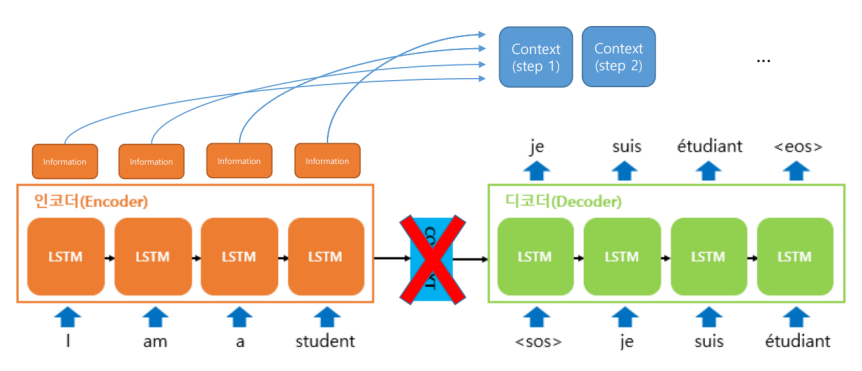
Seq2Seq 한계
- seq2seq 특성상 hidden state에서 앞쪽 input token의 정보는 희미해진다.
- 즉, input sequence의 길이가 길 경우에, 컨텍스트 벡터에서 input정보를 정확하게 압축하기가 어렵다.
- 이를 해결한 것 Attention
Attention
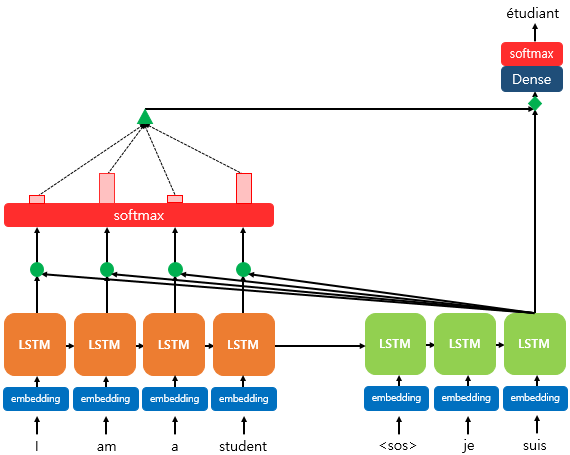
- 올바른 출력을 위해서는 어떤 input토큰을 더 많이 고려해야 할까?
- Decoding step에 따라 "attenetion weight"가 달라진다.
- 각 Decoding step에서 각기 다른 context vector를 활용한다.
- 이때 context vector는 encoder가 각 input 토큰을 압축한 정보의 가중합이다.
Attention의 전체적인 과정
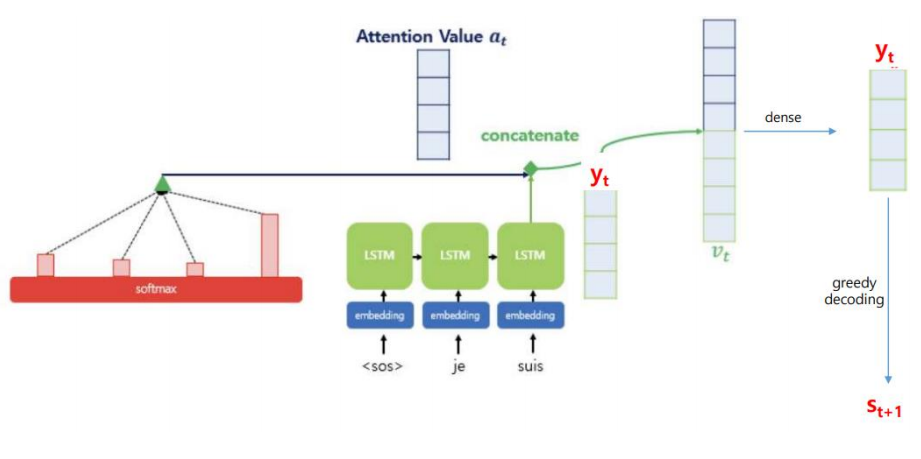
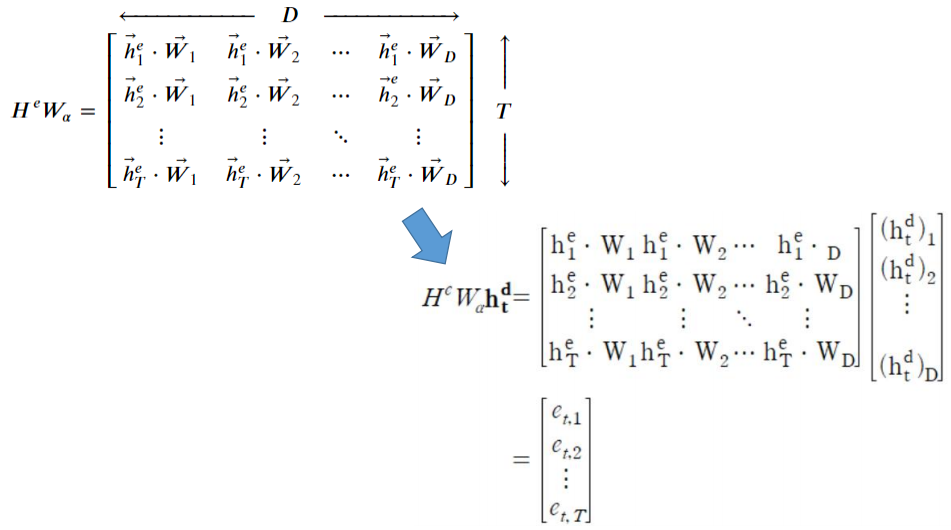
1) Attention Score를 구한다.
