
객체지향을 공부하다 보면 한 번씩은 듣게 되는 SOLID 원칙은 객체지향 설계 5원칙이라고도 불리며, 각 원칙의 앞 글자를 따서 만들어졌다. 객체지향 설계의 핵심 중 하나는 의존성을 관리하는 것인데, 의존성을 잘 관리하기 위해서는 SOLID 원칙을 준수해야 한다.
⛳️ 단일 책임의 원칙(Single Responsibilty Principle)
객체는 한 가지 역할만 가져야 한다는 원칙이다.쉽게 말해, 객체가 변경되는 이유는 단 한 가지여야 한다는 것이다. 근데 역할과 책임이 변경이랑 어떤 관계가 있길래 그럴까? “객체 하나가 이것저것 다 할 수 있으면 좋은거 아닌가, 왜 분리하는거지?” 라는 생각이 들었다. 결론부터 말하자면, 바로 책임이“변경의 축”이기 때문이다. 요구사항의 변경이 일어났을 때 보통 책임을 변경함으로써 반영하려고 한다. 여기서책임이란 단순히 메서드의 개수를 뜻하지 않고, 특정 사용자나 기능 요구사항에 따라 소프트웨어의 변경 요청을 처리하는 역할을 의미한다.
근데 이때 한 개의 객체가 책임을 너무 많이 가지고 있다면 어떤 일이 일어날까? 일단 클래스 자체가 매우 커지고, 책임 간의 결합도 역시 높아져서 한 개의 책임이 변했을 때 다른 책임도 변하는 연쇄적인 변화가 발생하게 된다. 예를 들어, 어떤 클래스 내에 메서드 A가 있다고 해보자. 메서드 A는 메서드 A의 결과를 기반으로 메서드 B 를 호출하고, 메서드 B 는 메서드 B 의 결과를 기반으로 메서드 C 를 호출하도록 구현이 되어 있다면? 만약 메서드 A의 동작이 일부 수정된다고 한다면, 메서드 B, 메서드 C 모두 변경해야 할 상황이 발생할 수 있다. 이러면 유지보수가 매우 비효율적인 것이므로 이들을 모두 분리할 필요가 있는 것이다.
추상화(Interface)를 통해서 객체를 설계하는 과정에서 적절한 한 개의 역할만 갖도록 구상해주면 된다. 근데 사람은 책임을 묶어서 생각하는 경향이 있기 때문에 생각보다 쉽지 않다. 책임의 분배에는 정답이 있는 것이 아니기 때문에 애플리케이션 설계 사항에 따라, 잘 분리할 수 있도록 경험이 쌓이는 것이 중요하다.
<SRP 원칙 예시 코드>
class Employee {
private String name;
private int salary;
public Employee(String name, int salary) {
this.name = name;
this.salary = salary;
}
// 사원 정보 관련
public String getName() {
return name;
}
public int getSalary() {
return salary;
}
// 급여 계산 관련
public int calculateAnnualSalary() {
return salary * 12;
}
// DB 저장 관련
public void saveToDatabase() {
System.out.println("Saving " + name + " to database...");
}
}
보다시피, Employee 클래스가 3가지 책임을 동시에 수행하고 있다. SRP 원칙을 위반한 것이다. Employee 클래스는 사원 정보만 관리하도록 한 가지 역할만 갖도록 수정할 필요가 있다.
class Employee {
private String name;
private int salary;
public Employee(String name, int salary) {
this.name = name;
this.salary = salary;
}
public String getName() { return name; }
public int getSalary() { return salary; }
}
급여 계산과 데이터 저장은 별도 클래스로 빼주자.
// 급여 계산 클래스
class SalaryCalculator {
public int calculateAnnualSalary(Employee employee) {
return employee.getSalary() * 12;
}
}
// 데이터 저장 클래스
class EmployeeRepository {
public void save(Employee employee) {
System.out.println("Saving " + employee.getName() + " to database...");
}
}🐳 개방 폐쇄 원칙(Open-Closed Principle)
"객체는 확장에 열려있고, 변경에는 닫혀있어야 한다는 원칙이다."
