자연어 처리(NLP)
- 사람의 언어를 컴퓨터가 이해, 조작, 생성할 수 있게 해주는 인공지능(ex.챗봇, 번역기, AI상담사, 검색)
말뭉치(Corpus)
- 말뭉치 : 언어 연구를 위해 특정 목적을 가지고 언어의 표본을 추출한 집합
토큰화(Tokenization)
-
토큰화 : 주어진 말뭉치(Corpus)를 토큰(token)이란 단위로 나누는 작업(토큰 -> 보통 의미가 있는 단위로 정의 (ex.단어, 구, 형태소...))
-
NLP에서 일반적으로 사용하는 전처리 과정(RNN, LSTM같은 신경망 모델에서 많이 사용)
Text -> Corpus -(전처리 과정)> Features -> 모델 -
토큰화 예시
-
단어 토큰화 : "This is a example" -> "This","is","a","example"
-
글자 토큰화 : "Tokenization" -> "T","o","k","n","i","z","a","t","o","n"
-
왜 토큰화를 쓰는가?
-
품사를 수월하게 매핑가능
('코딩','Noun'),('하느라','Verb'),('고생','Noun') -
원하지 않은 토큰 제거
조사, 욕설, 비속어 단어 제거 -
단어 사전(토큰의 리스트) 생성 가능
Corpus에서 나오는 data를 중복을 제거하고 나온 토큰으로 단어 사전을 만든다.
불용어(stop words)
- 문장 내에서 자주 등장하면서 중요한 문법적 기능 수행하지만, 언어 분석시 의미가 없는 단어들
- 문서에 출현한 용어를 빈도별로 리스트 후 stop word list 작성
- the, of, is, a/ 을, 를.... 또는 사용자가 직접 불용어 사전을 정의하기도 한다.
- 해당 분야와 의미상 관련된 용어는 포함시켜야 한다.
인코딩(Encodings)
- 텍스트를 숫자로 표현하는 작업(정수 인코딩, 원핫 인코딩...)
- 인코딩이 필요한 이유
- 컴퓨터가 읽을 수 있는 형식은 텍스트가 아닌 숫자
- 문서를 정량적으로 분석한 후 정성적인 해석 가능
단어 토큰화
- "I","am","a","boy"
- 정수 인코딩
"I":0,"am":1,"a":2,"boy":3 - 원핫 인코딩
"I":[1,0,0,0],
"am":[0,1,0,0],
"a":[0,0,1,0],
"boy":[0,0,0,1]
언어 모델(Language Model)
- 통계적 언어 모델/인공신경망의 언어 모델
- 학습을 통해 다음에 어떤 단어가 나올지 예측하는 작업
통계적 언어 모델(Statistic Language Model, SLM)
- 조건부 확률
-
사건 A가 일어났을 때 사건 B가 일어날 조건부 확률
P(B|A) = P(A∩B)/P(A)
P(A,B) = P(A)P(B|A) = P(A∩B) -
사건 (A,B)가 2개
P(A,B) = P(A)P(B|A) = P(A∩B) -
사건 (A,B,C)가 3개
P(A,B,C) = P(A)P(B|A)P(C|A,B) = P(A∩B∩C) -
사건 (E1, E2,...,En)이 n개
P(E1,E2,...,En) = P(E1)P(E2|E1)...P(En|E1...En-1) -
이를 조건부 확률의 연쇄법칙이라 한다.
- 문장의 확률
- 문장이 나올 확률
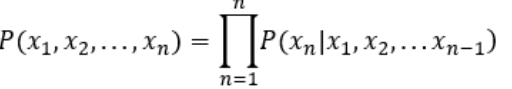
- 문장 : "나는 배가 고파서"
- P(나는 배가 고파서) = P(나는)P(배가|나는)P(고파서|나는 배가)
- P(나는 배가 고파서 밥을 먹었다) = P(나는)P(배가|나는)P(고파서|나는 배가)...P(먹었다|나는 배가 고파서 밥을)
- 카운트 기반 접근
- 확률 계산식
ex) "나는 배가 고파서" 다음에 "밥을"이 나올 확률인 P(밥을|나는 배가 고파서) 구하는 법?
P(밥을|나는 배가 고파서) = count(나는 배가 고파서 밥을)/count(나는 배가 고파서)
말뭉치 안에 각 부분이 나온 횟수를 count
count(나는 배가 고파서 밥을) = 25번
count(나는 배가 고파서) = 100번
P(밥을|나는 배가 고파서) = 25%
통계적 언어 모델의 한계점
- 희소 문제
- 글에서 특정 문장이 나오지 않는다면 확률값 계산을 할 수가 없다.
N-gram언어 모델
- SLM의 한계 해결하고자 등장
- SLM은 문장이 길어질수록 Corpus에 문장이 존재하지 않을 가능성이 높다.
- N-gram : 주어진 말뭉치에서 연속된 n글자/단어의 집합
- 전체 문장이 아닌 N개의 단어만 참고한다.
ex) "The black cat eats a muffin"
-
unigram(N=1)
The/black/cat/eats/a/muffin -
Biagram(N=2)
The black/black cat/cat eats/eats a/a muffin -
Trigram(N=3)
The black cat/black cat eats/cat eats a/eats a muffin -
4-gram(N=4)
The black cat eats/black cat eats a/cat eats a muffin -
n-gram에서 특정 단어를 예측하는데 살펴볼 앞 단어의 개수는 n-1개이다.
n-gram의 한계점
- n개의 글자만을 살펴봄으로 앞에서 무시된 글자들로 인해서 다소 맞지 않는 단어가 채택될 수 있다. -> n이 커질수록 성능은 좋아짐
- 하지만 n이 너무 커지면 SLM과 같이 말뭉치에 구문이 없을 수도 있다.(희소문제 발생)-> 완전히 해결 X
- n은 5를 넘지 않는것이 좋다.
