RNN(Recurrent Neural Network)
- '순환 신경망'으로 내부에서 순횐되는 구조를 가지고 있다.
RNN 구조
-
일반적인 nn와 RNN구조 차이
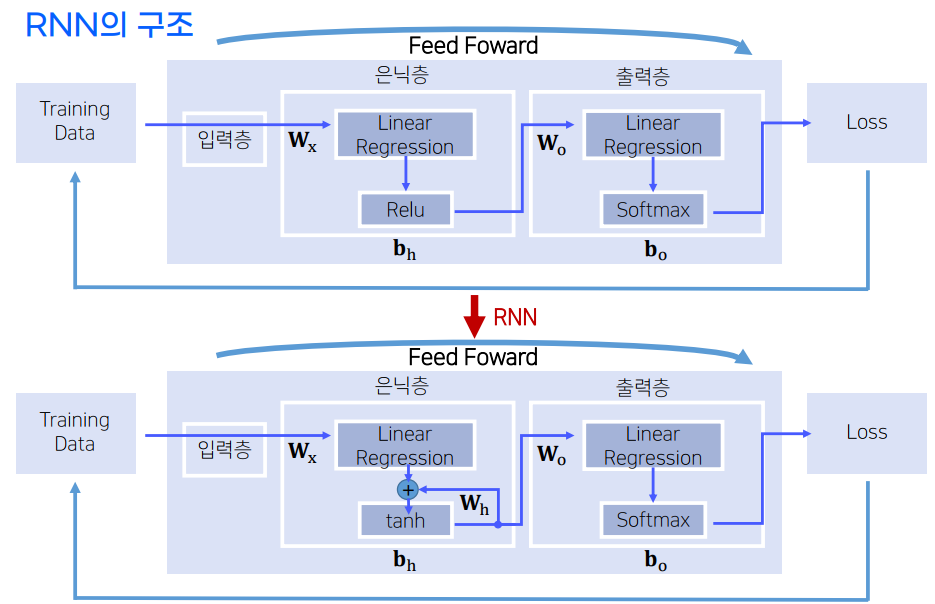
-
RNN의 구조
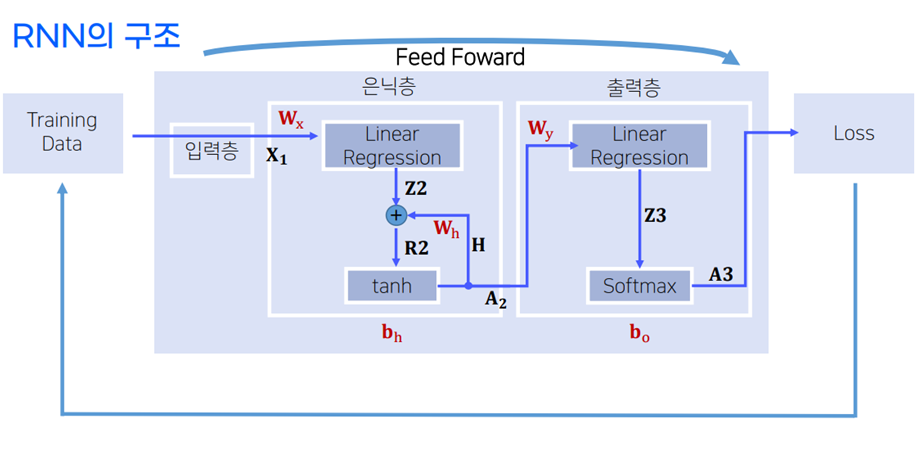
-
Ht = A2 = tanh(X1·Wx + Ht-1·Wh + bn)
-
Yt = f(A2·Wy +bo)
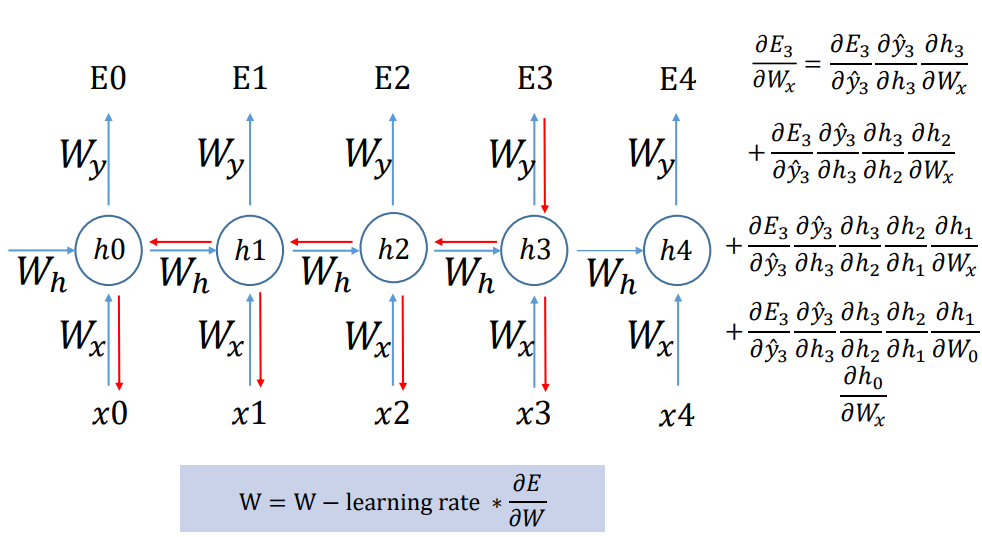
