조건부 확률
-
어떠한 사건이 일어나는 경우 다른 사건이 일어날 확률
-
딥러닝 분야에서 "X사건이 단서일때, Y사건이 발생할 확률"로 이해 가능
-
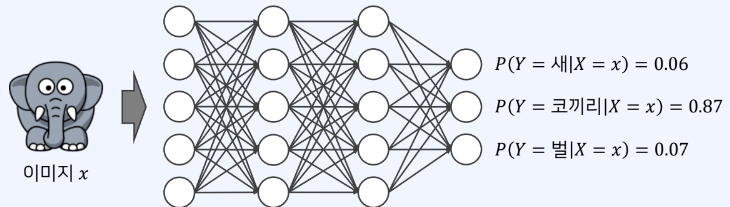
분류 모델은 일반적으로 다음과 같이 동작
-
이미지 x가 입력, 클래스 y사 나올 확률
P(Y=y|X=x)
-
특정 사건이 발생하는 경우에 다른 사건이 발생할 확률
-
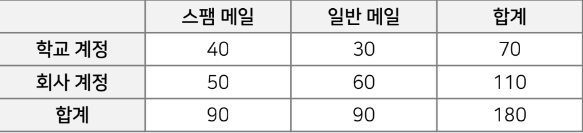
하나의 메일을 뽑았을 때 학교 계정의 메일일 확률
P(학교) = 70/180 -
하나의 메일을 뽑았을 때 학교 계정으로 온 메일이면서 스팸일 확률(결합 확률)
P(학교 ∩ 스팸) = 40/180 -
스팸 메일중 하나를 뽑았을 때 학교 계정으로 온 메일일 확률(조건부 확률)
P(학교|스팸) = 40/90
조건부 확률 질량 함수
- 조건부 확률 질량함수 공식 : PY|X(y|x) =PXY(x,y)/PX(x)
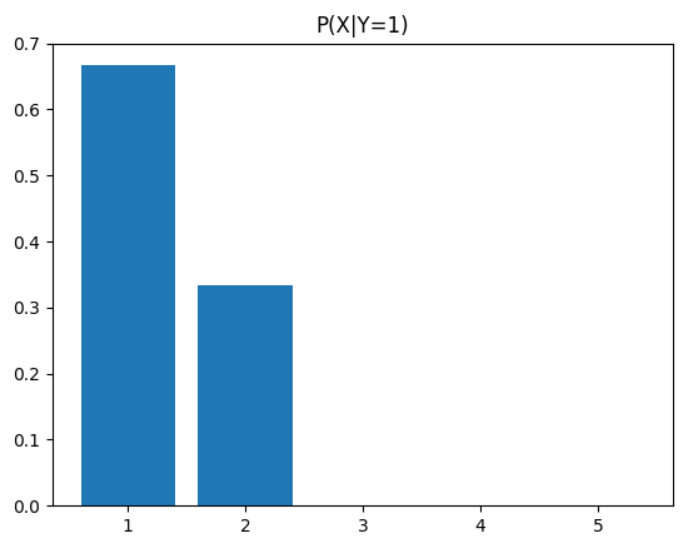
- 영어 성적(Y)이 1등급일 때, 국어 성적(X)이 1등급일 확률?
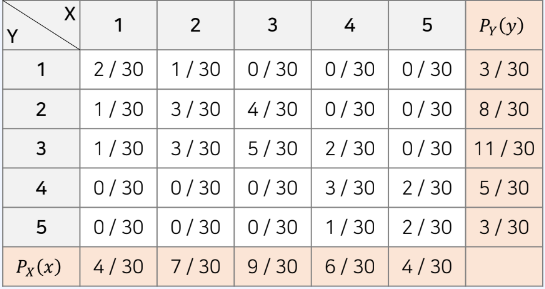
-> 2/3
파이썬을 이용한 조건부 질량함수
import pandas as pd
import matplotlib.pyplot as plt
scores = [1,2,3,4,5]
people_num = [[2,1,0,0,0],
[1,3,4,0,0],
[1,3,5,2,0],
[0,0,0,3,2],
[0,0,0,1,2]]
df = pd.DataFrame(people_num, index=scores, columns =scores)
df.columns.name = "X"
df.index.name = "Y"
pmf = df/df.values.sum()
marginal_pmf_y = pmf.sum(axis=1)
index = 0
x = [0,1,2,3,4]
plt.bar(x, pmf.iloc[index] / marginal_pmf_y[index+1])
plt.xticks(x, ["1","2","3","4","5"])
plt.title(f"P(X|Y={index+1})")
plt.show()