기존 연구의 한계
Domain-Specific Training의 제약
파인튜닝 의존:
- 초기 딥러닝 모델(GPT-1, BERT 등)은 도메인별 파인튜닝 과정을 거쳐야 했습니다.
- 각 테스크에 맞게 모델의 레이어를 수정하거나, 수백~수천 개의 예제 데이터가 필요했습니다.
일반화의 한계:
- 이러한 방식은 모델이 특정 도메인에 특화되도록 학습되므로, 전체적인 범용 언어 이해 및 다양한 테스크 수행 능력을 제한할 수 있습니다.
기존 머신러닝 모델의 데이터 한계
제한된 예제 수:
- 기존 시스템은 특정 테스크를 위해 데이터셋에서 제한된 수의 예제(수백~수천 개)에 의존했습니다.
모든 테스크에 대응의 어려움:
- 모든 도메인과 테스크에 대해 맞춤 데이터 쌍을 만드는 것은 현실적으로 매우 어렵습니다.
다중 테스크 학습의 필요성:
- 이러한 한계를 극복하기 위해 다양한 테스크를 동시에 학습하는 다중 테스크 학습(Multitask Learners)이 효과적이라는 주장이 제기되었습니다.
제안 방법론
Language Modeling을 통한 범용 학습
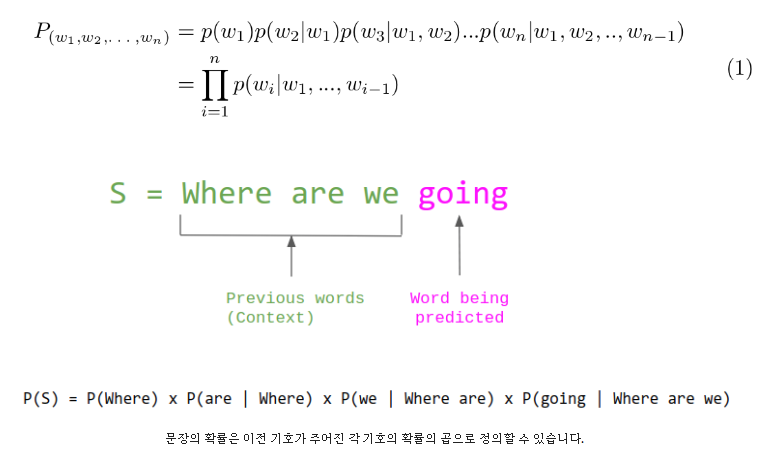
단일 모델로 다양한 테스크 수행
Language Modeling 기법:
- GPT-2는 GPT-1과 마찬가지로 “다음 단어 예측” 방식을 사용하여 사전학습(pretraining)을 진행합니다.
- 모델은 단순히 입력 텍스트에 기반해 p(output ∣ input)을 추정하지만, 암묵적으로 테스크 지시나 문맥 정보를 포함할 수 있어 p(output ∣ input, task)와 같은 효과를 나타냅니다.
학습 전략:
- 단일 과정으로 다양한 테스크를 동시에 학습함으로써, 별도의 파인튜닝 없이도 Zero-shot, Few-shot 학습이 가능해집니다.
- 실험 결과, 큰 모델의 경우 p(output ∣ input) 방식이 p(output ∣ input, task) 방식보다 학습 속도는 다소 느리지만, 최종 성능과 범용성에서는 뛰어난 결과를 보여줍니다.
Zero-shot 학습의 가능성
데이터의 다양성과 일반화:
- 대규모 텍스트 말뭉치를 활용함으로써, 모델은 다양한 도메인에서 명시적인 테스크 지시 없이도 스스로 적절한 작업을 수행하는 법을 학습합니다.
범용 언어 이해:
- 충분한 데이터와 모델 크기가 확보되면, 언어 모델은 특정 도메인에 국한되지 않고 언어의 본질적인 구조와 의미를 파악할 수 있게 됩니다.