RNN - BPTT(BackPropagation Through Time)
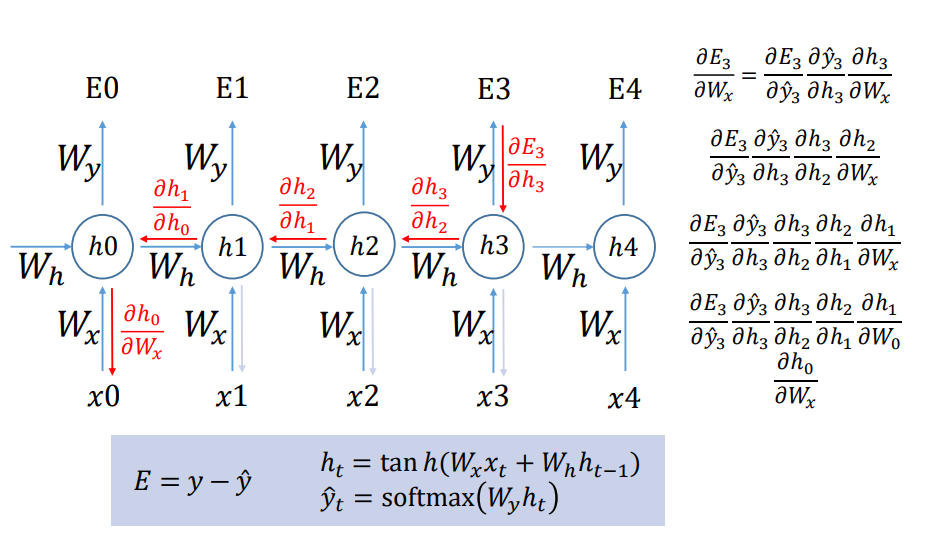
- 왜 sigmoid가 아닌 tanh를 사용할까? -> 기울기 소실 문제를 약간이나마 해결할 수 있다.
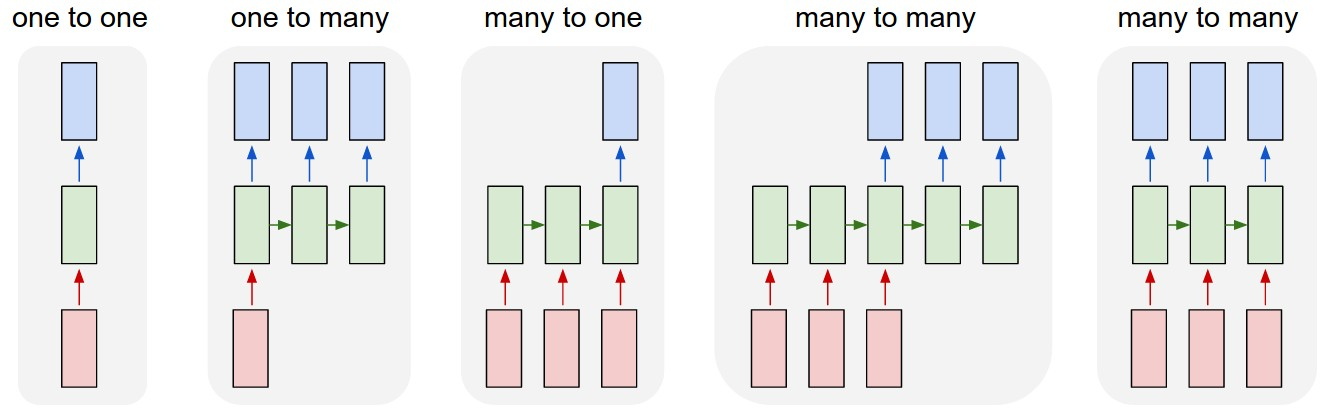
RNN의 한계
- 문장이 너무 길어지면 W = W-learning rate * ∂E/∂W
- 1보다 미분값이 큰 경우 Gradient Exploding -> gradient clipping 해준다.
