
자주 사용 되는 Python 라이브러리
| 주요 용도 | 패키지 | 설명 |
|---|---|---|
| 배열 / 선형대수 | numpy | 행렬이나 다차원배열을 쉽게 처리할 수 있도록 지원 |
| 통계 | scipy | 통합 패키지, 자연과학 분야에서 사용 |
| 데이터 다루기 | pandas | 데이터 프레임을 이용한 대규모 데이터 처리를 지원 |
| 머신러닝 | scikit-learn | 다양한 머신러닝 기법들을 패키지로 제공 |
| 딥러닝 | tenserflow | 인공신경망을 구현하기 위한 파이썬 패키지 (구글) |
| 딥러닝 | keras | 딥러닝 모델 개발을 위한 기능을 제공 |
| 딥러닝 | pytorch | 파이썬 기반 머신러닝 라이브러리 (페이스북) |
| 시각화 | matplotlib | 파이썬에서 그래프 등 다양한 시각화 기능을 제공 |
| 시각화 | seaborn | matplotlib 에 비해 그래프 종류는 적으나 사용이 간편함 |
파이썬 함수 선언 보는 방법
1. help() 함수 사용하기
Python의 내장 함수인 help()를 사용하면 함수나 클래스의 선언문과 그에 대한 설명을 볼 수 있습니다.
import numpy as np
help(np.array)2. ? 연산자 사용하기
Jupyter Notebook/Lab에서는 ? 연산자를 사용하여 함수나 클래스의 문서화를 볼 수 있습니다.
import pandas as pd
pd.DataFrame?3. ?? 연산자 사용하기
?? 연산자를 사용하면 함수나 클래스의 소스 코드까지 볼 수 있습니다.
import matplotlib.pyplot as plt
plt.plot??4. Shift + Tab 사용하기
Jupyter Lab에서 함수나 클래스의 이름 뒤에 커서를 두고 Shift + Tab 키를 누르면 해당 함수나 클래스의 간략한 설명을 볼 수 있습니다. 이 키를 두 번 연속 누르면 더 자세한 설명을 볼 수 있습니다.
예시:
import seaborn as sns
sns.heatmap( # 여기서 Shift + Tab 키를 누르세요.5. IPython의 pinfo와 pinfo2 매직 명령어 사용하기
IPython 환경에서는 %pinfo와 %pinfo2 매직 명령어를 사용할 수 있습니다.
%pinfo np.mean
%pinfo2 np.meanNumpy
Numarray와 Numeric이라는 오래된 Python 패키지를 계승해서 나온 수학 및 과학 연산을 위한 파이썬 패키지이다. Py는 파이썬을 나타내기 때문에, 일반적으로 넘파이라고 읽는다.
np 메서드 목록
| 중요 | 함수 | 설명 |
|---|---|---|
| ✅ | np.array(object, dtype=None, copy=True, order='K', subok=False, ndmin=0) | 입력 데이터를 배열로 변환 |
| ✅ | np.zeros(shape, dtype=float, order='C') | 모든 요소가 0인 배열 생성 |
| ✅ | np.ones(shape, dtype=None, order='C') | 모든 요소가 1인 배열 생성 |
| np.zeros_like(a, dtype=None, order='K', subok=True) | 주어진 배열과 동일한 형태의 모든 요소가 0인 배열 생성 | |
| np.ones_like(a, dtype=None, order='K', subok=True) | 주어진 배열과 동일한 형태의 모든 요소가 1인 배열 생성 | |
| ✅ | np.identity(n, dtype=None) | 주대각선이 1이고 나머지가 0인 단위 행렬 생성 |
| ✅ | np.arange(start, stop, step, dtype=None) | 지정된 범위 내에서 균일하게 떨어진 값들로 배열 생성 |
| ✅ | np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None) | 지정된 구간을 균일하게 나눈 값들로 배열 생성 |
| ✅ | np.reshape(a, newshape, order='C') | 배열의 형태를 변경 |
| np.ravel(a, order='C') | 배열을 1차원으로 펼침 | |
| np.transpose(a, axes=None) | 배열의 축을 교환 | |
| np.concatenate((a1, a2, ...), axis=0, out=None, dtype=None, casting="same_kind") | 배열을 지정된 축을 따라 연결 | |
| np.stack(arrays, axis=0, out=None) | 배열들을 새로운 축을 따라 쌓음 | |
| np.hstack(tup) | 배열을 수평으로 쌓음 | |
| np.vstack(tup) | 배열을 수직으로 쌓음 | |
| ✅ | np.sum(a, axis=None, dtype=None, out=None, keepdims=False) | 배열의 요소들의 합계 반환 |
| ✅ | np.mean(a, axis=None, dtype=None, out=None, keepdims=False) | 배열의 요소들의 평균값 반환 |