확장에 열려있다: 모듈의 확장성을 보장하는 것이다. 새로운 변경 사항이 발생했을 때 유연하게 코드를 추가함으로써 애플리케이션의 기능을 큰 힘을 들이지 않고 확장할 수 있다.변경에 닫혀있다: 객체를 직접적으로 수정하는 것은 제한해야 한다는 것이다. 새로운 변경 사항이 발생했을 때 객체를 직접적으로 수정해야 한다면 큰 부담이 될 것이다.
쉽게 말해, 기능 추가 요청이 오면 클래스를 확장을 통해 손쉽게 구현하면서, 확장에 따른 클래스 수정은 최소화 하도록 프로그램을 작성해야 한다는 것이다.
<OCP 원칙 예시 코드>
class NotificationSender {
public void sendNotification(String type, String message) {
if (type.equals("email")) {
System.out.println("Sending EMAIL: " + message);
} else if (type.equals("sms")) {
System.out.println("Sending SMS: " + message);
} else if (type.equals("push")) {
System.out.println("Sending PUSH: " + message);
}
}
}위의 코드에서 알림 방식이 추가될 때마다 sendNotification() 메서드를 수정해야 한다.
// 알림 전송을 위한 인터페이스
interface Notification {
void send(String message);
}
// Email 알림
class EmailNotification implements Notification {
public void send(String message) {
System.out.println("Sending EMAIL: " + message);
}
}
// SMS 알림
class SmsNotification implements Notification {
public void send(String message) {
System.out.println("Sending SMS: " + message);
}
}
// 확장 가능한 알림 전송기
class NotificationSender {
public void send(Notification notification, String message) {
notification.send(message);
}
}
// 사용 예시
public class Main {
public static void main(String[] args) {
NotificationSender sender = new NotificationSender();
sender.send(new EmailNotification(), "Hello via Email!");
sender.send(new SmsNotification(), "Hello via SMS!");
sender.send(new PushNotification(), "Hello via Push!");
}
}리팩토링한 코드를 살펴보면, 새 알림 방식을 추가해도 기존 NotificationSender는 절대 수정할 필요가 없어진다. 이처럼 인터페이스 기반 설계로 OCP를 준수하도록 하면 된다.
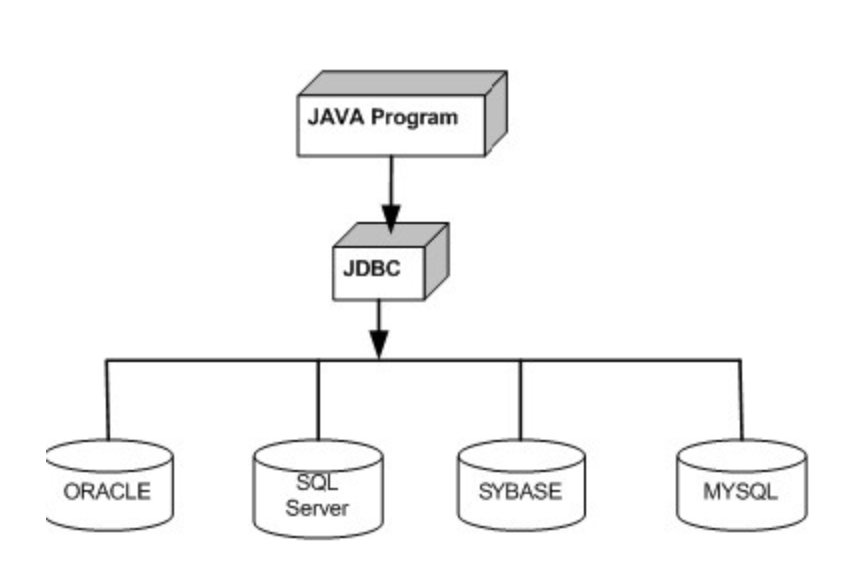
OCP 원칙을 가장 잘 따르는 예시가 바로 자바의 데이터베이스 인터페이스인 JDBC이다. 만약 자바 애플리케이션에서 사용하고 있는 데이터베이스를 MySQL에서 Oracle로 바꾸고 싶다면, 단지 connection 객체 부분만 교체해주면 되는 것이다. 즉, 자바 애플리케이션은 데이터베이스라고 하는 주변의 변화에 닫혀 있는 것이다. 반대로 데이터베이스를 손쉽게 교체한다는 것은 데이터베이스가 자신의 확장에는 열려 있다는 말이 된다.
