안녕하세요! 최근 패스트 캠퍼스에서 추천시스템 강의(The RED : 현실 데이터를 활용한 추천시스템 구현)를 듣고 있어 이에 대한 내용을 간략하게 공유하고, 스스로도 정리해보고자 이 포스트를 게시하게 되었습니다. 추천 시스템에 대해 잘 모르신다면 이 강의 정말로 추천드립니다...! 물론 너무 강의에서 공개하는 자료나 실습내용까지는 공개하지 않습니다. 패스트 캠퍼스에서 몇몇 강의를 들으며 실망도 많이 했지만..그와중에 풍부한 내용이 있는 강의입니다. 저는 통계학과 관련된 공부만을 하였기 때문에 추천시스템을 직접적으로는 공부해볼 기회가 적었는데, 직접공부를 해보며 여러 관점의 추천시스템들을 살펴 볼 수 있었습니다!
현재 계속 수강중이며 내용은 계속해서 추가하겠습니다!
1. 추천시스템 개요
추천이란 사전적의미로 어떠한 조건에서 적합한 대상을 책임지고 소개함을 말하는 명사입니다. 추천시스템은 이러한 사전적의미와 같이 적합한 대상을 소개하는 시스템인데요! 사용자의 취향이나 선호도, 상황 등을 고려해보거나 로그수준의 데이터에서 사용자들의 행동을 변수로 이용하여 추천을 진행 할 수 있습니다.

실제로 아마존의 경우 매출의 35%가 추천을 통한 매출이고, 넷플릭스의 경우 대여되는 영화의 66% 정도가 추천을 통한 대여라고 합니다. 또한 구글 뉴스에서는 38% 이상의 조회수가 추천을 통해 이루어진다고 합니다.
추천시스템을 얘기할 때 검색과 추천의 비교는 자주 등장하는 주제인데요! 검색은 키워드를 통해 사용자의 의도를 파악 할 수 있는데에서 시작하지만 추천은 그렇지 못한 상황에서 사용자에게 적절한 컨텐츠를 추천해 주는 것이라고 볼 수 있습니다.
1.2. 추천시스템 분류
추천시스템은 요건, 데이터, 모형, 계량방식 등에 따라 여러가지 분류가 가능합니다. 실제로 추천시스템을 구축할 경우 각 요건, 데이터, 모형, 계량방식에 맞추어보고 이에 따라 유연하게 구축해야 할 것으로 보입니다.
1.2.1. 추천 요건
-
Best: 특정 카테고리에서 가장 많이 선호되는 아이템을 추천하며, 가장 대표적인 예로 베스트셀러가 Best 추천입니다.
- 이력이 없는 신규사용자에게 추천 가능하며, 추천 결과가 없는 경우 추천 결과 보완가능
-
Related: 특정 아이템이 주어졌을 때 아이템간의 유사도를 기반으로하여 높은 유사도를 가지는 아이템을 추천하는 것으로, 예를 들면 장바구니에 상품을 담았을 때 여러 추천목록이 표시되는 것이 대표적인 예로 볼 수 있습니다.
- 대체재 추천: 대체관계에 있는 제품들을 추천, e.g. 서로 다른 브랜드, 모델의 스마트폰
- 보완재 추천: 보완관계에 있는 제품들을 추천, e.g. 아이패드와 애플 펜슬
-
Personalized: 특정 유저에 대해 추천하여 주는 것으로 사용자의 아이템 선호도를 예측하고, 예측된 선호도를 바탕으로 맞춤추천을 제공하는 것입니다.
- 사용자 별 세밀한 추천이 가능한 방법이지만, 사용자의 이용 내역데이터가 부족한 경우 좋은 결과를 기대하기 어려움
-
Context Aware: 특정 상황에 대해 추천하는 것으로 상황과 아이템 유사도를 고려하여 높은 유사도를 가진 아이템을 추천합니다. 예를 들면 비오는날에 비오는날 듣기 좋은 음악을 추천해 주는 것들이라고 볼 수 있습니다!
1.2.2. Feedback 데이터에 따른 분류
-
Explicit: 사용자의 아이템에 대한 명확한 선호 정보를 가진 이력
- 예를 들면 OTT에 가입할 때 선호하는 영화를 조사하고 이에 대한 선호도를 측정하거나 사용 중에 컨텐츠에 대한 피드백으로 별점을 체크하는 것이 Explicit Feedback 입니다.
-
Implicit: 아이템에 대한 암시적인 선호 정보를 가진 이력
- 사용자의 구매내역이나 log데이터에서 확인되는 행동패턴 등이 Implicit Feedback이라고 볼 수 있습니다.
당연하게도 Explicit Feedback이 더욱 명확한 정보를 가지고 있으나 데이터 수집이 어려우며, Implicit Feedback의 경우 아이템에 대한 선호도 정보고 모호하다는 상호 보완적인 관계에 있습니다!