- 1보다 미분값이 작을 경우 Gradient Vanishing
LSTM - RNN 비교
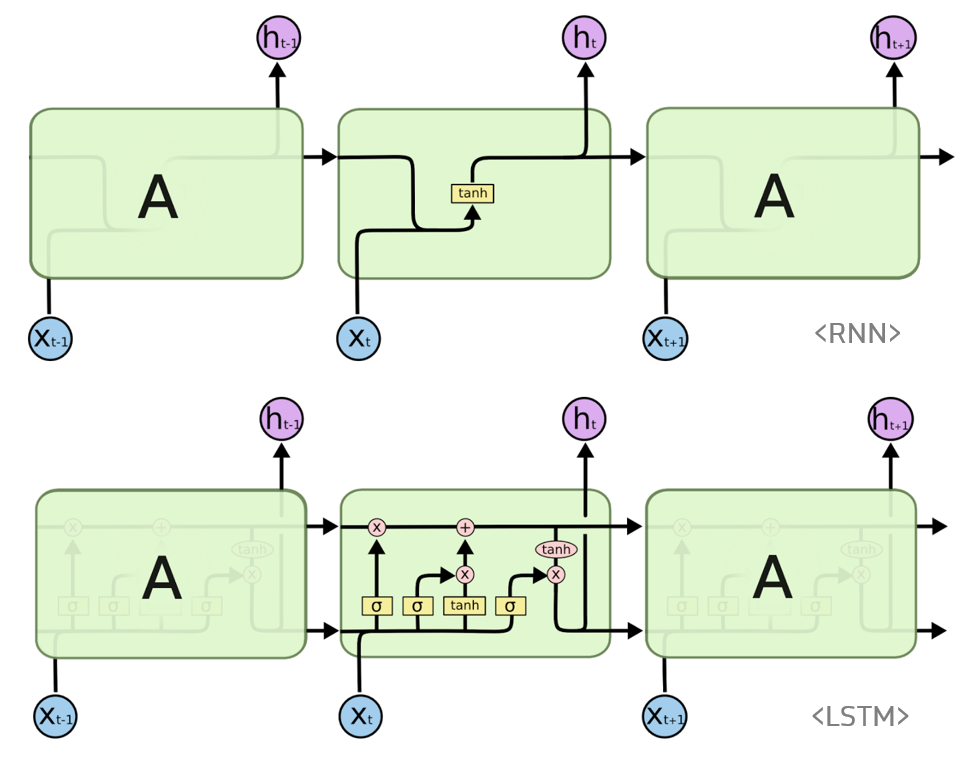
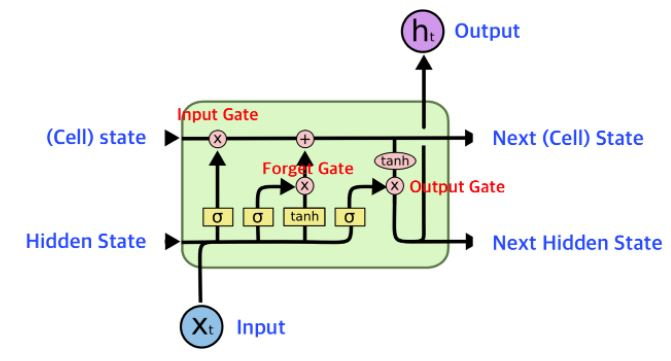
LSTM 모델 구조
-
forget gate
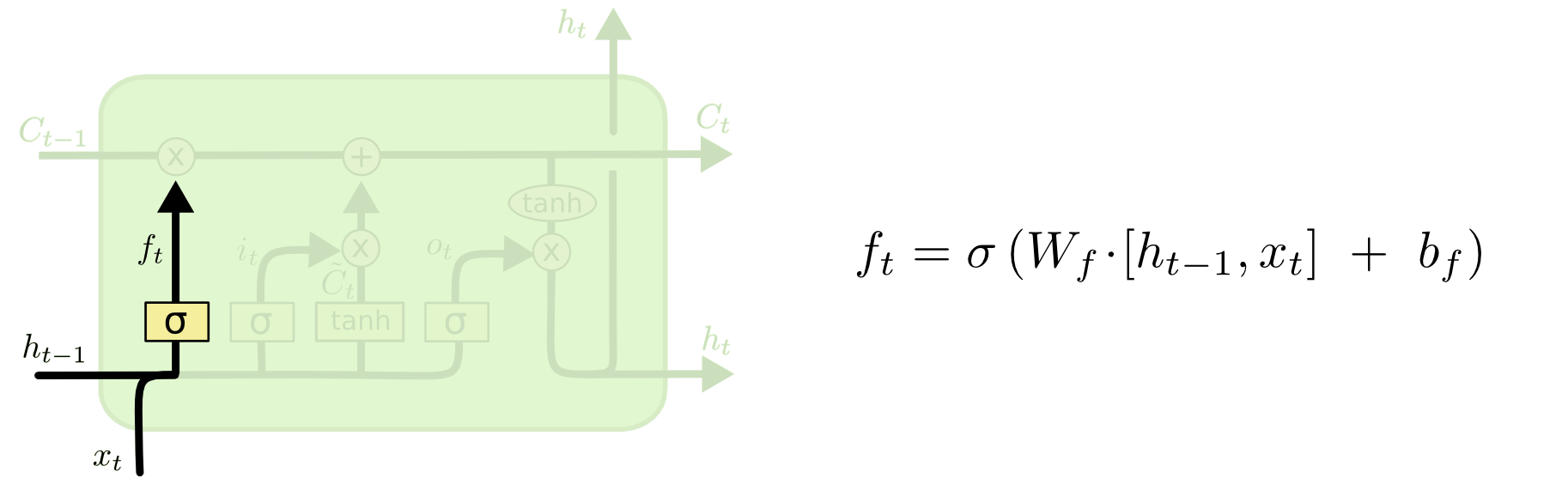
-
input gate
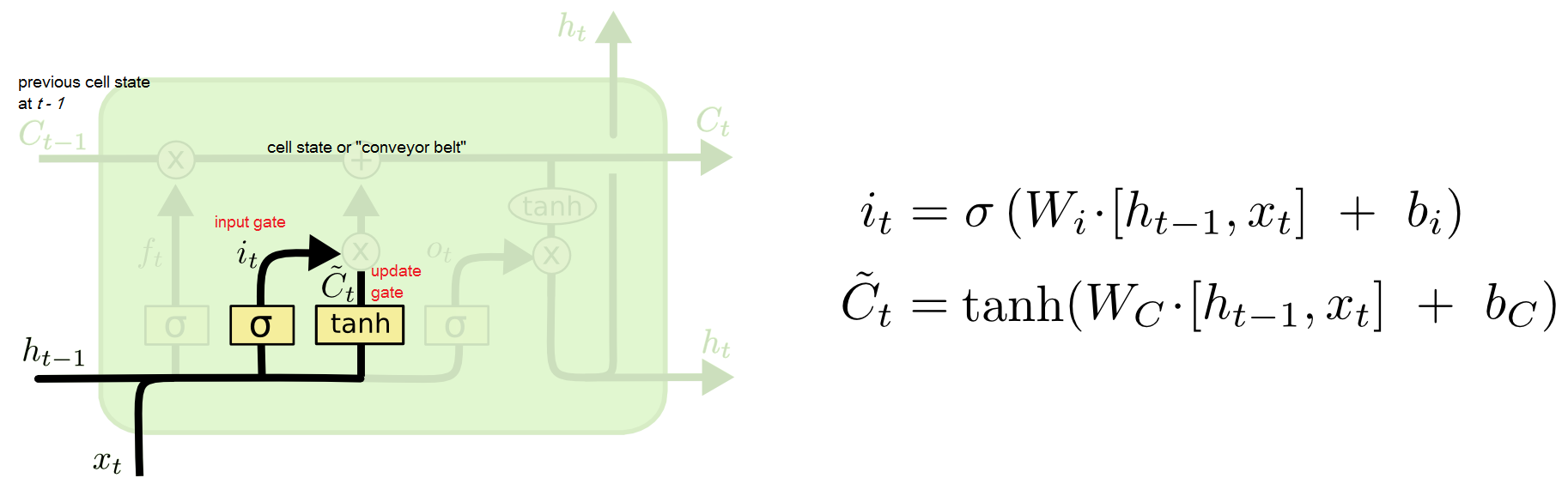
