Attention
why was it proposed ?
- 순환신경망 기반의 seq2seq 모형이 갖는 문제점 보완하기 위해
- 순환신경망 기반의 seq2seq 의 주요한 문제점
- 입력된 sequence data에 대해서 하나의 고정된 벡터 정보 ( 마지막 hidden state ) 만을 decoder로 전달한다는 것
그렇게 되면 입력된 모든 단어들의 정보가 제대로 전달되지 못한다는 문제 발생
특히, 입력된 단어가 많은 경우 앞쪽에서 입력된 단어들의 정보는 전달이 거의 안되는 문제 발생
어떻게 하면 되는가 ?
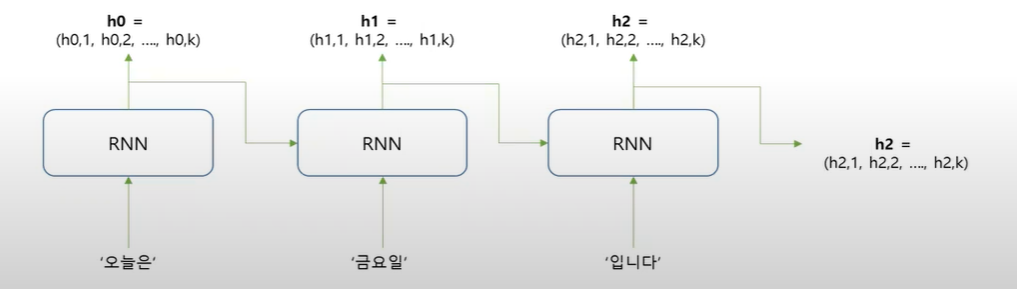
- Encoder 부분에서 생성되는 각 단어에 대한 hidden state 정보를 모두 decoder로 전달
- ex) '오늘은 금요일 입니다' → 'Today is Friday' 를 번역하는 경우
- 특정한 timestep 에서 예측을 하고자 하는 단어가 있다 만약 Friday라고 하는 단어를 decoder 부분에서 예측을 하고자 할 때 encoder 부분에서 전달이 된 모든 단어들에 대한 hidden state vector 정보를 모두 사용한다. 어떠한 방식으로 vector 를 사용하냐면 해당 timestep에서 decoder가 예측을 하고자하는 단어, 즉 Friday라고 하는 단어와 관련이 상대적으로 높은 단어에 더 큰 가중치를 준다.
'Today'를 예측하는 경우
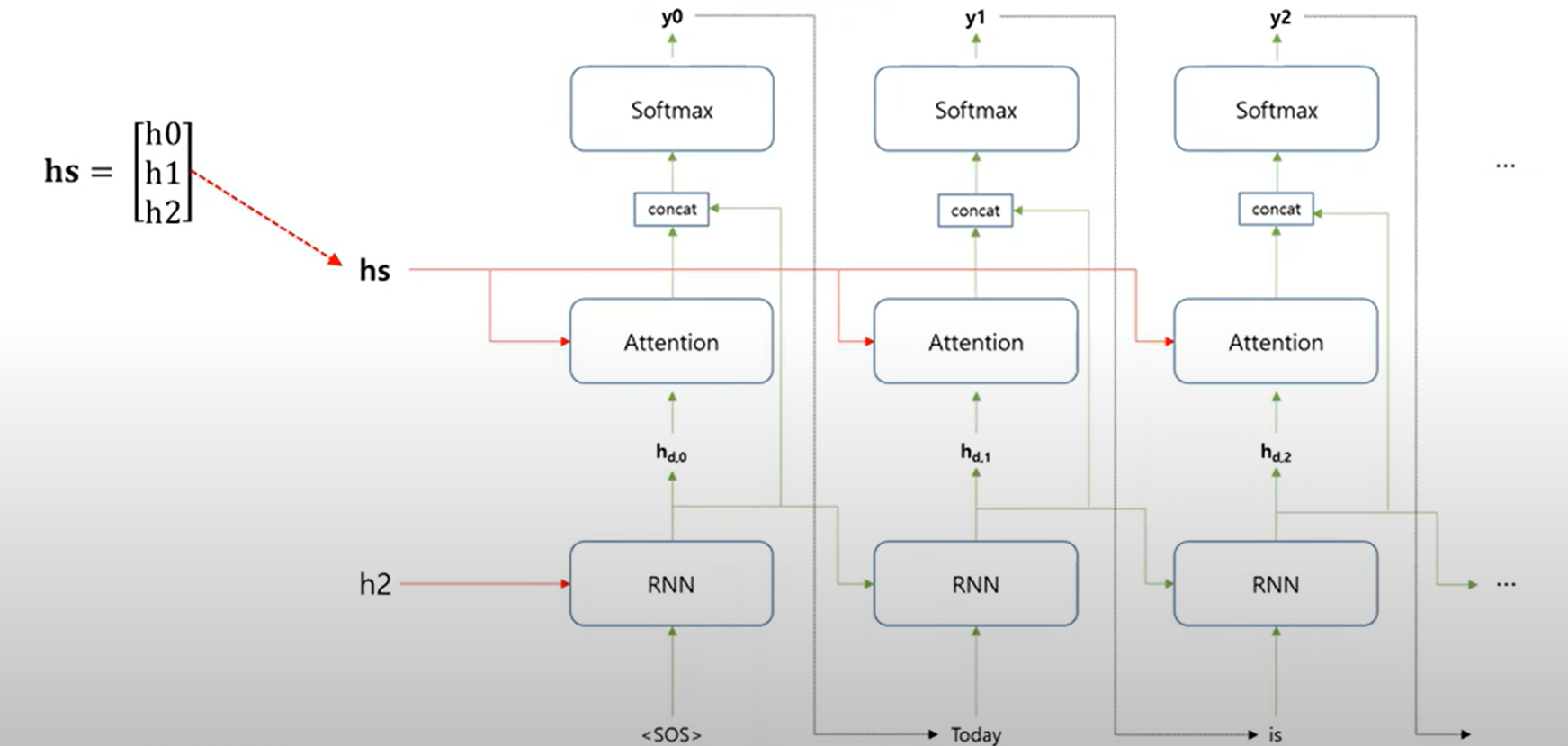
첫번째 어텐션, decoder에서 예측을 하고자 하는 단어는 'Today' 라는 단어이다.
