[ONE-PEACE: Exploring One General Representation Model Toward Unlimited Modalities] 논문 리뷰
오늘은 ONE-PEACE를 리뷰해보려 합니다. 최근에 개인적으로 진행하는 프로젝트 때문에 semantic segmentation task를 진행하게 되었는데 해당 모델이 리더보드 상위권에 있더라고요. 근데 multi-modal model이더라고요 ... 한번도 경험해본적이 없는 분야라 논문 리뷰를 해보려고 합니다.
1. Introduction
Representation model들은 다양한 분야에서 큰 성과를 이루어 왔다고 합니다. 저도 사실 처음보는 용어이기는 한데 저는 간단한 fine-tuning이나 zero-shot setting에서도 다양한 task를 진행할 수 있도록 데이터들의 일반적인 representation을 학습하는 모델들로 이해를 했습니다. 이러한 representation model들은 multi-modal 분야에서도 요긴하게 사용되는데 특히 다양한 도메인 (대표적으로 vision, language, audio)에 대해 통합된 학습이 가능한 uni-modal representation model들이 많이 연구가 되어 왔습니다.
그러나 아직까지 연구된 uni-modal model들은 multi-modal을 학습하기에는 조금 효용성이 떨어진다고 하네요. 즉, 저자들은 다양한 modal에서도 통일되게 사용가능한 general representation model의 필요성을 제안합니다.
본 논문에서는 general representation model의 scalable way (모델을 확장 혹은 축소 시키는 방법)에 대해 다루고 있습니다. 또한 general representation model은 다음과 같은 3가지 조건을 충족해야합니다: 1. 다양한 Modality에 유연한 structure를 가질 것, 2. pretraining task가 각 modality에서 충분히 유용한 정보를 추출해낼 수 있어야 하며 서로간의 alignment를 보장할 것, 3. 다른 modality들에도 충분히 적용할 수 있도록 pretraining task가 일반화될 것. 따라서 위 조건에 부합하는 모델인 ONE-PEACE와 pretraining 방법을 제안합니다.
2. Related Work
해당 파트에서는 Vison-Language Pretraining, Audio-Language Pretraing, Vision-Audio-Language Pretraining등 다양한 modality에 따른 pretraining을 다루고 있습니다.
3. Method
3.1 Modality Adapters
