오늘은 LLM explaination method들에 대한 survery 논문인 Explainability for Large Language Models: A Survey를 리뷰해 보겠습니다.
1. Introduction
최근 LLM의 인기가 급부상한 것 만큼 딥러닝 모델들의 고질적인 문제인 black box 특성에 대한 해결책으로 eXplainable AI (XAI)에 대한 관심이 많아지고 있습니다. 이러한 XAI 방법론들은 다음과 같은 총 2가지 측면에서 중요하다고 할 수 있습니다.
- 사용자의 경우 인공지능 모델에 신뢰를 가질 수 있습니다.
- 개발자나 연구자의 경우 의도하지 않은 bias를 디버깅하는등, 모델의 성능을 높히는데 인사이트를 얻을 수 있습니다.
그러나 LLM들은 일반 딥러닝 모델들보다도 복잡한 구조, 많은 파라미터들 수 때문에 설명하기가 더욱 어렵습니다. 본 논문은 이러한 LLM XAI method들을 설명하고 평가하여봅니다.
2. Training Paradigms of LLMs
LLM들은 downstream task를 수행하기 위해 traditional fine-tuning, prompting과 같은 (어쩌면 둘 다) 학습을 필요로 합니다. 본 섹션에서는 이러한 training method들에 대해 좀 더 자세히 알아봅니다.
2.1 Traditional Fine-Tuining Paradigm
대량의 언어 데이터를 활용해 pre-training하고 특정한 task (일반적으로 supervised task)에 대해 미세조정하는 일반적인 LLM의 학습 방법론을 의미합니다.
2.2 Prompting Paradigm
일반적으로 prompt를 사용한 방법론은 input sentence앞에 task에 관련된 추가적인 prompt를 삽입하여 성능을 높히는 방법론입니다. 이는 아래와 같은 총 2가지 방법론으로 구분될 수 있습니다.
-
Base Model: 추가적인 학습이 필요없이 prompt의 제공만으로 task를 잘 수행해내는 LLM들을 일컫습니다. 수치적으로는 1B이상의 papramter를 가지는 모델들을 말하며 이러한 모델들을 위한 설명은 모델이 가진 사전 지식들을 어떻게 prompt랑 잇는지에 집중합니다.
-
Assistant Model: 위와같은 base model들은 총 2가지 문제점이 있습니다: (1) pre-training data에 instruction-reponse example이 있을 경우 유저의 instruction (prompt)를 따르지 않을 수 있습니다, (2) Base model들은 bais에 영향을 받거나 toxic한 결과를 생성할 수 도 있습니다. (두가지 문제점 모두 대량의 corpus를 학습할 때 안좋은 데이터를 학습했을 가능성 때문인 것 같습니다.) 따라서 이러한 문제점을 해결하고자 인간의 피드백을 통해 fine-tuning 될 수 있으며 대표적으로 prompt를 통한 instruction tuning이나 강화학습을 활용한 Reinforcement Learning from Human Feedback (RLHF)등의 방법론이 있습니다. Fine-tuning과의 차이점을 task에 적합하도록 하는 것이 아닌 인간이 원하는 답변을 유도할 수 있도록 파라미터를 업데이트하는 것에 있습니다. 이러한 모델들을 assistant model, chat assistant등으로 불리며 모델이 이러낭 tuning에 의해 어떠한 것을 학습해냐는 것에 초점이 맞춰집니다.
3. Explanation fro Traditional Fine-Tuning Paradigm
본 섹션에서는 fine-tuned LLM에 사용되는 여러 explanation method에 대해 설명합니다. 특히, local, global-level에서 방법론들을 각각 따로 설명하는데 local은 specific한 input sentence에 대한 설명을 제공하고 global은 모델 그자체에 대한 작동 원리를 설명합니다. 전체적인 overview는 아래 그림과 같습니다.

