오늘은 Improving Language Understanding by Generative Pre-Training, 즉, GPT1 논문 리뷰를 해보도록 하겠습니다.
1. Introduction
라벨 데이터를 활용해야하는 supervision setting은 수집된 데이터를 augmentation (라벨을 할당하는 작업)하는 것은 시간적 time-consuming하고 expensive합니다. 따라서 unlabeled text를 활용하는 것이 필요시되는데 이러한 데이타들을 활용하기 위해서는 두 가지 문제점이 있습니다: 1. text representation을 학습하는 데 있어 최적화 목표 (라벨이 없기 떄문)가 명확하지 않다, 2. 학습된 representation을 target task에 활용하는 효과적인 방법들이 아직 논의된 바 없다.
따라서 본 논문에서는 unsupervision setting에서 pre-training을 활용한 representation 학습 및 supervision setting에서 효과적인 fine-tuning을 통해 위와 같은 문제들을 해결하려 합니다. 즉, 저자들의 범용성이 높은 text representation 학습해서 적은 adaptation (fine-tuning)을 통해 다양한 task에 적용하는 방법론, 혹은 모델을 제시합니다.
2. Related Work
Related work에서는 총 3가지 개념 (Semi-supervised learning, Unsupervised pre-training, Auxiliary training objectives)에 대해서 다루고 있는데 이에 대해서는는 본문 내용과 함께 다룰 수 있도록 하겠습니다.
3.Framework
3.1 Unsupervised pre-training
Unsupervised pre-training은 label을 사용하지 않고 범용성 있는 word token을 학습하는 과정입니다. (근데 논문 전반적으로 수식이 좀 ... 명확하게 쓰여져 있는 것 같지는 않습니다.)
만약 학습에 사용되는 의 토큰 셋이 주어져 있을 때 objective function을 다음과 같습니다.
해당 식의 의미는 i번째 토큰 등장 확률을 최대화하기 위해 이전 k 사이즈 만큼의 context window를 고려한다는 것입니다. 는 neural net의 학습 가중치들을 의미합니다. 또한 이러한 neural net은 transformer의 decoder를 가져와 사용합니다.
원 논문은 이부분에서 몇가지 수식이 더 나오는데 솔직히 저는 아예 잘 못 써진 수식들 같습니다... 더헷갈리기만 하니 다루지 않겠습니다. 포인트는 위 수식과 같이 특정 task에 대한 label이 없더라도 i이전의 토큰들을 인풋, i번째 토큰을 정답으로 하여 학습한다는 것 입니다.
3.2 Supervised fine-tuning
GPT는 unsupervised loss 외에도 end-to-end task를 위한 supervised loss도 추가적으로 사용합니다. 식은 다음과 같습니다.
식은 복잡해보이지만 결국 supervision loss와 비슷하게 transformer의 decoder의 출력 임베딩을 사용하여 다시 weght를 곱해주고 softmax를 지나는 것과 같은 방식으로 통해 task를 수행한다는 의미입니다. (Task 종류에 따라 각 word token을 따로 사용할 지 함께 사용할 지 달라질 것 같습니다.)
따라서 fine tuning시 최종 loss는 다음과 같습니다.