-
Cell update
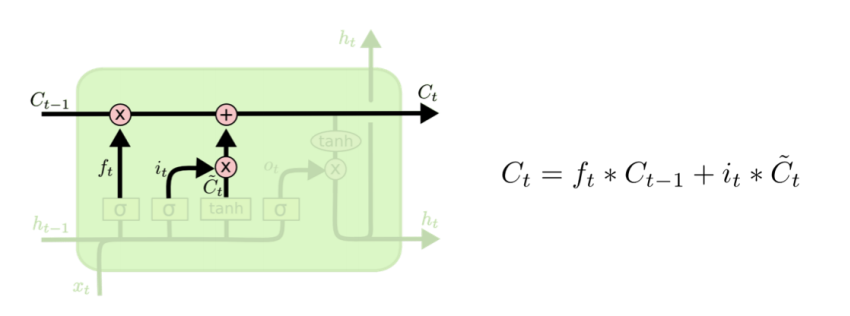
-
output gate
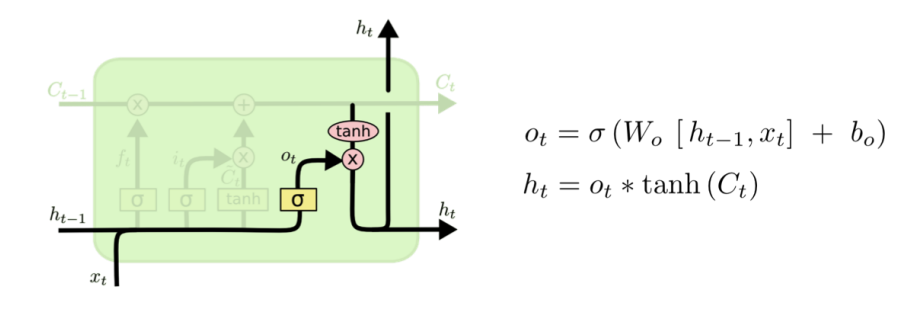
GRU 모델구조
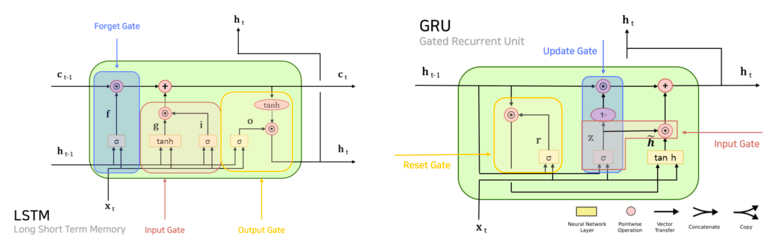
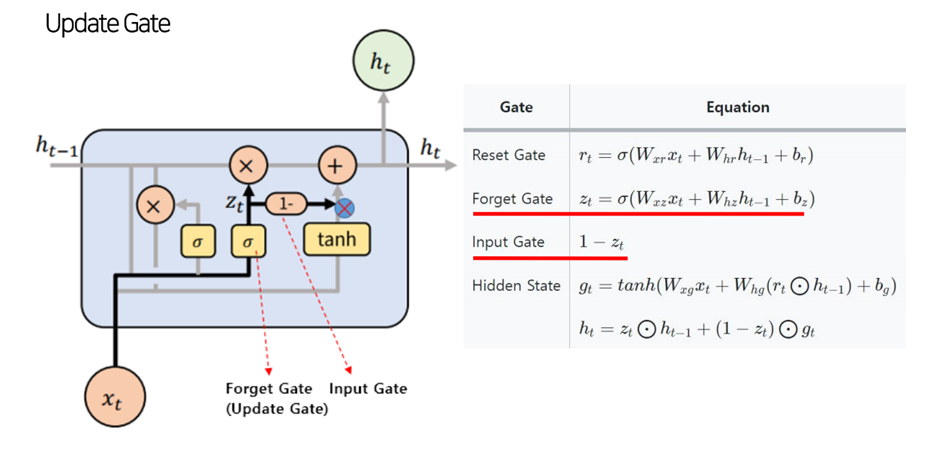
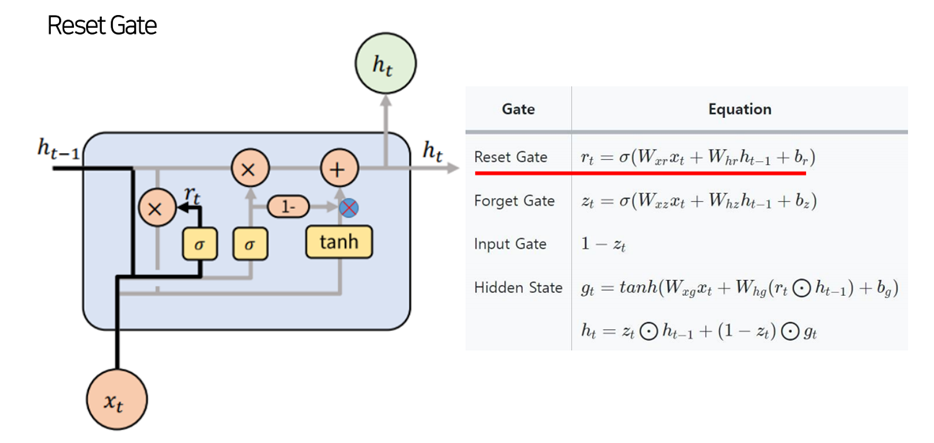
