는 paging 기법을 사용한다.
Replacement Policy
가상 메모리 성능에 영향을 크게 주는 정책이다.
교체 알고리즘이며 새로운 page 들어와야 할 때(메모리가 꽉 찼을 때), 어떤 frame을 swap-out 할지에 대한 정책이다.
멀티 프로그래밍을 위해 OS가 많은 프로세스를 적재할 때 종종 발생한다.
최대한 미래에 잘 접근되지 않을 page를 swap-out 해야한다. 이를 위해 과거 이력을 봐야한다.
커널 프로세스와 같이 frame이 lock 되어 있다면 이는 고려하지 않는다.
이 알고리즘은 오버헤드가 굉장히 클 수 있기 때문에 page fault를 줄이려고 알고리즘을 복잡하게 구현하면 성능이 떨어질 수 있는 tradeoff 관계가 있다.
Optimal Page Replacement
실제로 구현할 수 없는 알고리즘이다. 미래를 안다고 가정하고 제일 사용률이 낮은 page를 swap-out한다. 이는 다른 알고리즘과의 비교용이다. 가장 최적의 알고리즘이다.
initial page fault 수를 세고, 그 이후 page fault 수를 세야한다.
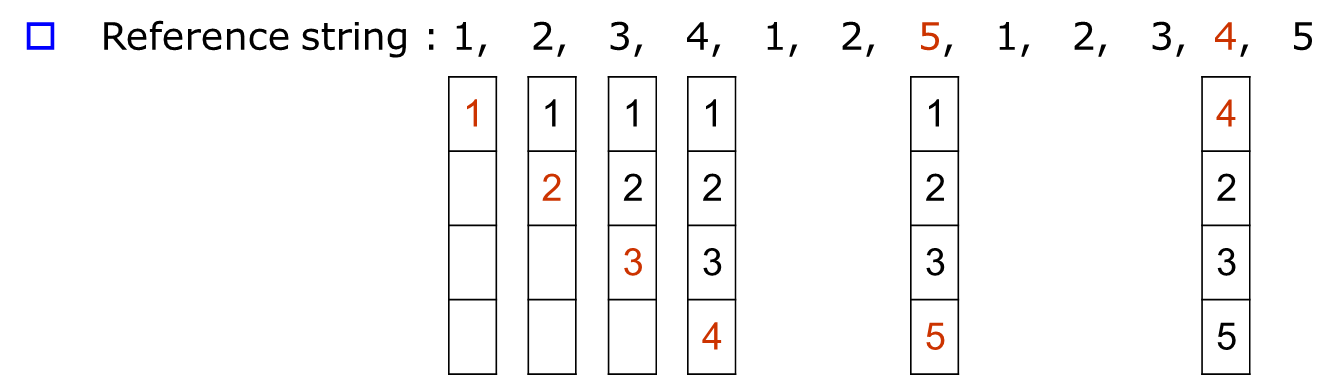
두 번의 page fault가 발생한다. 최적.
FIFO
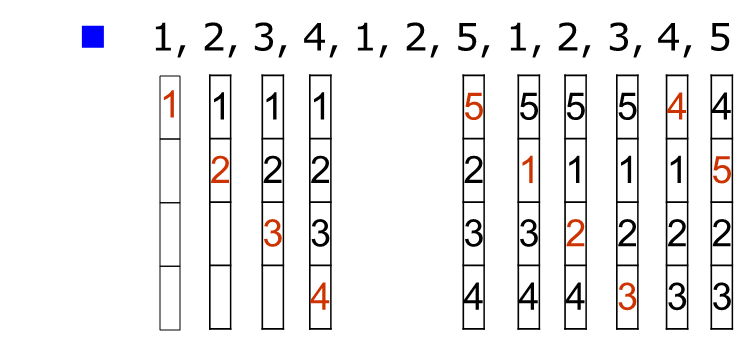
얼마나 사용되는지에 대한 정보가 아예 고려되지 않았다.
구현이 쉽지만 성능이 굉장히 안 좋다.
10번의 page fault가 발생한다.
만약 frame 수가 증가한다면 직관적으로 page fault수가 적어질거라 예상한다.
근데 FIFO 알고리즘은 증가하는 상황이 존재한다.
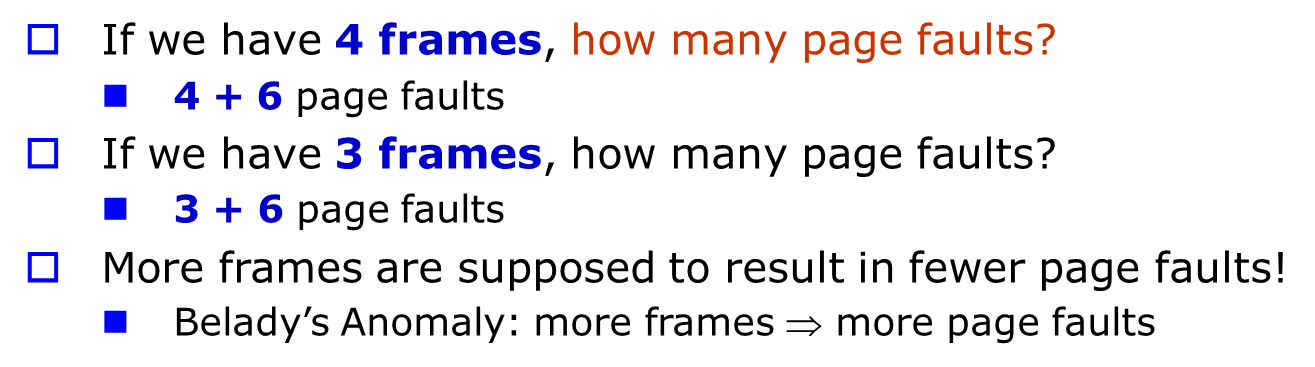
LRU(Least Recently Used)
optimal policy의 근접이다. 가장 오래 접근되지 않은 page를 swap-out한다.