| ✅ | np.max(a, axis=None, out=None, keepdims=False, initial=) | 배열의 요소들 중 최대값 반환 |
| ✅ | np.min(a, axis=None, out=None, keepdims=False, initial=) | 배열의 요소들 중 최소값 반환 |
| ✅ | np.argmax(a, axis=None, out=None) | 배열의 요소들 중 최대값을 가지는 요소의 인덱스 반환 |
| ✅ | np.argmin(a, axis=None, out=None) | 배열의 요소들 중 최소값을 가지는 요소의 인덱스 반환 |
| ✅ | np.sort(a, axis=-1, kind='quicksort', order=None) | 배열을 지정된 축을 따라 오름차순으로 정렬 |
| np.argsort(a, axis=-1, kind='quicksort', order=None) | 배열을 정렬했을 때의 인덱스를 반환 | |
| np.partition(a, kth, axis=-1, kind='introselect', order=None) | 배열을 지정된 축을 따라 kth 개수만큼 정렬 | |
| np.argpartition(a, kth, axis=-1, kind='introselect', order=None) | 배열을 부분적으로 정렬했을 때의 인덱스를 반환 | |
| np.dot(a, b, out=None) | 두 배열의 내적을 계산 | |
| np.matmul(a, b, out=None) | 두 배열의 행렬 곱을 계산 | |
| np.where(condition, [x, y, ] / ) | 조건에 따라 선택된 요소들을 반환 | |
| np.clip(a, a_min, a_max, out=None) | 배열의 값을 지정된 최소값과 최대값으로 자름 | |
| np.isnan(x) | 배열의 요소가 NaN인지 여부를 확인 | |
| ✅ | np.all(a, axis=None, out=None, keepdims=False) | 배열의 모든 요소가 참인지 확인 |
| ✅ | np.any(a, axis=None, out=None, keepdims=False) | 배열의 요소 중 하나라도 참인지 확인 |
| ✅ | np.unique(ar, return_index=False, return_inverse=False, return_counts=False, axis=None) | 배열의 고유한 요소들로 구성된 배열 반환 |
| ✅ | np.isin(element, test_elements, assume_unique=False, invert=False) | 요소가 다른 배열의 요소인지 여부를 반환 |
| np.trace(a, offset=0, axis1=0, axis2=1, dtype=None, out=None) | 배열의 주대각선 요소들의 합계 반환 | |
| np.setdiff1d(arr1, arr2) | arr1 - arr2 (차집합 연산) |
ndarray
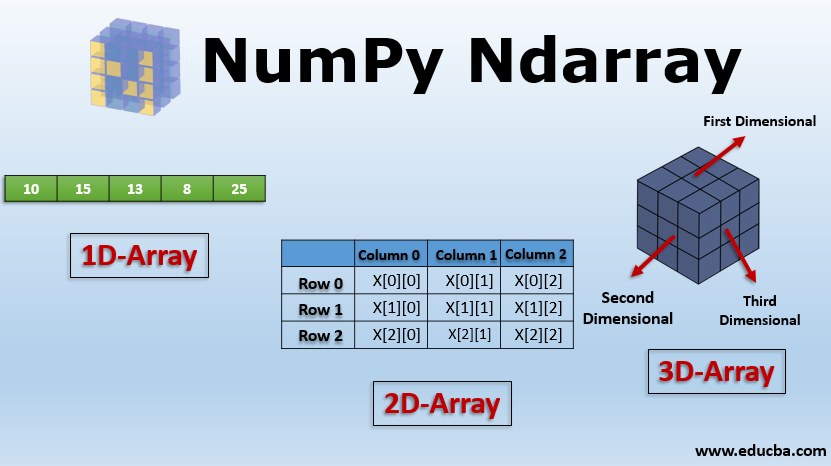
- 메모리 효율적인 벡터 산술 연산 기능 제공
- 반복문 없이 전체 데이터 배열 일괄 연산 기능 제공
- 선형대수, 난수 발생, 푸리에 변환 등 다양한 연산 기능 제
내부 구성
ndim- 차원수
- type은 int
shape- 행렬 모양
- type은 tuple
dtype- 데이터 타입
ndarray 객체 메서드 목록
| 중요 | 함수 | 설명 |
|---|---|---|
| ✅ | arr.sum(axis=None) | 배열의 모든 요소들의 합계 반환 |
| ✅ | arr.mean(axis=None) | 배열의 모든 요소들의 평균값 반환 |
| ✅ | arr.max(axis=None) | 배열의 모든 요소들의 최대값 반환 |
| ✅ | arr.min(axis=None) | 배열의 모든 요소들의 최소값 반환 |
| arr.argmax(axis=None) | 배열의 모든 요소들의 최대값을 가지는 요소의 인덱스 반환 | |
| arr.argmin(axis=None) | 배열의 모든 요소들의 최소값을 가지는 요소의 인덱스 반환 | |
| ✅ | arr.sort(axis=-1) | 배열을 axis 기준으로 오름차순으로 정렬. axis 값 의미 파악 중요 |
| arr.argsort(axis=-1) | sort 함수 결과를 호출이전의 인덱스로 변경 | |
| arr.partition(kth, axis=-1) | 배열의 axis기준으로 kth 개만 오름차순으로 정렬해서 채우고 나머지는 랜덤하게 채운다. | |
| arr.argpartition(kth, axis=-1) | partition 함수 결과를 호출이전의 인덱스로 변경 |
⭐ numpy에서 axis 값의 의미
https://pybasall.tistory.com/129
Pandas
User Guide — pandas 2.2.2 documentation
Pandas는 데이터 조작과 분석을 위한 강력한 라이브러리입니다.
이는 테이블 형식의 데이터를 쉽게 처리하고 조작할 수 있는 다양한 기능을 제공합니다.
