태양 흑점 활동(sunspot)
- Sequence (시계열) 데이터 다루기
For this task you will need to train a neural network to predict sunspot activity using the Sunspots.csv provided.
Your neural network is expected to have an MAE of at least 20, with top marks going to one with an MAE of around 15.
At the bottom is provided some testing code should you want to check before uploading which measures the MAE for you.
Strongly recommend you test your model with this to be able to see how it performs.
Sequence(시퀀스)
Sunspots.csv를 사용하여 태양 흑점 활동(sunspot)을 예측하는 인공신경망을 만듭니다.
MAE 오차 기준으로 최소 20이하로 예측할 것을 권장하며, 탑 랭킹에 들려면 MAE 15 근처에 도달해야합니다.
아래 주어진 샘플코드는 당신의 모델을 테스트 하는 용도로 활용할 수 있습니다.
Solution
순서 요약
- import: 필요한 모듈 import
- 전처리: 학습에 필요한 데이터 전처리를 수행합니다.
- 모델링(model): 모델을 정의합니다.
- 컴파일(compile): 모델을 생성합니다.
- 학습 (fit): 모델을 학습시킵니다.
1. import 하기
필요한 모듈을 import 합니다.
import csv
import tensorflow as tf
import numpy as np
import urllib
from tensorflow.keras.layers import Dense, LSTM, Lambda, Conv1D
from tensorflow.keras.models import Sequential
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.losses import Huberurl = 'https://storage.googleapis.com/download.tensorflow.org/data/Sunspots.csv'
urllib.request.urlretrieve(url, 'sunspots.csv')2.1 전처리 (csv 파일로부터 데이터셋 만들기)
csv.reader() 함수를 활용합니다.
with open('sunspots.csv') as csvfile:
reader = csv.reader(csvfile, delimiter=',')
next(reader)
i = 0
for row in reader:
print(row)
i+=1
if i > 10:
break빈 list를 만들어 줍니다. (sunspots, time_step)
sunspots = []
time_step = []time_step에는 index 값을, sunspots에는 sunspots의 정보를 넣어 줍니다.
with open('sunspots.csv') as csvfile:
reader = csv.reader(csvfile, delimiter=',')
# 첫 줄은 header이므로 skip 합니다.
next(reader)
for row in reader:
sunspots.append(float(row[2]))
time_step.append(int(row[0]))sunspots와 time_step을 numpy array로 변환합니다.
- 참고: 모델은 list 타입을 받아들이지 못합니다. 따라서, numpy array 로 변환해 줍니다.
series = np.array(sunspots)
time = np.array(time_step)
series.shape, time.shape시각화 해보기
import matplotlib.pyplot as plt
plt.figure(figsize=(16, 8))
plt.plot(time, series)
plt.xlabel("Time")
plt.ylabel("Value")
plt.grid(True)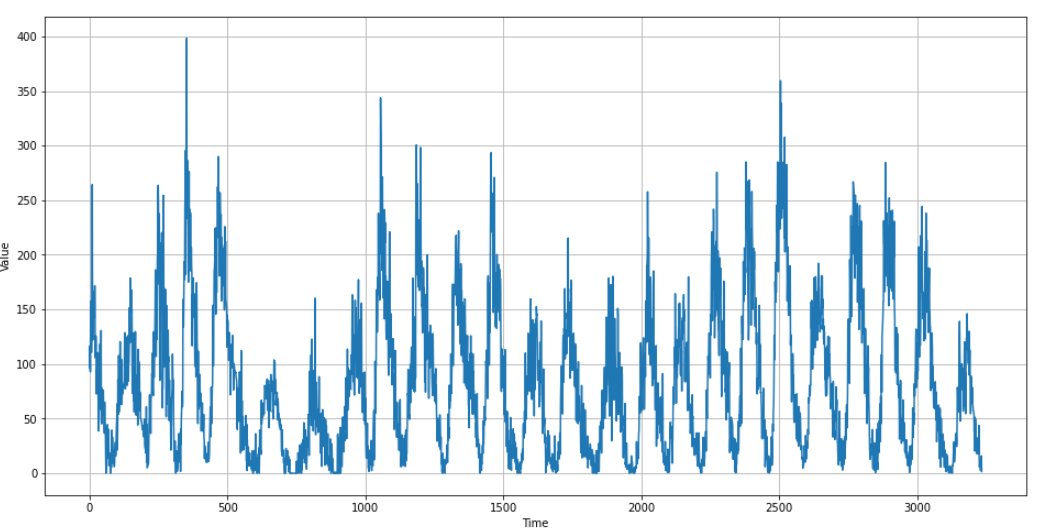
Train Set, Validation Set 생성
3000 인덱스를 기준으로 Train / Validation Set를 분할 합니다.
