오늘은 GPT2, Language Models are Unsuperviesd Multitask Learners 논문을 리뷰해보도록 하겠습니다.
1. Introduction
인트로에서는 Multitask learning이 가능한 general model에 대한 필요성을 강조하고 있습니다. 일반적으로 그러한 모델을 만들기 위해서는 매우 다양한 (dataset, objective) 쌍이 필요로 한데 이는 매우 비효율적입니다. 따라서 본 논문에서는 이전에 zero-shot setting에서도 충분히 다양한 task를 해내었던 GPT1과 같이 pretraining과 fine-tuning을 활용하여 general model을 학습하는 방법을 제시하고 성능을 검증하는 것이 목표입니다.
2. Approach
본 논문의 가장 주요한 키워드는 Language Modeling입니다. Language Modeling은 unsupervied setting에서 각각의 sequential (단어, 토큰 ...)으로 이루어진 (문장, 문단)의 disturibution을 추정하는 것을 의미합니다. 각 data의 등장 확률은 일반적으로 다음과 같이 결합 확률을 factorization 형태로 나타냅니다.
이러한 추정은 특정 sequential에서 다음 단어 혹은 토큰의 sampling을 가능케하며 도 구해낼 수 있기 때문에 다양한 architecture 혹은 학습 방법에 이용되어 왔습니다.
Single task에서 학습 과정은 과 같이 주어진 input에 대한 output의 조건부 분포를 추정하는 과정으로 표현될 수 있습니다. 그러나 multitask는 똑같은 input이더라도 task 별로 output이 다르게 도출되어야 하기 때문에 를 추정하는 것으로 표현될 수 있습니다. 일반적으로 이러한 multitask는 architecture나 algorithm 관점에서 고려되어 왔지만 language model은 간단히 input의 sequence를 조정함에 따라 표현될 수 있습니다. 예를들어, 를 통해 영어를 프랑스어로 번역하는 task를 간단히 표현할 수 있습니다.
unsupervised setting에서도 supervised setting과의 본질적인 objective (아마 윗 문달들에서 언급된 조건부 분포를 최적화하는 것을 말하는 것 같습니다.) 같기 때문에 충분히 golbal minimum을 달성할 수 있습니다. 오히려 문제는 근본적으로 unsupervised objective를 최적화할수 있냐에 달려있습니다. 어쨋건 이전 연구들은 LLM이 충분히 multitask를 수행해낼 수 있다는 것을 보여주었습니다. 물론 학습 속도는 supervised approach들 보다는 매우느리지만요.
사실 다음 문단의 의미를 정확히 파악하지는 못했지만 결국 정제되거나 특별한 형태로만 추출되지 않은 완전한 야생의 language data를 활용해서 multitask LLM을 학습해야함을 주장하는 것 같습니다.
2.1 Training data
GPT2는 기존 연구들과 같이 정제된 데이터를 사용하는 것이 아니라 common crawl(크롤링)을 사용해서 최대한 다양하고 많은 데이터를 수집했다고 합니다. 하지만 수집된 데이터들은 퀄리티가 낮다는 문제가 있습니다. 그래서 Reddit에서 3개 이상의 karma(좋아요 같은게 아닐까 ... )를 받은 글들을 수집했고 이후에는 사람이 판단하여 데이터를 만들었다고 합니다... 최종적으로 총 40GB의 WebText 데이터셋을 구성했습니다.
2.2 Input Representation
GPT2는 토크나이징할 때 'Byte Pair Encoding (BPE)' 방식을 채용했습니다. 이전까지 BPE의 구현은 모든 unicode (그냥 문자)로 부터 vocabulary를 형성하는 것에서 시작하였는데, 이러한 경우 base vocabluary가 130000개나 필요하다고 합니다. 반면 문자들을 byte화 해서 BPE를 적용한다면 base vocabulary가 256개만 필요하다고 합니다. 또한 vocabulary에 없는 토큰이라도 표현할 수 있다고 합니다.