3.1 Local Explanation
우선 local explanation는 앞서 말씀 드린 것 처럼 input에 dependent한 설명을 의미합니다. 즉, input sentence가 들어오고 sentiment classification, generation등이 진행되었을 때 해당 task에 관해 중요한 input token등을 명확히 하는 시나리오등을 생각해볼 수 있습니다. 이러한 local explanation method들은 아래와 같은 figure와 같이 분류될 수 있습니다.
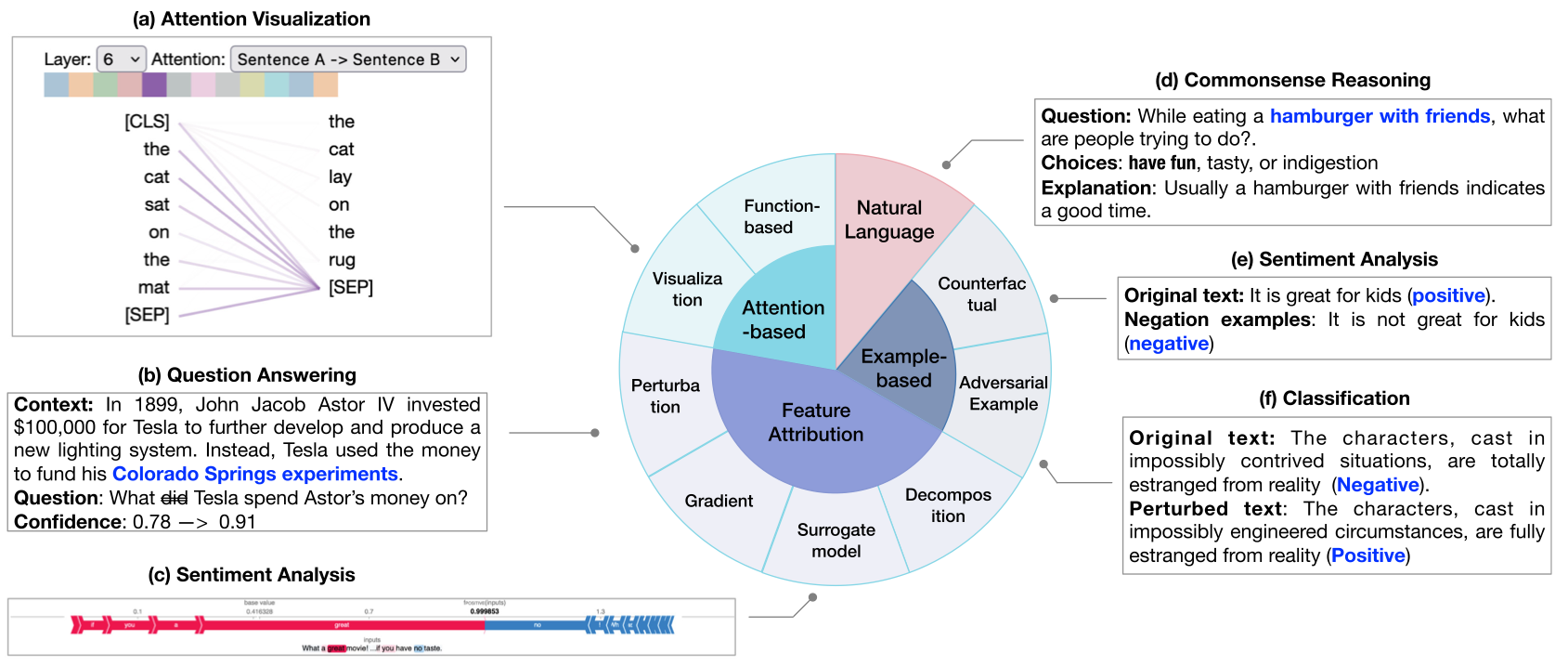
3.1.1 Feature Attribution-Based Explanation
해당 방법론은 input feature (word, token, phrases)에 관한 relevance (importance) score를 할당하는 것이 목적입니다. 즉, word (token) 로 구성된 가 주어져 있을 때 LLM의 output 에 가장 큰 영향을 주는 를 계산함으로써 를 설명으로 제공할 수 있습니다. 또한 이러한 방법론들은 아래와 같이 분류될 수 있습니다.