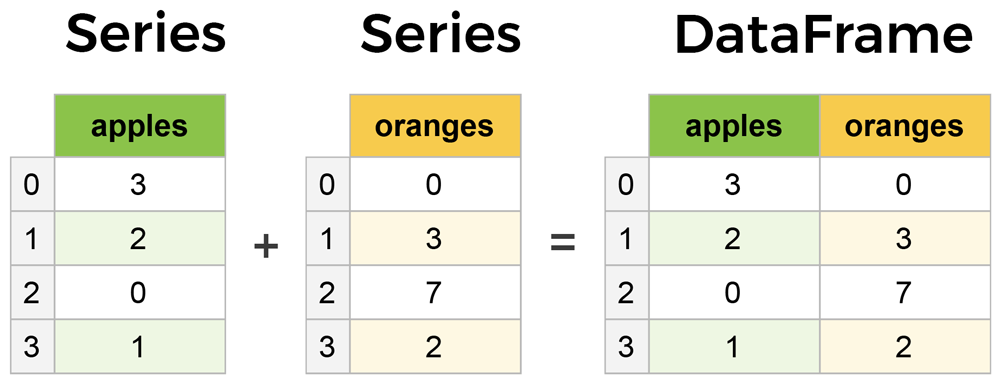
Pandas는 특히 DataFrame과 Series라는 두 가지 주요 데이터 구조를 제공합니다.
- DataFrame: 이는 행과 열로 구성된 테이블 형식의 데이터 구조입니다. 각 열은 서로 다른 유형의 데이터를 포함할 수 있으며, 각 행은 데이터 레코드를 나타냅니다. 데이터프레임은 CSV 파일, 엑셀 파일, 데이터베이스 쿼리 결과 등 다양한 소스에서 데이터를 읽고 쓰는 데 사용됩니다.
- Series: 이는 1차원 배열과 유사하지만 각 요소는 색인(index)으로 레이블링됩니다. 시리즈는 데이터프레임의 열이나 행을 나타낼 수 있습니다.
Series
- Pandas 라이브러리의 기본 객체이며, 1차원 배열
values,index로 구분되어 있음
필드 구성
values- 1차원 배열 값들
- type은 numpy.ndarray
index- 1차원 배열 인덱스
- type은 pandas.core.indexes.range.RangeIndex
name- 1차원 배열 이름
- optional
Series 생성자
pd.Series(
data=None,
index=None,
dtype: 'Dtype | None' = None,
name=None,
copy: 'bool | None' = None,
fastpath: 'bool | lib.NoDefault' = <no_default>,
) -> 'None'
Docstring:
One-dimensional ndarray with axis labels (including time series).
Labels need not be unique but must be a hashable type. The object
supports both integer- and label-based indexing and provides a host of
methods for performing operations involving the index. Statistical
methods from ndarray have been overridden to automatically exclude
missing data (currently represented as NaN).
Operations between Series (+, -, /, \*, \*\*) align values based on their
associated index values-- they need not be the same length. The result
index will be the sorted union of the two indexes.
Parameters
----------
data : array-like, Iterable, dict, or scalar value
Contains data stored in Series. If data is a dict, argument order is
maintained.
index : array-like or Index (1d)
Values must be hashable and have the same length as `data`.
Non-unique index values are allowed. Will default to
RangeIndex (0, 1, 2, ..., n) if not provided. If data is dict-like
and index is None, then the keys in the data are used as the index. If the
index is not None, the resulting Series is reindexed with the index values.
dtype : str, numpy.dtype, or ExtensionDtype, optional
Data type for the output Series. If not specified, this will be
inferred from `data`.
See the :ref:`user guide <basics.dtypes>` for more usages.
name : Hashable, default None
The name to give to the Series.
copy : bool, default False
Copy input data. Only affects Series or 1d ndarray input. See examples.Series 객체 메서드 목록
| 중요 | 함수 | 설명 |
|---|---|---|
| ✅ | max() | max( axis: 'Axis | None' = 0, skipna: 'bool' = True, numeric_only: 'bool' = False, **kwargs, ) |
| ✅ | min() | min( axis: 'Axis | None' = 0, skipna: 'bool' = True, numeric_only: 'bool' = False, **kwargs, ) |
| ✅ | mean() | mean( axis: 'Axis | None' = 0, skipna: 'bool' = True, numeric_only: 'bool' = False, **kwargs, ) |
| ✅ | var() | var( axis: 'Axis | None' = None, skipna: 'bool' = True, ddof: 'int' = 1, numeric_only: 'bool' = False, **kwargs, ) |
| ✅ | std() | std( axis: 'Axis | None' = None, skipna: 'bool' = True, ddof: 'int' = 1, numeric_only: 'bool' = False, **kwargs, ) |
| ✅ | idxmax(axis=0, skipna=True, *args, **kwargs) | 최대값의 index ser[ser == ser.max()].index 와 동일 |
| ✅ | idxmin(axis=0, skipna=True, *args, **kwargs) | 최소값의 index ser[ser == ser.min()].index 와 동일 |
| ✅ | value_counts() | ser.value_counts( normalize: 'bool' = False, sort: 'bool' = True, ascending: 'bool' = False, bins=None, dropna: 'bool' = True, ) -> 'Series' |
| ✅ | reindex(index) | ser.reindex( index=None, *, axis: 'Axis | None' = None, method: 'ReindexMethod | None' = None, copy: 'bool | None' = None, level: 'Level | None' = None, fill_value: 'Scalar | None' = None, limit: 'int | None' = None, tolerance=None, ) -> 'Series' fill_value 인자를 사용하여 NA/NaN 결측값을 채워줄수 있다. https://eunguru.tistory.com/223 |
| ✅ | reset_index() | reset_index( level: 'IndexLabel | None' = None, *, drop: 'bool' = False, name: 'Level' = <no_default>, inplace: 'bool' = False, allow_duplicates: 'bool' = False, ) -> 'DataFrame | Series | None' https://velog.io/@yeonheedong/Pandas-인덱스-setindex-reindex-resetindex-sortindex-sortvalue |
| diff(period=1) | 배열간의 period 에 따른 차이값에 대한 Series를 리턴한다. | |
| abs() | 절대값 | |
| ✅ | agg(func, axis=0), aggregate(func, axis=0) | 지정된 축에 대해 하나 이상의 작업을 사용하여 집계합니다. agg( func=None, axis: ‘Axis’ = 0, *args, **kwargs, ) |
| cummax() | DataFrame 또는 Series 축에 대한 누적 최대값을 반환합니다. cummax( axis: 'Axis | None' = None, skipna: 'bool' = True, *args, **kwargs, ) | |
