[ICML 2021] CLIP: Learning Transferable Visual Models From Natural Language Supervision
논문 리뷰(Paper Review)
목록 보기
3/5
지난 달에 열린 cvpr 2023에 다녀왔는데, accept된 논문들 중 VL 모델의 대부분 CLIP과 성능을 비교하는 것을 보았다. CLIP에 대해 간단하게 리뷰해 보고자 한다. CLIP은 OpenAI에서 제안한 모델로, 논문은 다음 링크에서 확인 가능하고, 아래 리뷰의 summary를 github에 정리해두었다.
Abstract
- 컴퓨터비전의 최신기술 시스템은 정해진 카테고리의 고정된 셋을 예측하도록 학습시킴 → 이는 추가적으로 레이블된 데이터에는 적용하기 힘든 한계점 발생
- 핵심 Idea: 어떤 캡션이 어떤 이미지와 함께 가는지에 대한 간단한 사전학습을 통하여, SOTA 이미지 표현을 효율적이고 확장가능하도록 학습함.
- 사전학습 이후, 자연어는 학습된 시각적 개념을 참조하는데 사용되어, downstream task에 zero-shot을 적용할 수 있도록 함
1. Introduction and Motivating Work
- NLP 분야에서는 raw text 데이터를 활용해 사전학습하는 방식으로 지난 몇년간 혁신을 보여줌
- 또한, text-to-text의 발달로 인해 특수한 데이터 학습 없이도 zero-shot transfer가 가능하게 됨
- 자연어 supervision으로 image representation learning은 좋지 않은 성능을 보이는데, zero-shot learning에서도 현저히 낮은 정확도를 보임.
- weakly supervised model은 어느 정도 개선은 있었지만, 모델의 유연성을 단축시키고 zero-shot 능력을 제한함
- 본 논문은 CLIP(Contrastive Language-Image Pre-training)이라는 모델을 제안
- weakly supervised model과 text를 통한 image representation의 학습에서 가장 중요한 차이는 데이터 규모로 보았으며, 이 차이를 줄이기 위해 400M개 쌍의 (이미지, 텍스트) 데이터를 수집함
- 대규모의 text 데이터를 학습하고 이를 image와 연결해주어, 다양한 vision task에서 좋은 결과를 보여줌
2. Approach
2.1. Natural Language Supervision
- 자연어로부터 학습하는 것은 다른 학습 방식을 넘어서 잠재적으로 여러 강점을 가짐
- 이미지분류에서 기존 crowd-sourced labeling과 비교했을 때, 자연어 supervision은 ‘ML compatible format’을 따르지 않기 때문에 확장하기 더욱 쉬움
- 자연어로부터 학습하는 것은 representation을 ‘그냥’ 학습하지 않고, 언어에 대한 representation까지도 연결하기 때문에, zero-shot transfer를 가능하게 함
2.2. Creating a Sufficiently Large Dataset
- 기존의 연구는 주로 MS-COCO, Visual Genome, YFCC100M 등의 데이터를 사용
- 본 논문은 인터넷에 공개된 방대한 데이터셋을 수집하여 400M개의 이미지와 텍스트 쌍으로 구성된 데이터를 사용함
2.3. Selecting an Efficient Pre-Training Method
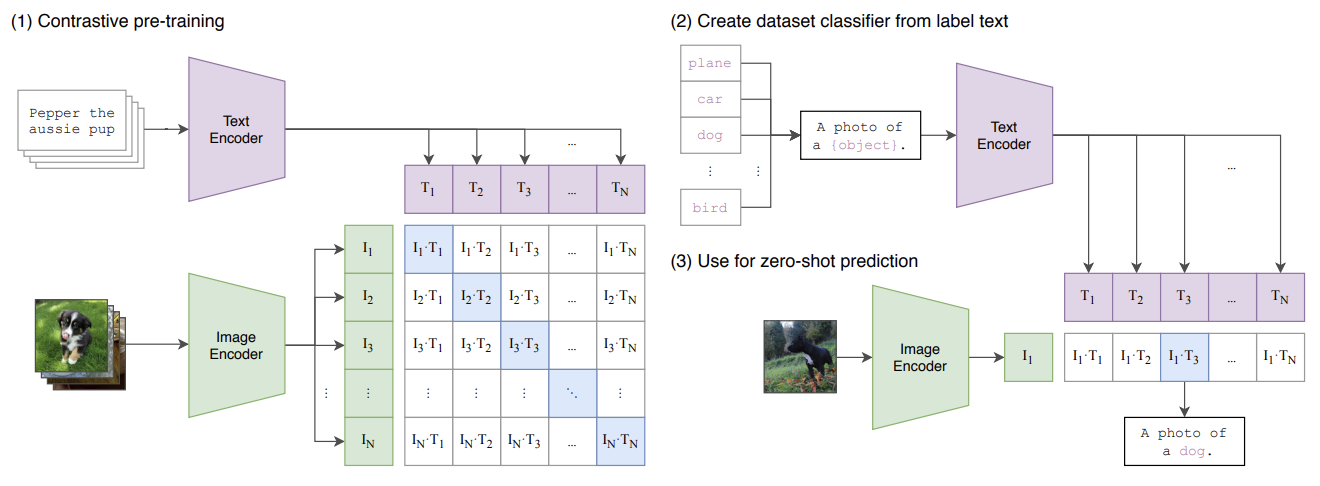
- selected approach: bag-of-words contrastive 방식
- Contrastive Learning은 두 개의 input에 대해 각각 encoder 통과 후 나온 두 embedding 간의 유사도를 계산하는 방식
- CLIP의 Method는 다음과 같음
- batch마다 N개의 (image, text) 쌍이 존재할 때, 각각 encoder를 통과해 나온 N개의 embedding 결과의 유사도 계산
- positive pair(diagonal)에서의 코사인 유사도는 최대화하고, negative pair(off-diagonal)에서의 유사도는 최소화하도록 loss 설정하여 학습
- 따라서 임의의 이미지가 입력되었을 때, image와 text embedding의 유사도를 비교하여, 가장 높은 항목을 text label로 선정됨 → 학습에 사용되지 않은 데이터도 prediction 가능 (zero-shot learning)
2.4. Choosing and Scaling a Model
- image encoder: 2개의 architecture 고려 (ReNet-50과 ViT)
- text encoder: Transformer 사용
2.5. Training
- 5개의 ResNet과 3개의 ViT로 실험
- ResNet: ResNet-50, ResNet-101, EfficientNet-style의 ResNet-50(RN50x4, RN50x16, RN50x64)
- Vision Transformer: ViT-B/32, ViT-B/16, ViT-L/14
- epochs: 32 // optimizer: Adam // lr: cosine-schedule

🤗🤗🤗
덕분에 좋은 정보 얻어갑니다, 감사합니다.