hs = [ h0, h1, h2 ] 이 세계의 hidden state vector에 'Today'하고 관련이 제일 높은 encoder에 입력이 된 단어에 대한 hidden state vector 인 h0에 가장 큰 가중치를 주게 된다. 이러한 점이 attentio 가장 핵심적인 부분이다.
가중치의 계산
-
가중치는 hs의 각 hidden state와 decode에 예측하고자 하는 단어에 대한 hidden state와의 유사도를 가지고 계산
-
hidden state 간의 유사도를 계산 => 내적 연산
-
decoder 부분의 첫번째 RNN 층 에서 출력되는 'Today' 단어를 예측하는데 사용되는 hidden state =>hd,0 = ( 1 0 0 0 2 )
-
h0, h1,h2와 hd,0과의 내적 연산 이 값들을 attention score 라고 함 -> attention score의 값이 클수록 관련도가 크다는 것을 의미
-
attention score 를 가지고 가중치를 계산
-
가중치는 확률값으로 표현
-
확률 값을 계산하기 위해 attention score에 softmax() 적용
Self-attention
Attention과의 차이
- Attention은 encoder-decoder 모형에서 보통 decoder에서 encoder에서 넘어오는 정보에 가중치를 주는 식으로 작동
- Self-attention은 입력된 텍스트 데이터 내에 존재하는 단어들 간의 관계를 파악하기 위해 사용
- 관련이 높은 대명사에 더 많은 가중치를 주기 위해 사용 - 지시대명사가 무엇을 의미하는지 등을 파악하는데 유용
- Example
- 입력 데이터 : The dog likes an apple. It has a long talil
- 이러한 경우, 입력된 데이터 내에 존재하는 다른 단어들하고의 관계를 파악 가능하다면, it이 dog라는 단어와 관련이 높다는 것을 알 수 있음.
- it을 예측하는데 있어서 dog에 더 많은 가중치를 준다. - self-attention는 단어들의 hidden state vector 정보를 사용해 내적 연산을 하는 것이 아니라, 단어들의 embedding vector(자기자신포함) 이용해 내적 연산을 수행해 단어드르이 유사정도를 파악
- 가중치의 값 계산 => Attention Score Softmax()에 적용하여 계산
Transformer에서의 self-attention
- 앞의 설명은 입력된 단어들의 임베딩 정보, 그대로 사용하여 attention score와 가중치를 구한다고 설명
- Transformer의 self-attention은 입력 받은 단어들 중에서 어떠한 단어에 더 많은 가중치를 줘야하는지 파악하기 위해서 각 단어들에 대한 Query, Key, Value 라고 하는 서로 다른 3개의 벡터들을 사용
- Key, Value 벡터들은 사전 형태의 데이터 의미 : Key는 단어의 id와 같은 역할, Value는 해당 단어에 대한 구체적 정보를 저장하는 역할을 한다고 생각
- Query 벡터는 유사한 다른 단어를 찾을 때 사용되는 ( 질의 ) 벡터라고 생각
작동순서
단계 1 : 입력된 각 단어들에 대해서 Query, Key, Value 벡터를 계산
- 이때 각각의 가중치 행렬이 사용 됨
단계 2 : Attention score 계산
- Query를 이용해서 각 Key 들하고의 유사한 정도를 계산 => 내적 연산
단계 3 : Attention score를 이용하여 가중치를 계산
- Softmax() 함수를 적용
단계 4 : 가중치를 Value 벡터에 곱한다
최종결과물
- 가중치가 곱해진 value vector들의 합
수식으로 표현
-
Q는 Query 벡터들에 대한 행렬
-
k는 Key 벡터들에 대한 행렬
-
V는 Value 벡터들에 대한 행렬
-
는 K 행렬의 전치행렬 ( Transpose )
-
Q와 의 곱하기는 Query 벡터들과 Key벡터들의 내적연산을 의미
