JAVA Collection Framework
JAVA 에서 제공하는 기본적인 자료구조
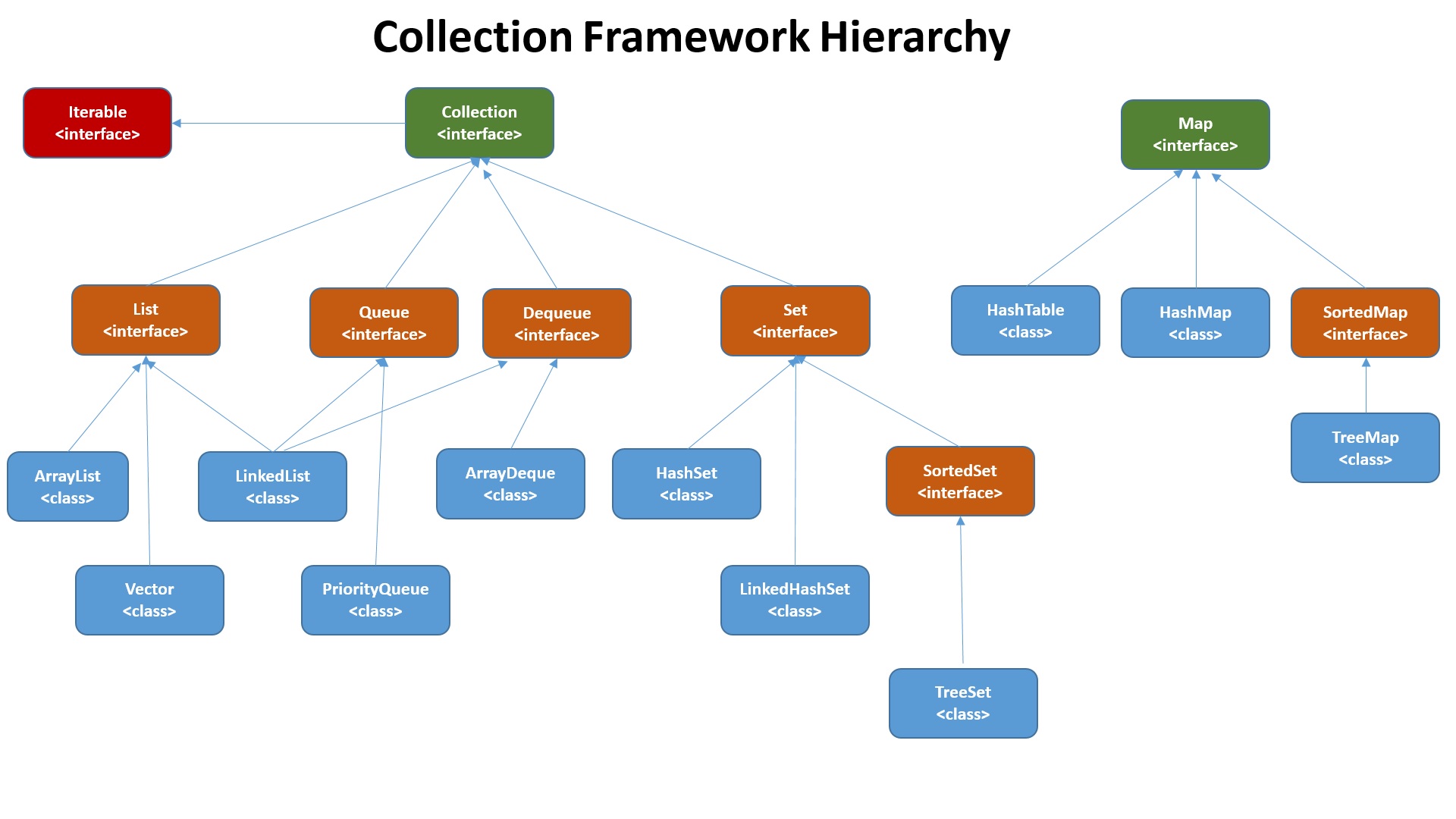
위 계층 구조를 보면 List, Queue, Set은 같은 계열이고,
Map은 다른 계열인 것을 볼 수 가 있다.