2.3 Model
이전에 발표되었던 GPT1과 크게 차이가 없습니다.
3. Experiments
해당 부분에서는 역시나 다른 모델들과 같이 좋다는 이야기만 주구장창 나올테니 좀 특별한 부분이나 데이터 셋 위주로 다루도록 하겠습니다.
3.1~3.3 Language Modeling~ LAMBADA
Dataset은 다음과 같은 benchmark들을 사용했습니다.
- Children's Book Test(CBT)는 LM이 각 카테고리의 단어를 올바르게 예측 할 수 있는지 실험하기 위해 고안된 데이터 셋 입니다 (~명사, 동사들과 같은 종류로 분류).
- LAMBADA는 LM의 long-range dependency를 검증하기 위한 데이터 셋입니다. Task는 간단히 주어진 문장의 마지막 단어를 올바르게 예측하는 것입니다.
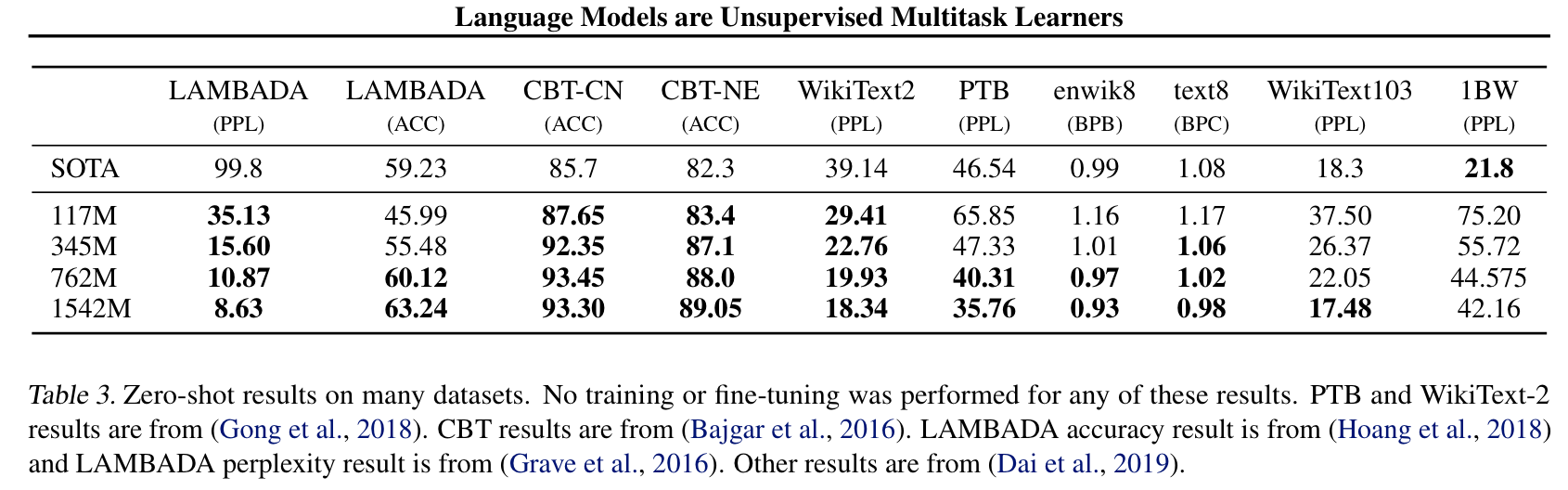
- 위 데이터셋들 외에서도 global benchmark인 WikiText2, enwik8, text9 WikiText103, 1BW에서 테스트 하였고 아래 표와같이 한개의 데이터셋을 제외하고는 모두 sota를 달성했습니다.
3.4 Winograd Schema Challenge
Winograd Schema Challenge는 commonsense reasoning을 수행하기 위해 진행된는 챌린지 인듯하다. 아래 예시와 같이 모호한 단어(he, they ...)들이 무엇을 지칭하는지 맞추는 문제인듯 하다.