단어 가방 모델(Bag of word,BOW)
- 문자를 숫자로 표현하는 방법 중 하나. 문장의 순서, 문맥 등을 고려하지 않고 오직 등장 횟수만 집중해 텍스트를 수치화
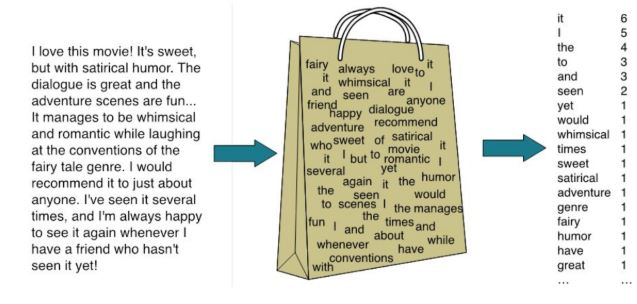
- BOW 만드는 과정
- 각 단어에 고유한 index 부여
- 각 index 위치에 단어 토큰의 등장 횟수를 기록한 vector를 만든다.
문서-단어 행렬(Document-Term metrix, DTM)
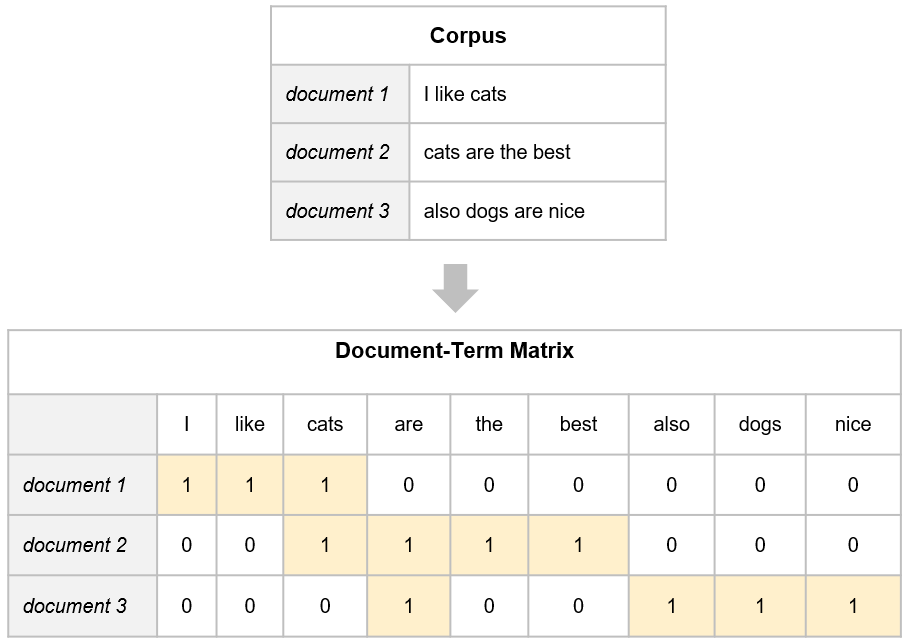
- 단어의 빈도로 문서를 분석하는데는 한계가 있다.
TF-IDF(Term Frequency-Inverse Document Frequency)
-
TF : 특정 단어가 문서에서 등장하는 빈도
-
IDF : 역 문서 빈도 - 불용어 처럼 문서와 연관성이 없음에도 자주 나오는 단어 들에게 패널티를 주기 위해 이용
-
TF-IDF의 특징
해당 문서의 단어의 출현 횟수 & 전체 문서의 단어 출현 횟수 동시 고려해 중요도 산출, 주로 문서의 유사도, 검색 결과의 중요도, 문서 내의 특정 단어의 중요도 측정에 사용된다. -
IDF = log10(N/nt)
(N: 전체 문서의 개수, nt:용어 t가 등장하는 문서의 총개수) -
각 문서에서 단어에 대한 TF를 IDF에 곱하여 TF-IDF완성(a 같은 불용어들은 모든 문서에 등장하기 때문에 IDF 값은 0또는 매우 작은 값이되어 TF-IDF 값에서 패널티를 받는다.)
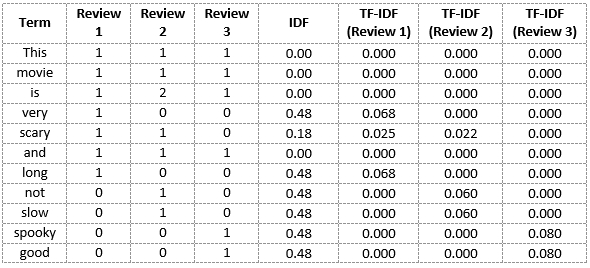
-
TF와 IDF를 결합하여 각 용어의 가중치 계산
-
적은 수의 문서(IDF값이 크다.)에 용어 t가 많이 나타날 때(TF가 크다) 가장 높은 값을 가진다.
-
모든 문서에 그 용어가 나타날때 가장 낮은 값을 가진다.