1. List : 순서가 있는 데이터의 집합으로, 데이터의 중복을 허용함.
2. Set : 순서가 없는 데이터의 집합으로, 데이터의 중복을 허용하지 않음.
3. Map : 키와 값의 한 쌍으로 이루어지는 데이터의 집합으로, 순서가 없음. 이때 키는 중복을 허용하지 않지만, 값은 중복될 수 있음.
1. List
요소의 저장 순서가 유지되고, 데이터의 중복을 허용하는 컬렉션
1-1. ArrayList
JDK 1.2부터 제공된 ArrayList 클래스는 내부적으로 배열을 이용하여 요소를 저장
배열을 이용하기 때문에 인덱스를 이용해 배열 요소에 빠르게 접근
요소의 추가 및 삭제 작업에 걸리는 시간이 매우 길어지는 단점을 가지고 있음
// 생성
ArrayList<Integer> arrList = new ArrayList<Integer>();
// 요소 추가
arrList.add(40);
arrList.add(20);
arrList.add(30);
arrList.add(10);
// 인덱스를 활용한 요소 가져오기 / 삭제 / 수정
int index = 3;
arrList.get(3);
arrList.remove(index);
arrList.set(index, 20);
// Collections를 이용하여 정렬 가능
// 주의!! Collection = 인터페이스, Collections = 클래스
Collections.sort(arrList);
// Iterator 이용 가능
Iterator<Integer> iter = arrList.iterator();
while (iter.hasNext()) {
System.out.print(iter.next() + " ");
}
// size(): 요소의 총 개수
arrList.size();1-2. LinkedList
ArrayList의 단점인 요소의 추가, 삭제 작업 시간을 줄이기 위해 고안됨
메모리에 저장된 요소가 비순차적으로 분포, 요소들 사이를 링크(link)로 연결하여 구성
자세한 내용
// 생성
LinkedList<String> lnkList = new LinkedList<String>();
// 요소 추가
lnkList.add("넷");
lnkList.add("둘");
lnkList.add("셋");
lnkList.add("하나");
// 인덱스를 활용한 요소 가져오기 / 삭제 / 수정
int index = 3;
lnkList.get(index);
lnkList.remove(index);
lnkList.set(index, "둘");
// Collections를 이용하여 정렬 가능
// 주의!! Collection = 인터페이스, Collections = 클래스
Collections.sort(arrList);
// Iterator 이용 가능
Iterator<Integer> iter = arrList.iterator();
while (iter.hasNext()) {
System.out.print(iter.next() + " ");
}
// size(): 요소의 총 개수
lnkList.size();1-3. Vector
JDK 1.0부터 사용해 온 ArrayList 클래스와 같은 동작을 수행하는 클래스.
현재는 기존 코드와의 호환성을 위해서만 남아있으므로, Vector 클래스보다는 ArrayList 클래스를 사용하는 것이 좋다
2. Set
요소의 저장 순서가 유지하지 않음, 데이터의 중복을 허용하지 않는 컬렉션
2-1. HashSet
HashSet 클래스는 해시 알고리즘(hash algorithm)을 사용하여 검색 속도가 매우 빠름
이러한 HashSet 클래스는 내부적으로 HashMap 인스턴스를 이용하여 요소를 저장
요소의 저장 순서를 유지해야 한다면 JDK 1.4부터 제공하는 LinkedHashSet 클래스를 사용
HashSet<String> hs = new HashSet<String>();
// add() 메소드를 이용한 요소의 저장
hs.add("홍길동");
hs.add("이순신");
// iterator() 메소드를 이용한 요소의 출력
Iterator<String> iter = hs.iterator();
while (iter.hasNext()) {
System.out.print(iter.next() + " ");
}
// size() 메소드를 이용한 요소의 총 개수
System.out.println("집합의 크기 : " + hs.size());2-2. TreeSet
데이터가 정렬된 상태로 저장되는 이진 검색 트리(binary search tree)의 형태로 요소를 저장
추가하거나 제거하는 등의 기본 동작 시간이 매우 빠름
TreeSet<Integer> ts = new TreeSet<Integer>();
// add() 메소드를 이용한 요소의 저장
ts.add(30);
ts.add(40);
ts.add(20);
ts.add(10);
// Enhanced for 문과 get() 메소드를 이용한 요소의 출력
for (int e : ts) {
System.out.print(e + " ");
}
// remove() 메소드를 이용한 요소의 제거
