워드 임베딩1
희소 표현
- 대표적인 희소 표현 : 원-핫 벡터
- 표현하고 싶은 단어의 인덱스에만 1을 부여하고 다른 인덱스에는 0을 부여하는 벡터의 표현 방식
- 벡터의 차원 = 단어 집합의 크기
ex) dog = [1,0,0]
cat = [0,1,0]
animal = [0,0,1]
pet = [0,0,1]
희소표현의 한계
- BOW가 커지면 커질수록 사용하는 메모리의 수가 계속 증가한다.(공간 낭비)
- 유사어 판단 불가능 (위의 예에서는 animal, pet 구별 불가)
워드 임베딩의 정의
- NLP task에서 단어를 하나의 벡터로 표현하는 기술(컴퓨터는 자연어를 그대로 처리할 수 없다.)
- 단어를 밀집 표현(dense vector)로 표현
- 워드 임베딩을 통해서 나온 결과 : 임베딩 벡터
- 유사어 판별 가능
ex) 'sad' : [0.02, -0.02]
'gloomy' : [0.01, -0.01]
밀집 표현
- 1과 0이 아닌 실수값을 찾는다.
- 훨씬 적은 차원으로 단어를 표현할 수 있다.
- 사용자가 설정한 값으로 벡터의 차원 설정
- 두 단어의 유사도 구할 수 있다.

코사인 유사도
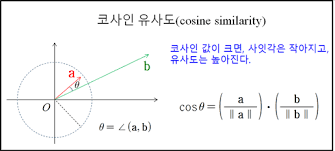
- 두 단어를 벡터로 나타냈을 때 두 벡터사이의 각도를 측정해서 유사도를 측정하는 방법(-1~1 사이의 값을 가진다.)
- 원핫 인코딩에서는 불가능
- 비슷한 단어끼리는 코사인 유사도가 클 것이다.
오토인코더
- 데이터를 압축된 형태로 학습시킬 수 있도록 하는 신경망의 하나의 형태
- 데이터 특징 추출로 인한 용량 감소
ex) 30차원의 data 1000개 -> 2차원 data 1000개 - input data --Encoder--> Abstract data --Decoder--> Output data
오토인코더의 구조
- 인코더 : 데이터의 차원 축소, 중요한 특징을 골라내고 그렇지 않은 부분 삭제
- Abstract data에는 데이터의 중요한 특징 내포
- 디코더 : 축소된 데이터로부터 원래 데이터 복원
오토인코더 학습 방식
- 데이터를 압축할 때 발생할 수 있는 손실 최적화
- ex) MSE를 Loss로 두고 경사하강법(다양한 최적화, Loss 사용 가능)
- y(pred) : Output data, y(true) : input data
- 좋은 모델일 수록 데이터 압축후 복원해도 원래 데이터와 유사
워드 임베딩2
지도 학습 VS 비지도 학습
지도학습(supervised learning)
- 정답(label)이 있는 상황에서 모델 학습
- 회귀, 분류 문제
- Mnist dataset
비지도 학습(unsupervised learning)
- 정답(label)이 없는 상황에서 모델 학습
- 데부분의 워드 임베딩 기술, 클러스터링
오토인코더는 자기 지도 학습(self-supervised learning), Label = input data
원-핫 인코딩을 이용한 단어 예측 모델
- 오토인코더를 이용한 단어 예측
- Word2Vec
오토인코더를 통한 단어 예측
ex) 'cat', 'sat'이 순서대로 주어지고 다음 나올 단어를 예측하는 경우
cat : shape-(1,1000) w200 -> shape-(1,50) -> shape(1,100)(cat과 set concat)-> (1,1000)
sat : shape-(1,1000) w440 -> shape-(1,50) ->
최종 (,1000)의 값을 softmax함수를 통해 확률로 표현해줌 -> 학습된 모델에서 결과값이 [0.01, 0.02, ...,0.9, ...,0.01]이 된다면 0.9의 값의 index에 대응되는 단어가 나올 것이다.
Word2Vec
- 워드 임베딩의 가장 대표적인 모델
- 학습 방식에 2가지 방식 CBOW와 SKip-Gram이 있다.
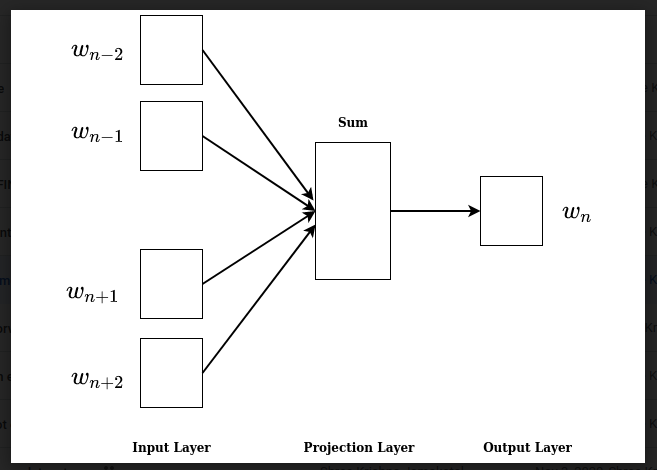
Word2Vec-CBOW