| cummin() | DataFrame 또는 Series 축에 대한 누적 최소값을 반환합니다. cummin( axis: 'Axis | None' = None, skipna: 'bool' = True, *args, **kwargs, ) | |
| cumsum() | DataFrame 또는 Series 축에 대한 누적 합을 반환합니다. cumsum( axis: 'Axis | None' = None, skipna: 'bool' = True, *args, **kwargs, ) | |
| cumprod() | DataFrame 또는 Series 축에 대한 누적 곱을 반환합니다. cumprod( axis: 'Axis | None' = None, skipna: 'bool' = True, *args, **kwargs, ) | |
| ✅ | isin(values) | 특정 값의 포함여부를 논리값으로 반환 |
| ✅ | isna() | 결측값 여부를 논리값으로 반환 |
| ✅ | notna() | 결측값 여부를 논리값으로 반환 |
| drop() | drop( labels: 'IndexLabel | None' = None, *, axis: 'Axis' = 0, index: 'IndexLabel | None' = None, columns: 'IndexLabel | None' = None, level: 'Level | None' = None, inplace: 'bool' = False, errors: 'IgnoreRaise' = 'raise', ) -> 'Series | None' | |
| ✅ | dropna() | dropna( *, axis: 'Axis' = 0, inplace: 'bool' = False, how: 'AnyAll | None' = None, ignore_index: 'bool' = False, ) -> 'Series | None' |
| ✅ | astype(dtype) | astype( dtype, copy: 'bool_t | None' = None, errors:'IgnoreRaise' = 'raise', ) -> 'Self' |
| describe() | 각종 기술 통계량을 산출 describe( percentiles=None, include=None, exclude=None ) | |
| to_numpy() | Series → ndarray 로 전환 Series.array 필드값을 이용해도 됩니다. to_numpy( dtype: 'npt.DTypeLike | None' = None, copy: 'bool' = False, na_value: 'object' = <no_default>, **kwargs, ) | |
| to_frame(name=None) | Series → DataFrame 으로 전환 | |
| to_list(), tolist() | Series → list 로 전환 |
DataFrame
- 표 같은 스프레드시트 형식의 2차원 자료 구조
index,columns,values,dtypes,ndim,shape,size로 이루어져 있다.
필드 구성
index- 1차원 배열 인덱스
- type은 pandas.core.indexes.range.RangeIndex
columns- 열의 이름 목록
- type은 pandas.core.indexes.base.Index
values- 2차원 자료 구조의 실제 데이터
- type은 ndarray
- ndim = 2
dtypes- column 이름을 인덱스로 두고, column dtype을 Value로 설정한 Series
- 열의 각 데이터 타입
- type은 Series
ndimvalues의 ndim
shapevalues의 shape
sizevalues의 sizeassert data.ndim == data.values.ndim assert data.shape == data.values.shape assert data.size == data.values.size
DataFrame 생성자
- 펼쳐보기
pd.DataFrame( data=None, index: 'Axes | None' = None, columns: 'Axes | None' = None, dtype: 'Dtype | None' = None, copy: 'bool | None' = None, ) -> 'None' Docstring: Two-dimensional, size-mutable, potentially heterogeneous tabular data. Data structure also contains labeled axes (rows and columns). Arithmetic operations align on both row and column labels. Can be thought of as a dict-like container for Series objects. The primary pandas data structure. Parameters ---------- data : ndarray (structured or homogeneous), Iterable, dict, or DataFrame Dict can contain Series, arrays, constants, dataclass or list-like objects. If data is a dict, column order follows insertion-order. If a dict contains Series which have an index defined, it is aligned by its index. This alignment also occurs if data is a Series or a DataFrame itself. Alignment is done on Series/DataFrame inputs. If data is a list of dicts, column order follows insertion-order. index : Index or array-like Index to use for resulting frame. Will default to RangeIndex if no indexing information part of input data and no index provided. columns : Index or array-like Column labels to use for resulting frame when data does not have them, defaulting to RangeIndex(0, 1, 2, ..., n). If data contains column labels, will perform column selection instead. dtype : dtype, default None Data type to force. Only a single dtype is allowed. If None, infer. copy : bool or None, default None Copy data from inputs. For dict data, the default of None behaves like ``copy=True``. For DataFrame or 2d ndarray input, the default of None behaves like ``copy=False``. If data is a dict containing one or more Series (possibly of different dtypes), ``copy=False`` will ensure that these inputs are not copied. .. versionchanged:: 1.3.0 See Also -------- DataFrame.from_records : Constructor from tuples, also record arrays. DataFrame.from_dict : From dicts of Series, arrays, or dicts. read_csv : Read a comma-separated values (csv) file into DataFrame. read_table : Read general delimited file into DataFrame. read_clipboard : Read text from clipboard into DataFrame.