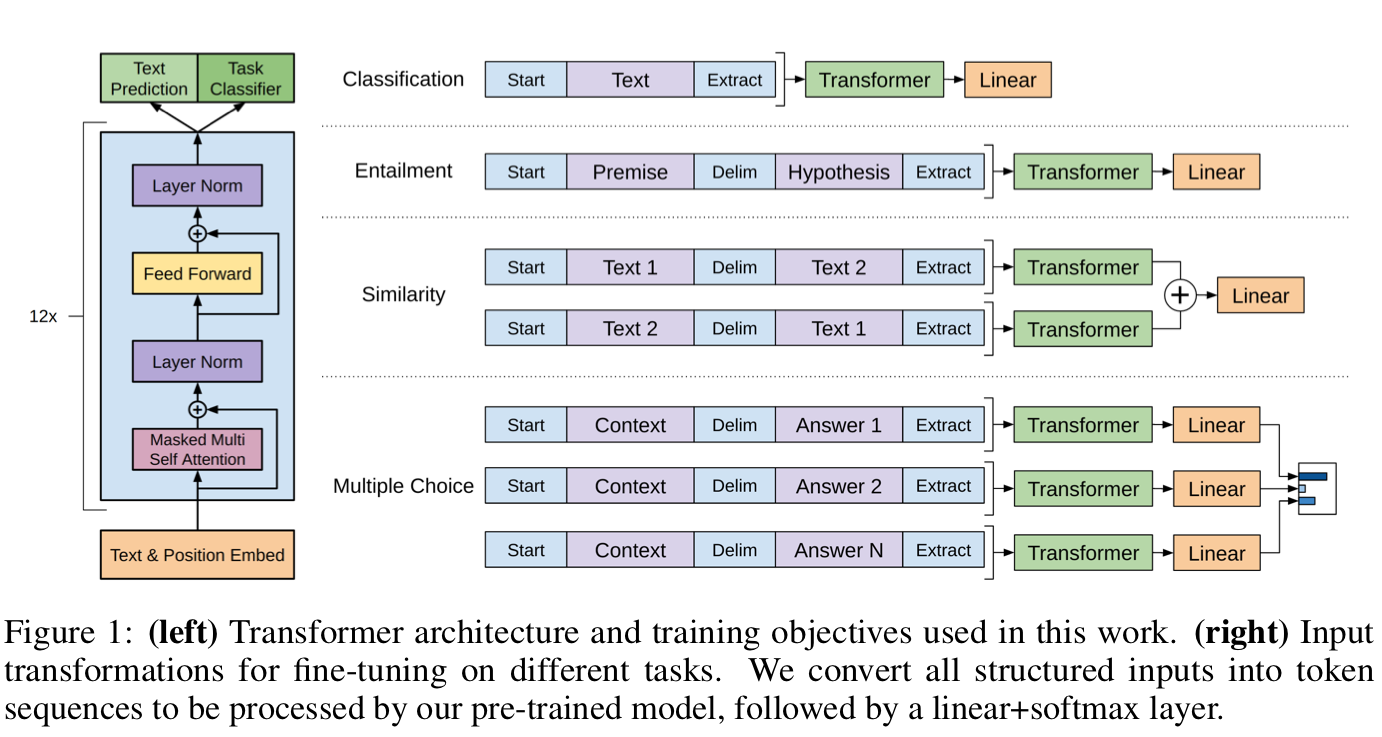
3.3 Task-specific input transformations
바로 위에서 언급했듯이 task 종류에 따라 fine-tuning 방법은 바뀔 수 있습니다. 예를 들어 word 단위로 분류가 이루어지는 text classification과 같은 경우에는 각 토큰에 weight를 곱해준 뒤, softmax를 취해 수행될 수 있습니다. 다른 task 같은 경우 start , end , delim 토큰들을 사용하여 아래 예시들과 같이 수행될 수있습니다.
4.Experiments
4.1 Setup
pre-training data로는 BooksCorpus dataset과 1B Word Benchmark 데이터셋을 사용했다고 합니다. 또한 대부분의 task 오직 3번의 epoch만으로 좋은 성능을 달성할 수 있다고 합니다.
4.2 Supervised fine-tuning
사용된 dataset들과 task는 아래의 표에서 확인하실 수 있습니다.