Perturbation-Based Explanation: 가장 간단한 방법중 하나로 input token을 제거, 마스킹과 같이 변형 시킨후에 output을 관찰하는 방법론 입니다. 만약 특정 토큰들의 제거로 output이 바뀐다면 (classification의 경우 class가 바뀐다면) 해당 토큰들은 LLM의 prediction에 주요한 영향을 주고 있다고 판단한 수 있습니다. 하지만 이러한 방법론들은 input token의 independent함을 가정, 중요도가 아닌 perturbation에 의한 Out-Of-Distribution으로 의한 prediction 변경등의 문제가 있습니다.
Gradient-Based Explanation: 이름에서 알 수 있으시듯이 improtance score를 계산하기 위해 gradient 값을 활용하는 방법론입니다. Output에 대한 input의 gradient는 직관적으로 민감도로 해석되기에 importance score로써 사용하는 것이죠. 가장 간단하게 importance score 로 정의될 수 있습니다. 이외에도 gradient와 input feature들의 값을 곱해 평균을 낸다던가 하는 식으로 사용됩니다. 이러한 방법론도 input이 0이면 importance score가 0이다거나 gradient가 매우 작으면 score 또한 매우작다는 등의 문제점이 있습니다. 따라서 이러한 문제점을 보완한 IG (intergrated gradients)와 같은 방법론들이 등장했습니다.
Surrogate Models: 개인적으로는 얘가 왜 여기 feature-based method들에 껴 있는지는 모르겠습니다. 해당 방법론은 LLM을 근사하는 인간이 이해할 수 있는 모델 (decision Tree, linear regression)등을 활용하여 설명하는 방법론 입니다. 가장 쉽게 예를 들자면 설명 대상이 되는 LLM과 최대한 유사한 성능을 내는 decision tree를 설계하여 대신 설명이 되도록 하는 것이죠. 역시나 해당 방법론 또한 복잡한 LLM을 설명하는 데에는 부적절해보입니다. 대표적으로 LIME이 있습니다.
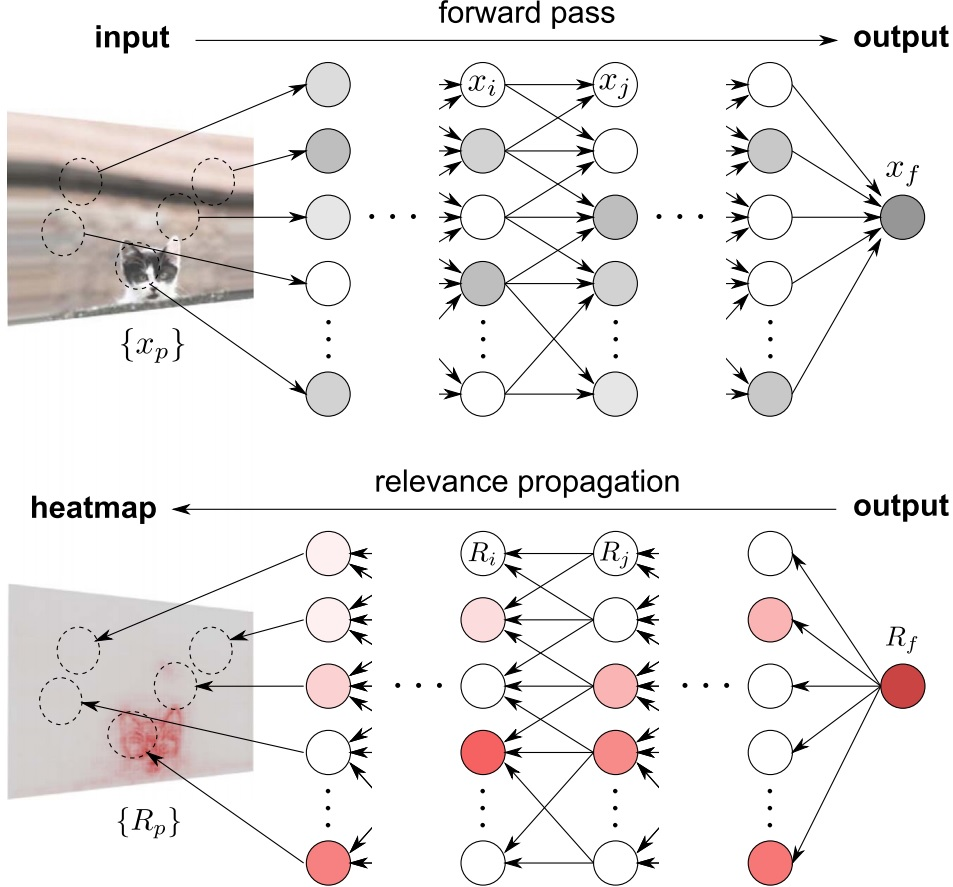
