
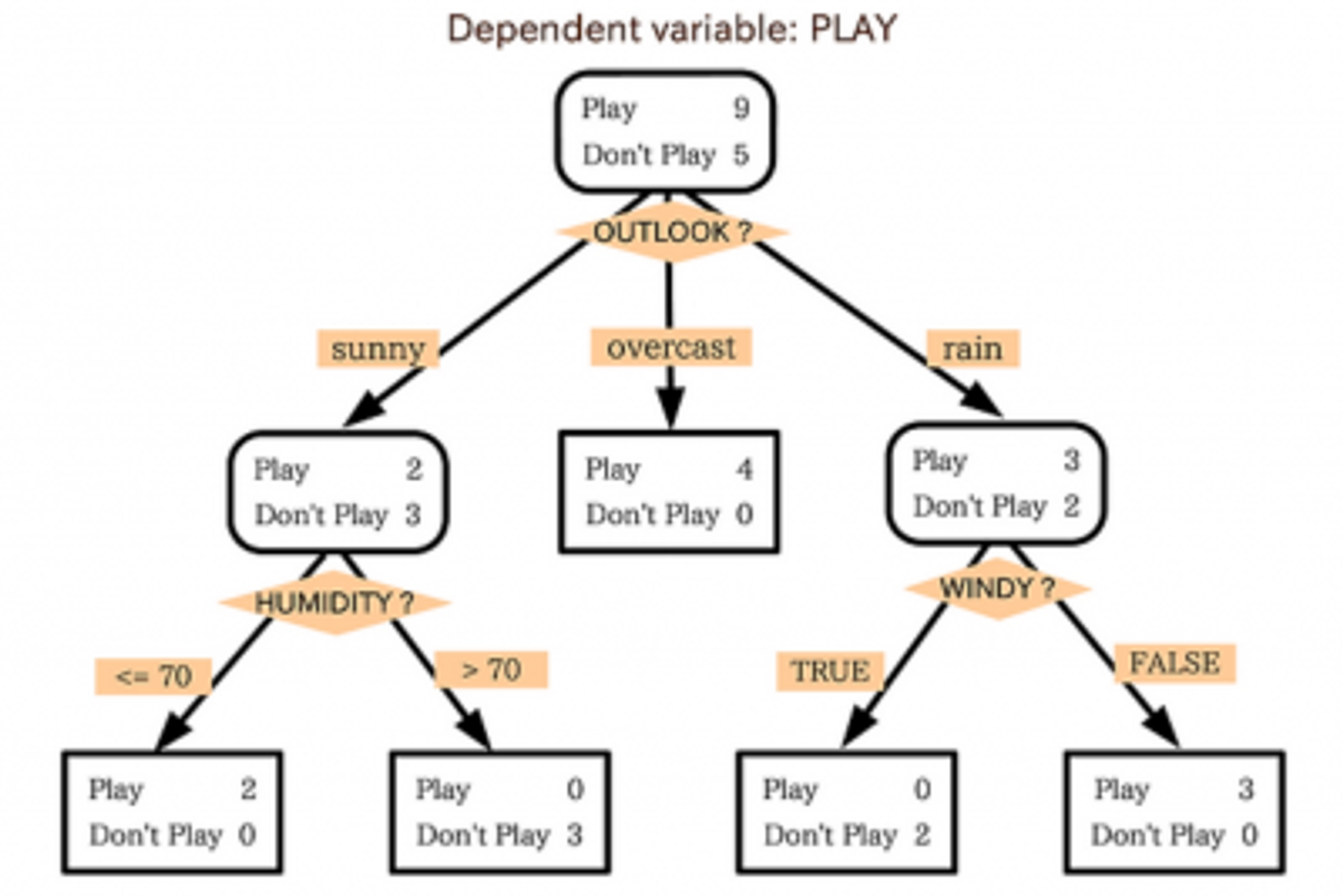
의사결정나무 (Decision Tree)
- 의사결정을 위한 규칙을 나무 모양으로 조합하여, 목표변수에 대한 분류를 수행하는 기법이다.
