Sarcasm (비꼼) 분류하기
- RNN 을 활용한 텍스트 분류 (Text Classification)
NLP QUESTION
For this task you will build a classifier for the sarcasm dataset
The classifier should have a final layer with 1 neuron activated by sigmoid as shown.
It will be tested against a number of sentences that the network hasn't previously seen
And you will be scored on whether sarcasm was correctly detected in those sentences
자연어 처리
이 작업에서는 sarcasm 데이터 세트에 대한 분류기를 작성합니다.
분류기는 1 개의 뉴런으로 이루어진 sigmoid 활성함수로 구성된 최종 층을 가져야합니다.
제출될 모델은 데이터셋이 없는 여러 문장에 대해 테스트됩니다.
그리고 당신은 그 문장에서 sarcasm 판별이 제대로 감지되었는지에 따라 점수를 받게 될 것입니다
Solution
순서 요약
- import: 필요한 모듈 import
- 전처리: 학습에 필요한 데이터 전처리를 수행합니다.
- 모델링(model): 모델을 정의합니다.
- 컴파일(compile): 모델을 생성합니다.
- 학습 (fit): 모델을 학습시킵니다.
1. import 하기
필요한 모듈을 import 합니다.
import json
import tensorflow as tf
import numpy as np
import urllib
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectional, Flatten
from tensorflow.keras.models import Sequential
from tensorflow.keras.callbacks import ModelCheckpoint2.1 전처리 (Load dataset)
tensorflow-datasets를 활용합니다.
필요한 데이터세트를 다운로드합니다.
url = 'https://storage.googleapis.com/download.tensorflow.org/data/sarcasm.json'
urllib.request.urlretrieve(url, 'sarcasm.json')2.2 전처리 (Json 파일 로드)
## Json 파일 로드
with open('sarcasm.json') as f:
datas = json.load(f)datas 5개 출력해봅시다.
article_link: 뉴스 기사 URLheadline: 뉴스기사의 제목is_sarcastic: 비꼬는 기사 여부 (비꼼: 1, 일반: 0)
datas[:5]
2.3 전처리 데이터셋 구성(sentences, labels)
빈 list를 생성합니다. (sentences, labels)
- X (Feature): sentences
- Y (Label): label
sentences = []
labels = []
for data in datas:
sentences.append(data['headline'])
labels.append(data['is_sarcastic'])문장 5개를 출력합니다.
sentences[:5]labels[:5]2.4 전처리 (Train / Validation Set 분리)
20,000개를 기준으로 데이터셋을 분리합니다.
training_size = 20000
train_sentences = sentences[:training_size]
train_labels = labels[:training_size]
validation_sentences = sentences[training_size:]
validation_labels = labels[training_size:]2.5 전처리 Step 1. Tokenizer 정의
단어의 토큰화를 진행합니다.
num_words: 단어 max 사이즈를 지정합니다. 가장 빈도수가 높은 단어부터 저장합니다.oov_token: 단어 토큰에 없는 단어를 어떻게 표기할 것인지 지정해줍니다.
vocab_size = 1000
oov_tok = "<OOV>"tokenizer = Tokenizer(num_words=vocab_size, oov_token='<OOV>')2.6 전처리 Step 2. Tokenizer로 학습시킬 문장에 대한 토큰화 진행
fit_on_texts로 학습할 문장에 대하여 토큰화를 진행합니다.
tokenizer.fit_on_texts(train_sentences)for key, value in tokenizer.word_index.items():
print('{} \t======>\t {}'.format(key, value))
if value == 25:
break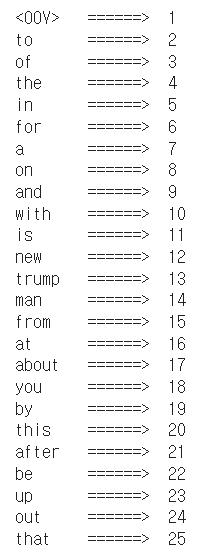
토큰화된 단어 사전의 갯수
len(tokenizer.word_index)단어사전은 dictionary 형태로 되어 있습니다.