Training Dataset: WebText 구축
데이터 품질과 다양성 확보
기존 데이터셋의 한계:
- 기존 모델들은 뉴스, 위키피디아, 소설 등 상대적으로 단일 도메인 데이터셋에 의존했습니다.
WebText 데이터셋:
- GPT-2 연구진은 웹에서 더 다양하고 풍부한 텍스트 데이터를 확보하기 위해 WebText라는 새로운 데이터셋을 구축했습니다.
- 구성 과정:
- Reddit에서 3 karma 이상을 받은 45M 개 이상의 글을 수집.
- 중복되거나 낮은 품질의 콘텐츠를 휴리스틱 기반으로 제거.
- 최종적으로 약 800만 개의 문서, 총 40GB 분량의 데이터를 확보.
의의:
- 다양한 출처에서 온 데이터는 모델이 여러 도메인에서 일반적인 패턴과 언어적 특징을 학습하는 데 큰 도움을 주었습니다.
Input Representation: 효율적인 토큰화 전략
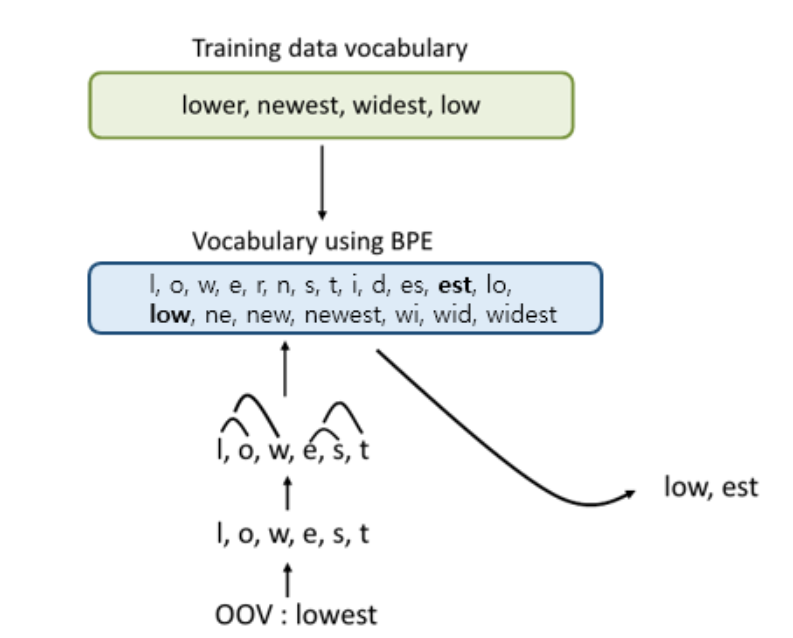
BPE와 Vocabulary 최적화
Byte Pair Encoding (BPE):
- GPT-2는 단어와 문자 사이의 중간 표현으로 BPE를 활용하여 텍스트를 토큰 단위로 인코딩합니다.
- 유니코드 단위에서 동작하여 약 13만 개의 Vocabulary를 생성할 수 있으나, 이는 비효율적일 수 있음.
최적화 고려:
- 만약 byte 수준에서 동작한다면 256개만의 Vocabulary가 필요하지만, 이 경우 그리디 기반 휴리스틱에 따라 불필요한 토큰이 많이 생성될 위험이 있습니다.
- GPT-2는 문자 수준 이상의 병합을 억제하여, 제한된 Vocabulary 공간 내에서 효율적으로 언어 정보를 표현할 수 있도록 설계되었습니다.