3.5 Reading Comprehension
Conversation Question Answering data(CoQa)는 대화 데이터 형식이 주어지고 해당 대화에 대한 question이 주어졌을 때 올바른 대답을 선택하는 형식의 task dataset입니다. 즉, 문맥을 올바르게 판단할 수 있는지 측정하기 위한 데이터 셋이빈다.
3.6 Summarization
CNN과 Dailt Mail Dataset을 활용하여 측정하였다고 합니다. 저는 처음보는 Rouge metrics를 사용하던데, 해당 지표는 생성된 단어, 혹은 정답 요약에서 n-gram overlapping을 측정하는 방식입니다.
3.7 Translation
번역 작업도 수행했습니다... 딱히 특별한 건 없습니다!
3.8 Question Answering
해당 task도 context가 주어지거 문제와 그 후보들이 주어져 정답을 맞추는 형태입니다. 아직은 retrival을 활용한 방법보다는 정확도가 떨어진다고 합니다.
4. Generalization vs Memorization
많은 image dataset는 트레인과 테스트 데이터 셋 사이에 복제된 것과 같은 이미지가 존재한다고 합니다. GPT2를 학습한 WebText dataset에서도 이러한 현상을 발견했기 떄문에 일반화를 검증하기 위해서 test data가 train data에서도 존재하는지 잘 따져봐야합니다.
따라서 Bloom filter를 고안하여 아래표와 같이 8-gram 상에서 WebText dataset과 test에 사용한 dataset과의 overlapping 비율을 측정하였습니다.
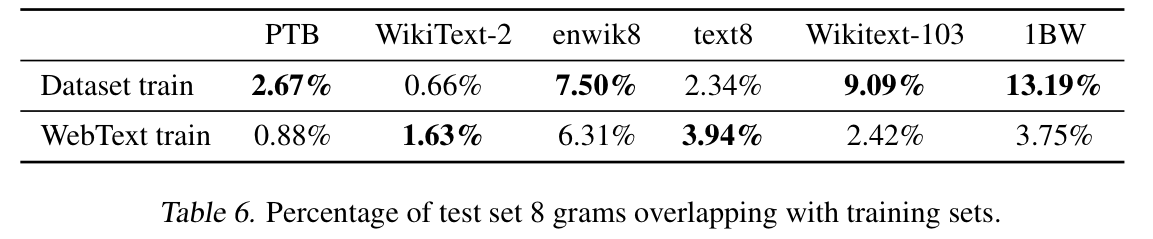
이후 아쉽게도 overlapping에 따른 실험을 보고하지는 않았지만 각 데이터 셋들과의 overlapping을 측정해보았다는 것이 의미가 있는 것 같습니다. 추가적으로 webtext data는 overlapping 비율이 낮기 때문에 generalization 능력이 나쁘지 않다고 주장하고 있습니다.
총평
솔직히 처음 읽었을 때는 그다지 잘썻다거나 좋은 모델이라는 생각을 하지는 않았던 것 같습니다. 새로운 방법론을 제시한건 아니기 때문입니다. 근데 반복해서 읽다보니 unsupervise learing을 적용해서 일반화된 LM에 대한 중요성을 일깨워주었다는 점에서 되게 좋게 느껴졌습니다. 해당 논문의 contribution은 제가 생각하기에는 다음과 같습니다.
- Byte wise BPE tokenizer 제시
- Unsupervised (zero-shot) setting에서의 LM 모델 학습 성능 검증
- Generalization을 위한 학습에 사용될 webtext dataset 제안
읽어주셔서 감사드립니다! LM 논문들은 항상 방법론드이 어려운 건 아니기 때문에 여러개를 읽고 정리해서 포스팅 하는게 좋을 것 같다는 생각이 듭니다...