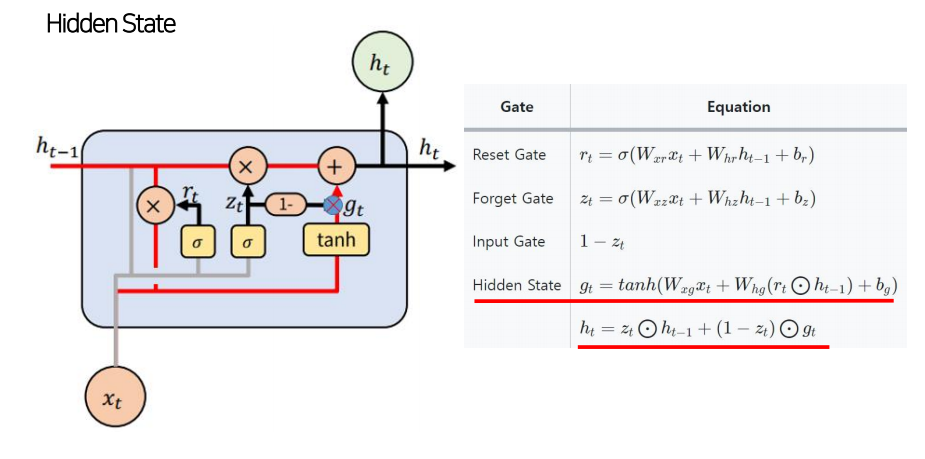
GRU - encoder-decoder
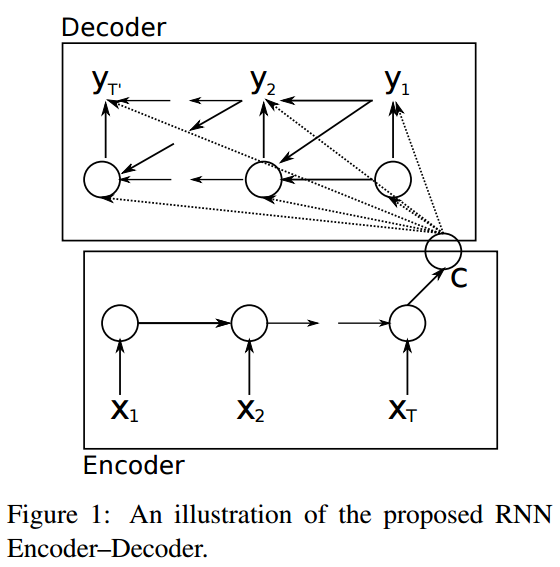
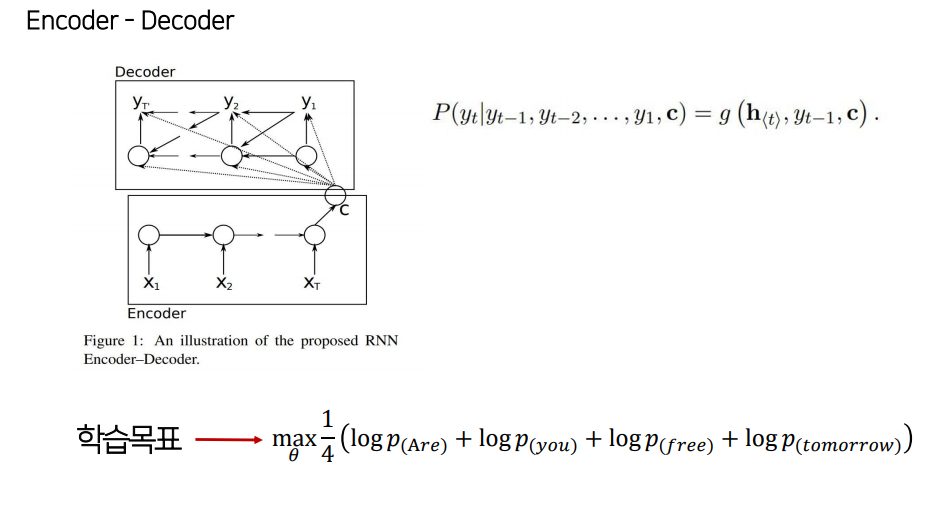
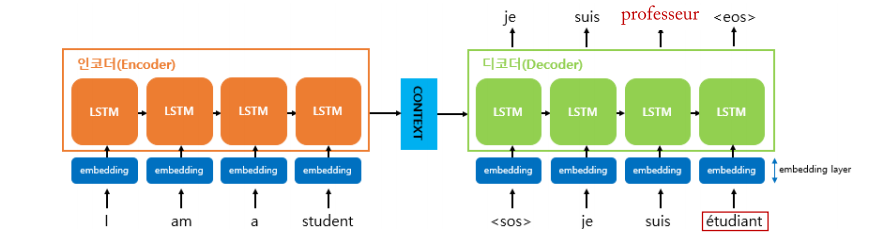
Seq2Seq
RNN의 한계
- 각 step에서의 입력과 출력이 같지 않을 경우
- Casuality(인과율)이 성립. 즉 t번째 step은 t+1의 결과를 참고할 수 없음