ts.remove(40);
// iterator() 메소드를 이용한 요소의 출력
Iterator<Integer> iter = ts.iterator();
while (iter.hasNext()) {
System.out.print(iter.next() + " ");
}
// size() 메소드를 이용한 요소의 총 개수
ts.size();
// subSet() 메소드를 이용한 부분 집합의 출력
① System.out.println(ts.subSet(10, 20));
② System.out.println(ts.subSet(10, true, 20, true));3. Map
요소의 저장 순서가 유지하지 않음, 키는 중복을 허용하지 않지만, 값의 중복은 허용
3-1. HashMap
HashMap 클래스는 해시 알고리즘(hash algorithm)을 사용하여 검색 속도가 매우 빠름
HashMap<String, Integer> hm = new HashMap<String, Integer>();
// put() 메소드를 이용한 요소의 저장
hm.put("삼십", 30);
hm.put("십", 10);
hm.put("사십", 40);
hm.put("이십", 20);
// Enhanced for 문과 get() 메소드를 이용한 요소의 출력
System.out.println("맵에 저장된 키들의 집합 : " + hm.keySet());
for (String key : hm.keySet()) {
System.out.println(String.format("키 : %s, 값 : %s", key, hm.get(key)));
}
// remove() 메소드를 이용한 요소의 제거
hm.remove("사십");
// iterator() 메소드와 get() 메소드를 이용한 요소의 출력
Iterator<String> keys = hm.keySet().iterator();
while (keys.hasNext()) {
String key = keys.next();
System.out.println(String.format("키 : %s, 값 : %s", key, hm.get(key)));
}
// replace() 메소드를 이용한 요소의 수정
hm.replace("이십", 200);
// size() 메소드를 이용한 요소의 총 개수
hm.size();3-2. HashTable
Hashtable 클래스는 JDK 1.0부터 사용해 온 HashMap 클래스와 같은 동작을 하는 클래스.
현재는 기존 코드와의 호환성을 위해서만 남아있으므로, Hashtable 클래스보다는 HashMap 클래스를 사용하는 것이 좋다.
3-3. TreeMap
TreeMap 클래스는 키와 값을 한 쌍으로 하는 데이터를 이진 검색 트리(binary search tree)의 형태로 저장
추가하거나 제거하는 등의 기본 동작 시간이 매우 빠름
JDK 1.2부터 제공된 TreeMap 클래스는 NavigableMap 인터페이스를 기존의 이진 검색 트리의 성능을 향상시킨 레드-블랙 트리(Red-Black tree)로 구현
TreeMap<Integer, String> tm = new TreeMap<Integer, String>();
// put() 메소드를 이용한 요소의 저장
tm.put(30, "삼십");
tm.put(10, "십");
tm.put(40, "사십");
tm.put(20, "이십");
// Enhanced for 문과 get() 메소드를 이용한 요소의 출력
System.out.println("맵에 저장된 키들의 집합 : " + tm.keySet());
for (Integer key : tm.keySet()) {
System.out.println(String.format("키 : %s, 값 : %s", key, tm.get(key)));
}
// remove() 메소드를 이용한 요소의 제거
tm.remove(40);
// iterator() 메소드와 get() 메소드를 이용한 요소의 출력
Iterator<Integer> keys = tm.keySet().iterator();
while (keys.hasNext()) {
Integer key = keys.next();
System.out.println(String.format("키 : %s, 값 : %s", key, tm.get(key)));
}
// replace() 메소드를 이용한 요소의 수정
tm.replace(20, "twenty");
// size() 메소드를 이용한 요소의 총 개수
tm.size();4. 참고
https://hwan1001.tistory.com/10
http://www.tcpschool.com/java/java_collectionFramework_concept
https://facingissuesonit.com/2019/10/15/java-collection-framework-hierarchy/
https://www.codejava.net/java-core/collections/java-map-collection-tutorial-and-examples