Decomposition-Based Methods: 해당 방법론은 output에서 부터 input까지 뉴런단위로 relevance score (importance score)를 분해하며 부여하는 방법론입니다. 즉, Output에서 input까지 일정한 방식에 따라 중요도를 분해시켜 부여한 뒤 input의 중요도 순으로 설명을 제공하는 방법론입니다. 대표적으로 Layer-wise relevance propagation (LRP)가 있습니다 (아래 그림 참조). 해당 방법론에서는 layer 단위로 비선형성에 영향을 주는 activation function별로 rule을 두어 relevance score를 다음 뉴런에 부여했던 것으로 기억합니다. 또한 Taylor-type decomposition (DTD) 또한 존재하는데 해당 방법론은 LRP에서 사용한 rule이 아닌 테일러 급수를 사용한 근사를 통해 relevance score를 다음 뉴런에게 부여하는 방법론으로 기억합니다.
3.1.2 Attention-Based Explanation
Attention model은 그 자체로 각각의 토큰 임베딩에 관해 영향을 많이 주는 토큰들을 확인할 수 있게 함으로써 어느정도의 설명력을 가지고 있습니다. 해당 섹션에서는 이러한 attention based method들에 대한 설명에 대해 서술합니다.
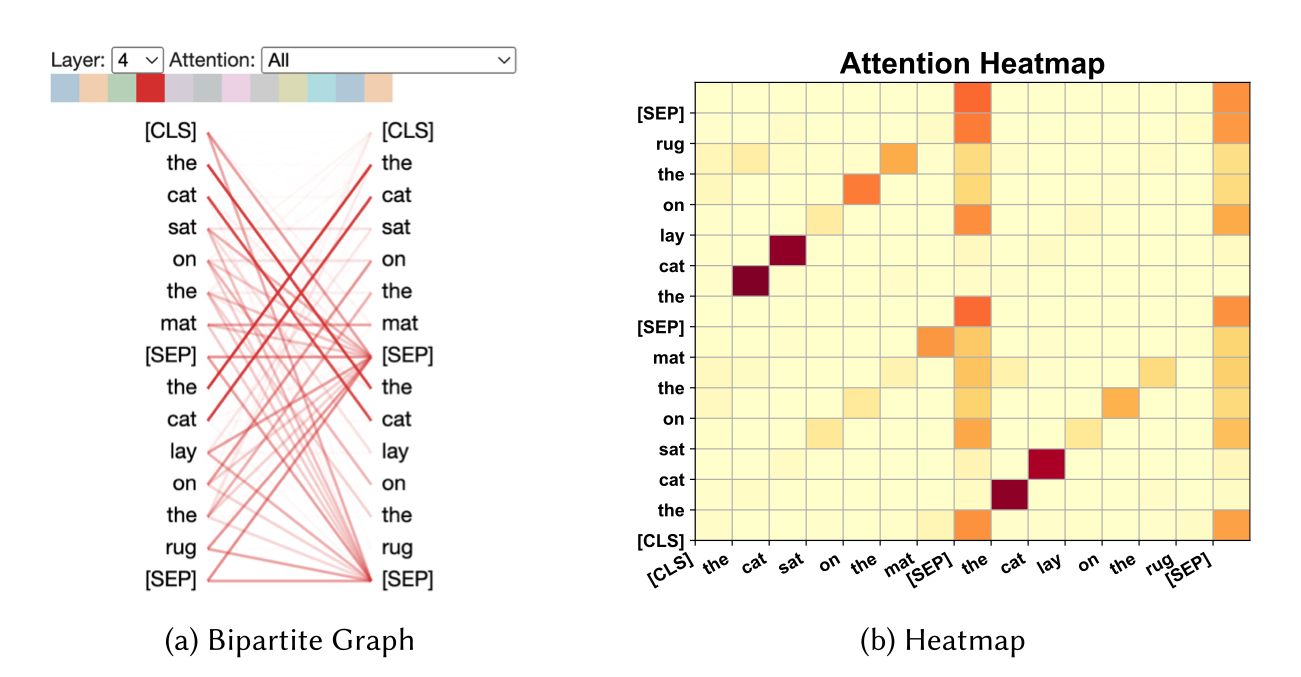
Visualization: 딱히 특별한 것은 없고 아래 그림과 같이 attention score를 시각화하여 설명을 제공하는 방법입니다.
Function-Based Methods: Attention score이외의 importance에 영향을 주는 추가적인 function을 정의하여 설명에 함께 사용하는 방법론입니다. 주로 gradient 등을 추가적으로 사용하여 attention score와의 곱을 통해 설명을 제공하는 식으로 사용된다고 합니다.
3.1.3 Example-Based Explanations
해당 방법론들은 모델에 영향을 주는 specific한 input example을 설명으로써 사용합니다.