🔀 리스코브 치환 원칙(Liskov Substitution Principle)
서브 타입은 자신의 기반(부모) 타입으로 교체할 수 있어야 한다는 것이다.다른 말로, 하위 클래스가 상위 클래스로 바뀌어도 역할 수행에 문제가 없어야 한다는 것이고, 서브 타입은 기반 타입이 정해둔 약속을 지켜야 한다는 것이다. 따라서 기본적으로 LSP 원칙은 부모 메서드의 오버라이딩을 조심스럽게 따져가며 해야 한다.
결국은, 리스코프 치환 원칙을 지키지 않으면 개방 폐쇄 원칙을 위반하게 되는 것이다. 앞서 살펴봤듯이, 개방 폐쇄의 원칙은 추상화를 의존하고 이를 상속을 통해 확장할 수 있었다. 리스코프 치환의 원칙은 규약이 준수된 상속 구조를 보장해주는 원칙이다. 따라서 이게 깨져서 기반 타입으로의 대체가 힘들다면 아무리 확장을 해봤자 적절한 역할의 수행이 어렵기 때문에 개방 폐쇄의 원칙 또한 위배되게 될 것이다.
LSP의 예시로, 자바의 Collection 인터페이스를 들 수 있다. Collection 타입의 객체에서 자료형을 ArrayList에서 전혀 다른 자료형 TreeSet으로 바꿔도 add() 메서드를 실행하는데 있어서 원래 의도대로 작동되기 때문이다. 쉽게 말해, 다형성 이용을 위해 부모 타입으로 메서드를 실행해도 의도대로 실행되도록 구성을 해줘야 하는 원칙이라고 이해하면 된다.
<LSP 원칙 코드 예시>
public class MyCollectionApp {
public static void main(String[] args) {
Collection<String> names = new ArrayList<>();
names.add("Alice");
names.add("Bob");
processCollection(names);
names = new TreeSet<>();
names.add("Charlie");
names.add("Dave");
processCollection(names);
}
public static void processCollection(Collection<String> items) {
for (String item : items) {
System.out.println("Item: " + item);
}
}
}
위의 코드처럼, ArrayList, TreeSet, LinkedList 어떤 구현체라도 Collection을 따르기만 하면 정상 동작한다. “하위 클래스는 상위 클래스다. 구현 클래스는 인터페이스 할 수 있어야 한다.” 이 두 가지만 잘 지켜진다면 문제 없다.
🗂️ 인터페이스 분리 원칙(Interface Segregation Principle)
인터페이스는 자신의 클라이언트가 사용할 메서드만 가지고 있어야 한다.즉, 클라이언트 입장에서 생각해보자면, 내가 쓰지 않을 메서드에 대해서는 알고 싶지 않다는 것이다.
“인터페이스가 커지면 할 수 있는 일이 많아져서 좋은거 아닌가?” 사실은 그렇지 않다. 같은 인터페이스를 구현하는 클라이언트 간의 결합도가 높아져서 문제가 발생한다. 결합도가 높아지면 클라이언트 A를 위한 메서드가 추가됐을 때, 그 메서드를 사용하지 않을 다른 클라이언트들도 구현이 강제되게 되고, 클라이언트 A에서 변화가 발생하면 다른 클라이언트도 변경되는 연쇄적인 문제가 발생할 수 있다.