DataFrame 객체 메서드 목록
EDA 파트에서 주로 많이 사용하는 메서드들을 기재하겠습니다.
| 중요 | 함수 | 설명 |
|---|---|---|
| ✅ | df[”aa”][:2] | DataFrame 배열 인덱스 방식으로 접근 column name, index 기반으로 접근 |
| ✅ | iloc[:,0] | row, col 숫자 기반으로 접근 |
| ✅ | loc[:,”aa”] | row, col 객체 기반으로 접근 |
| rename() | column이나 index의 이름을 바꿉니다. inplace : DataFrame을 새로 만드는 대신 DataFrame을 수정할지 여부입니다. True이면 복사 값이 무시됩니다. rename( mapper: 'Renamer | None' = None, *, index: 'Renamer | None' = None, columns: 'Renamer | None' = None, axis: 'Axis | None' = None, copy: 'bool | None' = None, inplace: 'bool' = False, level: 'Level | None' = None, errors: 'IgnoreRaise' = 'ignore', ) |
-
df.info()
df.info( verbose: 'bool | None' = None, buf: 'WriteBuffer[str] | None' = None, max_cols: 'int | None' = None, memory_usage: 'bool | str | None' = None, show_counts: 'bool | None' = None, ) -> 'None' -
df.describe()
df.describe( percentiles=None, include=None, exclude=None ) -> 'Self' -
df.head(n = 5)
-
df.tail(n = 5)
-
df.sum(axis=0)
df.max( axis: 'Axis | None' = 0, skipna: 'bool' = True, numeric_only: 'bool' = False, **kwargs, ) -
df.max(axis=0) , df.min(axis=0)
df.max( axis: 'Axis | None' = 0, skipna: 'bool' = True, numeric_only: 'bool' = False, **kwargs, ) -
df.idxmax(axis=0) , df.idxmin(axis=0)
df.idxmax( axis: 'Axis' = 0, skipna: 'bool' = True, numeric_only: 'bool' = False, ) -> 'Series' -
df.mean(axis=0) , df.median(axis=0) , df.mode(axis=0)
df.mean( axis: 'Axis | None' = 0, skipna: 'bool' = True, numeric_only: 'bool' = False, **kwargs, ) -
df.var(axis=0, ddof=1), df.std(axis=0, ddof=1)
df.var( axis: 'Axis | None' = 0, skipna: 'bool' = True, ddof: 'int' = 1, numeric_only: 'bool' = False, **kwargs, ) -
df.corr()
df.corr( method: 'CorrelationMethod' = 'pearson', min_periods: 'int' = 1, numeric_only: 'bool' = False, ) -> 'DataFrame' -
df.corrwith(df2)
df.corrwith( other: 'DataFrame | Series', axis: 'Axis' = 0, drop: 'bool' = False, method: 'CorrelationMethod' = 'pearson', numeric_only: 'bool' = False, ) -> 'Series' -
df.isin(array_like)
df.isin(values: 'Series | DataFrame | Sequence | Mapping') -> 'DataFrame' -
df.quantile(q)
df.quantile( q: 'float | AnyArrayLike | Sequence[float]' = 0.5, axis: 'Axis' = 0, numeric_only: 'bool' = False, interpolation: 'QuantileInterpolation' = 'linear', method: "Literal['single', 'table']" = 'single', ) -> 'Series | DataFrame' -
df.isna() , df.isnull()
-
df.notna() , df.notnull()
-
df.fillna(value), df.ffill(), df.bfill()
df.fillna( value: 'Hashable | Mapping | Series | DataFrame | None' = None, *, method: 'FillnaOptions | None' = None, axis: 'Axis | None' = None, inplace: 'bool_t' = False, limit: 'int | None' = None, downcast: 'dict | None | lib.NoDefault' = <no_default>, ) -> 'Self | None' -
df.replace(to_replace, value)
df.replace( to_replace=None, value=<no_default>, *, inplace: 'bool_t' = False, limit: 'int | None' = None, regex: 'bool_t' = False, method: "Literal['pad', 'ffill', 'bfill'] | lib.NoDefault" = <no_default>, ) -> 'Self | None' -
df.dropna()
-
how = any, all
df.dropna( *, axis: 'Axis' = 0, how: 'AnyAll | lib.NoDefault' = <no_default>, thresh: 'int | lib.NoDefault' = <no_default>, subset: 'IndexLabel | None' = None, inplace: 'bool' = False, ignore_index: 'bool' = False, ) -> 'DataFrame | None'
-
-
df.drop(labels, axis=0)
df.drop( labels: 'IndexLabel | None' = None, *, axis: 'Axis' = 0, index: 'IndexLabel | None' = None, columns: 'IndexLabel | None' = None, level: 'Level | None' = None, inplace: 'bool' = False, errors: 'IgnoreRaise' = 'raise', ) -> 'DataFrame | None' -
df.reset_index()
df.reset_index( level: 'IndexLabel | None' = None, *, drop: 'bool' = False, inplace: 'bool' = False, col_level: 'Hashable' = 0, col_fill: 'Hashable' = '', allow_duplicates: 'bool | lib.NoDefault' = <no_default>, names: 'Hashable | Sequence[Hashable] | None' = None, ) -> 'DataFrame | None' -