과거를 보고 미래를 예측하는 기법이다.
그러나 구현이 복잡하다는 단점이 존재한다.
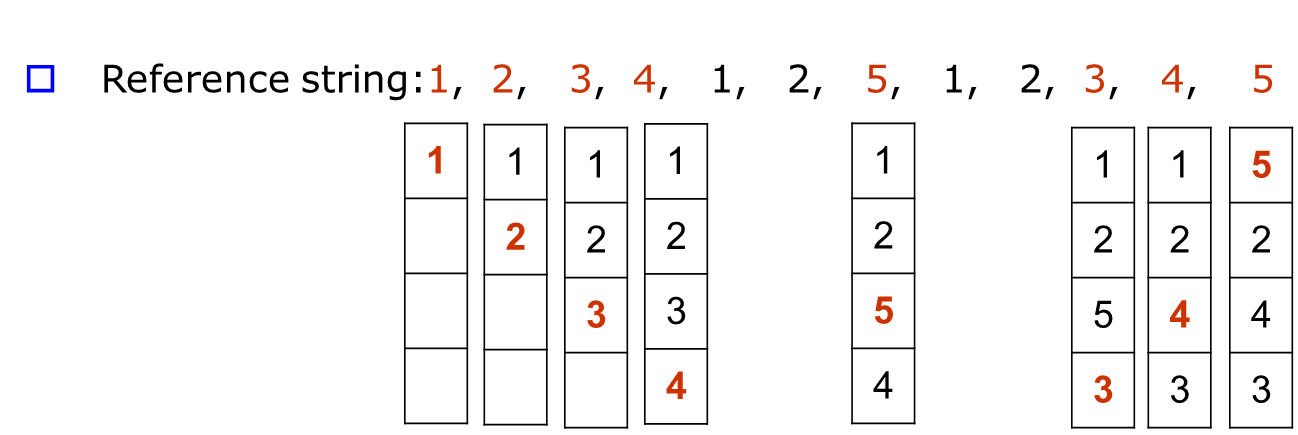
4개의 page fault가 발생한다.
FIFO와 optimal의 중간이다.
단점으로 구현이 복잡하다는 점이 있다. 가장 최근에 사용되지 않은 page를 저장하려면 stack을 사용하거나 페이지에 접근할 때마다 page table entry에 시간을 측정한다거나 방법이 있다.
오버헤드가 너무 크다. 메모리에 접근할 때마다 시간 기록이나 stack에 pop과 push가 발생한다.
비용이 크다. belady anomaly가 발생하지 않는다.
Clock(Second Chance)
LRU는 비용이 크기 때문에 이에 비슷한 성능을 가지는 Clock 알고리즘을 사용할 수 있다.
frame 번호로 indexing이 가능한 환영 버퍼(배열)에 페이지를 저장해둔다.
이 버퍼엔 page 번호와 reference bit이 저장되어 있으며 초기에 page가 load되면 1으로 set 해놓는다.
그리고 page가 접근되면 1로 set한다.
만약 환영 버퍼에 공간이 있다면 환영 버퍼의 cell을 가리키는 포인터를 움직이며 page를 추가한다.
그리고 환영 버퍼가 꽉 찼을 때, reference bit이 1이라면 0으로 변경하고 0이라면 이를 swap-out 후 새로운 페이지를 할당한다.
Second chance인 이유는 1에서 0이되고 0에서 swap-out 되기 때문이다. 두 번의 기회가 주어진다.
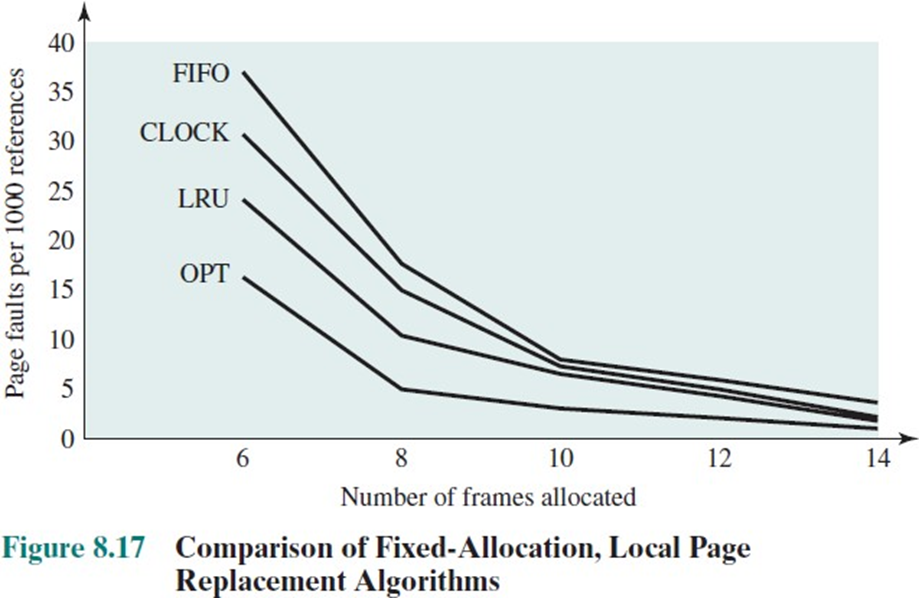
Frame 수가 많을수록 당연히 page faults는 많이 발생하지 않는다.
그러나 적을 때 replacement policy의 성능 차이는 미미하지 않다.