split_time = 3000
time_train = time[:split_time]
time_valid = time[split_time:]
x_train = series[:split_time]
x_valid = series[split_time:]Window Dataset Loader
# 윈도우 사이즈
window_size=30
# 배치 사이즈
batch_size = 32
# 셔플 사이즈
shuffle_size = 1000def windowed_dataset(series, window_size, batch_size, shuffle_buffer):
series = tf.expand_dims(series, axis=-1)
ds = tf.data.Dataset.from_tensor_slices(series)
ds = ds.window(window_size + 1, shift=1, drop_remainder=True)
ds = ds.flat_map(lambda w: w.batch(window_size + 1))
ds = ds.shuffle(shuffle_buffer)
ds = ds.map(lambda w: (w[:-1], w[1:]))
return ds.batch(batch_size).prefetch(1)train_set와 validation_set를 만듭니다.
train_set = windowed_dataset(x_train,
window_size=window_size,
batch_size=batch_size,
shuffle_buffer=shuffle_size)
validation_set = windowed_dataset(x_valid,
window_size=window_size,
batch_size=batch_size,
shuffle_buffer=shuffle_size)3. 모델 정의 (Sequential)
from IPython.display import Image
Image('https://i.stack.imgur.com/NmYZJ.png')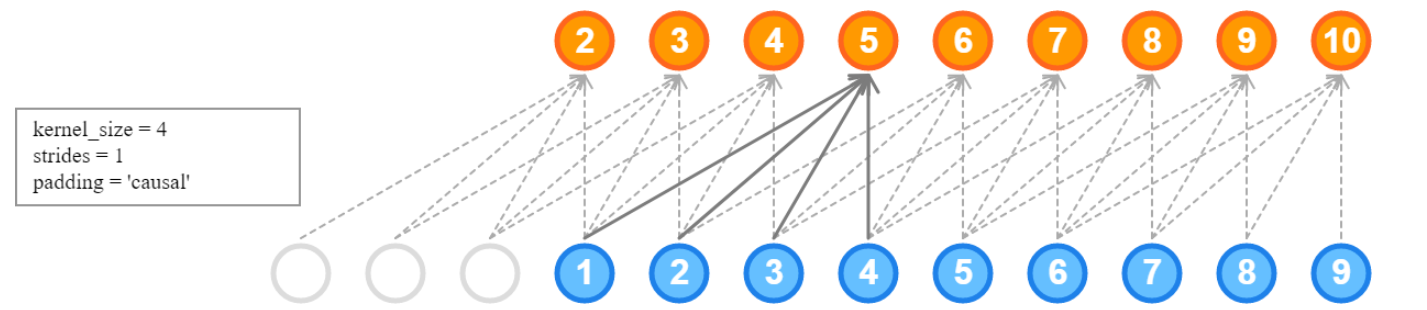
model = Sequential([
tf.keras.layers.Conv1D(60, kernel_size=5,
padding="causal",
activation="relu",
input_shape=[None, 1]),
tf.keras.layers.LSTM(60, return_sequences=True),
tf.keras.layers.LSTM(60, return_sequences=True),
tf.keras.layers.Dense(30, activation="relu"),
tf.keras.layers.Dense(10, activation="relu"),
tf.keras.layers.Dense(1),
tf.keras.layers.Lambda(lambda x: x * 400)
])모델 결과 요약
model.summary()4. 컴파일 (compile)
Optimizer는 SGD(Stochastic Gradient Descent) 를 사용합니다.
- lr(learning_rate): 학습률입니다.
- momentum: 모멘텀 (가중치) 입니다.
optimizer = SGD(lr=1e-5, momentum=0.9)Huber Loss: MSE와 MAE를 절충한 후버 손실(Huber loss)
loss= Huber()model.compile()시 우리가 튜닝한 optimizer와 loss를 활용합니다.
model.compile(loss=loss,
optimizer=optimizer,
metrics=["mae"])ModelCheckpoint: 체크포인트 생성
val_loss 기준으로 epoch 마다 최적의 모델을 저장하기 위하여, ModelCheckpoint를 만듭니다.
checkpoint_path는 모델이 저장될 파일 명을 설정합니다.ModelCheckpoint을 선언하고, 적절한 옵션 값을 지정합니다.
checkpoint_path = 'tmp_checkpoint.ckpt'
checkpoint = ModelCheckpoint(checkpoint_path,
save_weights_only=True,
save_best_only=True,
monitor='val_mae',
verbose=1)5. 학습 (fit)
epochs=100history = model.fit(train_set,
validation_data=(validation_set),
epochs=epochs,
callbacks=[checkpoint],
)학습 완료 후 Load Weights (ModelCheckpoint)
학습이 완료된 후에는 반드시 load_weights를 해주어야 합니다.