ONE-PEACE의 기본적인 구조는 총 3개의 modality-adapter와 Modality fusion encoder로 구성되어 있습니다. 대략적인 구조는 아래와 같습니다.
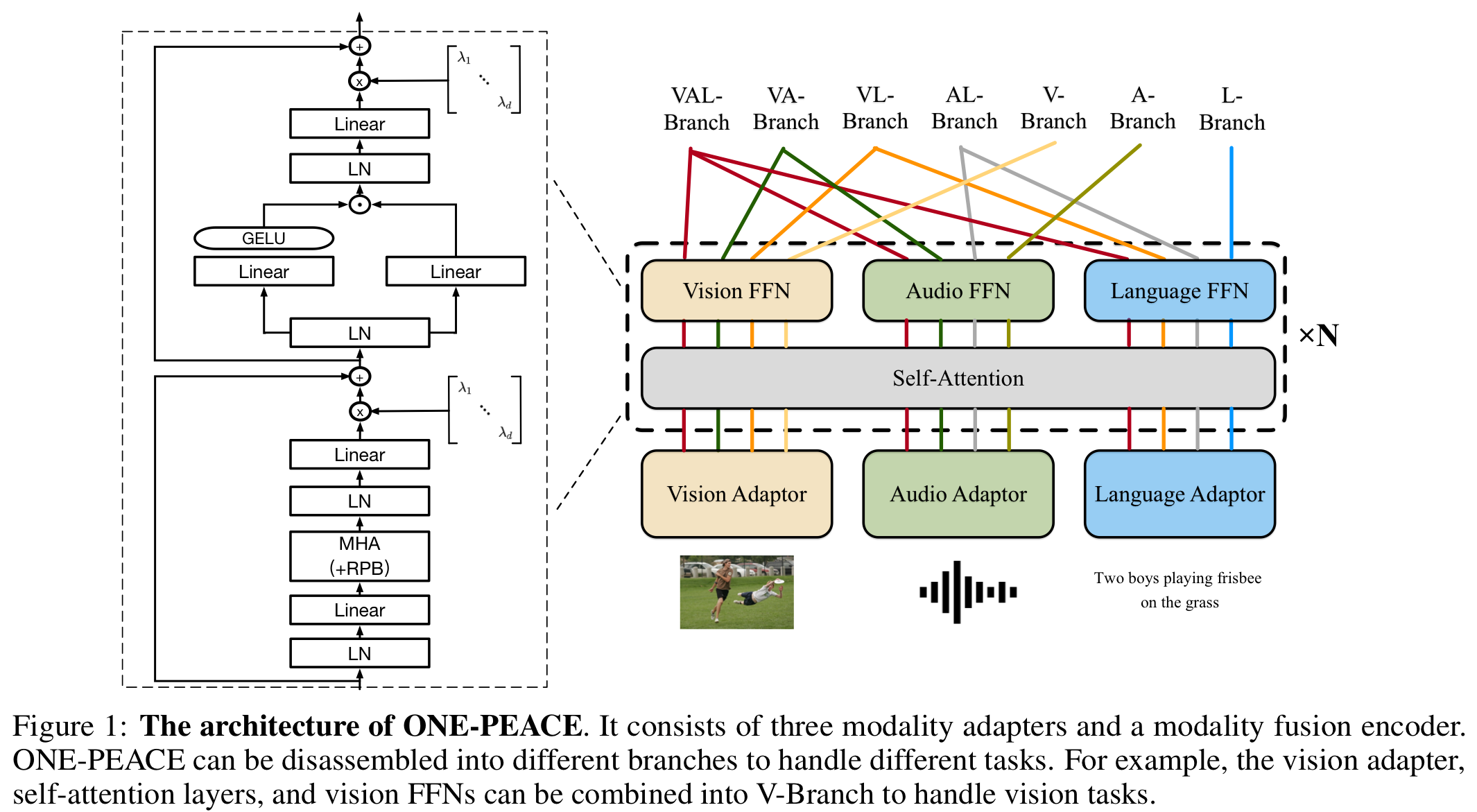
위 그림을 보시면 각각의 adapter에 연결된 FFN (Feed-Forward-Network)들을 통해 여러개의 task(VA-Vedio, Audio, AL-Audio, Language)들을 수행해내는 것을 알 수 있습니다.
Modality Adaptor는 각각의 adapter들이 서로 다른 신호들에 대해서 적용됩니다. 즉, 각 domain에 맞는 adapter를 선택할 수 있기 때문에 좀 더 유연한 unified model의 디자인이 가능하다고 합니다. 이제 본 논문에서 사용한 각각의 adapter를 살펴보도록 하겠습니다.
Vision Adapter (V-Adapter)는 VIT와 유사하게 이미지를 패치단위로 나누어서 transformer block들을 거치는 형태로 설계되었습니다. 패치의 크기는 forward를 진행할 수록 달라진다 합니다. 또한 positional embdding을 더해주었고 vision class embedding token도 함께 학습합니다. 수식적으로는 로 표기되며 은 패치의 갯수를 의미합니다.
Audio Adapter (A-Adapter)는 제가 한번도 다뤄본적이 없어서 잘 모르겠지만 적혀있는데로 최대한 설명드리도록 하겠습니다. 우선 16kHz 마다 샘플링을 진행하고 standadization을 적용했습니다. 이후 convolution (아마 1d convolution)을 적용하여 임베딩을 추출했다고 합니다. 수식적으로는 로 표기되며 은 audio representation의 총 길이 입니다.
Language Adapter (L-adapter)도 일반적인 LLM 모델에 사용되는 것과 비슷한것 같습니다. 토큰화를 진행한후 positional embedding을 더해주고 transformer 계열 모델들을 통해 학습해주는 것 같습니다. 문장 시작에는 , 끝에는 토큰이 삽입되며 수식적으로는 다음과 같습니다. , 은 문장의 길이를 나타냅니다.
Modality Fusion Encdoer 또한 기본적으로는 transformer 구조를 따릅니다. 위 그림에서 확인하실 수 있듯이 각각의 다른 domain 사이에서 공통된 self-attention layer를 공유합니다. 이는 각각의 다른 modality 사이에서 interaction을 공유하게 해준다고합니다. 또한 서로 다른 modality는 각각의 FFN을 사용함으로써 각 domain에 적절한 정보를 추출하는데 도움을 줍니다. 또한 다음과 같은 사항들을 추가하여 안정성 및 성능을 높혔습니다.