Adversarial Example: 딥러닝 모델들이 인간이 알아챌 수 도 없는 input의 작은 변화에도 민감하게 반응할 때가 있습니다. Adversarial example은 민감한 영향을 줄 수 있는 의도적으로 생성된 sample들을 의미하며, training data에 첨가됨으로써 LLM 모델의 견고함이나 정확도를 상승시킬 수 있습니다. 근데 이게 설명 방법론이랑 뭔 상관...
Counterfactual Explanation: 간단하게 model의 prediction 변화에 영향을 주는 input 내의 counterfactual한 word, sentence등을 설명으로 제공하는 방법론을 의미합니다.
3.1.4 Natural Language Explanation
해당 방법론은 LLM model에 사용한 training data와 인간이 annotation한 설명을 또 다른 언어 모델에 학습시켜 설명이 가능한 모델을 제공합니다. 하지만 제 생각에는 이는 설명을 위한 또 다른 모델을 학습한 것이지 설명 대상 모델을 올바르게 설명하는 방법론이라고는 생각하지 않습니다.
3.2 Global Explanation
Global Explanation이란 local explanation과는 다르게 input에 dependent한 설명을 제공하는 것이 아닌 LLM 모델 자체의 동작 원리나, 보유하고 있는 지식들을 설명으로 제공하길 원하는 방법론입니다. 이는 크게 아래와 같이 4가지 정도로 분류될 수 있습니다.
3.2.1 Probing-Based Explanation
해당 방법론은 LLM이 보유하고 있는 지식들을 설명으로 제공합니다.
Classifier-Based Probing: 해당 방법론은 이미 학습되어 있는 LLM의 parameter를 frozen하고 그 위에 얉은 classifier를 얹어 학습시키는 것으로 LLM이 보유하고 있는 지식등을 포착합니다. 또한 이때 classifier는 LLM의 특정한 능력 (품사 맞추기, resoning)과 관련된 task를 수행하도록 학습됩니다.
Parameter-Free Probing: 해당 방법론은 딱히 얉은 classfier를 사용하지 않고 zero-shot setting에서 LLM의 능력을 검증하기 위해 의도된 특정한 task (grammer, Sentiment analysis)들을 통해 LLM이 보유한 지식을 검증하는 방법론들입니다.