그렇지 않으면, 열심히 ModelCheckpoint를 만든 의미가 없습니다.
# checkpoint 를 저장한 파일명을 입력합니다.
model.load_weights(checkpoint_path)오차 및 정확도 시각화
학습 Loss (오차) / accuracy (정확도)에 대한 시각화
import matplotlib.pyplot as pltplt.figure(figsize=(12, 9))
plt.plot(np.arange(1, epochs+1), history.history['loss'])
plt.plot(np.arange(1, epochs+1), history.history['val_loss'])
plt.title('Loss / Val Loss', fontsize=20)
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(['loss', 'val_loss'], fontsize=15)
plt.show()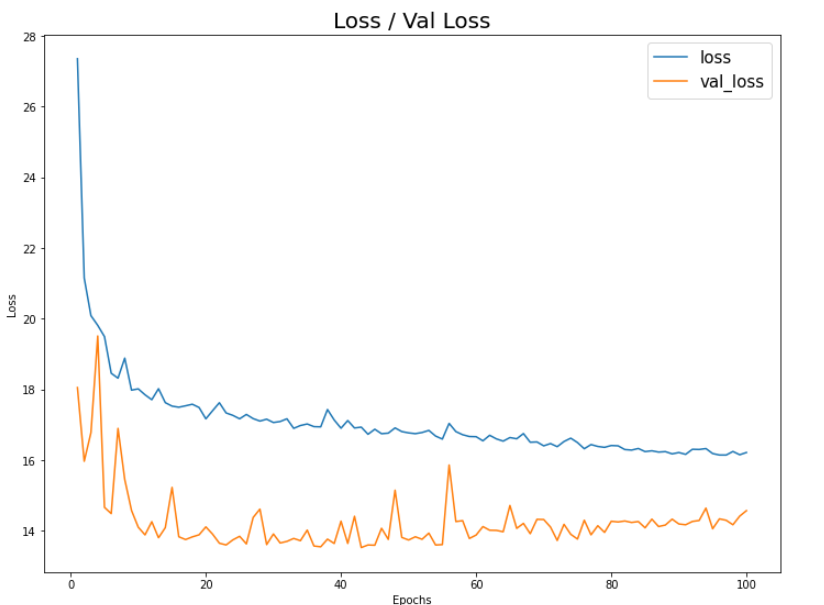
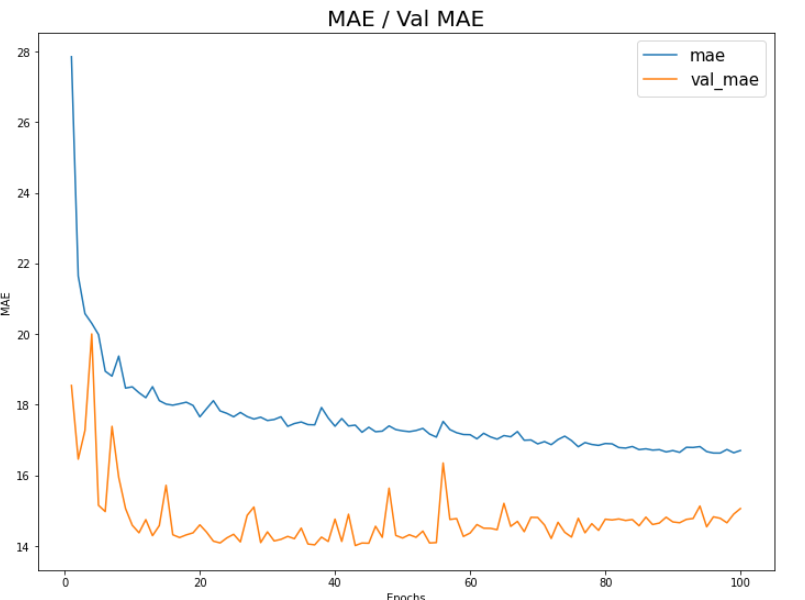
plt.figure(figsize=(12, 9))
plt.plot(np.arange(1, epochs+1), history.history['mae'])
plt.plot(np.arange(1, epochs+1), history.history['val_mae'])
plt.title('MAE / Val MAE', fontsize=20)
plt.xlabel('Epochs')
plt.ylabel('MAE')
plt.legend(['mae', 'val_mae'], fontsize=15)
plt.show()