문제 상황(스팸 분류 모델)
- 입력 : 하나의 텍스트
- 출력 : 텍스트가 특정 클래스에 속할 확률
- 목표 : 하나의 텍스트(x) 가 스팸(y)일 확률 계산
- 텍스트의 확률 변수를 X, 클래스의 확률 변수를 Y라고 하자
- 클래스 2개 존재 y1 = 햄, y2 = 스팸
베이즈 정리
-
P(Y|X)를 계산할 수 있으면 우리가 원하는 프로그램을 만들 수 있다.
-
하지만 P(Y|X) 직접 구하기 어려울 때 이용한다.
-
베이즈 정리 공식

-
베이즈 정리란 조건부 확률을 구하는 공식이다.
-
베이즈 정리 공식 P(A|B) = P(B|A)P(A)/P(B)
문제 해결
- 스팸이 70%, 정상 30%
- 스팸중에 대출 이란 단어 포함 90%
- 정상중에 대출 이란 단어 포함 3%
- 대출 이란 단어가 들어 있는 메일이 스팸일 확률?
P(스팸) = 0.7
P(정상) = 0.3
P(대출|스팸) = 0.9
P(대출|정상) = 0.03
구하고자 하는 값 P(스팸|대출) = P(대출|스팸)P(스팸)/P(대출)
즉, P(대출)을 구해야 하는데 이는 P(대출,스팸)+P(대출,정상) = 0.7X0.9 + 0.3X0.03 = 0.639
즉, P(스팸|대출) = 0.9X0.7/0.639 가 된다.
확률 모델
- 일반적인 분류 모델 P(y|x)는 다음과 같은 공식으로 예측결과 ŷ를 계산한다.
- ŷ = argmaxyP(y|x) (argmax: 이런 값을 최대화 하는 y를 찾겠다.
황금 법칙
- 텍스트 x가 주어졌을 때 이 텍스트는 어떤 클래스로 분류될까?
- argmaxyP(y|x) = argmaxyP(x|y)P(y)/P(x) = argmaxyP(x|y)P(y)
- 분모에 해당하는 P(x)를 고려하지 않아도 된다.
최대 우도 추정(Maximum Likelihood Estimation)
- 가능도가 가장 높은 클래스를 선택하는 방법
- X는 특징 혹은 데이터를 말한다.
- X = 광고성 단어의 개수라고 해보자
- 현재 예시에선 X>=5 를 스팸이라 분류하면 된다.
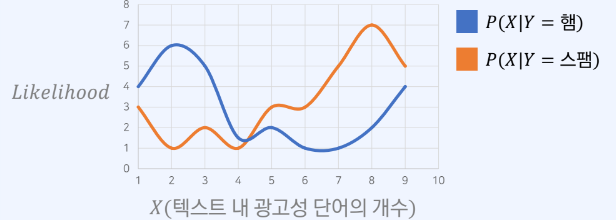
최대 우도 추정시 유의할 점
-
사후 확률(posterior)을 직접 계산하기 어렵기 때문에 가능도를 이용한다.
-
하지만 가능도만으로 사후 확률을 완전히 근사할 수 없다.
P(Y|X) = P(X|Y)P(Y)/P(X)
posterior ∝ likelihood X prior -
만약 prior가 uniform distribution을 따르지 않는다면?
- 전체 메일 중에서 스팸 메일의 수 자체가 적다고 하자
- P(Y = 스팸) = 1/3, P(Y = 햄) = 2/3
- 분포는?
- X>= 6일때 스팸으로 분류하면 된다.
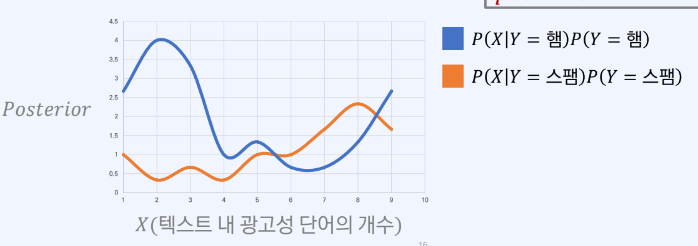
정리
- prior를 고려할 떼 posterior를 더 잘 계산 가능
- 나이브 베이즈 분류기에서 사용됨