- Sub-LayerNorm: 말그래도 transformer block들 사이에 layer norm을 적용.
- GeGLU Activation Function
- Relative position Bias: Position embedding외에도 position을 표시하기위해 학습되는 bias로 유추됩니다. 사전학습간에는 attention layer가 동일한 bias를 공유하지만 fine-tuning시에는 공유하지 않고 따로 학습되는 것 같습니다.
- LayerScale: 특정 layer의 Output이 residual block을 통해 그전의 결과들과 합쳐지기 전에 learnable digonal matrix를 곱해져서 scaling을 진행한다고 합니다.
3.2 Tasks
ONE-PEACE의 사전학습은 Cross-Modal Contrastive Learning과 Intra-Model Denoising Contrastive Learning로 구성되어 있으며 대략적으로 아래 그림과 같이 진행됩니다.
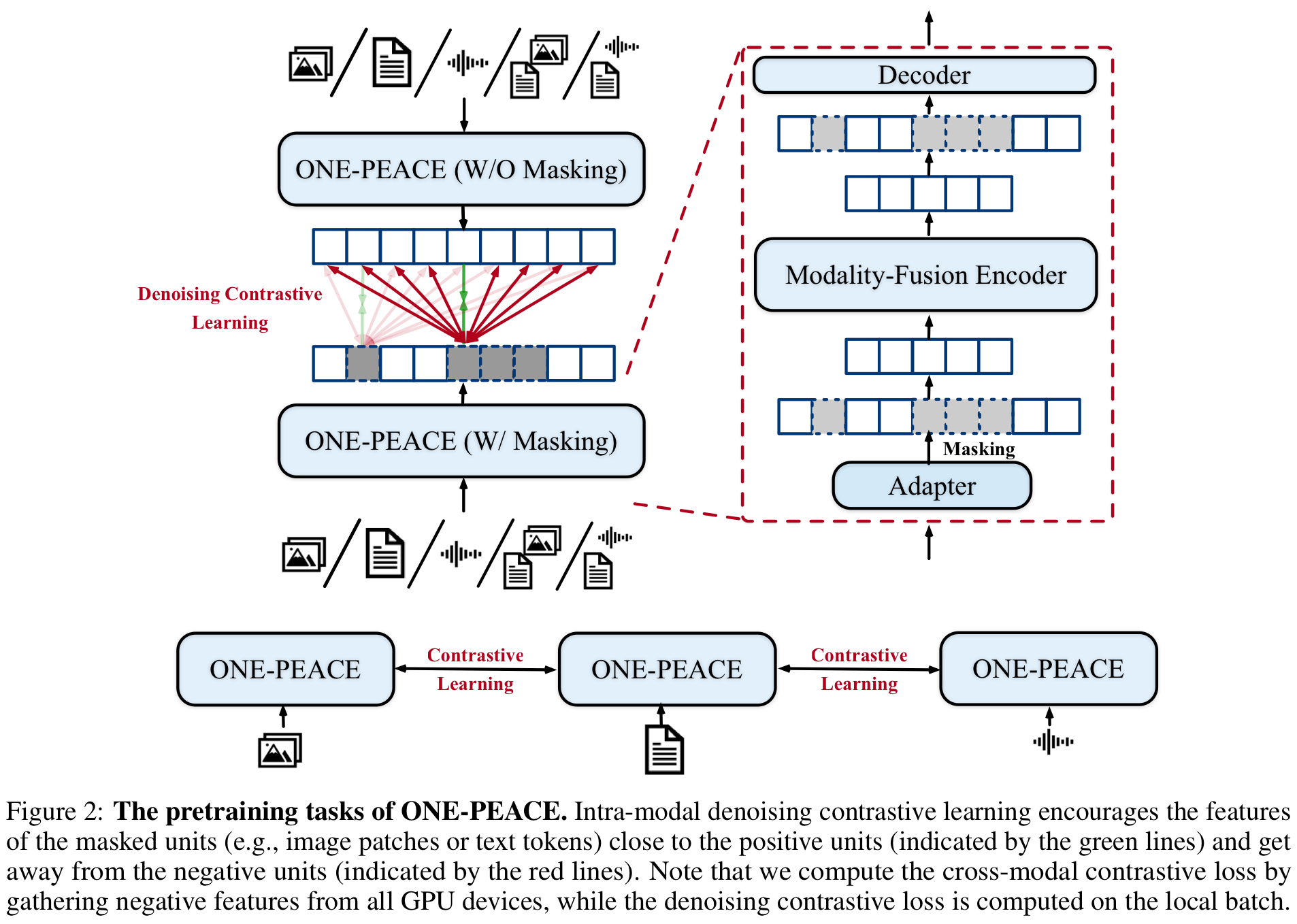
Cross-Modal Contrastive Learning은 다양한 modality를 학습하기 위해 일반적으로 사용되는 방법론이라 합니다. 가장 기본적인 아이디어는 서로 다른 modality의 sample pair 하더라도 연관이 있으면 similarity를 최대화하고 그렇지 않다면 최소하는 것입니다. 만약 sample pair ()가 있다고 가정하면 각각의 branch (Text-Vision, Audio-Text)를 지난후 cls 토큰에 linear projection과 noramalization을 적용하여 최종 cls representation ()를 얻어낸 후 다음과 같이 contrastive learning을 적용합니다:
은 배치 사이즈, 는 배치내의 인덱스를 의미합니다.
앞서 설명드린 loss는 다른 modality 사이의 representation embedding들을 align (같은 space상에 위치시키는데)시키는데 집중하고 있습니다. 하지만 이러한 learning 방법은 각 modality에서 detail한 정보를 추출하고 downstream task에 대해 성능을 높히는 데는 주는 영향이 적습니다. 따라서 이를 위해 Intra-modal Denoising Contrastive Learning을 소개하며 기본적으로는 masked prediction과 contrastive learning이 결합된 형태를 하고 있습니다.