즉, 단어를 key로 입력하면 값을 return 합니다.
word_index = tokenizer.word_index
word_index['trump']
word_index['hello']2.7 전처리 Step 3. 문장(sentences)을 토큰으로 변경 (치환)
texts_to_sequences: 문장을 숫자로 치환 합니다. Train Set, Valid Set 모두 별도로 적용해주어야 합니다.
train_sequences = tokenizer.texts_to_sequences(train_sentences)
validation_sequences = tokenizer.texts_to_sequences(validation_sentences)변환된 Sequences 확인
train_sequences[:5]2.8 전처리 Step 4. 시퀀스의 길이를 맞춰주기
3가지 옵션을 입력해 줍니다.
maxlen: 최대 문장 길이를 정의합니다. 최대 문장길이보다 길면, 잘라냅니다.truncating: 문장의 길이가maxlen보다 길 때 앞을 자를지 뒤를 자를지 정의합니다.padding: 문장의 길이가maxlen보다 짧을 때 채워줄 값을 앞을 채울지, 뒤를 채울지 정의합니다.
# 한 문장의 최대 단어 숫자
max_length = 120
# 잘라낼 문장의 위치
trunc_type='post'
# 채워줄 문장의 위치
padding_type='post'train_padded = pad_sequences(train_sequences, maxlen=max_length, truncating=trunc_type, padding=padding_type)
validation_padded = pad_sequences(validation_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)변환된 Sequences 확인
train_padded.shape2.9 전처리 Step 5. label 값을 numpy array로 변환
model이 list type은 받아들이지 못하므로, numpy array로 변환합니다.
train_labels = np.array(train_labels)
validation_labels = np.array(validation_labels)Embedding Layer
고차원을 저차원으로 축소시켜주는 역할을 합니다.
one-hot encoding을 진행했을 때, 1000차원으로 표현되는 단어들을 16차원으로 줄여주는 겁니다. 그렇게 해서 sparsity문제를 해소하도록 유도합니다.
embedding_dim = 16- 변환 전
sample = np.array(train_padded[0])
sample
- 변환 후
x = Embedding(vocab_size, embedding_dim, input_length=max_length)
x(sample)[0]
3. 모델 정의 (Sequential)
이제 Modeling을 할 차례입니다.
model = Sequential([
Embedding(vocab_size, embedding_dim, input_length=max_length),
Bidirectional(LSTM(64, return_sequences=True)),
Bidirectional(LSTM(64)),
Dense(32, activation='relu'),
Dense(16, activation='relu'),
Dense(1, activation='sigmoid')
])모델 결과 요약
model.summary()4. 컴파일 (compile)
optimizer는 가장 최적화가 잘되는 알고리즘인 'adam'을 사용합니다.loss는 이진 분류이기 때문에binary_crossentropy를 사용합니다.
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])ModelCheckpoint: 체크포인트 생성
val_loss 기준으로 epoch 마다 최적의 모델을 저장하기 위하여, ModelCheckpoint를 만듭니다.
checkpoint_path는 모델이 저장될 파일 명을 설정합니다.ModelCheckpoint을 선언하고, 적절한 옵션 값을 지정합니다.
checkpoint_path = 'my_checkpoint.ckpt'
checkpoint = ModelCheckpoint(checkpoint_path,
save_weights_only=True,
save_best_only=True,
monitor='val_loss',
verbose=1)5. 학습 (fit)
epochs=10history = model.fit(train_padded, train_labels,
validation_data=(validation_padded, validation_labels),
callbacks=[checkpoint],
epochs=epochs)학습 완료 후 Load Weights (ModelCheckpoint)
학습이 완료된 후에는 반드시 load_weights를 해주어야 합니다.
그렇지 않으면, 열심히 ModelCheckpoint를 만든 의미가 없습니다.
