[NeurIPS 2019] XLNet: Generalized Autoregressive Pretraining for Language Understanding
논문 리뷰(Paper Review)
목록 보기
4/5
이전에 읽었던 논문 리뷰 업로드..ㅎㅎ NLP 분야의 논문으로, Auto-Encoding + Auto-Regressive를 합친 모델이다. 논문은 다음 링크에서 접할 수 있다!
Abstract
- 최근 양방향 컨텍스트에 대한 모델링이 가능해짐에 따라, BERT와 같은 Denoising auto-encoding 기반의 Pretrained 방식은 auto-regressive 기반의 Pretrained 방식보다 더 나은 성능을 달성
- BERT는 마스크로 입력값을 손상시켜 학습한다는 단점을 가짐
- 마스크된 토큰들 사이의 dependency 반영 X
- 실제 데이터로 finetuning할 때, pretrain 마스크 X
- AR과 AE의 장단점을 고려한 Auto-regressive Pretrained 방법인 XLNet 제안
- factorization order의 모든 순열에 대해 예상 가능성을 최대화함 → 양방향 컨텍스트 학습 가능
- Auto-Regressive을 통해 BERT의 한계 극복
- SOTA Auto-Regressive 모델인 Transformer-XL의 아이디어를 Pretraining에 통합
- 2019년 6월 구글 AI팀에서 발표한 논문으로, 당시 20개 자연어 처리 부분에서 최고 성능을 달성함. (++ Transformer-XL 저자 == XLNet 저자)
Introduction
Unsupervised Representation Learning
- NLP 분야에서 좋은 성과를 냄
- 전형적인 방법
- 방대한 양의 unlabeled된 텍스트 말뭉치로 신경망을 사전학습
downstreamwork에 맞게 모델 또는 representation을 finetune함
- 성공적인 사전학습 방법 : AR(Auto-regressive), AE(Auto-encoding)
AR(Auto-regressive)
- AR의 특징
- 자기회귀 모델을 사용하여, 텍스트 말뭉치의 확률분포 추정 목적
- 이전 토큰들을 보고 다음 토큰 예측 → 데이터 순차적으로 처리함 (ELMO, ..)
- 텍스트 시퀀스가 주어지면, likelihood를 forward/backward product를 하여 분해함
- 신경망과 같은 parametric model은 각각의 조건부 분포를 모델링하도록 학습됨
- AR의 한계점
- 양방향 컨텍스트 모델링에 효과적이지 않음 → downstream 작업에 필요..! ⇒ AR 언어 모델링과 효과적인 pretraining 사이에 격차 발생
- 양방향 컨텍스트 모델링에 효과적이지 않음 → downstream 작업에 필요..! ⇒ AR 언어 모델링과 효과적인 pretraining 사이에 격차 발생
AE(Auto-encoding)
- AE의 특징
- AE의 목적은 손상된 입력에서 원본 데이터 재구성하는 것 (BERT, ..)