df.set_index(keys)
df.set_index( keys, *, drop: 'bool' = True, append: 'bool' = False, inplace: 'bool' = False, verify_integrity: 'bool' = False, ) -> 'DataFrame | None' -
df.sort_values(by)
df.sort_values( by: 'IndexLabel', *, axis: 'Axis' = 0, ascending: 'bool | list[bool] | tuple[bool, ...]' = True, inplace: 'bool' = False, kind: 'SortKind' = 'quicksort', na_position: 'str' = 'last', ignore_index: 'bool' = False, key: 'ValueKeyFunc | None' = None, ) -> 'DataFrame | None' -
df.sort_index()
df.sort_index( *, axis: 'Axis' = 0, level: 'IndexLabel | None' = None, ascending: 'bool | Sequence[bool]' = True, inplace: 'bool' = False, kind: 'SortKind' = 'quicksort', na_position: 'NaPosition' = 'last', sort_remaining: 'bool' = True, ignore_index: 'bool' = False, key: 'IndexKeyFunc | None' = None, ) -> 'DataFrame | None' -
df.nlargest(n), df.nsmallest(n), ser.nlargest(n), ser.nsmallest(n)
-
df.sort_values(ascending=False).head(n)과 동일 -
df.sort_values().head(n)과 동일df.nlargest( n: 'int', columns: 'IndexLabel', keep: 'NsmallestNlargestKeep' = 'first', ) -> 'DataFrame' ser.nlargest( n: 'int' = 5, keep: "Literal['first', 'last', 'all']" = 'first', ) -> 'Series'
-
-
df.sample(n)
df.sample( n: 'int | None' = None, frac: 'float | None' = None, replace: 'bool_t' = False, weights=None, random_state: 'RandomState | None' = None, axis: 'Axis | None' = None, ignore_index: 'bool_t' = False, ) -> 'Self' -
df.astype(dtype)
df.astype( dtype, copy: 'bool_t | None' = None, errors: 'IgnoreRaise' = 'raise', ) -> 'Self' -
df.select_dtypes(include=None, exclude=None)
# 숫자 타입의 컬럼들만 추려서 Sub DataFrame을 리턴한다. df.select_dtypes("number") df.select_dtypes(np.number) -
df.groupby(by)
df.groupby( by=None, axis: 'Axis | lib.NoDefault' = <no_default>, level: 'IndexLabel | None' = None, as_index: 'bool' = True, sort: 'bool' = True, group_keys: 'bool' = True, observed: 'bool | lib.NoDefault' = <no_default>, dropna: 'bool' = True, ) -> 'DataFrameGroupBy' -
ser.groupby(by)
ser.groupby( by=None, axis: 'Axis' = 0, level: 'IndexLabel | None' = None, as_index: 'bool' = True, sort: 'bool' = True, group_keys: 'bool' = True, observed: 'bool | lib.NoDefault' = <no_default>, dropna: 'bool' = True, ) -> 'SeriesGroupBy' -
df.nunique(axis=0)
pd.DataFrame.nunique( axis: 'Axis' = 0, dropna: 'bool' = True ) -> 'Series’ -
ser.nunique()
pd.Series.nunique( dropna: 'bool' = True ) -> 'int' -
DataFrameGroupBy vs SeriesGroupBy
Dataframe 병합 메서드
1. pd.concat 메서드
- pd.concat(objs)
pd.concat( objs: 'Iterable[Series | DataFrame] | Mapping[HashableT, Series | DataFrame]', *, axis: 'Axis' = 0, join: 'str' = 'outer', ignore_index: 'bool' = False, keys: 'Iterable[Hashable] | None' = None, levels=None, names: 'list[HashableT] | None' = None, verify_integrity: 'bool' = False, sort: 'bool' = False, copy: 'bool | None' = None, ) -> 'DataFrame | Series'- 용도: 여러 데이터프레임이나 시리즈를 축(axis) 기준으로 이어붙임.
- 사용법:
pd.concat(objs, axis=0, join='outer', ignore_index=False) - 주요 매개변수:
objs: 결합할 데이터프레임이나 시리즈의 리스트.axis: 결합할 축 (0은 행 방향, 1은 열 방향).join: 결합 방식 ('outer'는 합집합, 'inner'는 교집합).ignore_index: 인덱스를 무시하고 새로 생성할지 여부.
2. pd.merge, df.merge 메서드
- pd.merge(left, right)
pd.merge( left: 'DataFrame | Series', right: 'DataFrame | Series', how: 'MergeHow' = 'inner', on: 'IndexLabel | AnyArrayLike | None' = None, left_on: 'IndexLabel | AnyArrayLike | None' = None, right_on: 'IndexLabel | AnyArrayLike | None' = None, left_index: 'bool' = False, right_index: 'bool' = False, sort: 'bool' = False, suffixes: 'Suffixes' = ('_x', '_y'), copy: 'bool | None' = None, indicator: 'str | bool' = False, validate: 'str | None' = None, ) -> 'DataFrame'- 용도: 두 데이터프레임을 공통 열이나 인덱스를 기준으로 결합 (SQL JOIN과 유사).