# checkpoint 를 저장한 파일명을 입력합니다.
model.load_weights(checkpoint_path)오차 및 정확도 시각화
학습 Loss (오차)에 대한 시각화
import matplotlib.pyplot as pltplt.figure(figsize=(12, 9))
plt.plot(np.arange(1, epochs+1), history.history['loss'])
plt.plot(np.arange(1, epochs+1), history.history['val_loss'])
plt.title('Loss / Val Loss', fontsize=20)
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(['loss', 'val_loss'], fontsize=15)
plt.show()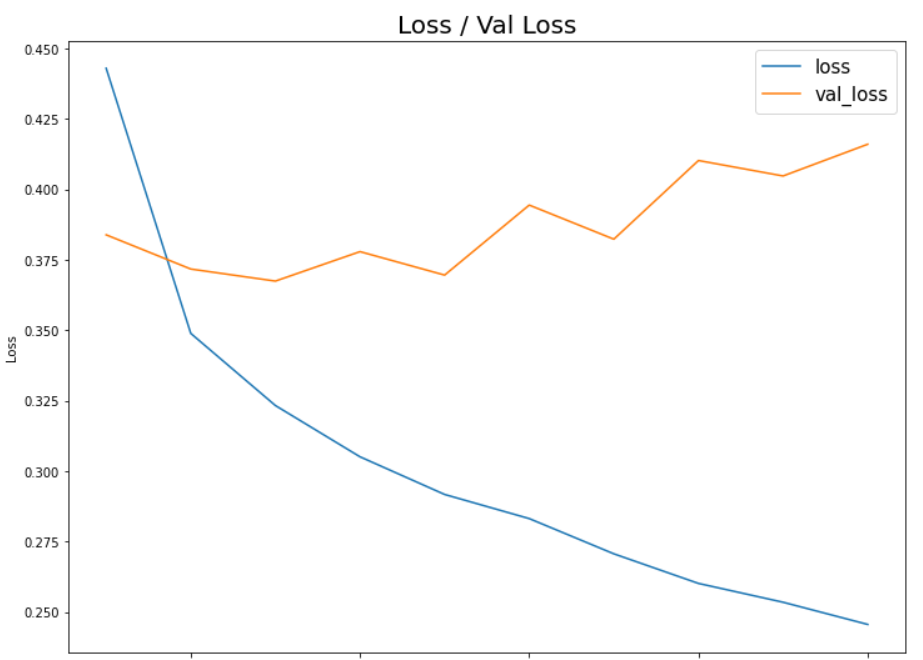
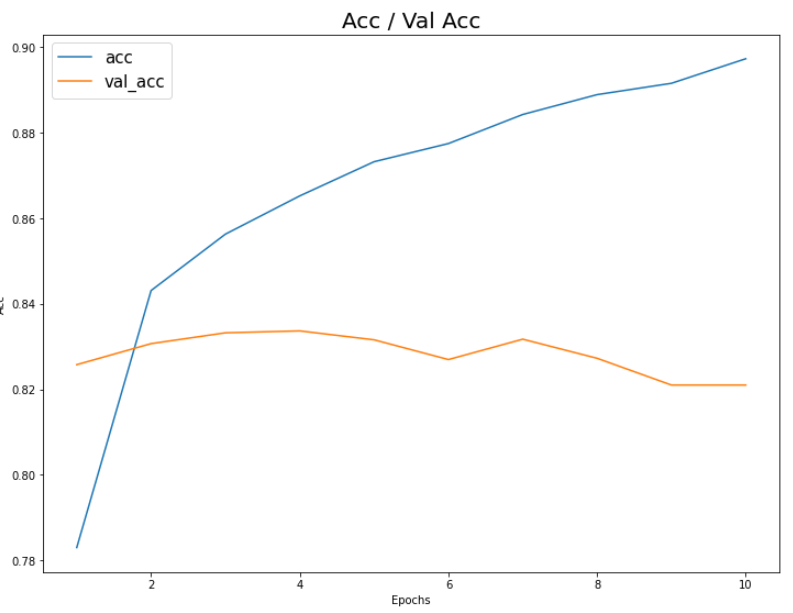
accuracy (정확도)에 대한 시각화
plt.figure(figsize=(12, 9))
plt.plot(np.arange(1, epochs+1), history.history['acc'])
plt.plot(np.arange(1, epochs+1), history.history['val_acc'])
plt.title('Acc / Val Acc', fontsize=20)
plt.xlabel('Epochs')
plt.ylabel('Acc')
plt.legend(['acc', 'val_acc'], fontsize=15)
plt.show()