- 수치 데이터, 범주 데이터 모두 사용 가능하다.
package import
import pandas as pd
import numpy as np
import matplotlib
import scipy
import matplotlib.pyplot as plt
import scipy.stats as stats
import sklearn
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
print(f"pandas version: {pd.__version__}")
print(f"numpy version: {np.__version__}")
print(f"matplotlib version: {matplotlib.__version__}")
print(f"scipy version: {scipy.__version__}")
# 출력 결과
pandas version: 2.2.2
numpy version: 1.26.4
matplotlib version: 3.9.0
scipy version: 1.13.1
sklearn version: 1.5.0데이터 불러오기
df = pd.read_csv("https://raw.githubusercontent.com/YoungjinBD/dataset/main/iris.csv")
df
# df.info()데이터 전처리
# Age 결측치 대체 (평균값)
df["Age"] = df["Age"].fillna(df["Age"].mean())
assert df["Age"].isna().sum() == 0
# Embarked 결측치 대체 (최빈값)
df["Embarked"] = df["Embarked"].fillna(df["Embarked"].mode()[0])
assert df["Embarked"].isna().sum() == 0
# Sex Label Encoding
from sklearn.preprocessing import LabelEncoder
labelEncoder = LabelEncoder()
labelEncoder.fit(sorted(np.unique(df["Sex"])))
df["Sex"] = labelEncoder.transform(df["Sex"])
# Embarked Label Encoding
from sklearn.preprocessing import LabelEncoder
labelEncoder = LabelEncoder()
df["Embarked"] = labelEncoder.fit_transform(df["Embarked"])
# SibSp, Parch 합쳐서 FamilySize
df["FamilySize"] = df["SibSp"] + df["Parch"]train, test 데이터 준비
# train, test
from sklearn.model_selection import train_test_split
X = df[["Pclass", "Sex", "Age", "Fare", "Embarked", "FamilySize"]]
y = df["Survived"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=11)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)모델 적용 및 데이터 분석 수행
sklearn.tree.DecisionTreeClassifier클래스 활용sklearn.tree.DecisionTreeClassifier( *, criterion='gini', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, class_weight=None, ccp_alpha=0.0, monotonic_cst=None, )
from sklearn.tree import DecisionTreeClassifier
decisionTree = DecisionTreeClassifier()
decisionTree.fit(X_train, y_train)
y_pred = decisionTree.predict(X_test)
assert y_pred.shape == y_test.shape데이터 모델링 성능 평가
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
y_pred = decisionTree.predict(X_test)
report = classification_report(y_test, y_pred)
print(report)
print(accuracy_score(y_test, y_pred))
print(precision_score(y_test, y_pred, average=None))
print(recall_score(y_test, y_pred, average=None))
print(f1_score(y_test, y_pred, average=None))
print(confusion_matrix(y_test, y_pred))KNN (K-Nearest Neighbor)
- KNN 알고리즘은 변수별 단위가 무엇이냐에 따라 거리가 다라지고, 분류 결과가 달라질 수 있다.
- 따라서, KNN 알고리즘을 적용할 때에는 사전에 데이터를 표준화 해야한다.