Seq2Seq
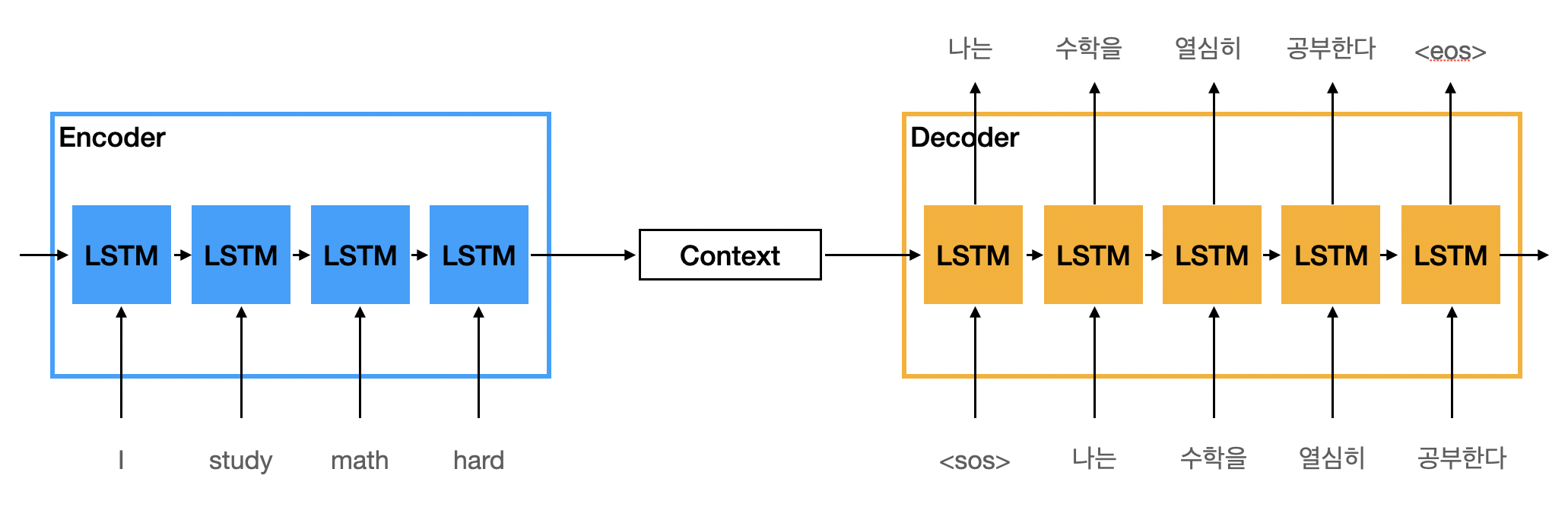
-
RNN을 어떻게 조립했느냐 따라서 Seq2Seq 구조가 만들어진다.
-
두개의 RNN 셀로 이루어져 있다.
-
모든 정보를 내포하고 있는 인코더 RNN 셀의 마지막 시점의 은닉 상태를(context vector) 디코더 RNN셀의 첫 은닉 상태로 넣어준다.
-
실제 context vector는 수백 이상의 차원을 가지고 있다.