- 주변단어(입력)가 주어질 때, 중심단어(출력)을 벡터 형태로 얻는 학습
ex) 'The','fat','sat','on' -> Ypred = 'cat'
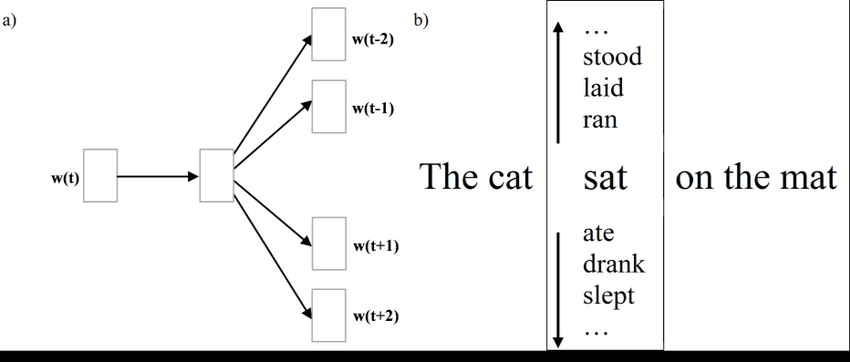
Word2Vec-Skip-gram
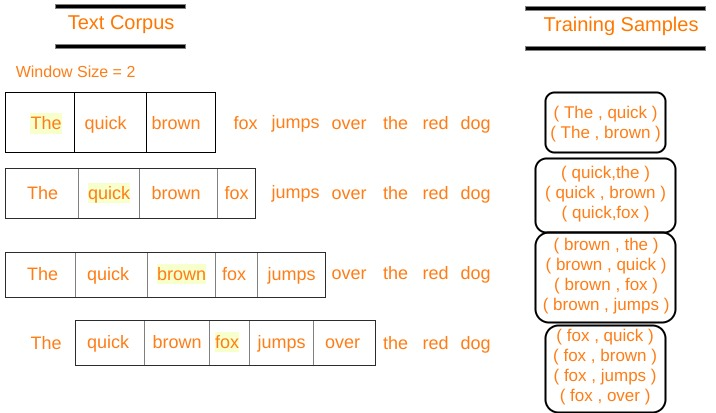
- 중심단어(입력)가 주어질 때 주변단어(출력)를 벡터 형태로 얻는 학습
ex) 'cat'-> Ypred = 'The','fat','sat','on'
의미론적 유사성 기반 인코딩
- 중심어 주위 문맥어(context word)의 등장 횟수를 기반으로 한 인코딩
- 문맥 행렬(context matrix)로 표현
- 행: 중심어, 열:문맥어
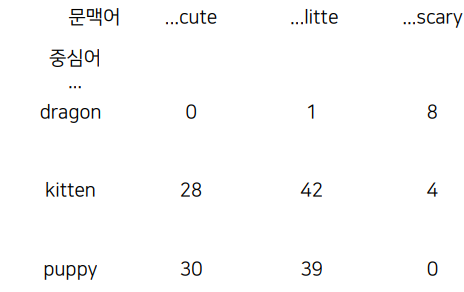
- dragon이 중심어 일때, 주위에 cute와 scary가 등장한 횟수는? 0, 8번
의미론적 유사성 기반 인코딩 손실함수 정의

Xmax의 역할
- 가중치의 개념으로 사용자가 직접 설정한 값
- 횟수에 따른 가중치 부여, 또한 너무 높은 가중치 방지(최대 1)