자신의 클라이언트가 필요로 하는 함수만 선언해주면 된다. 즉, 인터페이스의 역할에 충실한 기능만 제공해주면 된다는 말이다. 인터페이스는 무언가를 하도록 만들기 위해 구현하는 것이다. 따라서 가능하게 만들기 위해 필요한 기능들만 제공하면 되는 것이다. 이렇게 함으로써 클라이언트는 내가 필요한 메서드에만 자연스럽게 의존할 수 있다.
<ISP 원칙 예시 코드>
interface Worker {
void work();
void eat();
void sleep();
}
class Robot implements Worker {
public void work() {
System.out.println("Robot working...");
}
public void eat() {
// 로봇은 먹지 않는다.
throw new UnsupportedOperationException("Robot doesn't eat");
}
public void sleep() {
// 로봇은 자지도 않는다.
throw new UnsupportedOperationException("Robot doesn't sleep");
}
}
위의 코드처럼, Robot 클래스는 eat()와 sleep()을 필요하지 않지만 구현해야 하는 문제가 있다. 불필요한 의존, 즉 ISP 원칙을 위반한 것이다. 코드를 리팩토링 해보자.
// 인터페이스 분리
interface Workable {
void work();
}
interface Eatable {
void eat();
}
interface Sleepable {
void sleep();
}// 각 객체에 맞게 구현
class Human implements Workable, Eatable, Sleepable {
public void work() {
System.out.println("Human working...");
}
public void eat() {
System.out.println("Human eating...");
}
public void sleep() {
System.out.println("Human sleeping...");
}
}
class Robot implements Workable {
public void work() {
System.out.println("Robot working...");
}
}🙃 의존성 역전 원칙(Dependency Inversion Principle)
구체적인 것이 추상화된 것에 의존해야 한다는 원칙이다.쉽게 말해, 자주 변경되는 것에 의존하지 말라는 의미다.
상위 객체는 보통 애플리케이션의 본질을 담고 정책을 결정하는 역할을 한다. 이때 하위 수준의 객체에 의존하고 있다면, 하위의 변화가 상위에 영향을 주게 된다. 난 추상화를 자유롭게 재사용하기를 원한다. 특정 맥락에 따라 변경해서 사용하기를 원하는데, 상위 객체가 구체적인 것을 알고 있다면 맥락에 맞춰 변경할 수 없을 것이다. 즉, 추상화가 구체적인 것에 의존한다면, 추상화를 자유롭게 재사용 할 수 없게 되기 때문에 의존성 역전 원칙을 지키는 것이 좋다. “의존성은 이행적이다.” 라는 말이 있다. 한 레이어는 의존하고 있는 다른 레이어에도 의존하게 된다는 것이다.
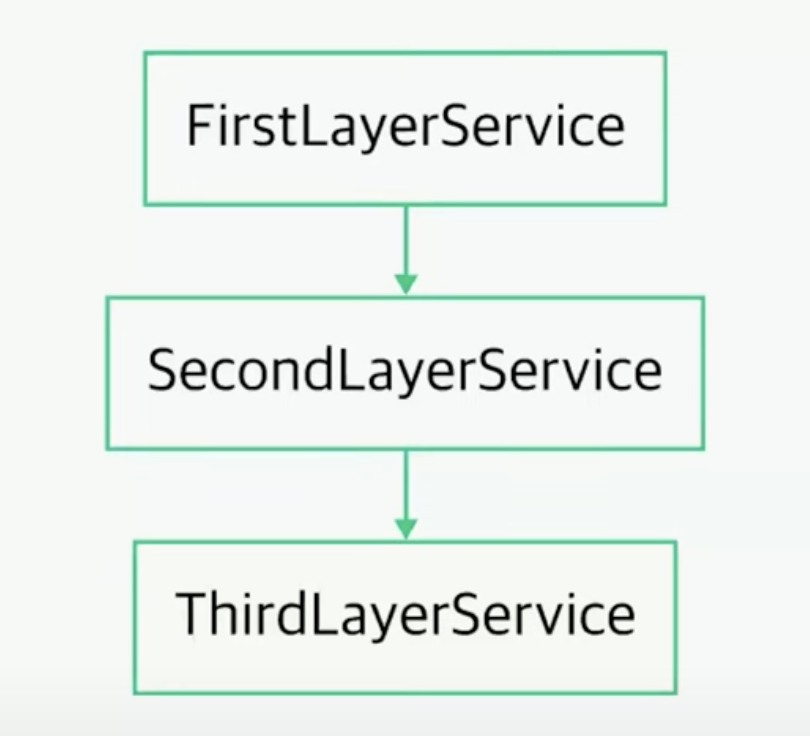
위와 같이, 상위 수준이 하위 수준에 의존하고 있는 구조를 살펴보면, 의존성이 아래로 타고 타고 내려갈 것이다. 따라서 마지막 레이어에 변화가 생길 때, 변화 역시 연쇄적으로 타고 올라가면서 발생하게 된다.