package import
import numpy as np
import pandas as pd
import sklearn
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
print(f"pandas version: {pd.__version__}")
print(f"numpy version: {np.__version__}")
print(f"sklearn version: {sklearn.__version__}")
# 출력 결과
pandas version: 2.2.2
numpy version: 1.26.4
sklearn version: 1.5.0데이터 불러오기
# data load
df = pd.read_csv("https://raw.githubusercontent.com/YoungjinBD/dataset/main/iris.csv")
df데이터 전처리
# Min-Max Normalization
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df2 = df.drop("species", axis=1)
df = df.join(pd.DataFrame(scaler.fit_transform(df2), columns=df2.columns + "_norm"))
df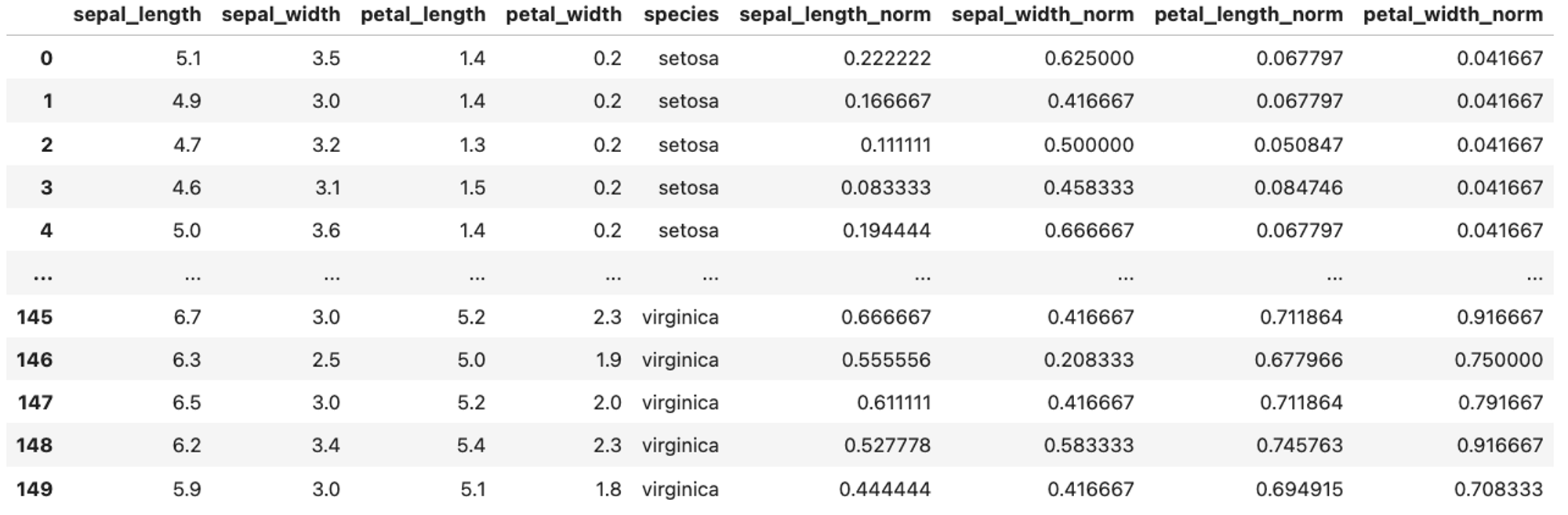
train, test 데이터 준비
# train test split
from sklearn.model_selection import train_test_split
columns = df.columns[df.columns.str.endswith("_norm")]
X = df[columns]
y = df["species"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=11)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)모델 적용 및 데이터 분석 수행
sklearn.neighbors.KNeighborsClassifier클래스 활용
sklearn.neighbors.KNeighborsClassifier(
n_neighbors=5,
*,
weights='uniform',
algorithm='auto',
leaf_size=30,
p=2,
metric='minkowski',
metric_params=None,
n_jobs=None,
)# KNN 모델 적용
from sklearn.neighbors import KNeighborsClassifier
# n_neighbors = len(np.unique(df["species"]))
n_neighbors = 6
knn = KNeighborsClassifier(n_neighbors=n_neighbors)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
assert y_pred.shape == y_test.shape데이터 모델링 성능 평가
# 모델 성능 - 정확도 측정
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import f1_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
report = classification_report(y_test, y_pred)
print(report)
print(f"accuracy = {accuracy_score(y_test, y_pred)}")
print(f"recall = {recall_score(y_test, y_pred, average=None)}")
print(f"precision_score = {precision_score(y_test, y_pred, average=None)}")
print(f"f1_score = {f1_score(y_test, y_pred, average=None)}")
print()
print(f"confusion_matrix = \n{confusion_matrix(y_test, y_pred)}")SVM (Support Vector Machine)
package import
import numpy as np
import pandas as pd
import sklearn
from sklearn.model_selection import train_test_split
from sklearn import svm
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import f1_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
print(f"numpy version = {np.__version__}")
print(f"pandas version = {pd.__version__}")
print(f"sklearn version = {sklearn.__version__}")데이터 불러오기
df = pd.read_csv("https://raw.githubusercontent.com/YoungjinBD/dataset/main/titanic.csv")
df데이터 전처리