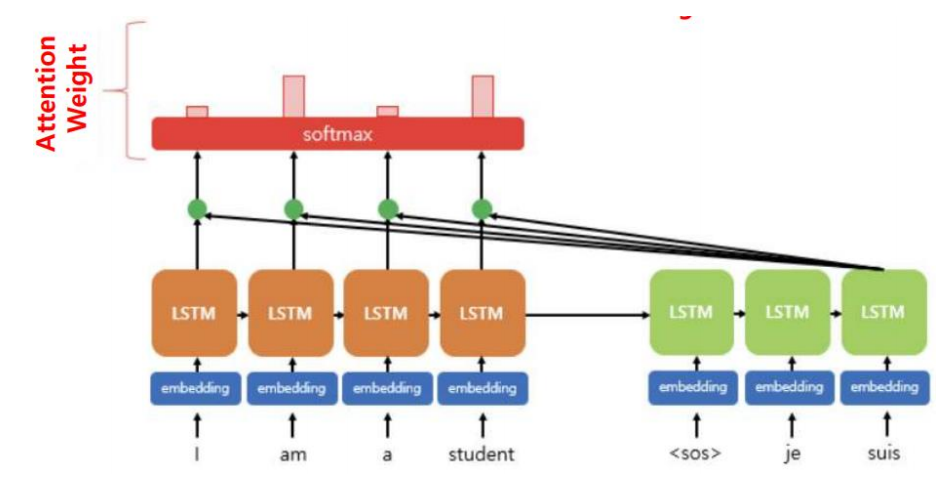
2) Attention Score를 Softmax 함수에 통과시켜서 Attention Weight를 구한다.
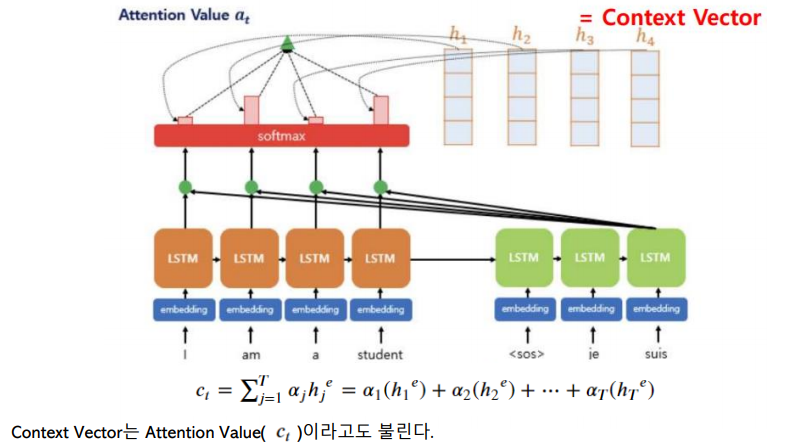
3) 각 인코더의 Attention Weight와 hidden state를 가중합하여 Context vector를 구한다.
4) Context vector와 디코더의 t시점의 output값(yt)을 연결한다.
1) Attention Score를 구한다.
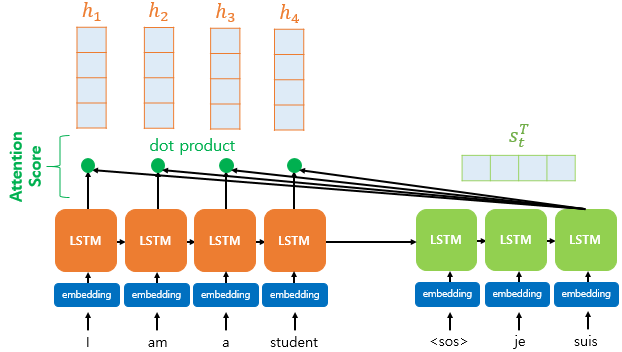

2) Attention Score를 Softmax 함수에 통과시켜서 Attention Weight를 구한다.
3) 각 인코더의 Attention Weight와 hidden state를 가중합하여 Context vector를 구한다.
4) Context vector와 디코더의 t시점의 output값(yt)을 연결한다.