- 사용법:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False)pd.merge(df.iloc[:,0:1], df.iloc[:,1:2], how='inner', on=None, left_on=None, right_on=None, left_index=True, right_index=True) - 주요 매개변수:
left,right: 결합할 두 데이터프레임.how: 결합 방식 ('left', 'right', 'outer', 'inner').on: 공통 열 이름.left_on,right_on: 각 데이터프레임에서 결합할 열 이름.left_index,right_index: 인덱스를 기준으로 결합할지 여부.
- df.merge(df2)
df.merge( right: 'DataFrame | Series', how: 'MergeHow' = 'inner', on: 'IndexLabel | AnyArrayLike | None' = None, left_on: 'IndexLabel | AnyArrayLike | None' = None, right_on: 'IndexLabel | AnyArrayLike | None' = None, left_index: 'bool' = False, right_index: 'bool' = False, sort: 'bool' = False, suffixes: 'Suffixes' = ('_x', '_y'), copy: 'bool | None' = None, indicator: 'str | bool' = False, validate: 'MergeValidate | None' = None, ) -> 'DataFrame'- 용도: 특정 데이터프레임의 메소드로, 다른 데이터프레임과 공통 열이나 인덱스를 기준으로 결합.
- 사용법:
df1.merge(df2, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False) - 주요 매개변수:
df2: 결합할 다른 데이터프레임.how: 결합 방식 ('left', 'right', 'outer', 'inner').on: 공통 열 이름.left_on,right_on: 각 데이터프레임에서 결합할 열 이름.left_index,right_index: 인덱스를 기준으로 결합할지 여부.
3.df.join 메서드
- df.join(df2)
df.join( other: 'DataFrame | Series | Iterable[DataFrame | Series]', on: 'IndexLabel | None' = None, how: 'MergeHow' = 'left', lsuffix: 'str' = '', rsuffix: 'str' = '', sort: 'bool' = False, validate: 'JoinValidate | None' = None, ) -> 'DataFrame'- 용도: 특정 데이터프레임의 메소드로, 주로 인덱스를 기준으로 다른 데이터프레임과 결합.
- 사용법:
df1.join(df2, how='left', on=None, lsuffix='', rsuffix='', sort=False) - 주요 매개변수:
df2: 결합할 다른 데이터프레임.how: 결합 방식 ('left', 'right', 'outer', 'inner').on: 결합할 열 이름 (기본값은 인덱스 기준 결합).lsuffix,rsuffix: 동일한 열 이름이 있을 경우 접미사.sort: 결합 후 정렬 여부.
Transform 메서드
1. DataFrame
DataFrame.transform(func, axis=0, *args, **kwargs)
- 설명: DataFrame의 각 요소에 대해 함수를 적용합니다. 이 메서드는 원본 DataFrame과 동일한 형태의 새로운 DataFrame을 반환합니다.
- 주요 매개변수:
func: 함수, 함수 이름, 또는 함수 목록. DataFrame의 각 요소에 적용할 함수.axis: 0 (index) 또는 1 (columns). 함수를 적용할 축을 지정합니다.
- 예시:
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]}) df.transform(lambda x: x + 1)
2. Series
Series.transform(func, *args, **kwargs)
- 설명: Series의 각 요소에 대해 함수를 적용합니다. 이 메서드는 원본 Series와 동일한 길이의 새로운 Series를 반환합니다.
- 주요 매개변수:
func: 함수, 함수 이름, 또는 함수 목록. Series의 각 요소에 적용할 함수.
- 예시:
df = pd.Series([1, 2, 3]) df.transform(lambda x: x ** 2)
3. DataFrameGroupBy
DataFrameGroupBy.transform(func, *args, **kwargs)
- 설명: 그룹화된 DataFrame의 각 그룹에 대해 함수를 적용합니다. 각 그룹의 결과를 원래 DataFrame의 인덱스에 맞춰 반환합니다.
- 주요 매개변수:
func: 함수, 함수 이름, 또는 함수 목록. 그룹화된 DataFrame의 각 그룹에 적용할 함수.
- 예시:
df = pd.DataFrame({'A': ['foo', 'foo', 'bar'], 'B': [1, 2, 3], 'C': [1,3,5]}) df.groupby('A').transform(lambda x: x - x.mean())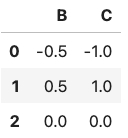
4. SeriesGroupBy
SeriesGroupBy.transform(func, *args, **kwargs)
- 설명: 그룹화된 Series의 각 그룹에 대해 함수를 적용합니다. 각 그룹의 결과를 원래 Series의 인덱스에 맞춰 반환합니다.
- 주요 매개변수:
func: 함수, 함수 이름, 또는 함수 목록. 그룹화된 Series의 각 그룹에 적용할 함수.
- 예시:
df = pd.Series([1, 2, 3, 4], index=['a', 'a', 'b', 'b']) df.groupby(level=0).transform(lambda x: x - x.mean())
Apply 메서드
DataFrame의 apply 메서드
DataFrame.apply(func, axis=0, raw=False, result_type=None, args=(), **kwds)
- 설명: DataFrame의 각 행 또는 열에 함수를 적용합니다.