# Age 결측치 평균값으로 대체
df["Age"] = df["Age"].fillna(df["Age"].mean())
assert df["Age"].isna().sum() == 0
# Embarked 결측치 최빈값으로 대체
df["Embarked"] = df["Embarked"].fillna(df["Embarked"].mode()[0])
assert df["Embarked"].isna().sum() == 0
# Sibsp, Parch 두 값을 더해서 FamilySize 칼럼 추가
# df = df.join(pd.DataFrame({"FamilySize": df["SibSp"] + df["Parch"]}))
df["FamilySize"] = df["SibSp"] + df["Parch"]
assert (df["FamilySize"] == df["SibSp"] + df["Parch"]).all()
# Sex, Embarked One-Hot 인코딩
if "sex_male" not in df.columns and "sex_female" not in df.columns:
# df = df.join(pd.get_dummies(df["Sex"], prefix="sex", prefix_sep="_", dtype="int"))
df = pd.concat([df, pd.get_dummies(df["Sex"], prefix="sex", prefix_sep="_", dtype="int")], axis=1)
if not all(column in df.columns for column in "Embarked_" + np.unique(df["Embarked"])):
df = df.join(pd.get_dummies(df["Embarked"], prefix="Embarked").astype(int))
# df = pd.concat([df, pd.get_dummies(df["Embarked"], prefix="Embarked").astype(int)], axis=1)
assert np.isin(["sex_male", "sex_female"], df.columns).all()
assert all(column in df.columns for column in ["Embarked_C", "Embarked_Q", "Embarked_S"])train, test 데이터 준비
from sklearn.model_selection import train_test_split
X = df[["Pclass", "Age", "Fare", "FamilySize", "sex_female", "sex_male", "Embarked_C", "Embarked_Q", "Embarked_S"]]
y = df["Survived"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=10)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)모델 적용 및 데이터 분석 수행
sklearn.svm.SVC클래스 활용sklearn.svm.SVC( *, C=1.0, kernel='rbf', degree=3, gamma='scale', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape='ovr', break_ties=False, random_state=None, )
from sklearn import svm
svc = svm.SVC() # kernel="rbf"
# svc = svm.SVC(kernel="rbf")
# svc = svm.SVC(kernel="linear", C=1, gamma=0.1)
# svc = svm.SVC(kernel="rbf", C=0.1, gamma=0.1)
svc.fit(X_train, y_train)
y_pred = svc.predict(X_test)
assert y_pred.shape == y_test.shape데이터 모델링 성능 평가
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
print(f"accuracy_socre = {accuracy_score(y_test, y_pred)}")
print(f"precision_score = {precision_score(y_test, y_pred, average=None)}")
print(f"recall_score = {recall_score(y_test, y_pred, average=None)}")
print(f"f1_score = {f1_score(y_test, y_pred, average=None)}")
print()
report = classification_report(y_test, y_pred)
print(report)
print(f"confusion_matrix = \n{confusion_matrix(y_test, y_pred)}")로지스틱 회귀 (Logistic Regression)
- Sigmoid 함수의 출력값을 각 분류 항목에 속하게 될 확률값으로 사용
- 이 값은 0과 1사이의 실수
- 확률에 따라 가능성이 더 높은 범주에 속하는 것으로 분류하는 이진 분류 모델이다.
- 현재 갖고있는 데이터를 통해 에러를 줄이는 방향으로
weight,bias의 최적값을 찾아간다.