Model
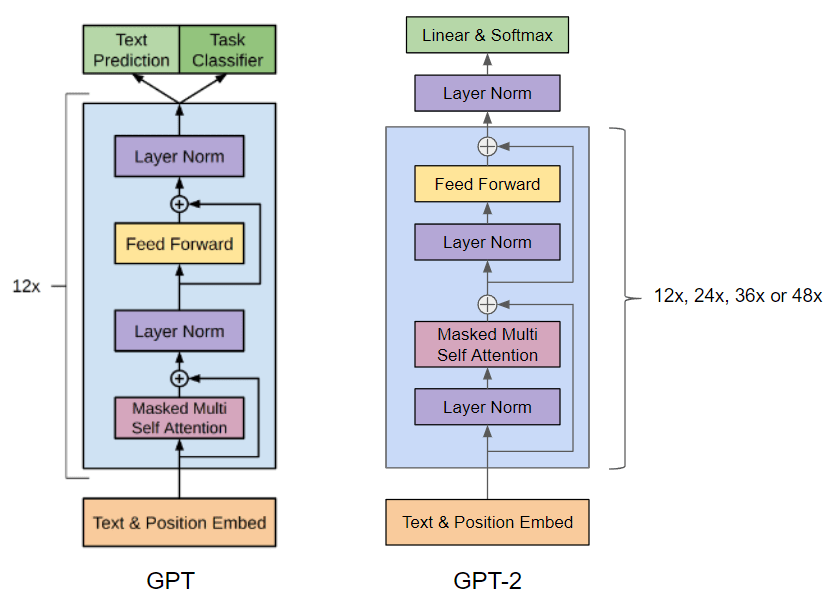
Transformer 기반 Decoder 구조
모델 아키텍처:
- GPT-2는 Transformer의 Decoder 구조를 기본으로 하며, Masked Multi-Self Attention과 Feed Forward 네트워크로 구성됩니다.
Layer Normalization 적용:
- 각 레이어의 입력에 LayerNorm을 적용하고, 최종 디코더 블록 이후에도 추가적인 LayerNorm을 거쳐 안정적인 학습을 도모합니다.
가중치 초기화:
- Residual layers의 수에 따라 1/√(N) (N: residual layer 수) 스케일링을 적용해, 깊은 네트워크에서도 안정적인 학습이 가능하도록 초기화합니다.
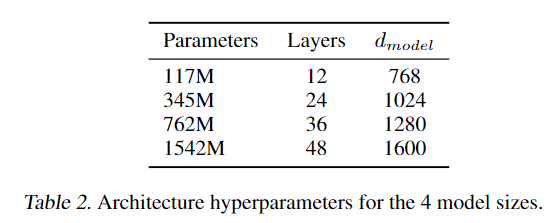
모델 스케일과 Zero-shot 성능
모델 크기 분류:
- GPT-2는 small, medium, large, extra-large 등 다양한 크기로 제공되어, 모델의 규모에 따른 성능 차이를 확인할 수 있습니다.
Zero-shot 학습 입증:
- 대규모 데이터(WebText)와 모델의 크기 덕분에, GPT-2는 사전학습만으로도 여러 도메인에서 Zero-shot 성능을 성공적으로 발휘합니다.
BERT와의 비교:
- 논문에서는 양방향(Bidirectional) 언어 모델인 BERT와 달리, 단방향(Language Modeling) 방식이 충분한 데이터와 모델 규모에서 더 일반화된 성능을 낼 수 있음을 주장합니다.
결론
GPT-2 논문은
기존의 도메인 특화 학습 방식을 극복:
- 파인튜닝 없이 하나의 모델로 다양한 테스크를 수행할 수 있도록 제시하며, 범용 언어 이해의 가능성을 입증합니다.
방대한 WebText 데이터셋 활용:
- 다양한 도메인의 데이터를 통해 모델이 폭넓은 언어 패턴과 테스크 수행 방법을 스스로 학습하도록 설계되었습니다.
효율적인 입력 표현 및 모델 구조:
- 최적화된 BPE 토큰화와 Transformer 기반 모델 구조로, 제한된 Vocabulary 공간을 효율적으로 활용하며 안정적인 학습을 달성합니다.
Zero-shot 학습 능력 증명:
- 대규모 모델과 데이터셋이 결합되면, 명시적인 테스크 지시 없이도 모델이 여러 작업을 자동으로 수행하는 놀라운 성능을 보입니다.

이상억