3.2.2 Neuron Activation Explanation
model performance와 같은 것에 크게 영향을 주는 neuron (dimension)을 찾아 설명으로 제공하는 방법론이며 크게 2가지 단계로 진행됩니다: 1. unsupervised 방식으로 중요한 neuron을 알아냅니다, 2. supervised setting에서 뉴런과 linguistic property의 관계를 알아냅니다. 즉, 특정한 linguistic property에 관해 중요한 영향을 주는 neuron들을 찾아냄으로써 설명을 제공하는 방법론이라 할 수 있습니다. 사실 제가 한번도 다뤄본적이 없는 방법론이라 읽어봐도 잘 모르겠습니다 ...
3.2.3 Concept-Based Explanation
해당 방법론은 input을 사전 정의된 concept들에 맵핑 시킨 후 모델 prediction에 대한 각 concept의 중요도를 확인하는 방법론입니다.
3.2.4 Mechanistic Interpretability
해당 방법론은 진짜 도저히 이해할 수가 없습니다. 죄송합니다...
3.3 Making Use of Explanations
이번 섹션에서는 앞서 설명된 설명 방법론들이 어떻게 사용될 수 있을지에 대해 서술합니다.
3.3.1 Debugging Models
Explanation method들은 LLM을 디버깅하는데 사용될 수 있습니다. 예를들어 explanation method를 통해 LLM의 prediction에 대한 설명을 봤는데 만약 input과 관계 없이 특정한 몇몇개의 token에만 집중하고 있다면 이는 input 전체의 context를 반영하고 있지 않다는 뜻입니다.
3.3.2 Improving Models
설명을 사용한 regularization technique은 모델의 preformance와 reliability를 상승시키는데 사용될 수 있습니다. Explanation Regularization (ER) 방법론은 모델의 추론 과정을 인간의 추론과 일치 시키도록 함으로써 LLM의 일반화 성능을 상승시킵니다. 예를들어 AMPLIFY라는 프레임워크는 post-hoc explanation method를 사용하여 input의로 인해 추론될 수 있는 내용을 자동으로 생성합니다. 이렇게 생성된 추론은 다시 LLM의 input으로 투입됨으로써 특정 task들에 대한 성능을 크게 증가시킵니다.
4. Explanation for Prompting Paradigm
고전적인 explanation method들은 fine-tuning된 LLM을 설명하는데 집중하기 때문에 prompt tuning을 통해 성능이 상승된 LLM에 적용하기 어려울 수 있습니다. 따라서 본 섹션에서는 위에서 언급한 방법론들이 아닌 propting tuning을 통해 학습 혹은 성능이 높아진 LLM을 위한 방법론들에 대해서 서술합니다.
4.1 Base Model Explanation
Base model의 설명은 prompt가 LLM의 prediction에 어떠한 영향을 주는지에 초점이 맞춰져 있습니다.
4.1.1 Explaining in-context Learning
In-context learning은 별도의 파라미터 업데이트 없이 유저가 입력한 prompt를 활용하여 (몇개의 예시들에 대해서 label이 존재) LLM이 더 좋은 답변 혹은 더욱 task를 잘 수행해내도록 하는 방법론입니다. 일종의 Prompt-tuning이라고 생각합니다. 최근 한 연구 아래와 같이 여러 상태의 in-context prompt로 부터 saliency map을 관찰하여 in-context learning이 효과가 있는지를 검증하였습니다. 검증 결과, 비교적 작은 모델 (GPT2)보다 큰 모델 (ChatGPT, InstructGPT)등에서 in-context learning의 효율성이 높다는 것을 입증하였습니다.