package import
import numpy as np
import pandas as pd
import sklearn
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import f1_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
print(f"numpy version = {np.__version__}")
print(f"pandas version = {pd.__version__}")
print(f"sklearn version = {sklearn.__version__}")데이터 불러오기
df = pd.read_csv("https://raw.githubusercontent.com/YoungjinBD/dataset/main/iris.csv")
df데이터 전처리
# Normalization
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df_number = df.select_dtypes("number")
df_number_scaled = pd.DataFrame(scaler.fit_transform(df_number), columns=df_number.columns)
df[df_number.columns] = df_number_scaled
assert (df.describe().loc["min"] == 0.0).all()
assert (df.describe().loc["max"] == 1.0).all()
df.describe()train, test 데이터 준비
from sklearn.model_selection import train_test_split
X = df.select_dtypes(np.number)
y = df["species"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=11)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)모델 적용 및 데이터 분석 수행
sklearn.linear_model.LogisticRegression클래스 활용
sklearn.linear_model.LogisticRegression(
penalty='l2',
*,
dual=False,
tol=0.0001,
C=1.0,
fit_intercept=True,
intercept_scaling=1,
class_weight=None,
random_state=None,
solver='lbfgs',
max_iter=100,
multi_class='deprecated',
verbose=0,
warm_start=False,
n_jobs=None,
l1_ratio=None,
)from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(X_train, y_train)
y_pred = lr.predict(X_test)
assert y_pred.shape == y_test.shape데이터 모델링 성능 평가
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import f1_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
print(f"accuracy_score = {accuracy_score(y_test, y_pred)}")
print(f"recall_score = {recall_score(y_test, y_pred, average=None)}")
print(f"precision_score = {precision_score(y_test, y_pred, average=None)}")
print(f"f1_score = {f1_score(y_test, y_pred, average=None)}")
print()
report = classification_report(y_test, y_pred)
print(report)
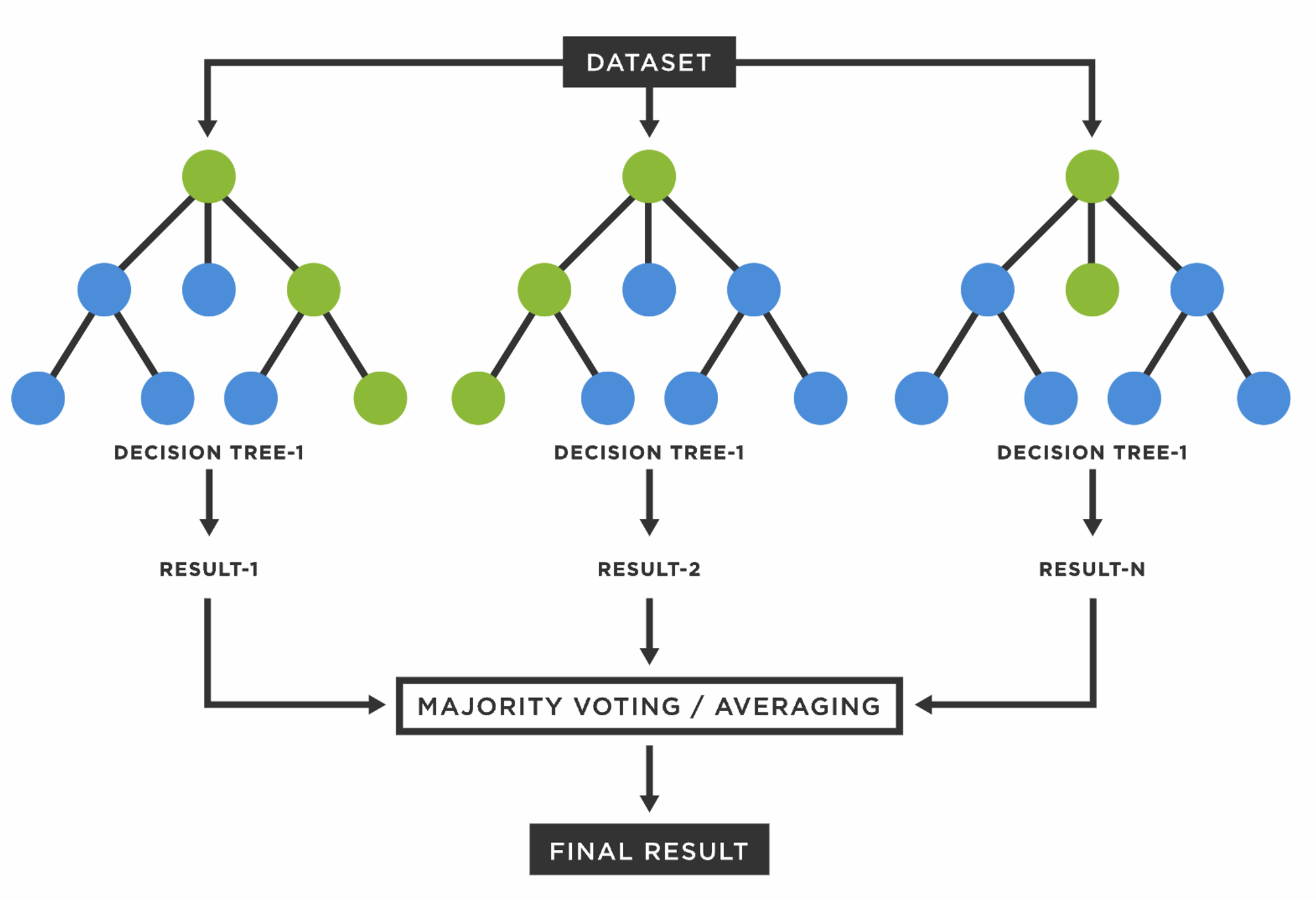
print(f"confusion_matrix = \n {confusion_matrix(y_test, y_pred)}")랜덤 포레스트 (Random Forest)
- 다수의 의사결정 트리들을 결합하여 분류 또는 회귀를 수행하는 아상블 기법이다.
- 각 트리는 전체 학습 데이터 중 서로 다른 데이터를 샘플링하여 일부 데이터를 제외한 후,
- 최적의 특징을 찾아 트리를 분기한다.
package import
import numpy as np
import pandas as pd
import sklearn