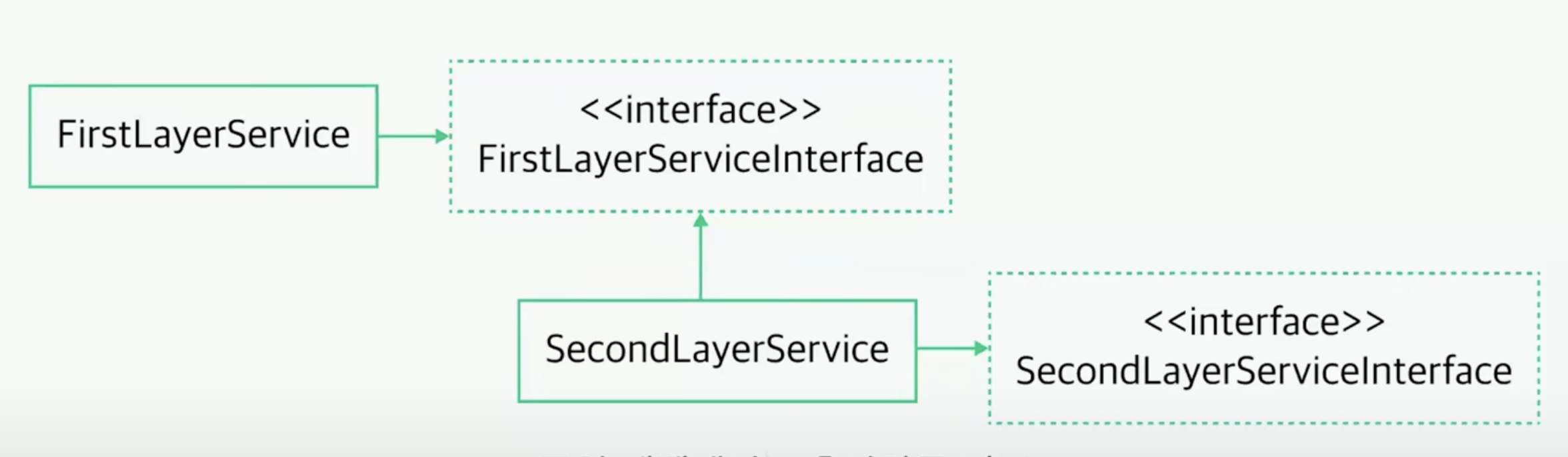
그러면 위와 같이 의존성 역전의 원칙을 잘 지킨 구조는 어떨까? 동일 레벨에서 구체적인 것이 아닌 추상화를 의존하고, 구체적인 것은 하위 레벨로 내려서 상위 레벨에 의존하게 만드는 것이다. 이런 식으로 의존 관계를 역전한다면, 하위 레벨에서 어떤 변화가 생겨도 타고 올라올 일도 없고, 해당 추상화를 자유롭게 재사용할 수 있을 것이다.