-
context vector를 Decoder의 초기 은닉상태 사용 할 수도, 디코더가 단어를 예측하는 매 시점마다 input으로 넣어 줄 수도 있다.
Seq2Seq 학습과정
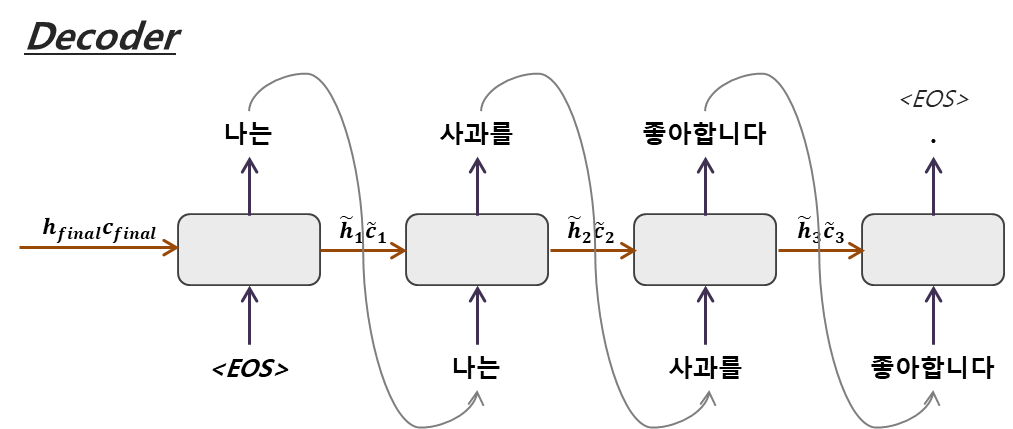
- Training:teaching force/Test(=inerence):Greedy decoding
- 디코더의 input에 이전 시점의 output을 넣어줌
- output 토큰 선정 기준 : 가장 높은 확률 값
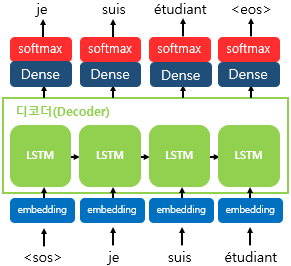
- Training:teaching force/Test(=inerence):Greedy decoding
- 디코더의 input에 정답이 들어감
- 이전 step의 결과가 오답일 경우 이후 학습에는 영향을 미치지 않게 방지
- Cross-Entropy Loss사용
- 각 step에 Cross-Entropy Loss를 모두 더하거나, 평균을 내서 loss로 사용