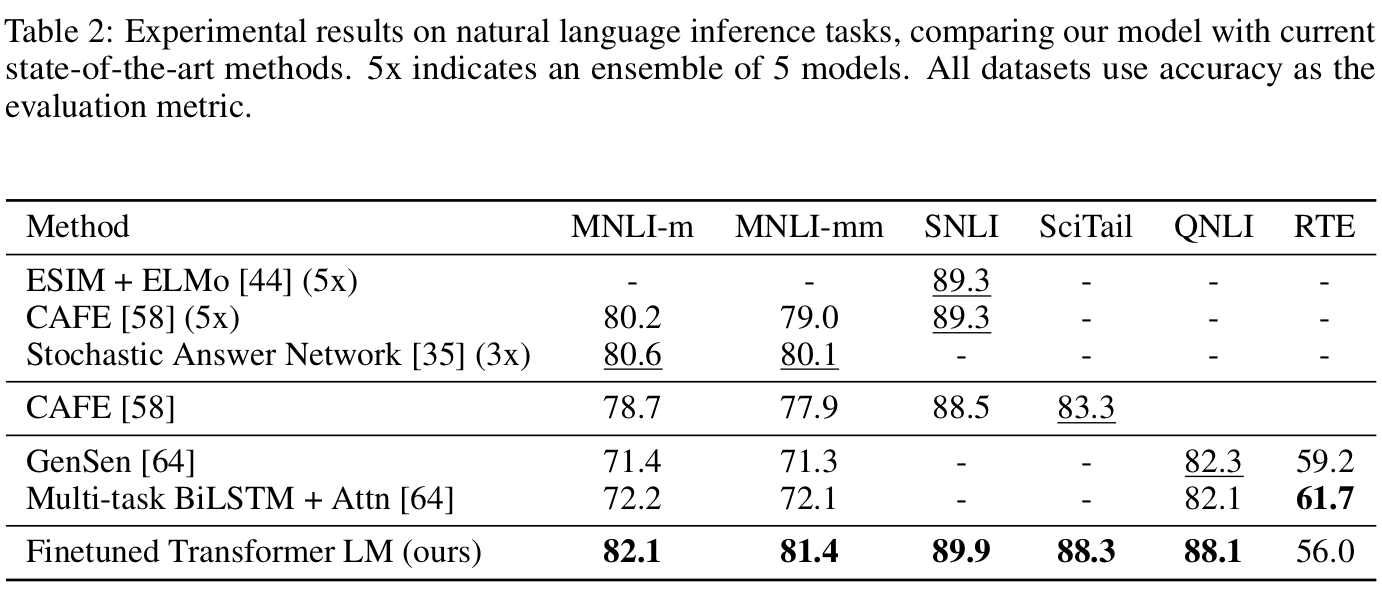
Natural language inference는 문장 사이의 관계를 entailment(자연스러움), contradiction(모순), neutral(중립)으로 분류하는 task이며 결과는 아래 표에 정리되어 있습니다.
사실 Question answering, Commonsense reasoning, Semantic Similarity, Classification등 다양한 task에 대한 실험을 진행하였는데 특별한 내용은 없어 생략하도록 하겠습니다.
5.Analysis
본 파트에서는 RACE, MultiNLI 두개의 dataset에 대해 fine-tuning시 pre-training으로 부터 전이되는 transformer layer의 갯수에 대한 성능 비교를 해보았습니다.
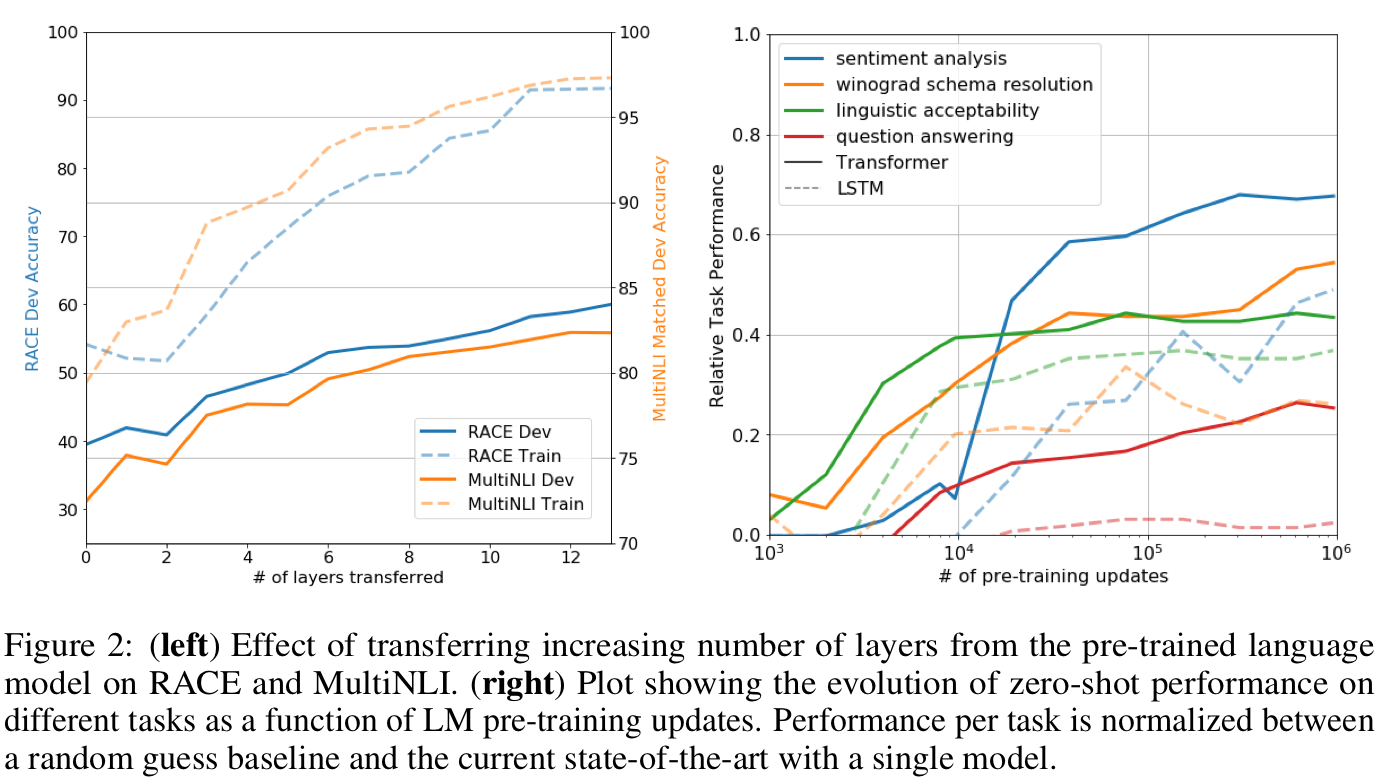
