
Package Import
import numpy as np
import pandas as pd
import sklearn
import scipy
import scipy.stats as stats
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split데이터 불러오기
df = pd.read_csv("...", sep=",")
df2 = pd.read_excel("...", sheet_name="Sheet1")데이터 살펴보기
df.head()
df.tail()
df.shape
df.info()
df.describe()데이터 전처리
Train / Test 데이터 준비
- `sklearn.model_selection
패키지에 있는 **train_test_split`** 함수 활용
train_test_split(
*arrays,
test_size=None,
train_size=None,
random_state=None,
shuffle=True,
stratify=None,
)from skelarn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=1234)데이터 분석 수행
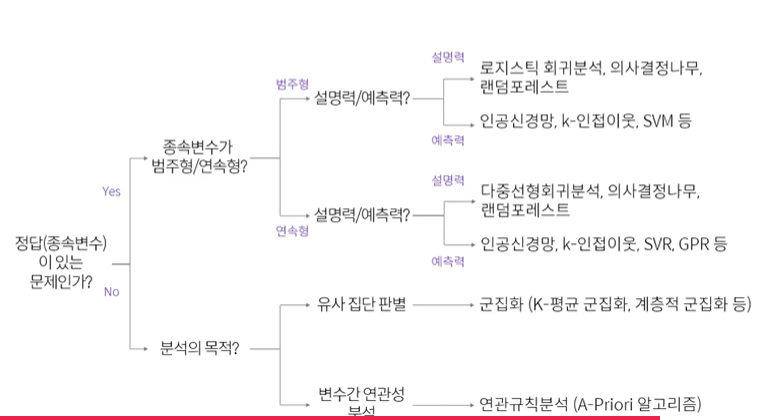
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
decisionTree = DecisionTreeClassifier(random_state=11)
decisionTree.fit(x_train, y_train)
y_pred = decisionTree.predict(x_test)
df = pd.DataFrame({"predicted": y_pred, "actual": y_test})
accuracy1 = round((df["predicted"] == df["actual"]).sum() / y_test.shape[0], 2) # 검증 통과율
accuracy2 = round(accuracy_score(y_test, y_pred), 2)
assert accuracy1 == accuracy2데이터 모델링 성능 검증
import sklearn.metrics as skmetric
skmetric.accuracy_score(y_test, y_pred)
skmetric.precision_score(y_test, y_pred, average=None)
skmetric.recall_score**(y_test, y_pred, average=None)
skmetric.f1_score**(y_test, y_pred, average=None)
skmetric.mean_absolute_error(y_test, y_pred)
skmetric.mean_squared_error(y_test, y_pred)
skmetric.median_absolute_error(y_test, y_pred)분석모델 성능 평가 방법
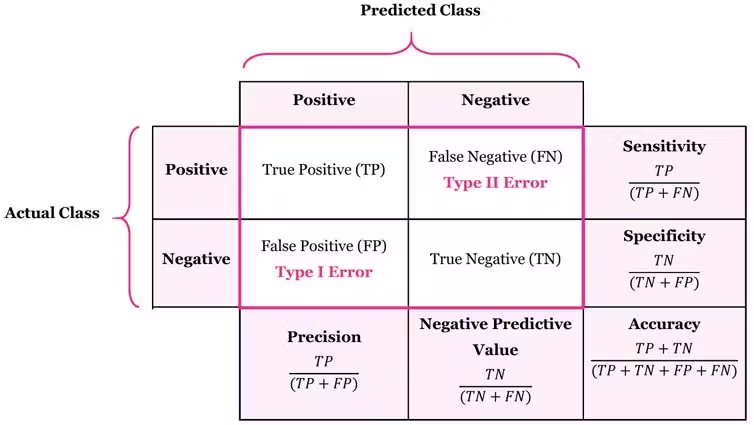
F1 Score
- Precision, Sensitivity(Recall)의 조화평균 지표
- 값이 클수록 모형이 정확하다고 판단할 수 있다.
코드 예시
from sklearn.metrics import classification_report
report = classification_report(y_test, y_pred) # return str
print(report)
# 출력 결과
precision recall f1-score support
setosa 1.00 1.00 1.00 9
versicolor 0.83 1.00 0.91 10
virginica 1.00 0.82 0.90 11
accuracy 0.93 30
macro avg 0.94 0.94 0.94 30
weighted avg 0.94 0.93 0.93 30import sklearn.metrics as metrics
print(metrics.**accuracy_score**(y_test, y_pred))
print(metrics.**precision_score**(y_test, y_pred, average=None))
print(metrics.**recall_score**(y_test, y_pred, average=None))
print(metrics.**f1_score**(y_test, y_pred, average=None))
# 출력 결과
0.9333333333333333
[1. 0.83333333 1. ]
[1. 1. 0.81818182]
[1. 0.90909091 0.9 ]average 매개변수
None: 각 클래스에 대한 개별 점수를 반환합니다.'micro': 전체 클래스에서의 총 합계를 기반으로 점수를 계산합니다.'macro': 각 클래스의 점수를 계산한 다음 그 평균을 냅니다. 클래스 간의 가중치를 고려하지 않습니다.'weighted': 각 클래스의 점수를 계산한 다음 그 평균을 냅니다. 각 클래스의 샘플 수로 가중치를 둡니다.'samples': 다중 레이블 분류에서 각 샘플의 점수를 평균화합니다.
scikit-learn 패키지 구성
| 분류 | Module | 설명 |
|---|---|---|
| 변수처리 | sklearn.preprocessing | 데이터 전처리에 필요한 기능 제공 |
| sklearn.feature_selection | 알고리즘에 큰 영향을 미치는 변수를 우선순위대로 선택하는 기능 제공 | |
| sklearn.feature_extaction | 텍스트 데이터나 이미지 데이터의 벡터화된 Feature를 추출하는데 사용됨 | |
| 데이터 분리, 검증 | sklearn.model_selection | 차원 축소와 관련한 알고리즘을 지원하는 모듈 |
| 평가 | sklearn.metrics | 분류, 회귀 등에 대한 다양한 성능 측정 방법 제공 |
| Accuracy, Precision, Recall, ROC-AUC, RMSE 등 제공 | ||
| 머신러닝 알고리즘 | sklearn.tree | 의사결정트리 알고리즘 제공 |
| sklearn.neighbors | KNN(K-Nearest Neighborhood) 등 최근접 이웃 알고리즘 제공 | |
| sklearn.svm | 서포트벡터머신(SVM) 알고리즘 제공 | |
| sklearn.ensemble | 랜덤 포레스트, 그래디언트 부스팅 등 앙상블 알고리즘 제공 | |
| sklearn.linear_model | 선형회귀, 릿지, 라쏘 및 로지스틱 회귀 등 알고리즘 제공 | |
| sklearn.naive_bayes | 나이브 베이즈 알고리즘 제공 | |
| sklearn.cluster | 비지도 학습 Clustering 알고리즘 제공 (K-Mean, DBSCAN 등) |
알고리즘 종류
분류
- DecisionTreeClassifier
- RandomForestClassifier
- GradientBoostingClassifier
- GaussianNB
- SVC
회귀
- LinearRegression
- Ridge
- Lasso
- RandomForestRegressor
- GradientBoostringRegressor

Hello velog!