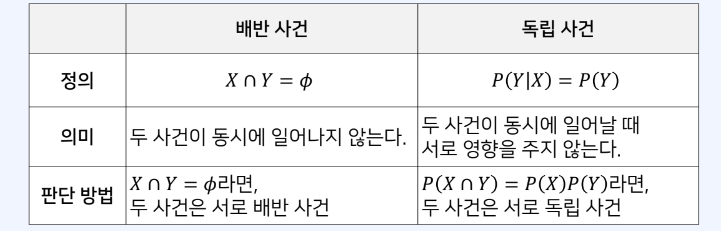
독립
- P(X∩Y) = P(X)P(Y)인 경우 두 사건 X, Y는 독립이다.
- 두 변수가 서로 영향을 주지 않는다는 의미
ex) 오늘 동해바다에서 고래가 발견되는 사건 / 내가 시험에서 100점 맞는 사건
종속
- 한 사건의 결과가 다른 사건에 영향을 줄 때 이 두 사건 X, Y를 종속 사건이라 한다.
ex) (일반적으로 국어 점수가 높으면 영어 점수가 높다) 국어 100점맞는 사건/영어 100점 맞는 사건
배반 사건
- 교집합이 없는 사건
ex) 내 키가 170이 넘는 사건/ 내 키가 170이 넘지않는 사건
배반 VS 독립
다변수 확률 변수
- 확률 변수가 2개 이상인 경우
- 개별적인 확률 변수에 대한 확률 분포를 고려할 수 있다.
- 두 확률 변수 모두 고려한 복합적인 확률 분포를 계산할 수 있다.
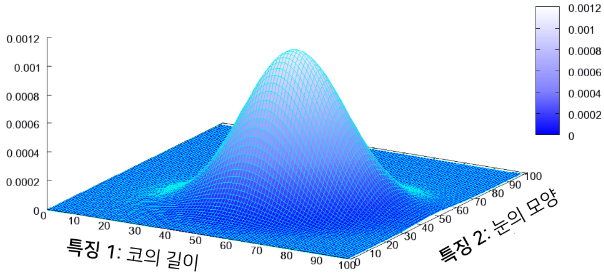
다변수 확률 분포
- 딥러닝 분야 분포는 일반적으로 다변수 확률 분포에 해당
- 얼굴 특징에 대한 확률 분포 예시
결합 확률
- 두 개의 사건이 동시에 일어날 확률, 두 확률 변수의 교집합이 발생할 확률
- P(X,Y) 또는 P(X∩Y) 형태로 표현
결합 확률 함수
- 이산 확률 변수 X, Y에 대해 결합 확률 함수 fxy(xi, yi) = P(X = xi, Y = yi)이다.
- X가 x1,x2,......, Y가 y1,y2,.........의 값을 가질 수 있다고 가정한다.
- f(x, y)라고 쓰기도 한다.
- X, Y가 가진 범위 내에서 결합확률함수의 값을 모두 더하면 1이다.
결합 확률 질량 함수 예시
-
랜덤으로 1~9 중하나를 출력하는 기계존재
-
이 기계를 한번 동작시킴
-
- 얻은 수가 짝수 X=0, 홀수 X=1
-
- 얻은 수가 소수가 아님 Y=0, 소수 Y = 1
-
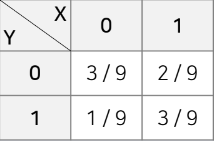
얻을 수 있는 X, Y 값

-
결합 확률 함수
-
f(0,0) = 3/9
-
f(0,1) = 1/9
-
f(1,0) = 2/9
-
f(1,1) = 3/9
-
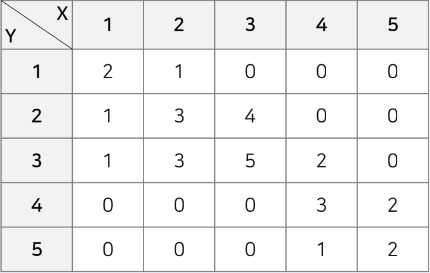
국어 등급이 1~5등급
-
영어 등급이 1~5등급
-
국어 등급 확률 변수 X
-
영어 등급 확률 변수 Y
-
국어 등급이 높을 때 영어 등급이 높은가? -> 결합 확률 분포 확인하여 경향 파악
-
다음을 결합 확률 질량함수로 표현해보자
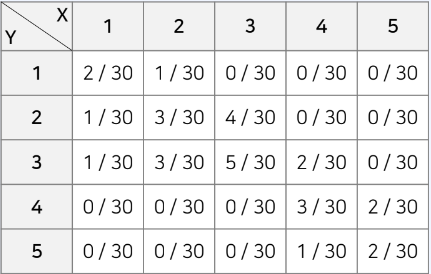
결합 확률 질량함수
- 이산 확률 변수가 2개 이상인 확률 질량함수이다.
- 확률은 PXY(x,y) = P(X=x, Y=y) 형태로 표현
- 또한 이때 원소의 총합은 1이다.