왼쪽 그림에 따르면 MultiNLI dataset에서는 pre-training으로 인해 총 9%의 성능 향상이 관찰된 것을 확인할 수 있습니다. 또한 오른쪽 그림에 따라 pre-training parameter 갯수에 따른 zero-shot 성능을 비교하였을 때 GPT(실선)의 성능이 LSTM(점선)의 성능보다 우수한 것을 확인할 수 있습니다. 즉, GPT의 pre-training은 문장의 구조나 연결 관계등을 더 잘 파악하고 있다고 결론 내릴 수 있습니다.
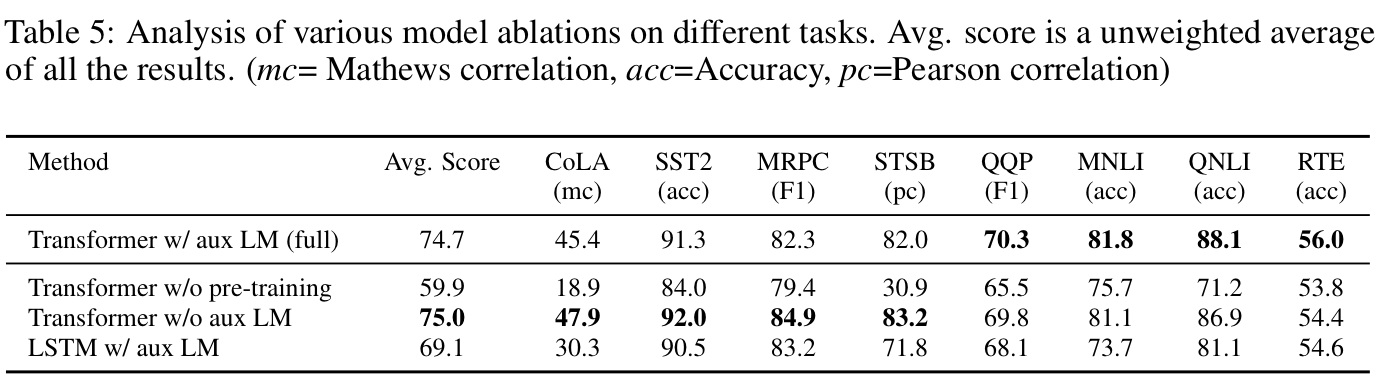
마지막으로 fine-tuning loss 에서 auxiliary loss 의 영향에 대해 실험하였으며 결과는 다음과 같습니다.
총평
GPT가 대단한 모델 혹은 training 방식인 것을 알고 있기에 논문을 꼭 읽어보고 싶었는데 솔직히 논문이 잘 쓰여져 있는 것 같지는(특히 수식) 않았습니다. 그래도 재미있게 읽었네요. 읽어주셔서 감사드립니다 :)