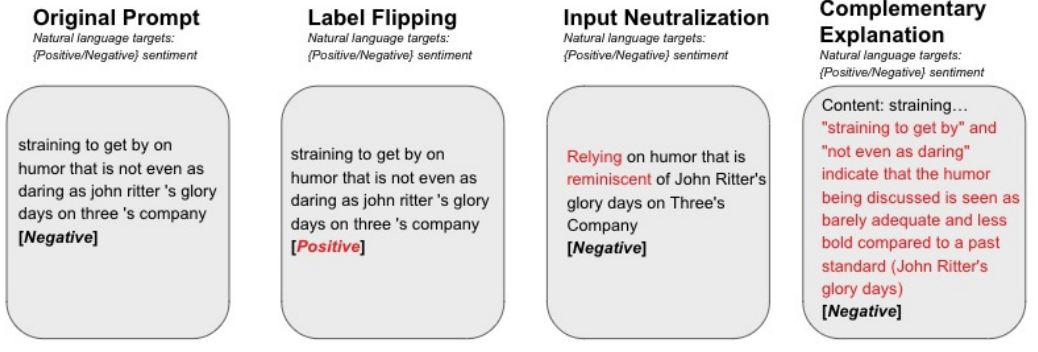
4.1.2 Explaining CoT Prompting
CoT (Chain of Thought) Prompting은 in-context learning과 마찬가지로 prompt 상의 내용을 활용하여 LLM의 성능을 높히는 방법을 의미합니다. 다만 In-context learning은 예시에 따른 label에 초점이 맞춰져 있다면 CoT prompting은 아래와 같이 추론 과정을 설명하는 것에 초점이 맞춰져 있습니다. 이경우 또한 saliency map을 활용하여 prompt 내용에 따른 각 토큰의 중요도를 판별해 보았을 때 CoT Prompting의 효용성을 입증했다고 합니다.
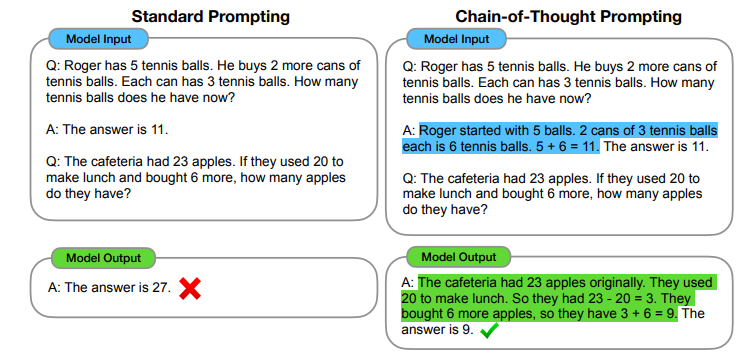
4.1.3 Representation Engineering
Prompt 내용에 따른 각 토큰의 중요도를 보았던 앞선 방법들과는 다르게 representation engineering은 모델의 구조와 representation vector 관점에서 모델을 설명하기 원합니다. Representation을 분석하는 것으로 LLM이 이해하고 있는 high level의 concept들을 이해할 수 있습니다. 이후의 내용은 사실 잘 이해하지를 못했습니다. 관련된 논문을 읽어보고 추가할 수 있도록 하겠습니다.
4.2 Assistant Model Explanation
4.2.1 Explaining the Role of Fine-tuning
Assistant model은 일반적인 pre-training 과정과 supervised, 강화 학습을 통한 fine-tuning 과정을 포함합니다. 이러한 학습은 task와 user들의 선호에 맞는 언어 능력을 갖출 수 있도록 합니다. 따라서 설명은 LLM이 pre-training을 통해 충분히 일반적인 지식을 학습했는지, fine-tuning을 통해 specific한 task나 user의 선호에 맞는 지식을 습득했는지에 관해 집중합니다.
최근 연구에서는 pre-training과 instruction fine-tuning 이후의 input token들의 중요도를 분석하였습니다. 해당 연구는 instruction tuning은 단지 답변시 style이나 format을 학습하는 것이고 대부분의 지식은 pre-training으로 부터 오는 것이라는 가설을 세웠습니다. 실험 결과 fine-tuning이나 reinforcement learning이 믿어왔던 것보다는 덜 중요하다는 사실을 밝혀냈습니다. 또한 instruction fine-tuning시 data의 양보다는 quality가 중요하다는 것을 밝혀냈습니다. 다른 연구들도 이와 비슷한 양상을 띄었습니다. 즉, LLM의 사전 지식들은 pre-training 과정에서 습득되며, instruction-tuning은 user에게 적합한 형태의 결과를 제공할 수 있도록 합니다.