1.2.3. 모델에 따른 분류
추천시스템은 아이템 속성을 이용하거나 사용자의 행동 이력 등을 이용하여
아이템 인기도, 아이템-아이템 유사도, 사용자-아이템 선호도, 사용자-사용자 유사도 등을 측정/예측 하고 여러 요건에 맞는 추천을
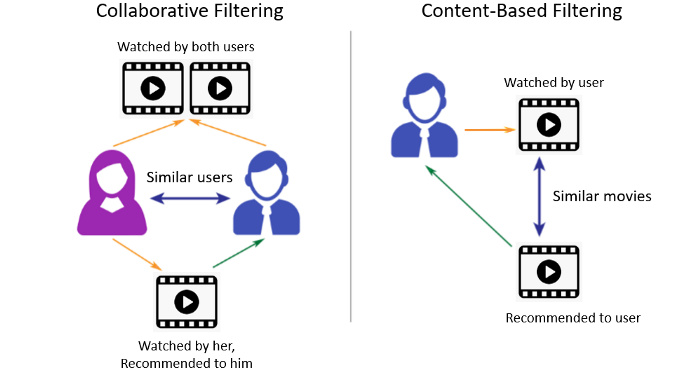
-
CBF(Content-based Filtering): 아이템 속성을 이용한 추천으로 다른 사용자들의 행동이력을 사용하지 않습니다.
- Related 추천: 해당 아이템과 비슷한 속성을 가진 아이템 추천 (e.g. 비슷한 장르의 영화추천)
- Personalized 추천: 사용자의 선호 속성과 유사한 아이템 추천 (e.g. SF를 좋아하는 사용자에게 SF장르의 영화 추천)
-
CF(Collaborative Filtering): 사용자들의 행동 이력을 이용한 추천으로 아이템의 속성을 사용하지 않습니다.
- Best 추천: 다수 사용자가 선호하는 하이템을 추천
- Related 추천: 해당 아이템과 같이 조회/ 구매/ 평가된 아이템을 추천
- Personalized 추천: 사용자와 이력이 비슷한 사용자가 선호하는 아이템 추천
-
Hybrid Recommendation: CF방법과 CBF 방법을 모두 이용하는 방법으로 아이템 속성과 사용자 행동이력을 모두 사용합니다.
- Best 추천: 특정 카테고리의 다수 사용자가 선호하는 아이템 추천
- Related 추천: 아이템 속성 + 해당 아이템과 같이 조회/ 구매/ 평가된 아이템을 추천
- Personalized 추천: 사용자의 선호 속성과 유사한 사용자들이 선호하는 아이템 추천
CBF와 CF는 서로 장단점이 존재하지만 경험적으로 CF방법이 조금 더 정확하다고 알려져있다고 합니다.
1.3.추천시스템 성능평가
추천시스템은 모델 개발이후 평가데이터를 이용한 성능 평가, 심사 위원 평가를 거쳐 실제 서비스를 운영하며 온라인 성능평가를 하여 모형을 또 한번 검증한다고 합니다.
1.3.1. 성능 평가
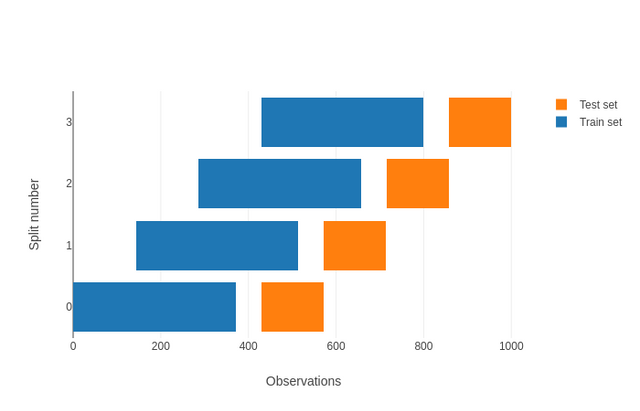
기본적으로 이력데이터들이 시간에 따라 기록되기 때문에 위와 같은 시계열분석에서의 예측방법과 동일한 평가를 진행한다고 합니다.
1.3.2. 심사 위원 평가
가장 신기했던 부분인데요.
추천시스템을 숫자로만 평가할 경우 신규 추천 결과에 대한 사용자의 반응을 알 수 없기 때문에, 이러한 평가를 받아보고자 실제 내부/외부 심사위원들을 선정하여 추천시스템의 품질을 평가한다고 합니다. 즉, 과거 데이터를 이용한 정량적인 평가뿐만아니라 심사위원들을 통한 정성적인 평가를 얻고자함이라고 합니다!
추가적으로 저의 개인적인 견해이지만, 과거 데이터를 이용해 추천시스템을 구축할 경우 현재의 트렌드를 유연하게 반영하지 못하는 문제가 생길 수 있는데 이러한 문제를 예방하고자 이러한 과정이 필요한 것으로 보입니다.
온라인 성능 평가
A/B Test를 통한 KPI지표 비교를 통해 모형을 평가하거나 실제 Rating과 예측값을 비교하며 성능을 평가 할 수 있습니다.
하지만 여기서 중요한 것은 실제값과 예측값을 비교할 때 RMSE와 MAE등을 비교하는 것도 좋지만, 실제로 추천되는 Top-K 에 대한 성능 평가를 비교하는 것이 더욱 합리적이라고 생각됩니다.
이때, 이러한 목적을 가지고 사용하는 지표가 Precision@K, Recall@K 지표인데요. 추천 결과의 개수가 K개 일때, 실제로 선호되는 항목 상위 K개와 비교하여 Precision과 Recall 값을 측정하는 것입니다. 또한 여기서 순위를 고려하여 높은 Ranking에 더 높은 가중치를 주는 MAP(Mean Average Precision), NDCG(Normalized Discounted Cumulative Gain) 등의 지표들이 사용된다고 합니다.