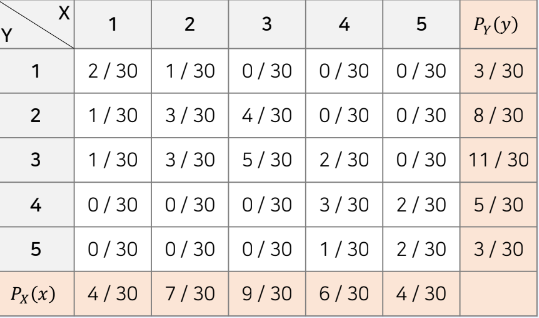
- 전체 학생수가 30명일 때 국어가 1등급이며 영어가 2등급인 학생
PXY(1,2) = P(X = 1, Y = 2) = 1/30
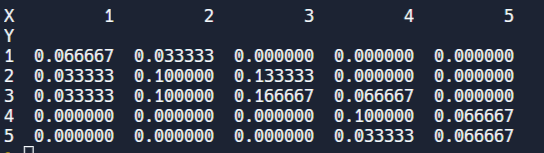
결합 확률 질량함수 파이썬 소스코드
- 위 국어와 영어 성적에 대한 결합 확률 질량함수는
import pandas as pd
scores = [1,2,3,4,5]
people_num = [[2,1,0,0,0],
[1,3,4,0,0],
[1,3,5,2,0],
[0,0,0,3,2],
[0,0,0,1,2]]
df = pd.DataFrame(people_num, index=scores, columns =scores)
df.columns.name = "X"
df.index.name = "Y"
pmf = df/df.values.sum()
print(pmf)-
결과 값
-
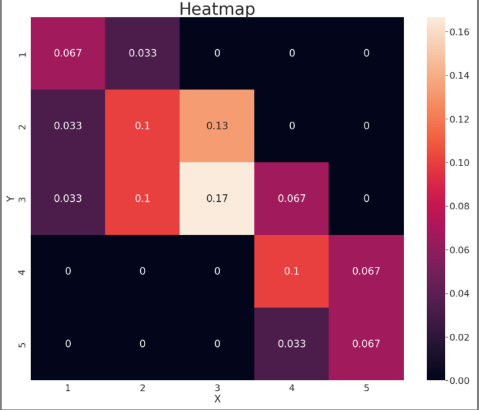
히트맵 이용
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
scores = [1,2,3,4,5]
people_num = [[2,1,0,0,0],
[1,3,4,0,0],
[1,3,5,2,0],
[0,0,0,3,2],
[0,0,0,1,2]]
df = pd.DataFrame(people_num, index=scores, columns =scores)
df.columns.name = "X"
df.index.name = "Y"
pmf = df/df.values.sum()
sns.set(font_scale = 2) # 폰트 규모 지정
plt.rcParams["figure.figsize"] = [20,16] # plot의 크기 지정
ax = sns.heatmap(pmf, annot=True,# annot 수치표시
xticklabels = [1,2,3,4,5],
yticklabels = [1,2,3,4,5])
plt.title("Heatmap", fontsize=40)
plt.show()
주변 확률 질량함수
- 두 확률 변수 중에서 하나의 확률변수에 대해서만 확률 분포를 나타낸 함수
- PX(x) = PXY(x,yi)에서 모든 yi값을 더한값
- PY(y) = PXY(xi, y)에서 모든 xi값을 더한값
ex) 국어가 1등급일 확률은 다음과 같다.
PX(1) = PXY(1,1)+PXY(1,2)+PXY(1,3)+PXY(1,4)+PXY(1,5) - 즉 X = 1 고정하고 모든 Y변수에 대한 확률값을 더해준다.
- 모든 X에 대해 표현하면 주변 확률 질량함수가 된다.
주변확률 질량함수 예시
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
scores = [1,2,3,4,5]
people_num = [[2,1,0,0,0],
[1,3,4,0,0],
[1,3,5,2,0],
[0,0,0,3,2],
[0,0,0,1,2]]
df = pd.DataFrame(people_num, index=scores, columns =scores)
df.columns.name = "X"
df.index.name = "Y"
pmf = df/df.values.sum()
index = 0
x = [0,1,2,3,4]
plt.bar(x, pmf.iloc[index]) #iloc : 행번호로 선택
plt.xticks(x, ["1","2","3","4","5"])
plt.title(f"P(X, Y={index+1})")
plt.show()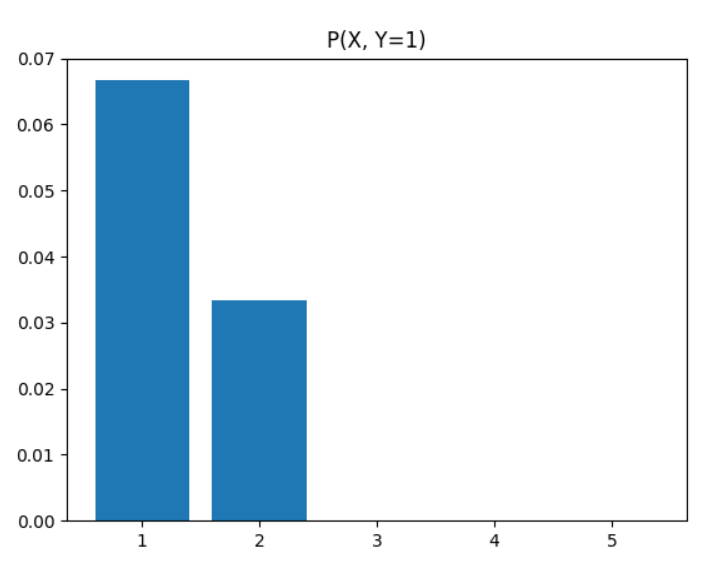
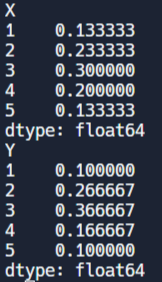
marginal_pmf_x = pmf.sum(axis=0)
print(marginal_pmf_x)
marginal_pmf_y = pmf.sum(axis=1)
print(marginal_pmf_y)