4.2.2 Explaining Hallucination
Hallucination이란 LLM이 전혀 상관없는 혹은 잘못된 내용은 답변으로 제공하는 것을 의미합니다. 이러한 hallunation의 원인은 주로 (1) 상관없는, 혹은 잘못된 데이터 (2) 반복된 데이터로 부터 온다고 믿어져 왔습니다.
또한 최근 연구는 hallucination이 모델에 내재적인 한계점으로 부터 발생한다는 주장을 하기도 했습니다. LLM은 여전히 sentence-level에서 학습하기 때문에 resoning이 약할 수 밖에 없다는 주장입니다.
이러한 hallucination을 해결하기 위한 몇가지 방법이 있습니다. 첫번째는 역시 scailing-up입니다. 더 많은 파라미터는 LLM의 memorization 성능을 높히기 때문입니다. 또한 근본적으로 질 좋은 데이터 셋 자체를 구성하는 것 또한 hallucination을 줄이는 방법중 하나입니다.
4.2.3 Uncertainty Quanification
최근 LLM의 신뢰성이나 한계들을 좀 더 잘 이해하기 위해 uncertainty를 정량화하는 것이 주목을 받고 있습니다.
첫번째로 model이 생성하는 답변들의 consistency를 측정하는 방법이 있습니다. 조금 변경된 질문에 대해 일정한 답변을 내놓는 것은 LLM의 신뢰성에 큰 영향을 줍니다. 두번째로 두번째로 LLM 자체가 내놓은 confidence를 측정하는 방법입니다. 마지막으로 생선된 token에 대한 prediction 확률을 평균내어 confidence로 사용하는 방법입니다.
4.3 Making Use of Explanations
해당 섹션에서는 prompting-based LLM에 사용되는 설명 방법론 혹은 설명들의 활용방안에 대해 서술합니다.
4.3.1 Improving LLMs
다양한 연구들은 pre-explanation (CoT, In-context learning) 혹은 post-explanation이 LLM의 성능을 높힐 수 있는지에 관해 연구했습니다. 이러한 연구들은 설명을 통해 prompting 혹은 fine-tuning하는 것이 LLM의 성능을 높힐 수 있지만 여전히 pre-training이나 설명 퀄리티에 많이 의존하고 있다는 것을 밝혀냈습니다.
사실 개인적으로 설명 방법론들이 LLM에 적용되어 성능을 높히는 방안에 대해 서술되기를 바랬는데 그보다는 다양한 prompting을 통해 LLM 자체의 성능을 높히는데 집중하고 있는 것 같습니다. 아쉽습니다.
4.3.2 Downstream Applications
Explanation method는 medical과 같은 분야에서 사용될 수 있습니다. 최근 한 image classification에 대해서 CLIP같은 vision-text multimodal model을 통해 image에 대한 설명을 추출하여 함께 제공하는 framework를 제안하였습니다.
Conclusion
Section 4이후의 내용들은 설명 방법론 혹은 제공된 설명에 대한 평가와 이러한 연구들에 대한 어려움을 서술하고 있습니다. 제 생각에 별로 critical 내용은 없으므로 패스하려고 합니다.
사실 저는 GNN에서 explnation method들을 연구한 만큼 LLM 자체를 설명하기 위한 방법론들을 알고싶어 논문을 읽기는 했습니다만 원하는 것은 얻지 못했습니다. 논문 내용이 전반적으로 LLM 자체를 설명하기 위한 방법론들 보다는 LLM이 내놓은 답변 자체를 설명으로 사용하는 내용에 좀 더 집중하고 있었기 때문입니다. 그래도 설명 방법론 혹은 LLM을 통한 설명이 어떻게 쓰일 수 있는지에 대해서 알 수 있었던 것은 좋았던 것 같습니다.