[CVPR 2017] Pix2Pix: Image-to-Image Translation with Conditional Adversarial Networks
논문 리뷰(Paper Review)
목록 보기
5/5
Conditional GAN 중 가장 base가 되고 있는 pix2pix에 대해 리뷰해보았다. pix2pix는 Berkeley AI Research(BAIR) Lab에서 2016년에 처음 발표했고, cvpr에 accepted된 논문이다. 논문은 다음 링크에서 접할 수 있고, 간단한 summary는 github에 정리해두었다.
1. Introduction
- image translation을 위해 CNN을 활용한 연구가 상당히 진행되어왔지만, 결과적으로 여러 문제 존재함
- CNN은 loss function을 최소화하도록 학습하기 때문에, task에 따라 효율적인 loss를 정의해야함
- 예를 들어, euclidian distance를 loss로 사용해 최소화하도록 학습한다면, blurry한 결과를 생성하게 됨
- output sharp/realistic 등과 같이 우리가 원하는 결과를 얻으려면 CNN으로는 한계가 있고 일반적으로 전문지식이 요구됨
- 본 논문은 Conditional GAN을 사용하여 image-to-image translation task 수행 →
pix2pix
2. Related work
Structured losses for image modeling
- Conditional GAN은 output의 연관관계(joint configuration)에 패널티를 부과하는 방법인 structured loss를 학습함
- 패널티 부과 방법: conditional random fields, SSIM metric, feature matching, nonparametric losses, convolutional pseudo-prior, losses based on matching covariance statistics
- Conditional GAN은 loss가 학습된다는 점에서 CNN과 차이를 보이며, 이론적으로 output과 target의 차이를 줄이기 위해 패널티를 줌
Conditional GANs
- 여러 논문에서 image-to-image mappings을 위해 condition없는 GAN만을 활용했고, L2와 같은 방법으로 input에 condition되게끔 output을 강제적으로 학습함
- 위 논문들은 inpainting을 포함한 여러 분야에서 성과를 냄
- 본 논문은 generator와 discriminator에 대한 여러 아키텍처 선택에서 이전 연구와 차이를 보임
- generator는 UNet 기반의 아키텍처를 사용했고, discriminator는 convolutional PatchGAN classifier를 사용
3. Method
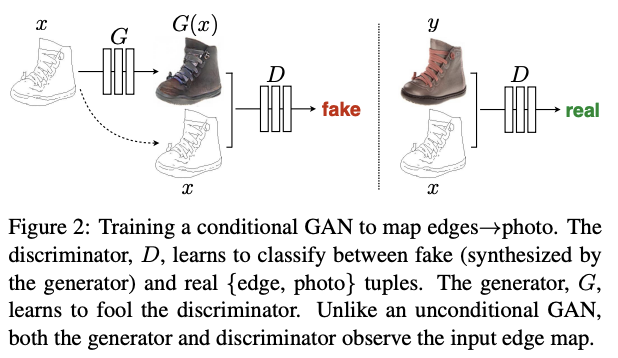
- GAN은 랜덤 노이즈 벡터 로부터 output image 로 맵핑을 학습하는 생성모델
- conditional GAN은 observed image x와 랜덤 노이즈 벡터 z로부터 y의 맵핑을 학습
3.1. Objective
- Conditional GAN은 기존 GAN loss에서 condition x를 추가하는데, 본 논문에서는 condition x = input image
- traditional loss와 GAN loss를 같이 사용했을 때 효과적이었다는 이전 연구 결과에 기반해, cGAN loss에 L1 loss를 함께 사용
- L1이 L2 보다 덜 blurry
- 또한, random noise z를 사용하지 않아도 generator를 학습시킬 수 있기 때문에 뺌
- generator의 Dropout layer로 노이즈 생성하고, 기존과 다르게 training 뿐만 아니라 test에도 Dropout layer 적용됨
3.2. Network architectures
Generator with skips
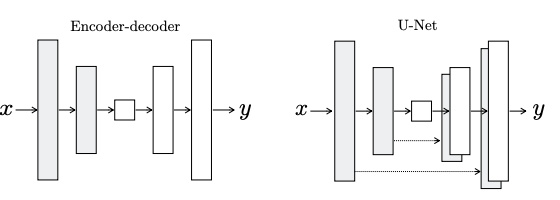
- 이전 연구들은 encoder-decoder 구조의 네트워크를 사용함으로써 high-level feature를 추출함
- 그러나 image translation 과정에서 low-level feature가 필요한 상황이 발생하는데, 기존 encoder-decoder 네트워크를 사용하면 이 정보들이 손실됨
- 따라서, UNet기반의 모델에 skip-connection을 추가하여, low-level 정보 손실을 막아 detail한 image translation 가능
Markovian discriminator (PatchGAN)
- 이미지를 N*N patch 단위로 쪼개어, 각각의 patch가 real인지 fake인지를 판별함 → patch들은 서로 독립이라는 가정을 따름(markov random field)
Optimization and Inference
- G를 학습할 때, 기존 GAN과 달리 를 최소화하지 않고 최대화하도록 수정
- 또한, D를 최적화할 때 objective를 2로 나누어 G보다 천천히 학습되도록 함
- inference 과정에서는 Dropout을 그대로 사용해주었고, batch normalization 할 때 train batch의 statistic이 아닌 test batch의 statistic을 사용함

🤗🤗🤗