- 우리가 확률 분포를 미리 안다면 확률 변수를 직접 넣어 구할 수 있지만 현실에서는 확률 분포 함수에서 나온 데이터만을 얻을 수 있다.
- 내재된 확률 분포 함수를 모를 때 어떻게 추정?
확률 분포의 추정
- 우리가 가진 데이터로부터 확률 분포를 추정하는 기술
확률 분포 추정 방법
-
데이터 형태에 따라 원하는 분포로 추정 가능
-
베르누이 분포 : 데이터가 0 또는 1의 형태
-
정규 분포 : 데이터가 크기 제한이 없는 실수 형태
-
카테고리 분포 : 데이터가 카테고리 값 형태
-
주어진 데이터를 이용해 확률 분포를 계산하는 대표적인 두가지 방법이 존재
-
- 모멘트 방법
-
- 최대 가능도 추정
확률 분포를 나타내기 위한 모수(parameter)
- 우리는 모수를 가지는 확률 분포에 대해 알아보았다.
- 정규분포는 평균, 분산 2가지 파라미터를 조합해 다양한 정규분포를 표현할 수 있다.
모멘트(moment) = 적률
-
확률 분포에서 계산한 특징값의 일종, n차 모멘트는
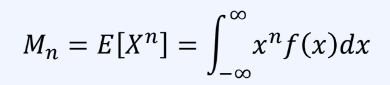
-
1차 모멘트는 평균, 2차 모멘트는 분산에 해당한다.
-
1차부터 무한데 차수까지 두 확률 분포의 모멘트 값이 동일 -> 두 확률 분포는 동일
모멘트 방법
-
1차 모멘트는 데이터의 평균과 같다.
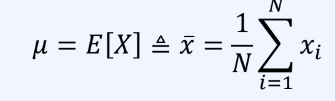
-
2차 모멘트는 데이터의 분산과 같다.
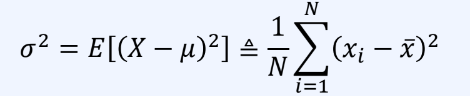
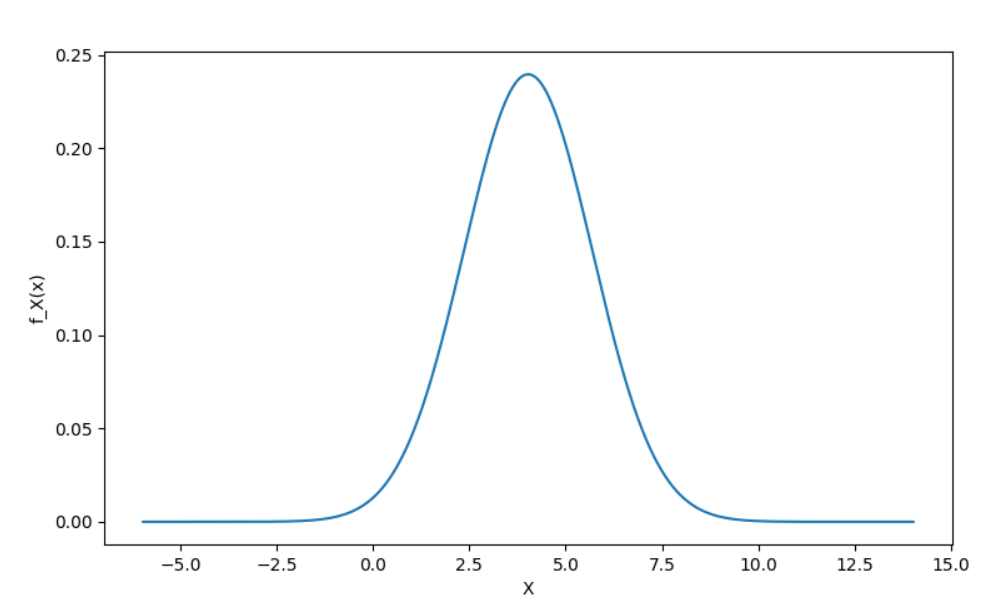
모멘트 방법을 이용한 정규 분포 추정
-
모멘트 방법을 이용해 정규 분포의 parameter를 추정할 수 있다.
-
다음 표를 보자

-
평균 : 4.025, 분산 : 2.774
-
정규 분포의 함수에서 평균(μ) 과 표준편차(σ)를 넣어 확률 값을 계산할 수 있다.
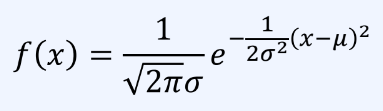
import math
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = [10,8]
arr = [1]*3 + [2]*5 + [3]*7 + [4]*10 + [5]*6 + [6]*6 + [7]*3
def mean(lst):
return sum(lst)/len(lst)
def var(lst):
lst_var = 0
for i in lst:
lst_var += ((i-mean(lst))**2)/len(lst)
return lst_var
def std(lst):
return math.sqrt(var(lst))
x = np.linspace(mean(arr)-10, mean(arr)+10, 1000) # 평균 중심 다수의 데이터 생성
# 정규 분포의 확률 밀도 함수
y = (1/(np.sqrt(2*np.pi) *std(arr))) * np.exp(-1/(2*(std(arr)**2))*((x-mean(arr))**2))
plt.plot(x,y)
plt.xlabel("X")
plt.ylabel("f_X(x)")
plt.show()