- 입력 토큰 시퀀스가 주어지면, 특정 부분이 [MASK]로 대체 → 손상된 버전에서 원래 토큰을 복구하도록 학습
- 양방향 컨텍스트를 사용하기 때문에, 양방향 정보 격차를 줄여 성능을 높임
- AE의 한계점
- pretrain-finetune discrepancy 문제 발생 ← [MASK] 기호는 실제 데이터에서 찾을 수 없음
- 토큰들은 서로 독립적이라고 가정 → 자연어에서 high-order, long-range dependency를 지나치게 단순화함
XLNet
- AR과 AE 언어 모델링의 장점을 살린, 일반화된 auto-regressive 방법인 XLNet 제안
Proposed Method
Background
⇒ AR 언어 모델링과 BERT에 대한 설명 및 비교
-
AR 언어 모델링
- 텍스트 시퀀스가 주어질 때, forward auto-regressive factorization에서 likelihood를 최대화하여 pretraining함
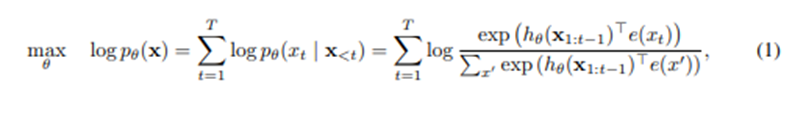
- : RNN 또는 Transformers와 같은 신경모델에서 생성된 컨텍스트 표현
- : x의 임베딩
- 텍스트 시퀀스가 주어질 때, forward auto-regressive factorization에서 likelihood를 최대화하여 pretraining함
-
BERT (== AE 언어 모델링)
- denoising auto-encoding 기반으로, 텍스트 시퀀스가 주어졌을 때, x에 있는 토큰 일부를 무작위로 특수기호 “[MASK]”로 대체 → 손상된 버전의 구성

- 학습 목표 : 를 로 재구성
- : 1인 경우에는 가 마스킹되었음을 의미함
- : 길이가 인 텍스트 시퀀스 에 대하여 hidden vector 시퀀스와 매핑하는 Transformer
-
3가지 측면에서 두 언어 모델의 장단점 비교
- Independence Assumption
- BERT는 수식에서 가 아닌 을 사용함. 끼리 independence를 가정했기 때문
- AR은 순차적으로 토큰을 예측하므로 Independence 가정 X
- Input Noise
- BERT는 랜덤으로 [MASK] 기호를 대체하여 데이터를 손상시키므로 Input Noise O
- AR은 입력의 corruption에 의존 X
- Context dependency
- BERT는 양방향 정보 사용
- AR은 단방향 정보 사용
- Independence Assumption
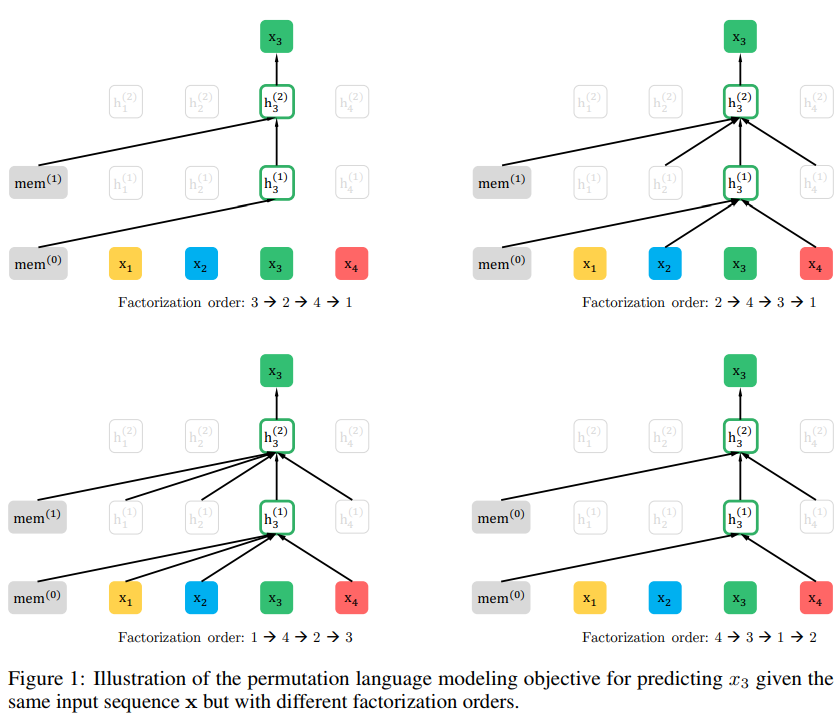
Permutation Language Modeling
- Permutation Language Model : AR모델의 장점을 유지하면서, 양방향 컨텍스트를 확보할 수 있도록 하는 모델
- 길이가 T인 시퀀스 x에는 T!개의 서로다른 순서가 autoregressive factorization을 위해 존재
-
모든 permutation에 대하여 고려한다면, 모델은 모든 위치에서 양방향에 대한 정보를 얻을 수 있음
-
AR framework 방식임!