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import f1_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
print(f"numpy version = {np.__version__}")
print(f"pandas version = {pd.__version__}")
print(f"sklearn version = {sklearn.__version__}")데이터 불러오기
df = pd.read_csv("https://raw.githubusercontent.com/YoungjinBD/dataset/main/titanic.csv")
df데이터 전처리
# Age 결측치 평균값 대체
df["Age"] = df["Age"].fillna(df["Age"].mean())
assert df["Age"].isna().sum() == 0
# Embarked 결측치 최빈값 대체
df["Embarked"] = df["Embarked"].fillna(df["Embarked"].mode()[0])
assert df["Embarked"].isna().sum() == 0
# Sex Label Encoding
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
df["Sex"] = encoder.fit_transform(df["Sex"])
assert all(v in np.unique(df["Sex"]) for v in [0, 1])
assert len(np.unique(df["Sex"])) == 2
# Embarked Label Encoding
df["Embarked"] = encoder.fit_transform(df["Embarked"])
# SibSp, Parch 값 더해서 FamilySize 칼럼으로 추가
df["FamilySize"] = df["SibSp"] + df["Parch"]
dftrain, test 데이터 준비
from sklearn.model_selection import train_test_split
X = df[["Pclass", "Sex", "Age", "Fare", "Embarked", "FamilySize"]]
y = df["Survived"]
X_train, X_test, y_train, y_test = train_test_split(X, y)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)모델 적용 및 데이터 분석 수행
sklearn.ensemble.RandomForestClassifier클래스 활용sklearn.ensemble.RandomForestClassifier( n_estimators=100, *, criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='sqrt', max_leaf_nodes=None, min_impurity_decrease=0.0, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None, ccp_alpha=0.0, max_samples=None, monotonic_cst=None, )
from sklearn.ensemble import RandomForestClassifier
randomForest = RandomForestClassifier(n_estimators=50, max_depth=3, random_state=20)
randomForest.fit(X_train, y_train)
y_pred = randomForest.predict(X_test)
assert y_pred.shape == y_test.shape데이터 모델링 성능 평가
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import f1_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
y_test_pred = [y_test, y_pred]
report = classification_report(*y_test_pred)
print(report)
print(f"accuracy_score = {accuracy_score(*y_test_pred)}")
print(f"recall_score = {recall_score(*y_test_pred)}")
print(f"precision_score = {precision_score(*y_test_pred)}")
print(f"f1_score = {f1_score(*y_test_pred)}")
print(f"confusion_matrix=\n{confusion_matrix(*y_test_pred)}")
Hello velog!