- 주요 매개변수:
func: 각 행 또는 열에 적용할 함수.axis: 함수를 적용할 축 (0 또는 'index'는 열 방향, 1 또는 'columns'는 행 방향).raw: True로 설정하면 각 행 또는 열이 Series가 아닌 ndarray로 전달됩니다.result_type: 'expand', 'reduce', 'broadcast' 중 하나로 설정하여 결과의 형태를 결정합니다.
- 예시:
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]}) # 각 열에 대해 함수를 적용 result = df.apply(lambda x: x.mean(), axis=0) print(result) # 각 행에 대해 함수를 적용 result = df.apply(lambda x: x.sum(), axis=1) print(result)
Series의 apply 메서드
Series.apply(func, convert_dtype=True, args=(), **kwds)
- 설명: Series의 각 요소에 함수를 적용합니다.
- 주요 매개변수:
func: 각 요소에 적용할 함수.convert_dtype: True로 설정하면 결과를 적절한 dtype으로 변환합니다.
- 예시:
s = pd.Series([1, 2, 3]) # 각 요소에 대해 함수를 적용 result = s.apply(lambda x: x ** 2) print(result)
Apply, Transform 메서드 차이점
주요 차이점
- 반환 형태:
apply함수는 결과를 더 자유롭게 반환할 수 있습니다. 예를 들어, 각 열에 대한 단일 값을 반환하거나, 원본 데이터 프레임과 다른 형상의 데이터 프레임을 반환할 수 있습니다.transform함수는 원본 데이터 프레임과 동일한 크기의 데이터를 반환해야 합니다. 각 요소가 변환된 후에도 데이터 프레임의 형상은 변하지 않습니다.
- 사용 목적:
apply함수는 다양한 변환 및 요약 작업에 사용됩니다. 예를 들어, 데이터 프레임의 각 열에 대한 합계, 평균 또는 복잡한 변환을 적용할 수 있습니다.transform함수는 각 요소를 변환하는 데 주로 사용되며, 그룹별 변환을 할 때 특히 유용합니다. 그룹화된 데이터에 대해 원래 데이터와 동일한 크기의 변환 결과를 반환합니다.
- 적용 대상:
apply함수는 데이터 프레임의 행 또는 열 전체에 적용되며, 반환 값은 리스트, 시리즈, 데이터 프레임 또는 단일 값이 될 수 있습니다.transform함수는 시리즈나 데이터 프레임의 각 요소에 적용되며, 반환 값은 반드시 원래의 크기와 동일해야 합니다.
예제
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
# 각 열에 대해 합계 계산
result_apply = df.apply(lambda x: x.sum(), axis=0)
print(result_apply)
# 결과:
# A 6
# B 15
# dtype: int64
# 각 행에 대해 최대값 계산
result_apply = df.apply(lambda x: x.max(), axis=1)
print(result_apply)
# 결과:
# 0 4
# 1 5
# 2 6
# dtype: int64df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
# 각 요소에 대해 2를 더하는 변환
result_transform = df.transform(lambda x: x + 2)
print(result_transform)
# 결과:
# A B
# 0 3 6
# 1 4 7
# 2 5 8
# 그룹화 후 각 그룹의 평균값으로 변환
df_grouped = df.groupby('A')
result_transform = df_grouped.transform('mean')
print(result_transform)
# 결과:
# B
# 0 4
# 1 5
# 2 6GroupBy 객체에서의 차이점
transform함수는 그룹별 변환에서 주로 사용되며, 그룹화된 데이터를 원래의 크기와 동일하게 유지하면서 변환할 때 유용합니다.- 반면에,
apply함수는 그룹별로 복잡한 계산을 수행하고 다양한 형식의 결과를 반환하는 데 사용됩니다.
df = pd.DataFrame({'A': ['foo', 'foo', 'bar'], 'B': [1, 2, 3]})
grouped = df.groupby('A')
# 각 그룹의 평균값 계산 (원래 크기 유지)
result_transform = grouped.transform('mean')
print(result_transform)
# 결과:
# B
# 0 1.5
# 1 1.5
# 2 3.0
# 각 그룹에 대해 함수 적용 (다양한 결과 반환 가능)
result_apply = grouped.apply(lambda x: x.sum())
print(result_apply)
# 결과:
# B
# A
# bar 3
# foo 3요약
apply함수는 자유로운 형식의 결과를 반환할 수 있으며, 요약 통계나 복잡한 변환 작업에 적합합니다.transform함수는 원본 데이터와 동일한 크기의 결과를 반환해야 하며, 주로 각 요소별 변환이나 그룹화된 데이터의 변환에 사용됩니다.
이러한 차이점을 이해하고 사용 목적에 맞게 apply와 transform 함수를 선택하면, 더 효율적이고 직관적인 데이터 처리가 가능합니다.
pd.crosstab(index, columns)
https://freedata.tistory.com/60
pd.crosstab(
index,
columns,
values=None,
rownames=None,
colnames=None,
aggfunc=None,
margins: 'bool' = False,
margins_name: 'Hashable' = 'All',
dropna: 'bool' = True,
normalize: "bool | Literal[0, 1, 'all', 'index', 'columns']" = False,
) -> 'DataFrame'