우선은 각 adapter에서 embedding을 추출한 후, domain (image patch, text token)에 맞게 마스킹을 취해줍니다. 이때 각각의 FFN에 forwarding 되기 전 modality-fusion encoder 단계에서 마스킹을 취해주었다 합니다. 이후, 마스킹 되지 않은 토큰들은 학습 가능한 mask token과 concat한후 가벼운 transformer decoder에 투입시켜줍니다. 이후 다음과 같이 masked된 토큰 임베딩 ()과 마스킹되지 않은 상태에서 ONE-PEACE의 포워딩을 통해 계산된 토큰 임베딩 () 사이의 contrastive learning을 적용합니다.
는 stop gradient operation, 은 sample내의 총 토큰 혹은 패치의 갯수, 은 마스킹된 토큰의 총 갯수라합니다.m은 아예 다른 데이터를 의미하는 것 같습니다. 즉, 위 식은 같은 데이터내의 masking된 토큰의 feature를 예측하면서 다른 데이터의 token들과는 멀어지게 만드는 효과를 냅니다.
3.3 Training
ONE-PEACE의 pretraining은 vision-language, audio-language에 관한 학습으로 진행됩니다. (vision-language는 data가 없나...?) vision-language 단계에서는 다음과 같이 vision, language adapter와 vision-laguage와 관련된 loss를 통해서만 학습합니다.
또한 audio-language 단계에서는 다음과 같이 A-Adapter, A-FFNs 등 audio-related parameter들만 학습합니다.
이러한 방법을통해 vision과 audio에 대한 학습이 없어도 language를 anchor로 하여 학습이 잘 된다고 합니다.
4. 결론
사실 4. Pretraining Details과 5. Result 또한 보려고 했것만 (물론 저는 훑어보기는 했습니다만 ...) 특별한 내용은 없더라고요. 해당 부분은 각 여러분들이 관심있는 modality에 대한 실험 결과만 봐도 충분할 것 같습니다.
Multi-modal model은 사실 처음보는 건데 LLM이랑 상당히 결이 비슷하네요. Pretraining은 통한 general representation (token)의 학습이후 pretraining... 이러한 실험을 할 수 있는 하드웨어가 상당히 부럽습니다 ㅎ. 오늘 논문 리뷰는 여기서 마치며 댓글, 메일을 통한 질문 혹은 논의는 언제나 환영입니다!