⇒ independence assumption과 pretrain-finetune discrepancy 문제 해결
-
- 제안된 모델은 factorization order만을 바꾸는 거임 =⇒ 순열의 대상
- Transformer의 attention mask에서 순서를 바꾸는데 사용됨
- 기존의 sequence order는 유지 → finetuning 때에는 natural order와 함께 text sequence를 적용해야 하기 때문
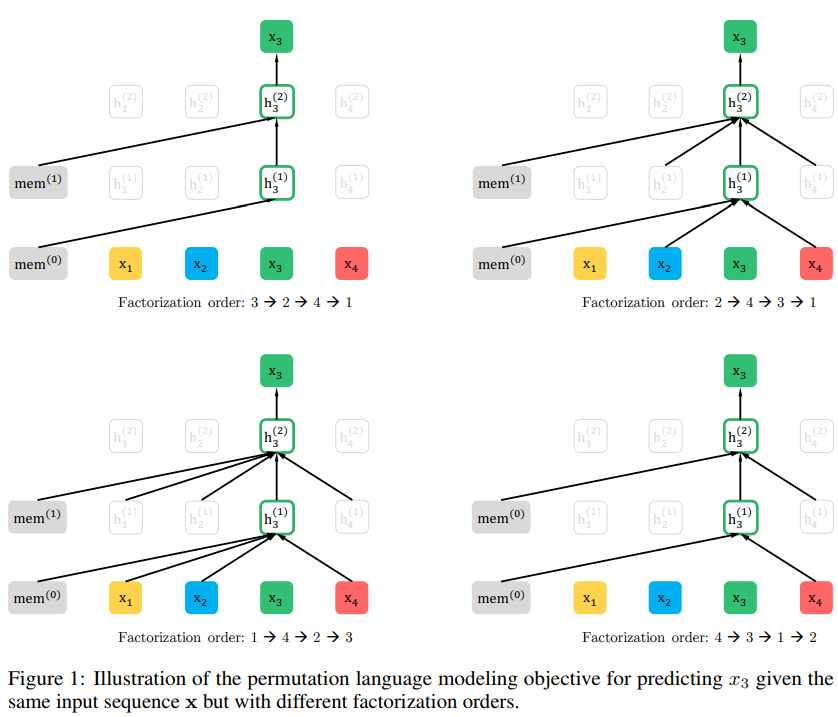
- 동일한 입력 시퀀스 x가 있지만, 다른 factorization order로 x3 예측하는 이미지
Architecture
-
논문에서 제시한 방법은 Standard Transformer Parameterixation에서는 작동하지 않는다는 문제를 지님
- next-token distribution을 다음과 같이 표기함 (=softmax formulation)
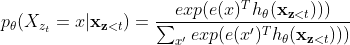
- 는 마스킹 후 공유된 Transformer 네트워크를 통해 생성된 의 hidden representation으로, 예측할 단어의 위치 에 의존하지 않음
- target의 위치와 관계없이 같은 분포가 예측되는 현상 발생 → 유용한 representation을 학습할 수 없음
- next-token distribution을 다음과 같이 표기함 (=softmax formulation)
-
따라서 re-parameterize 할 것을 제안함. (⇒ Target Aware representation)
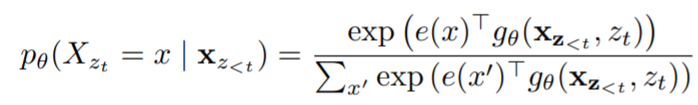
→ 를 고려함으로써, target position 고려
-
Two-Stream Self-Attention
- Target Aware representation 계산 과정에서 모순점 2가지
- 위치만 사용해야함 → 의 내용은 사용하면 안됨
- 다른 토큰을 예측할 때, 전체 문맥 정보를 제공하기 위해 내용을 인코딩 해야함
- query stream attention과 content stream attention 두 가지를 혼합한 self attention 기법
- content stream attention
- 기존의 self-attention과 유사
- 예측하고자 하는 토큰의 실제값 정보를 같이 사용하여 예측
- query stream attention
- 토큰, position 정보를 활용한 self-attention 기법
- content stream attention과는 달리, 예측하고자 하는 target 토큰 이전의 정보 값을 예측에 사용
- content stream attention
- Target Aware representation 계산 과정에서 모순점 2가지
-
Incorporating Ideas from Transformer-XL
- AR language model에 Transformer-XL을 결합함
- relative positional encoding
- 상대적 위치 정보를 모델링하는 기법
- attention score 식:

- (b),(d)에서의 absolute positional embedding 를 로 대체
⇒ R은 learnable parameters가 아닌 sinusoid encoding matrix임 - query position에 대해 qurey vector가 같아야 하므로, (c),(d)에서 를 , 로 대체
- 를 와 로 분리
⇒ content기반의 key vector와 location기반의 key vector를 각각 만들기 위해 - 결과적으로 각 term들은 직관적인 의미를 지님
(a): content 기반 처리
(b): content에 의존한 positional bias 잡음
(c): global content bias 인코딩
(d) : global positional bias 인코딩
- segment recurrence mechanism
- 긴 문장에 대해 여러 segment로 분리하고, 이에 대하여 recurrent하게 모델링함
- relative positional encoding
- AR language model에 Transformer-XL을 결합함

🤗🤗🤗
소중한 정보 감사드립니다!